A realistic perception through Lidar
- b05902031謝議霆
- b05902008王行健
- b05902125葛淯為
Outline
- Lidar Data format
- object detection
- PIXOR
- Deep continous fusion
- Frustum pointnets
- Aggregate View object detection
- conclusion
Lidar data format
Outline
- Lidar Data format
- object detection
- PIXOR
- Deep continous fusion
- Frustum pointnets
- Aggregate View object detection
- conclusion
3D point cloud

https://deepdrive.berkeley.edu/sites/default/files/styles/project_primary/public/projects/1707ObjectDetection_DataCollected.png?itok=x_B2igjd&c=6bdf32aba2a1789b077401c605966b17
BEV(bird eye view)

https://www.google.com/url?sa=i&source=images&cd=&cad=rja&uact=8&ved=2ahUKEwi06cnP8q7fAhWPd94KHetfBCQQjRx6BAgBEAU&url=http%3A%2F%2Fronny.rest%2Fblog%2Fpost_2017_03_26_lidar_birds_eye%2F&psig=AOvVaw2QVG5xJaiLwknrmXxMzn3a&ust=1545411818858203
Object detection
Outline
- Lidar Data format
- object detection
- PIXOR
- Deep continous fusion
- Frustum pointnets
- Aggregate View object detection
- conclusion
BEV

https://www.google.com/url?sa=i&source=images&cd=&ved=2ahUKEwi6vaHi8q7fAhVQZt4KHTqQCkcQjRx6BAgBEAQ&url=https%3A%2F%2Farxiv.org%2Fpdf%2F1805.01195&psig=AOvVaw3NDCkHDkL3oMDAH5rwL4ea&ust=1545411981064996
Image
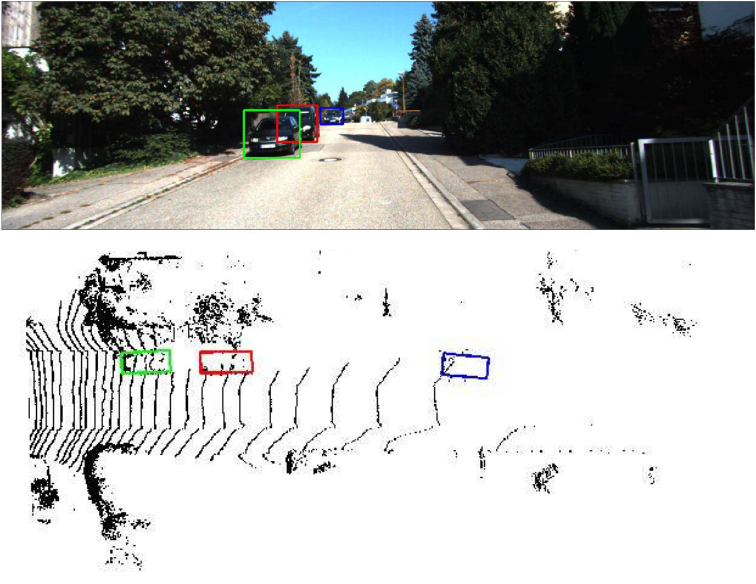
http://openaccess.thecvf.com/content_ECCV_2018/papers/Ming_Liang_Deep_Continuous_Fusion_ECCV_2018_paper.pdf
Evaluation -- IOU
- Intersection of union
Predicted\ region\cap ground\ truth \over Predicted\ region \cup ground\ truth
- Information in IOU
- Center
- angle
- size
PIXOR
real-time object detection on BEV
http://openaccess.thecvf.com/content_cvpr_2018/CameraReady/3012.pdf
Outline
- Lidar Data format
- object detection
- PIXOR
- Deep continous fusion
- Frustum pointnets
- Aggregate View object detection
- conclusion
Comparison
- Sparse point
- 3D convolution
- costly
3D clouds
BEV
- Depth channel
- standard convolution
- fast
Result
| Vehicle | Pedestrian | Bicyclist |
|---|---|---|
AP_{0.5}
AP_{0.7}
AP_{0.3}
AP_{0.5}
AP_{0.3}
AP_{0.5}
91.35
79.37
n/a
n/a
n/a
n/a
What really matters?
Is it important to detect a car?
Improper trade off
- Connected Car
- pedestrian, bicyclist
- restrict in BEV
- misunderstand object
Deep Continuous Fusion
http://openaccess.thecvf.com/content_ECCV_2018/papers/Ming_Liang_Deep_Continuous_Fusion_ECCV_2018_paper.pdf
Outline
- Lidar Data format
- object detection
- PIXOR
- Deep continous fusion
- Frustum pointnets
- Aggregate View object detection
- conclusion
Multi-Sensor
- To improve the disadvantage of lidar data
- Non-trivial fusion between 3D point cloud and camera image
- Sparse VS continous
method
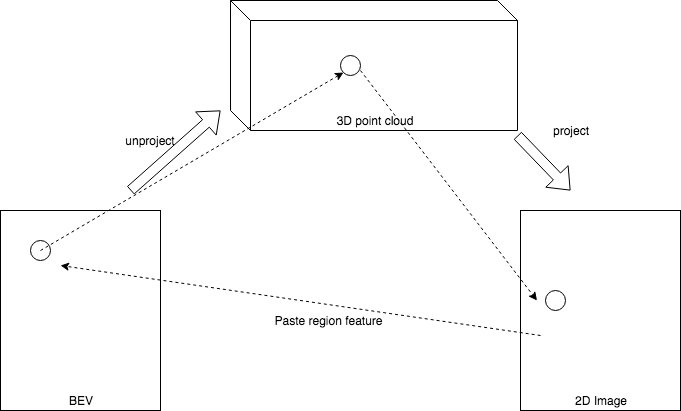
Result
| Vehicle | Pedestrian | Bicyclist | |
|---|---|---|---|
| PIXOR | |||
| Cont Fusion |
AP_{0.5}
AP_{0.7}
AP_{0.3}
AP_{0.5}
AP_{0.3}
AP_{0.5}
91.35
79.37
n/a
n/a
n/a
n/a
94.94
83.89
82.32
75.34
74.08
59.83
Issue
- non-observable place in Camera Image
- Solution : KNN search
Frustum PointNets
http://openaccess.thecvf.com/content_cvpr_2018/papers/Qi_Frustum_PointNets_for_CVPR_2018_paper.pdf
Outline
- Lidar Data format
- object detection
- PIXOR
- Deep continous fusion
- Frustum pointnets
- Aggregate View object detection
- conclusion
Another fusion method
- RGB image + Depth
- Depth channel : From 3D point cloud
Segmentation
- candidate
- Time reduction : f-rcnn to reduce the candidates
Classify
- Class
- orientation
- center
- size
Two stage
Label the box
- In RGBD image, a box might include some point with non-reasonable depth
- Thus, label on the 3D image instead.
Aggregate View Object Detection
https://arxiv.org/pdf/1712.02294.pdf
Outline
- Lidar Data format
- object detection
- PIXOR
- Deep continous fusion
- Frustum pointnets
- Aggregate View object detection
- conclusion
Pyramid-like structure
- sparse point
- points of pedestrian, small object......
- different level of kernel
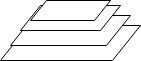
A set of anchor grid
- Possible box
- Score a region to choose the candidate
- Time reduction
Conclusion
Top among methods
- speed : PIXOR
- Vehicle : continuous fusion
- Pedestrian & bicyclist : Frustum pointnets
Difficulty to be realistic
- Attractive factor : Score (time, accuracy)
- Cost to achieve such score
- zero-tolerant on error
Lidar
By piepie01



