Clustering
UCI heart disease
Clustering
Clustering is an unsupervised learning technique used to group similar data points toghether based on their characteristic.
Clustering
Why we cluster data
1. Discover hidden patterns;
2. Simplify complex data;
3. Improve decision-making;
4. Preprocessing for other models.
UCI heart disease
UCI heart disease
UCI heart disease
1. sex
2. cp
3. fbs
4. restecg
5. exang
6. slope
7. thal
8. age
9. trestbps
10. chol
11. thalach
12. oldpeak
13. ca
Categorical
Continuous
UCI heart disease
1. sex
2. cp
3. fbs
4. restecg
5. exang
6. slope
7. thal
Categorical
Continuous
8. age
9. trestbps
10. chol
11. thalach
12. oldpeak
13. ca
1. To group samples into categories with correlated features.
2. To predict eventual heart disease
Goals
Used algorithm
Used algorithm
K-Means
- One of most famous algorithm
- Try to find correlations
- Input: number of cluster (k)
- Output: visualization in a scatterplot
K-Means
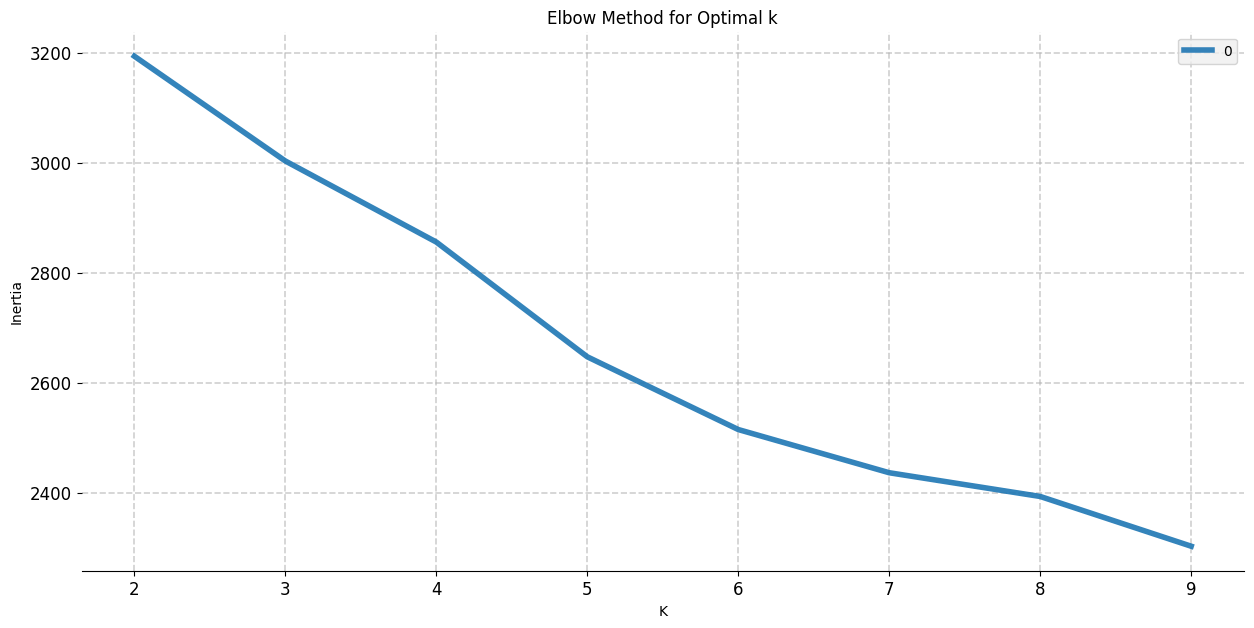
Elbow-method
K-Means
Elbow-method
- Find the suitable k for the dataset
-
When the curve get more linear,
we have the optimal k
Scatterplot
Scatterplot
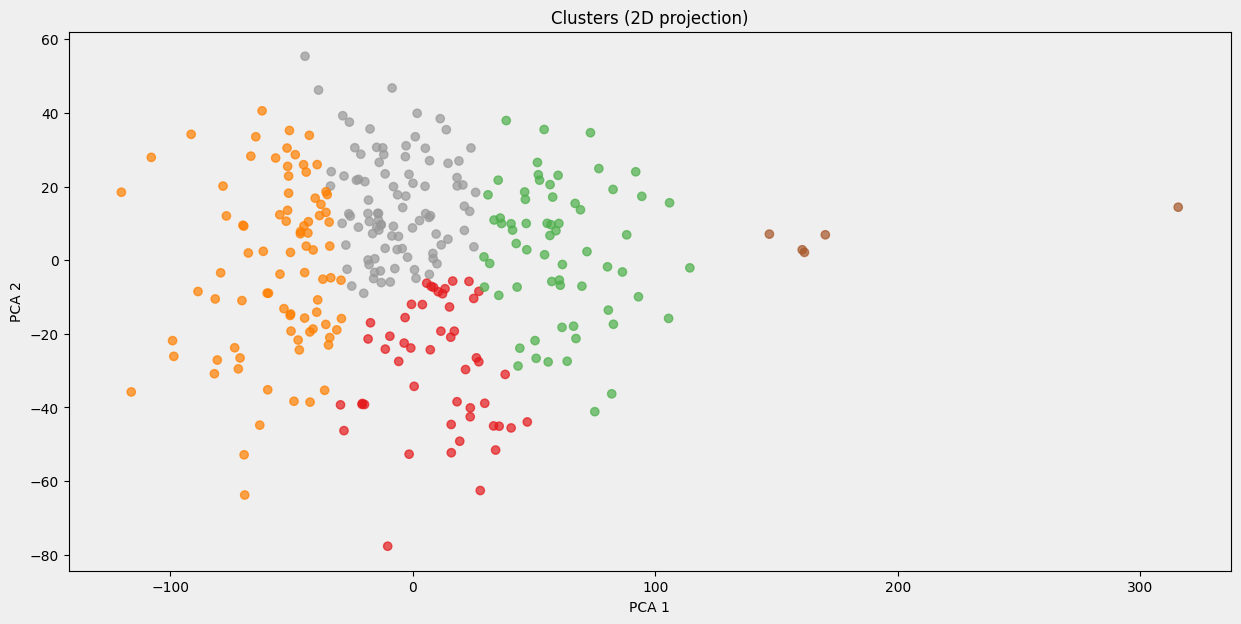
PCA plot
- Easier to read
- Good for low featured
dataset
Scatterplot
PCA plot
- Easier to read
- Good for low featured
dataset
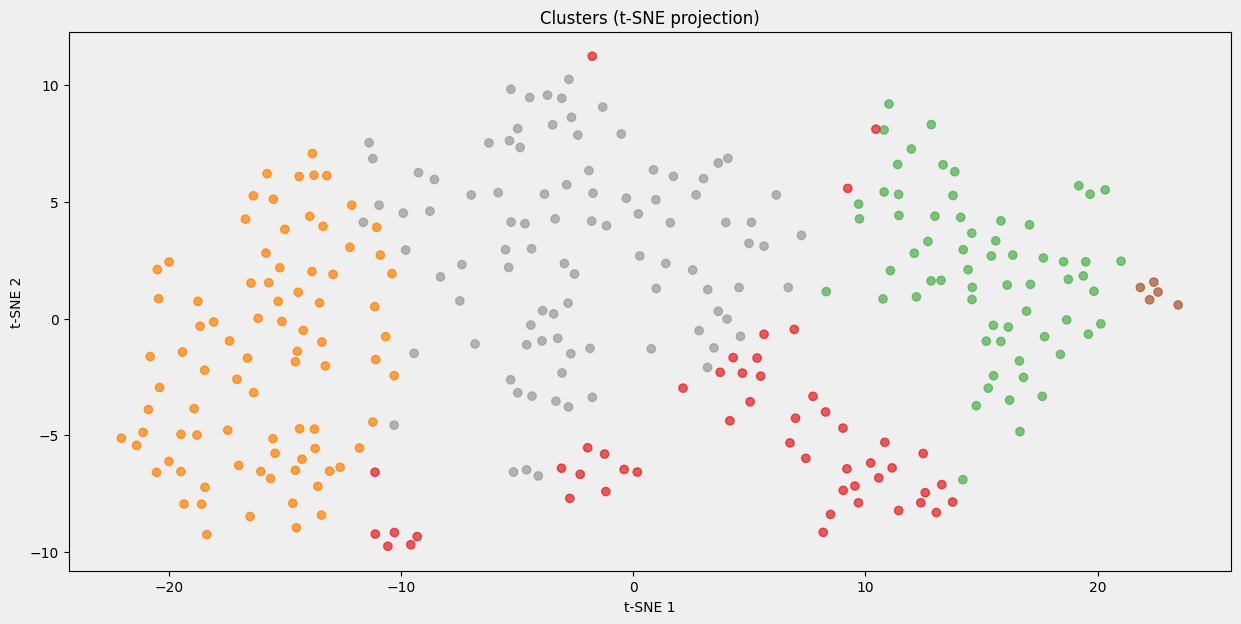
t-SNE plot
- More informative
- Good for high featured datasets
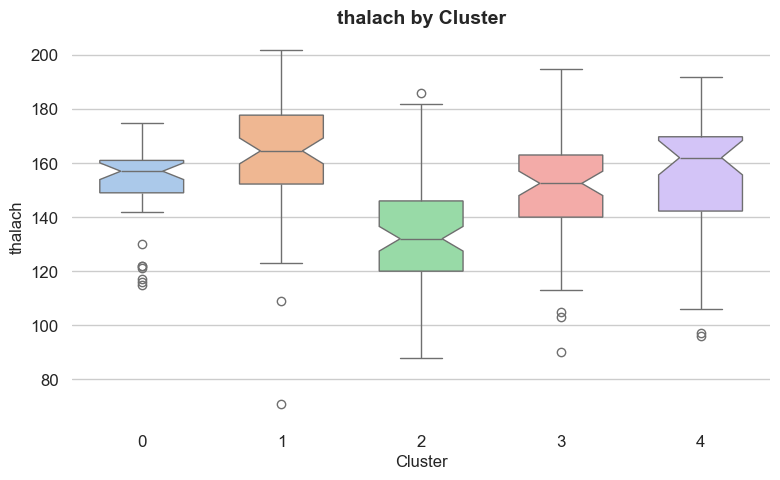
Feature importance
Feature importance
Each feature has a different level of importance in determining the cluster assignment of a given record.
Feature importance
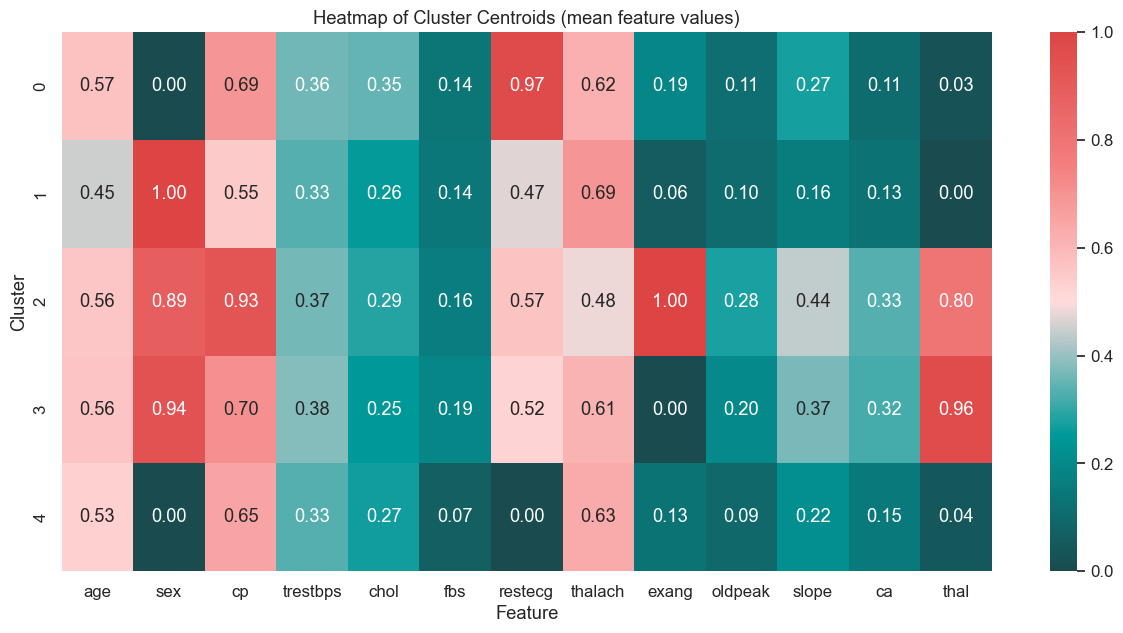
Feature importance
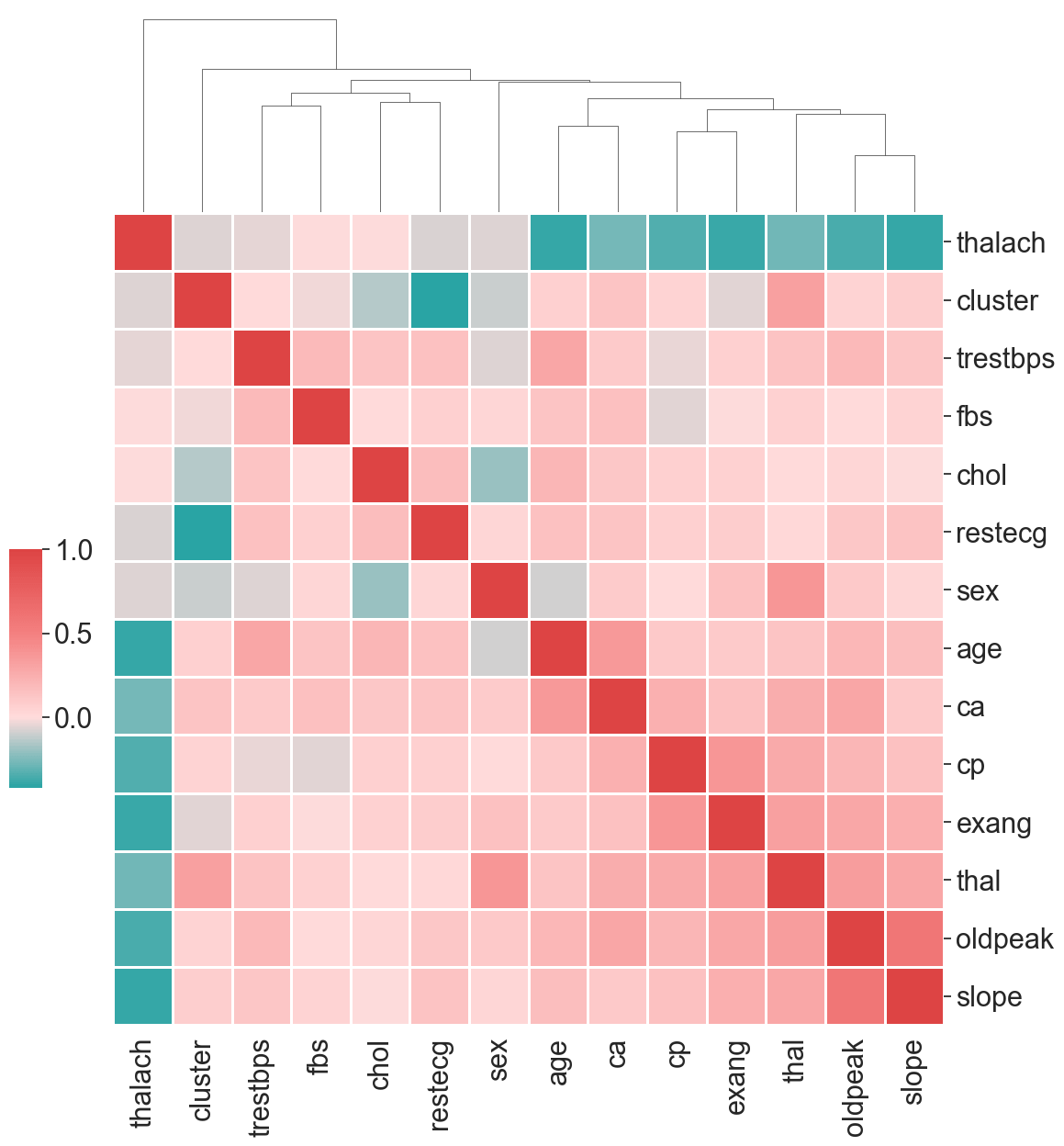
Feature importance
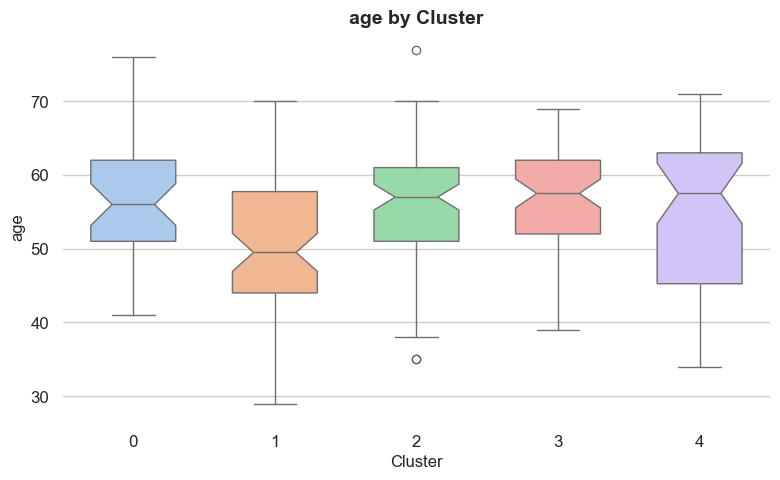
Feature importance
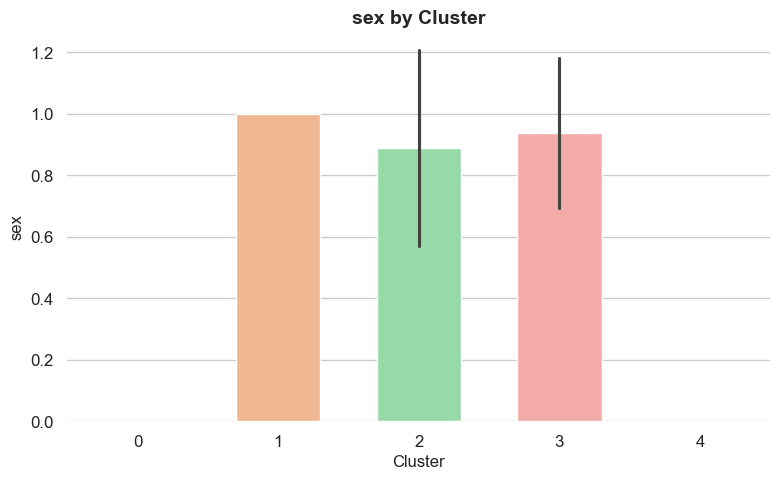
Feature importance
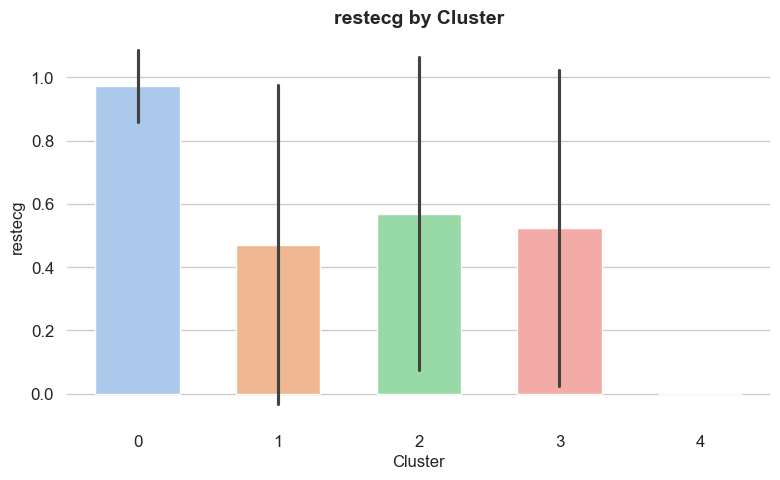
Feature importance
Credits
Pietro Mondini
Nicolò Moroni
Alessandro Crippa

Clustering
By Pietro Mondini

