From Selfie to AI: How to Teach Stable Diffusion Your Face and More
Demo time!
Training
You will need:
- some Python + good NVIDIA card (at least 16 GB VRAM)
- kohya-ss/sd-scripts with or without some extensions (e.g. cocktailpeanut/fluxgym)
- 1h - 2h - it depends on the number of images
- demo should take around 10-15 minutes
source env/bin/activate
./outputs/train.sh
----
nvidia-smiBefore we start
Fake but good enough
Contract
- Complex math will be presented
- LaTeX will be presented
- Inappropriate content will be presented
- Adult content will be presented
- Stupid "selfies" will be presented
Agenda
- Complex math will be presented
- LaTeX will be presented
- Inappropriate content will be presented
- Adult content will be presented
- Stupid "selfies" will be presented
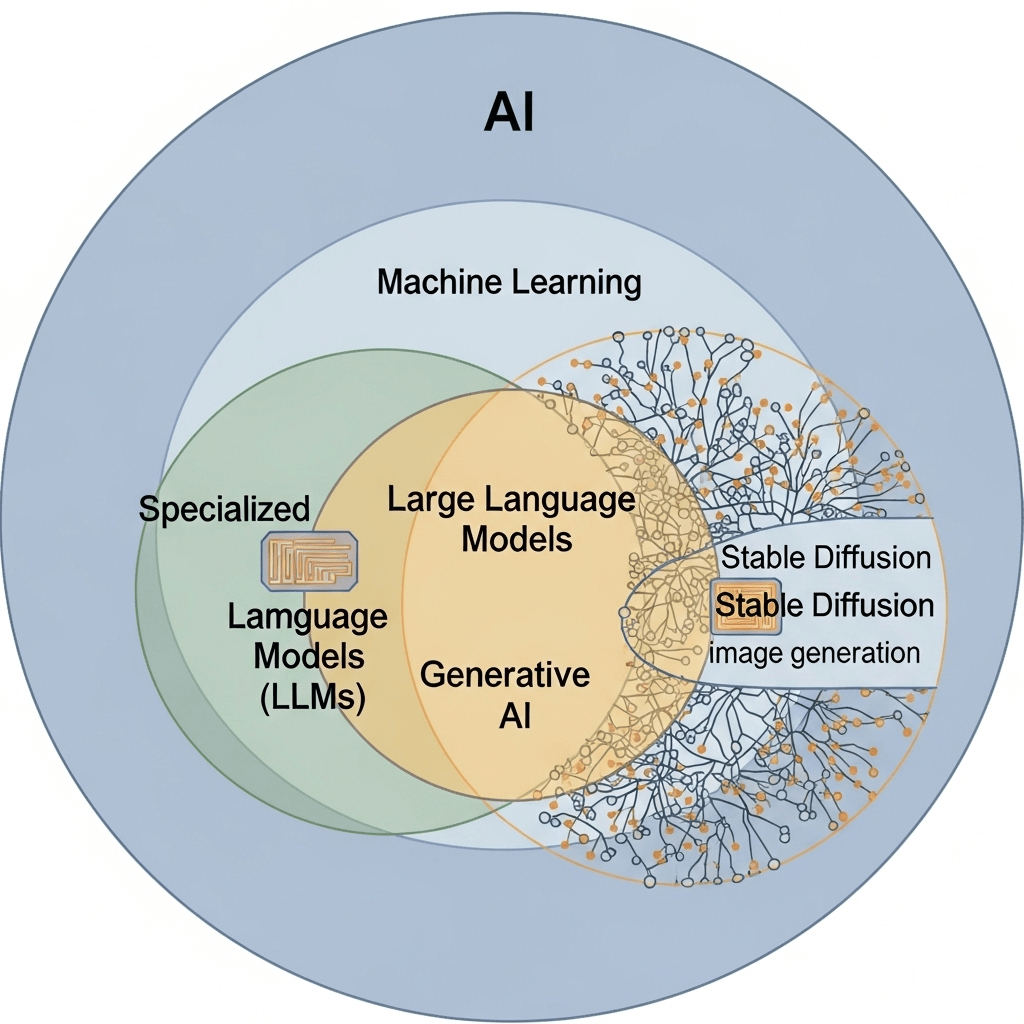
Why?






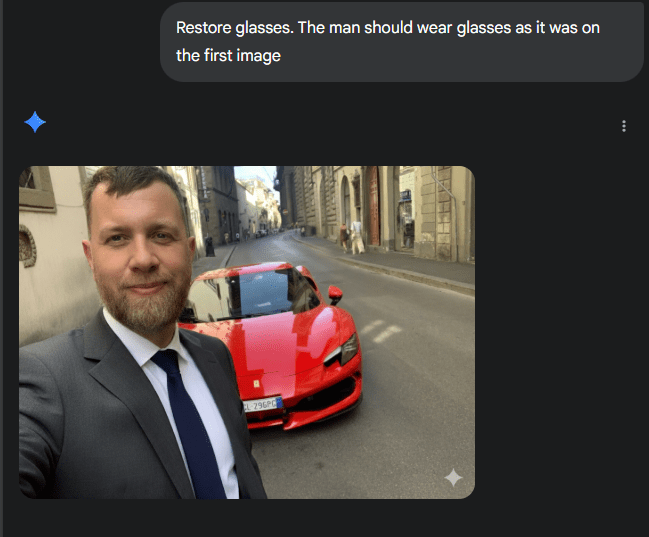

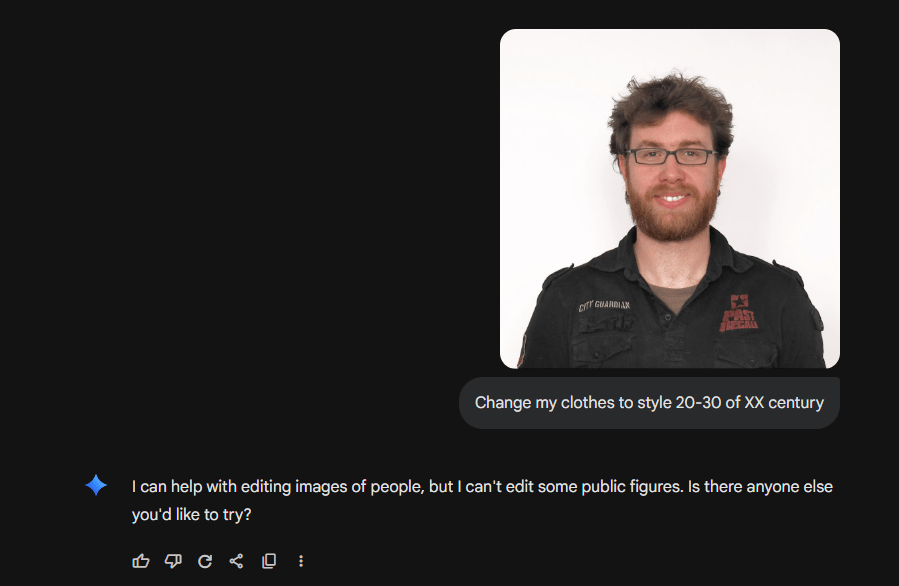
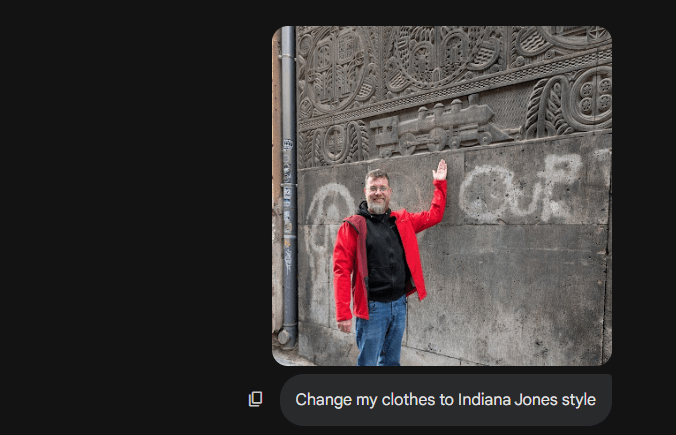



Curiosity!
Welcome

Name and Surname:
Piotr Stapp
Experience in IT:
18 years
Position:
System Principal Architect
Specialization:
Cleaner, Cloud, Code, Infra
Distinguishing marks:
Don't Stapp me now!



Theory
Core Concepts
Diffusion models learn to reverse a gradual noising process applied to training images.
The 2 key processes are:
-
Forward Process (Diffusion):
Noise is incrementally added to an image over several steps until it's indistinguishable from pure noise. -
Reverse Process (Denoising):
The model learns how to undo this noising process by predicting and removing noise at each step to recover the original image.
Core Concepts - math
Formally, they model:
-
A Markov chain that adds Gaussian noise:
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)q(x_t | x_{t-1}) = \mathcal{N}(x_t; \sqrt{1 - \beta_t} x_{t-1}, \beta_t I)pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))p_\theta(x_{t-1} | x_t) = \mathcal{N}(x_{t-1}; \mu_\theta(x_t, t), \Sigma_\theta(x_t, t))
q(x_t \mid x_{t-1}) = \mathcal{N}(x_t; \sqrt{1 - \beta_t} \, x_{t-1}, \beta_t \mathbf{I})
A neural network learns the reverse denoising:
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)q(x_t | x_{t-1}) = \mathcal{N}(x_t; \sqrt{1 - \beta_t} x_{t-1}, \beta_t I)pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))p_\theta(x_{t-1} | x_t) = \mathcal{N}(x_{t-1}; \mu_\theta(x_t, t), \Sigma_\theta(x_t, t))
p_\theta(x_{t-1} \mid x_t) = \mathcal{N}(x_{t-1}; \mu_\theta(x_t, t), \Sigma_\theta(x_t, t))
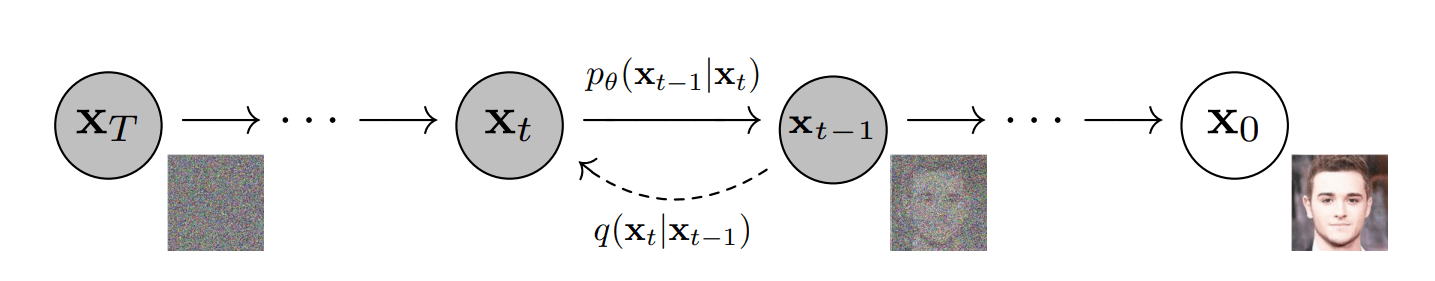
Source:
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising Diffusion Probabilistic Models. arXiv preprint arXiv:2006.11239, 2020
Core Concepts - image
Text to image
- Text Encoding (e.g., with CLIP, T5 or BERT)
- Image Denoising with guidance
Image Denoising
During image generation:
- Start with pure Gaussian noise.
- The model (typically a U-Net) uses the text embedding to conditionally predict what the less-noisy version of the image should look like.
- This process repeats for 25–1000 timesteps.
There are different types of conditioning:
- Classifier-free guidance (used in Stable Diffusion) allows the model to balance between purely random outputs and tightly matching the text prompt.
U-Net
A U-Net is a type of convolutional neural network (CNN) originally developed for biomedical image segmentation, but it’s now widely used in many image-to-image tasks, including diffusion models like Stable Diffusion.
U-Net
Dae-Young Kang, Hieu Pham Duong, and Jung-Chul Park.
Application of Deep Learning in Dentistry and Implantology. Implantology, vol. 24, no. 3, 2020, pp. 148–181. arXiv
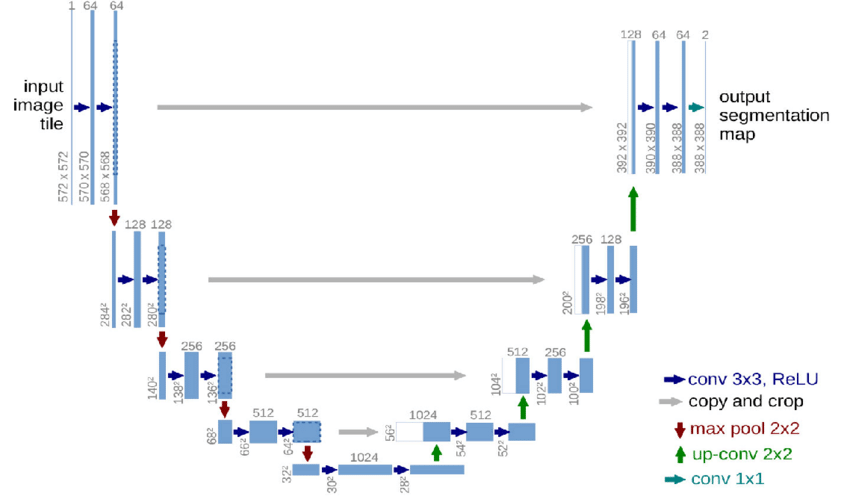
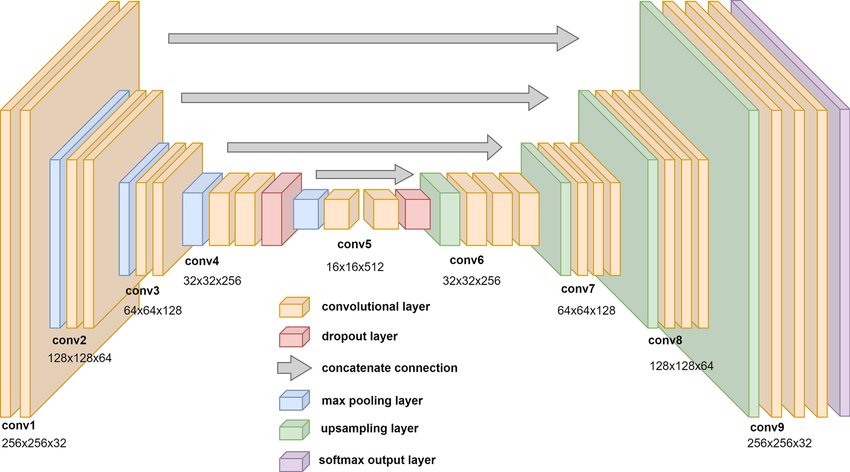
U-Net
M. J. Cardoso, A. Li, A. D. McClure, et al. Deep learning tools for the cancer clinic: an open-source framework with head and neck contour validation. Radiation Oncology, 2022. Available at: https://www.researchgate.net/publication/358442721
LoRA
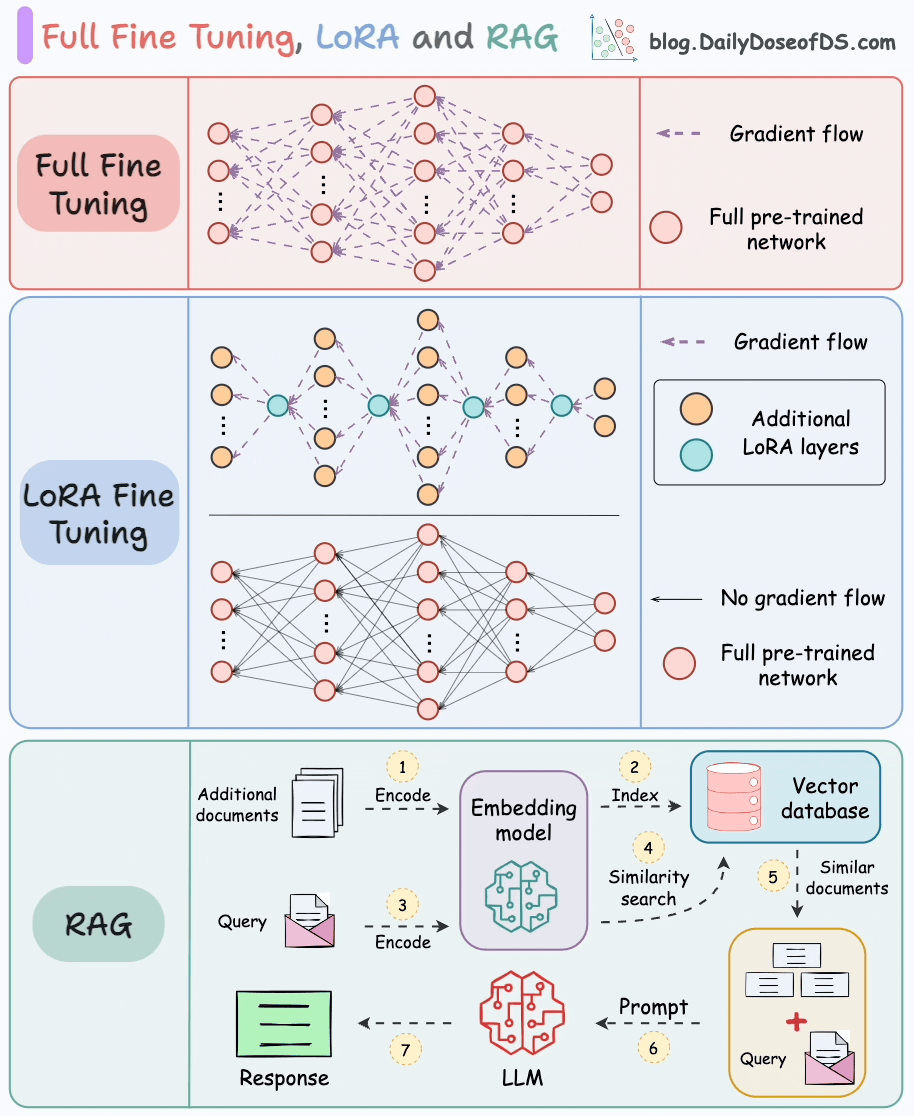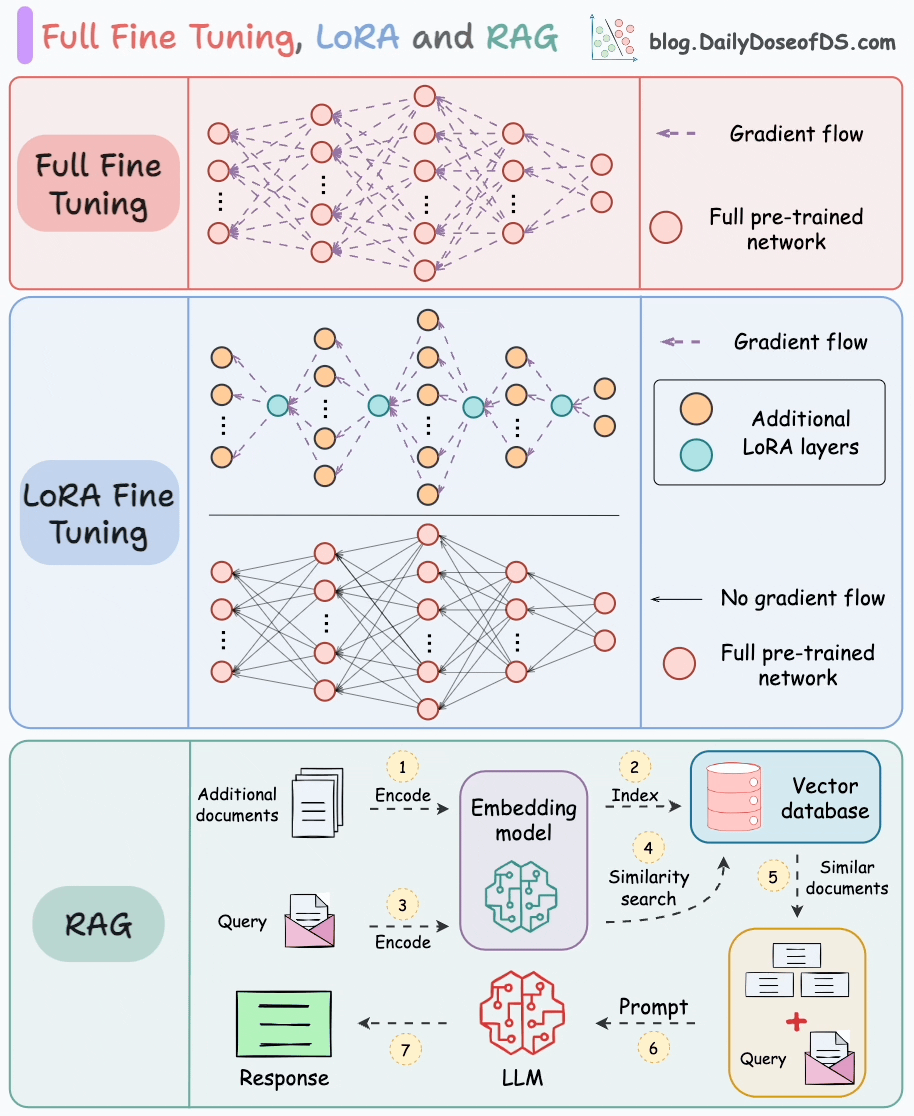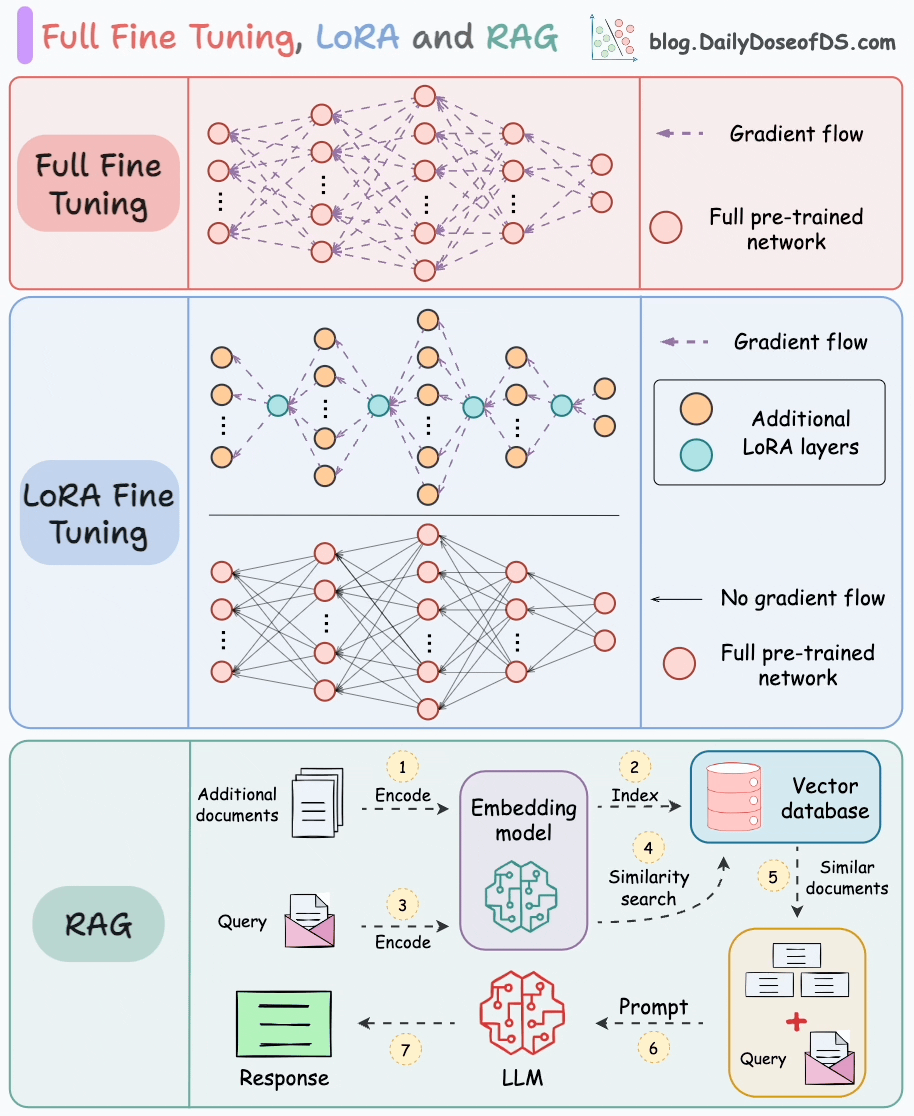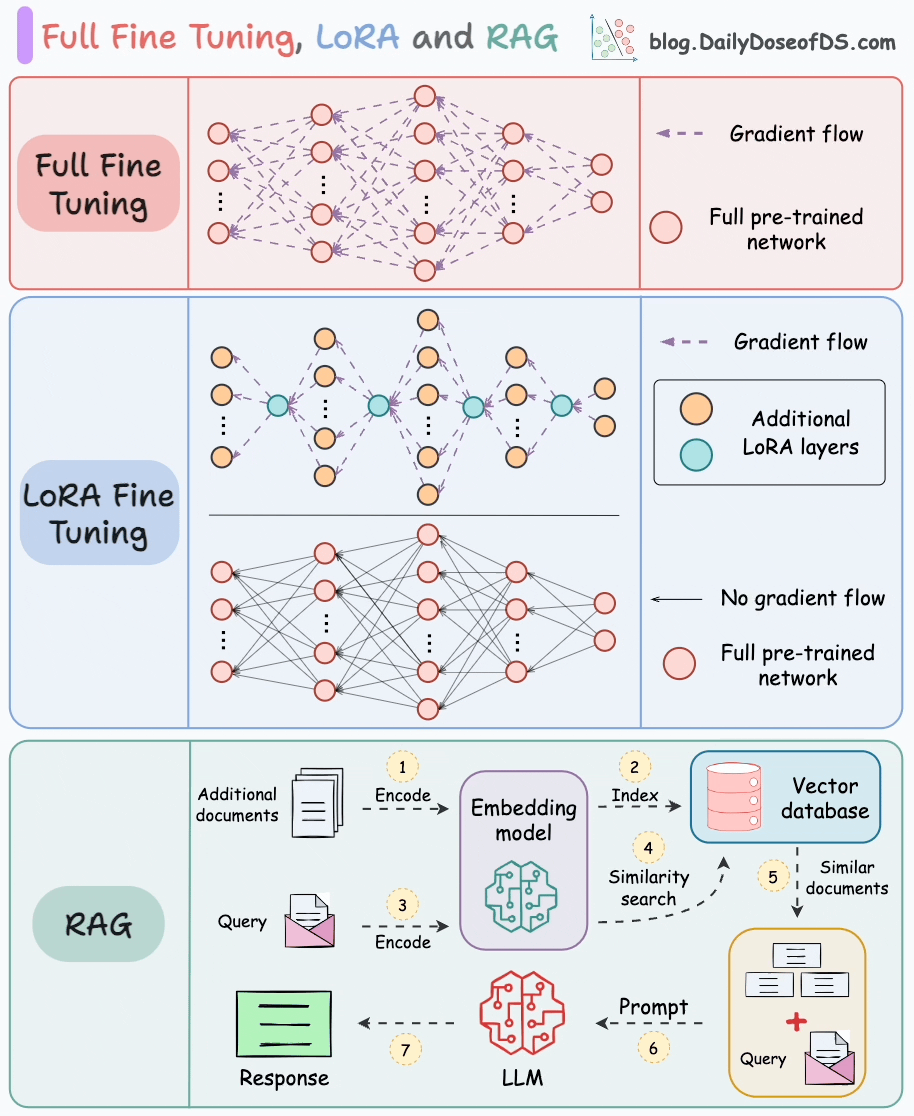
Avi Chawla. Full Model Fine-Tuning vs LoRA vs QLoRA. Daily Dose of Data Science, 2025. Available at: https://blog.dailydoseofds.com/p/full-model-fine-tuning-vs-lora-vs
Practice
Theory vs practice
Theory is when we know everything, but nothing works!
Practice is when everything works, and no one knows why.
In this room, we combine theory with practice.
Nothing works, and no one knows why.
- prof. Jan Miodek
Demo time!
Let's see how it is going!
Practice is hard


Requirements
- Model - The best (according to Internet) model generate images is FLUX.1-dev model created by Black Forest Labs:
- This model CANNOT be used in commercial projects, but there are versions which allows that
- Trening - Internet says that LoRA (whatever 😉) is good enough
- NVIDIA card with 16-24 GB VRAM
- Disk:
- 24 GB for FLUX.1-dev
- 10-30 GB for "python & stuff"
FLUX.1 familly
ELO score from 01-10-2024
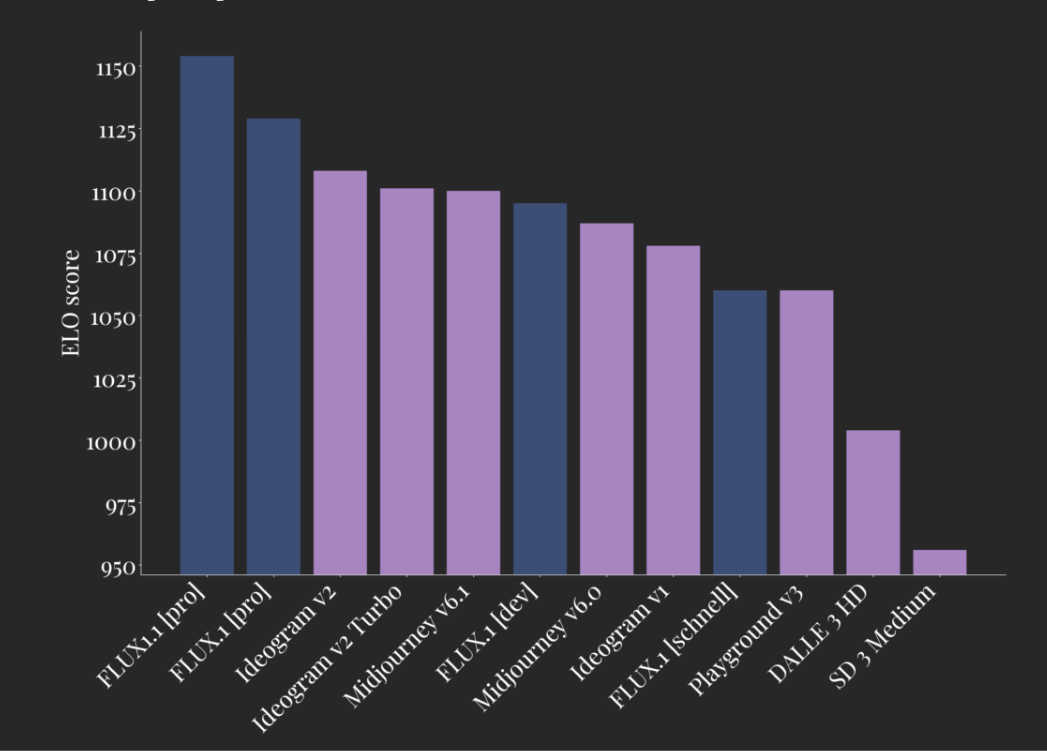
FLUX.1-dev
Current:
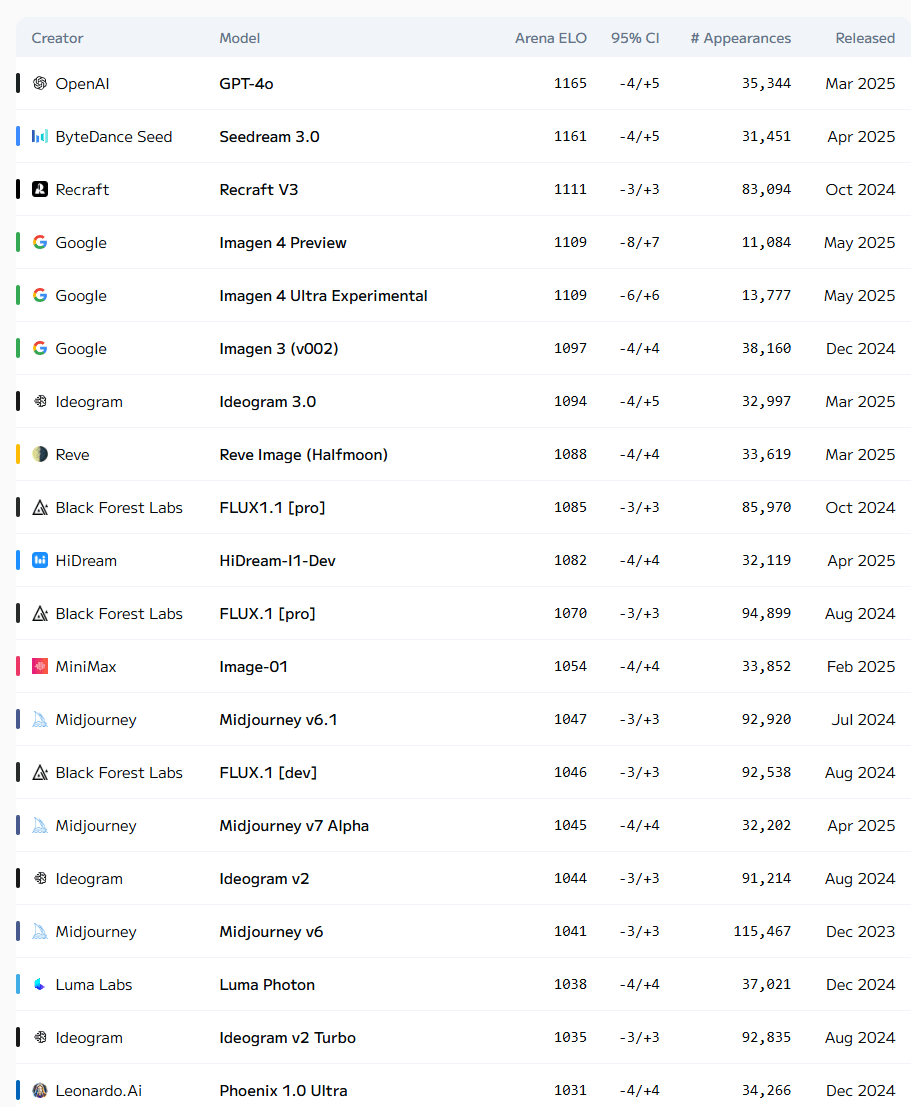
Requirements

Requirements
PyTorch-crucial framework
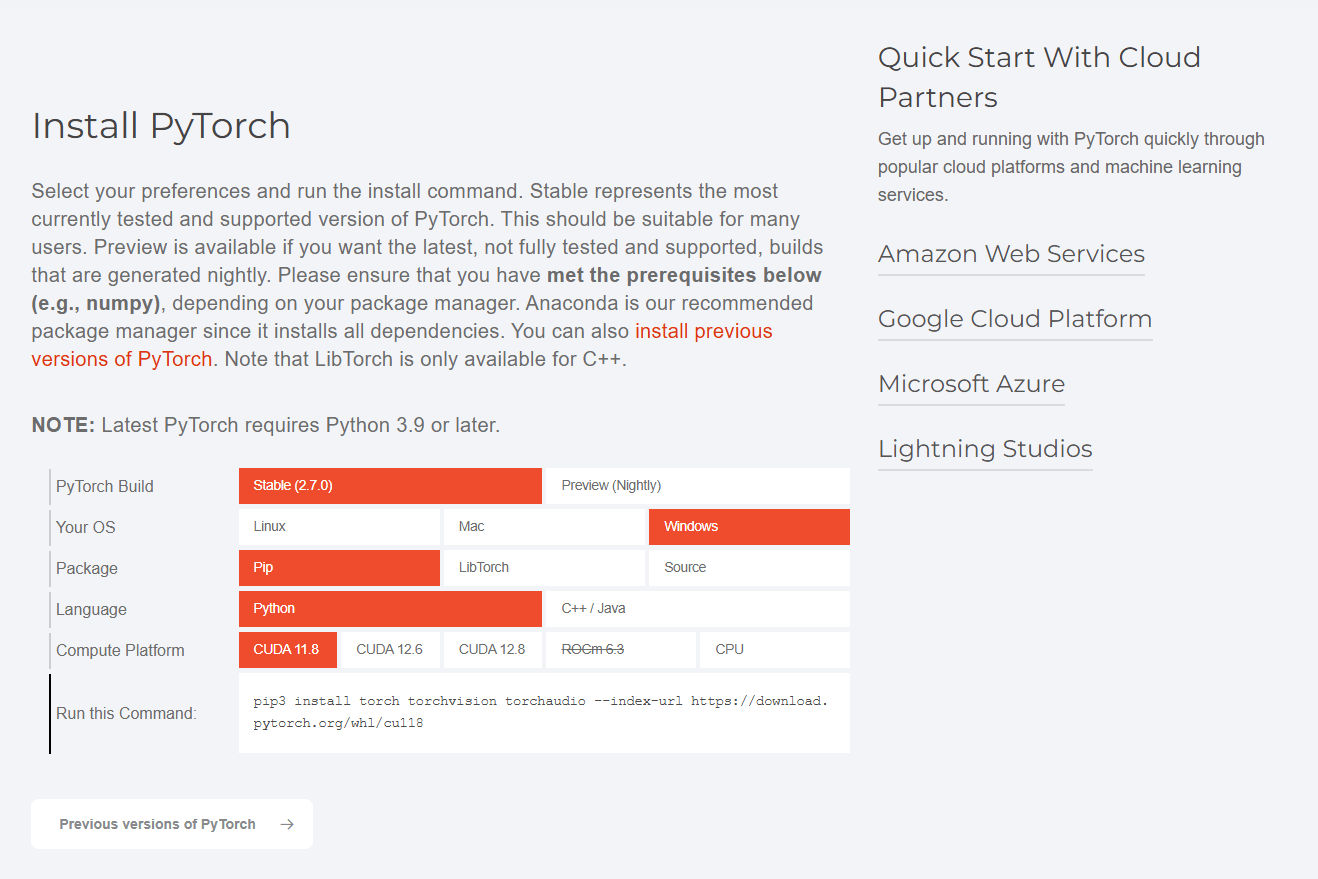
How to start? (1/3)
- frequent updates (last from 2025-03-01)
-
Supports:
- DreamBooth training
- Fine-tuning (native training)
- LoRA training
- Textual Inversion training
- Image generation
- Model conversion (supports 1.x and 2.x, Stable Diffision ckpt/safetensors and Diffusers)
- Works with low VRAM
How to start? (2/3)
- similar to previous
- TBH: I failed with this one, but I didn't spend a lot of time on it - VRAM problems - 16 GB vs 24 GB
- only FLUX models
How to start? (3/3)
- Simple UI over Kohya Scripts
- Generates shell script (see demo)
- Supports only Flux models
My machine
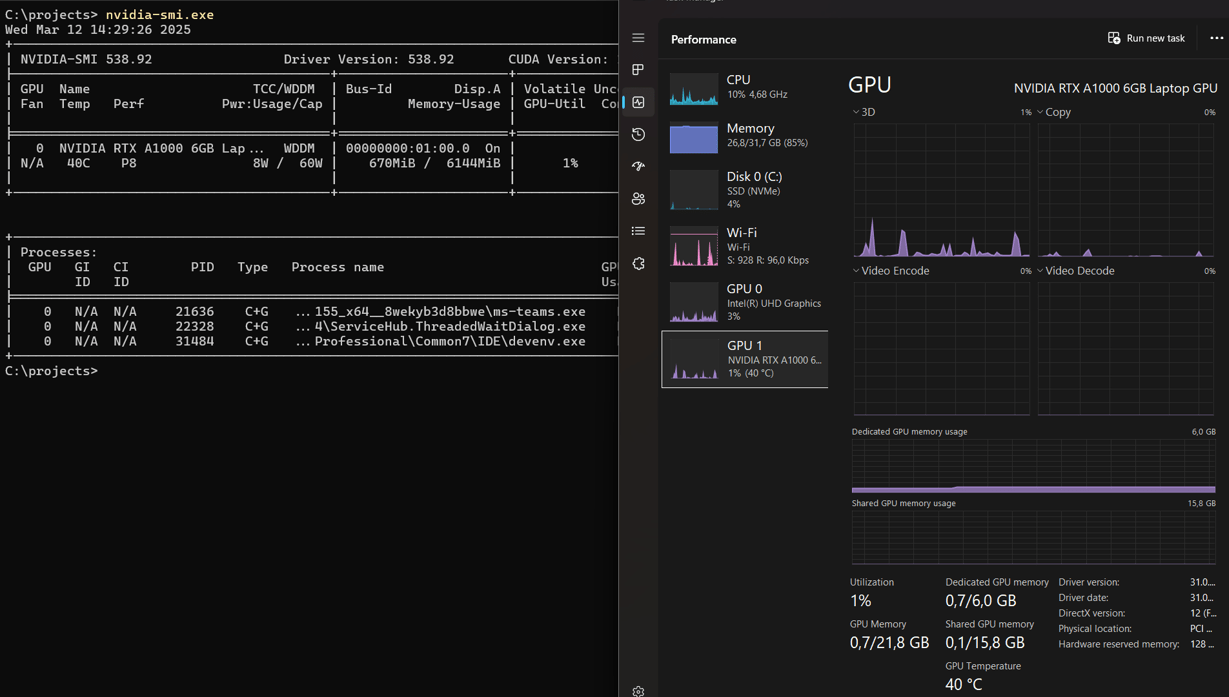
Results on my machine
- After 14 hours – 80 iterations out of 1600
- First simple images (each 20 iterations) – rather poor than good
- I stopped and decided to use cloud instead
Cloud FTW
- A lot of options including GPU per minute
- In my case - Standard NC24ads A100 v4
- Azure - Sweden Cental (Zone 3)
- 24 vcpus, 220 GiB memory
- Nvidia PCIe A100 GPU (80GB)
- ~ 5$ per hour - on demand
- ~ 1$ per hour - spot
- VS Code remote 😎
NVIDIA <3 Linux?

NVIDIA <3 Linux?
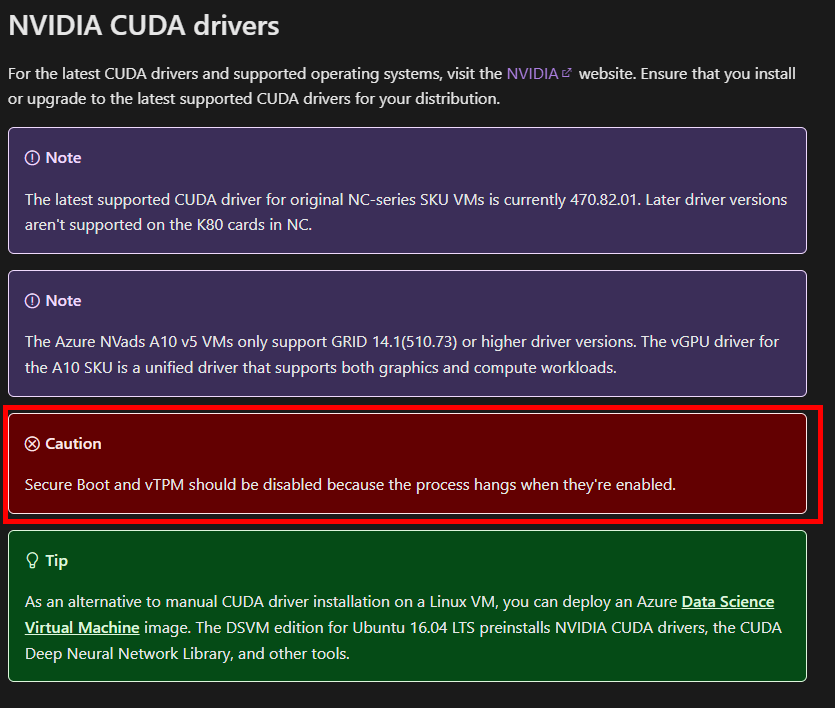
Demo
fluxgym
Safetensors files
A .safetensors file is a secure and efficient format for storing tensors - multi-dimensional arrays used in machine learning models.
It was developed as a safer alternative to the traditional PyTorch .pt or .pth files.
Safetensors files
- Key Features of .safetensors:
- Safe: It avoids arbitrary code execution during loading, which can be a risk with .pt files. This makes it more secure, especially when downloading models from the internet.
- Fast: It supports memory-mapped loading, which allows models to be loaded faster and with lower memory usage.
- Portable: It’s a binary format that can be used across different platforms and frameworks.
Data is the key!
First traning
- I prepared 10 images of myself
- Different poses
- Different lights
- [...]
- Everything as YouTube, websites, etc. suggested
Testing prompts
- stapp holding a sign that says 'I LOVE PROMPTS!'
- photo of a stapp, white background, profile photo, sun in the background
- photo of a stapp in superman costume, flying in the sky
Some results






Only one question
???WTF???
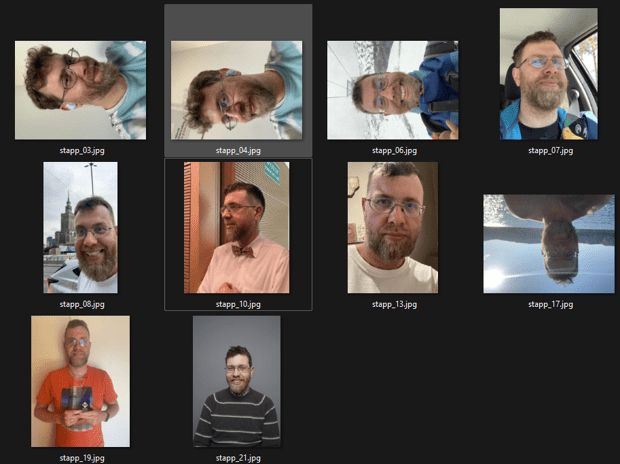
My first dataset
Generating
Code FTW
from diffusers import FluxPipeline
import torch, os, datetime
from dotenv import load_dotenv
def load_model(model_name, safetensor_path=None):
load_dotenv()
pipeline = FluxPipeline.from_pretrained(
model_name,token=os.getenv("HF_TOKEN"),torch_dtype=torch.float16)
pipeline.load_lora_weights(".", weight_name=safetensor_path)
pipeline = pipeline.to("cuda" if torch.cuda.is_available() else "cpu")
return pipeline
def main():
input_text = "A stapp as superman."
pipeline = load_model("black-forest-labs/FLUX.1-dev", "./lora/stapp-v1.safetensors")
for i in range(3):
time=datetime.datetime.now().strftime('%Y%m%d_%H%M%S')
output_image_path = f"output/generated_image_{time}_{i}.png"
pipeline(input_text).images[0].save(output_image_path)
print(f"Image generated and saved to {output_image_path}")
if __name__ == "__main__":
main()Examples
Prompting is still the key!
Stapp as Captain America

Prompting is still the key!
Stapp as Captain America

Prompting is still the key!
Stapp wearing glasses as Captain America, in a dynamic full-body pose, holding a large shield. Dark-blue, high-tech costume with star-patterned chest, hints of bronze. Helmeted, serious expression. Dramatic sunset sky with dark clouds. Shield is wooden-toned with cream bands and central star. Battlefield setting. Realistic lighting, photorealistic style. Heroic pose, strong posture, confident demeanor. Highly detailed, dramatic lighting.

Prompting is still the key!
Stapp wearing glasses as Captain America, in a dynamic full-body pose, holding a large shield. Dark-blue, high-tech costume with star-patterned chest, hints of bronze. Helmeted, serious expression. Dramatic sunset sky with dark clouds. Shield is wooden-toned with cream bands and central star. Battlefield setting. Realistic lighting, photorealistic style. Heroic pose, strong posture, confident demeanor. Highly detailed, dramatic lighting.

How to create a prompt?
- Using LLMs :)
- Or online: https://imageprompt.org/describe-image
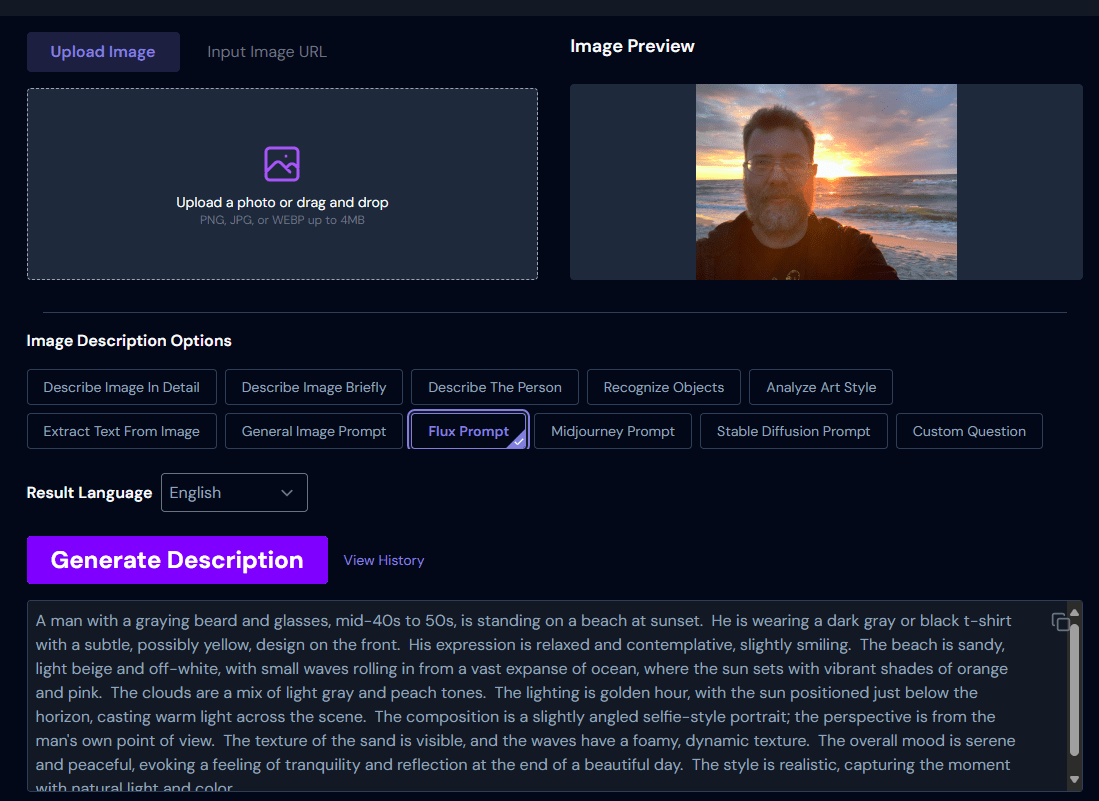
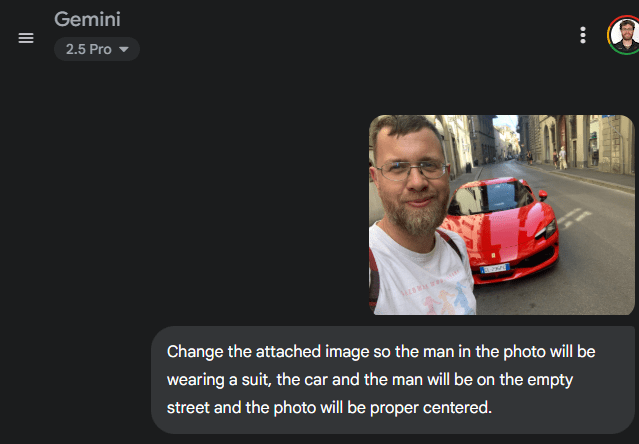
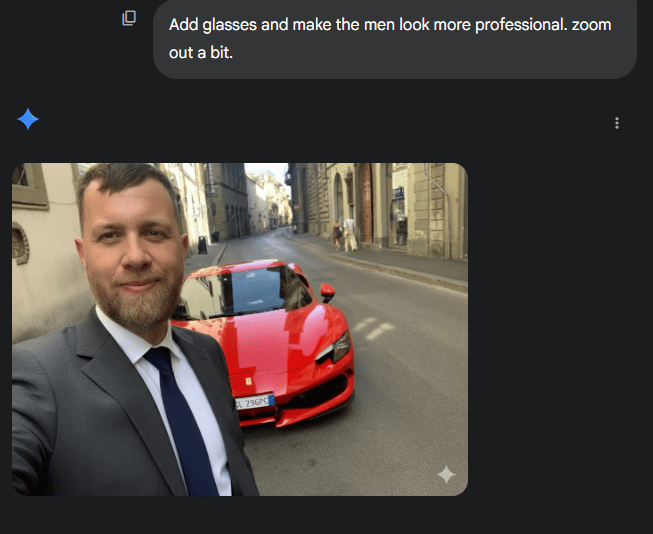
Demo time
input_text_short = "Stapp with Barack Obama"
input_text_long = "Stapp with Barack Obama in the White House, both smiling and shaking hands. The entire scene should be visible, capturing the moment of camaraderie and friendship."
----
python src/main-simple.pyExternal stuff
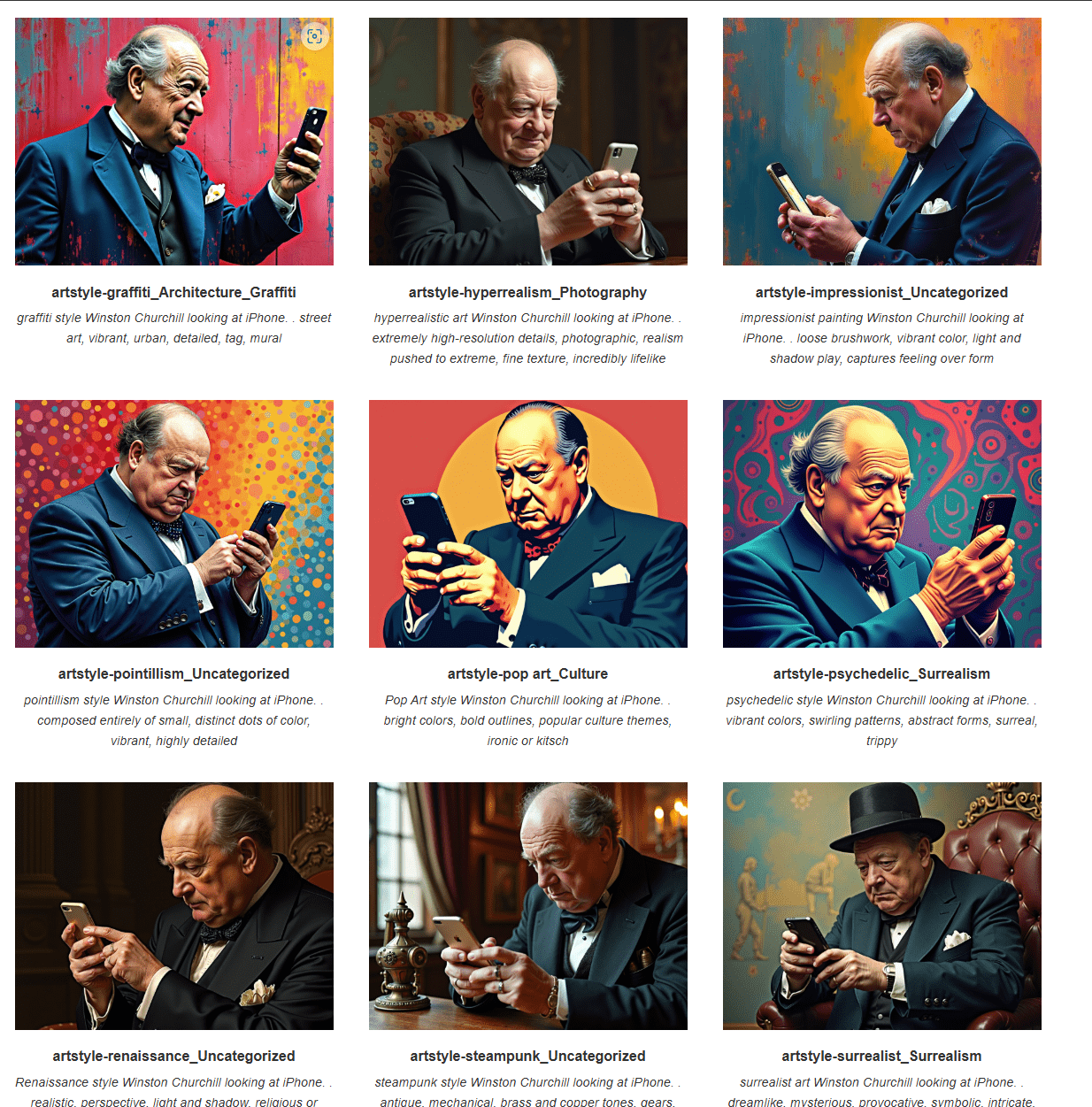
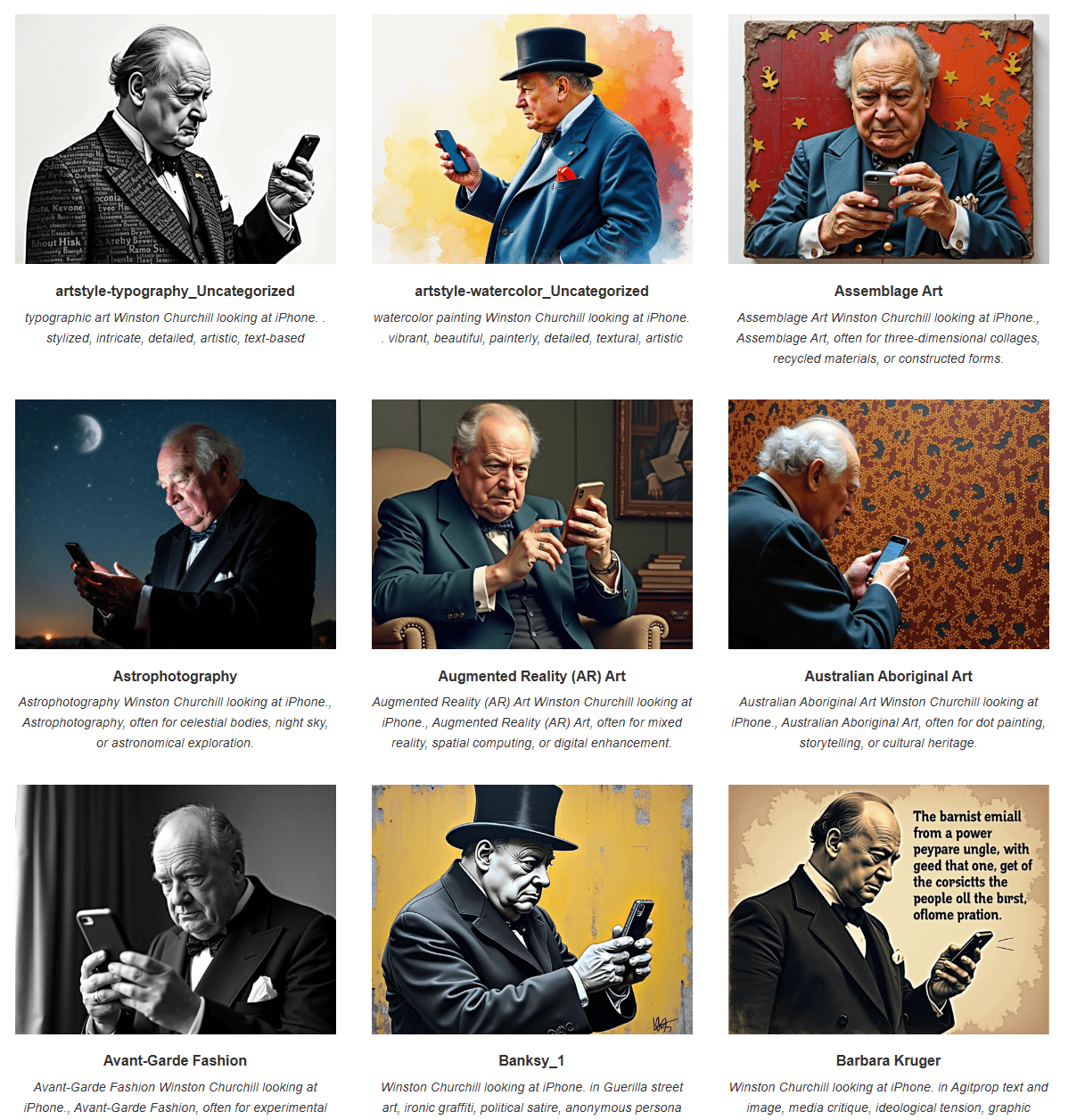
Different options
- LoRA can contain style instead of face :)
- There are a lot of possibilities included and available as LoRA
Built-in Styles
IKEA style

Demo mixing
stapp + ikea
# stapp lora
pipeline.load_lora_weights(
"./lora/stapp-v1.safetensors", weight_name="stapp.safetensors", adapter_name="stapp")
# IKEA lora
pipeline.load_lora_weights(
"./lora/ikea.safetensors", weight_name="ikea.safetensors", adapter_name="ikea")
pipeline.set_adapters(["stapp", "ikea"], adapter_weights=[0.9, 0.7])
Ghibli studio style


Demo
Ghibli studio
# LoRA Ghibli + stapp lora
python src/mmain-ghibli-mix.py
# plain LoRA Ghibli
python src/main-ghibli-plain.py
What about XXX?
A Critical Warning:
The Ease of Misuse and Societal Harm
Uncensored - FLUX + LoRA


Uncensored - plain FLUX


Demo? NO!
You can try it, but it won't be presented
# lora
python src/main-uncensored-lora.py
# plain flux
python src/main-uncensored-plain.py
Not enough time for this 😉
Fill or inpainting
- A way to replace or filling areas in the existing images
- Different models (e.g. FLUX.1-Fill-[dev] instead of FLUX.1-[dev])

DEMO - Fill or inpainting
python main_fill.pyimport torch
from diffusers import FluxFillPipeline
from diffusers.utils import load_image
from dotenv import load_dotenv
load_dotenv()
image = load_image("https://huggingface.co/datasets/diffusers/diffusers-images-docs/resolve/main/cup.png")
mask = load_image("https://huggingface.co/datasets/diffusers/diffusers-images-docs/resolve/main/cup_mask.png")
pipe = FluxFillPipeline.from_pretrained("black-forest-labs/FLUX.1-Fill-dev", torch_dtype=torch.bfloat16).to("cuda")
image = pipe(
prompt="a cup with a handle and NIKE logo",
image=image,
mask_image=mask,
height=1632,
width=1232,
guidance_scale=30,
num_inference_steps=50,
max_sequence_length=512,
generator=torch.Generator("cpu")#.manual_seed(0)
).images[0]
image.save(f"flux-fill-dev.png")
print("Successfully inpaint image")Image variations
- Flux models: FLUX.1-Redux - dev, schnell or pro
- But there are different too :)
Structural conditioning
- Uses canny edge or depth detection to maintain precise control during image transformations.
- Users can make text-guided edits while keeping the core composition intact

Multiple faces
- I'm still working on it, but results are just poor
- Combining LoRA is a bad idea
- Fill uses a different model
- It is easier to generate an alternative version of my children than me with my wife :)
Alternatives
GPT-image-1 supports multiple modalities and features:
- Text-to-image: Generate images from text prompts, similar to text2im in ChatGPT DALL-E.
- Image-to-image: Create new images from user-uploaded images and text prompts, a feature not available in ChatGPT DALL-E.
- Text transformation: Edit images using text prompts, akin to the transform feature in ChatGPT DALL-E.
- Inpainting: Edit images with text prompts and user-drawn bounding boxes, similar to inpainting with DALL-E.
GPT-image-1
Google Nano Banana

Video swap :)
The end?
References
-
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising Diffusion Probabilistic Models. arXiv preprint arXiv:2006.11239, 2020.
-
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-Resolution Image Synthesis with Latent Diffusion Models. arXiv preprint arXiv:2112.10752, 2021.
-
Dae-Young Kang, Hieu Pham Duong, and Jung-Chul Park. Application of Deep Learning in Dentistry and Implantology. Implantology, vol. 24, no. 3, 2020, pp. 148–181. arXiv
-
M. J. Cardoso, A. Li, A. D. McClure, et al. Deep learning tools for the cancer clinic: an open-source framework with head and neck contour validation. Radiation Oncology, 2022. Available at: https://www.researchgate.net/publication/358442721
-
https://learn.microsoft.com/en-us/azure/virtual-machines/linux/n-series-driver-setup
-
Flux Style Test Gallery - https://enragedantelope.github.io/Styles-FluxDev/
-
FLUX NSFW / Nude Prompts and Learnings - https://betterwaifu.com/blog/flux-nsfw
-
Nextusos/Flux-Uncensored-V2 - https://github.com/Nextusos/Flux-Uncensored-V2
-
Flux docs - https://github.com/black-forest-labs/flux
-
photo AI (my repo) - https://github.com/ptrstpp950/photoAi
-
Live Portrait - https://huggingface.co/spaces/KwaiVGI/LivePortrait
-
Hugging Face - https://huggingface.co/
The cost of a lie:
$5 and a few photos
- With just $5–$10 and a few poor-quality images, anyone - even teens - can make fake content.
- That’s why it’s so important to talk to your kids and other young people in your life, like cousins, nieces, nephews, or your friends’ kids.
- A quick conversation can make a big difference.

👇Slides, links & feedback 👇

https://linktr.ee/piotr.stapp
- https://www.linkedin.com/feed/update/urn:li:activity:7322896120173543424?utm_source=share&utm_medium=member_desktop&rcm=ACoAAAFoowoBfnkasuJGcMK36PzbSnYIZLkUE4A
- https://www.linkedin.com/posts/genai-works_artificialintelligence-promptengineering-activity-7324342617985413120-Ve-8/?utm_source=share&utm_medium=member_ios&rcm=ACoAAAFoowoBfnkasuJGcMK36PzbSnYIZLkUE4A
- https://x.com/godofprompt/status/1911839239823581467
- https://www.brainyquote.com/quotes/brian_odriscoll_680037
From Selfie to AI
By Piotr Stapp



