


































procon2019
このアカウントは京大マイコンクラブ(KMC)の2019年度の競技プログラミング練習会Normal(初心者向け)での説明用に作成したスライドです。 閲覧・参照はご自由にどうぞ。
第7回 グラフ表現,構造体, Union-Find木
担当 : laft
KMC-ID:laft
こんなの→
有向グラフ
無向グラフ
G=(V,E)
G=(V,E)
2の入次数は2
2の出次数は1
道{4,5,2,1,4}
葉
葉
葉
葉
葉
葉
根
さっきの木の図で2を根にした
サイズ\(|V|\times |V|\)の二次元配列\(A=a_{uv}\)
const int INF = 1e7; //とても大きい値を無限としておく。
int V,E;
cin >> V >> E; //Vは与えられた頂点数,Eは辺の数
vector<vector<int>> a(V,vector<int>(V,INF));//V*Vを無限で初期化
for(int i=0;i<E;++i){
//s→tへの有向辺として入力が与えられたとする。//wは重み
int s,t; //,w
cin >> s >> t; //>>w
a[s][t] = 1; //a[s][t] = w;
//a[t][s] = 1; (s-tの無向辺の場合)
}有向辺の時はa[s][t]をs→tと設定しよう。
無向辺の時は逆向きにも有向辺を張って対応しよう
サイズ\(|V|\)の配列\(A=a_{u}\)
{uと隣接してる頂点たち}
a[1] = {2,4}
a[2] = {3,4,5}
a[3] = {2,4}
a[4] = {1,2,3,5}
a[5] = {2,4}
int V,E;
cin >> V >> E; //Vは与えられた頂点数,Eは辺の数
vector<vector<int>> a(V);//V個の空ベクトルを含むベクトル
for(int i=0;i<E;++i){
//s→tへの有向辺として入力が与えられたとする。
int s,t;
cin >> s >> t;
a[s].push_back(t);
//a[t].push_back(s); (s-tの無向辺の場合)
}このとき、a[u]にはuと隣接している頂点の配列が入っている。
サイズ\(|E|\)の集合\(A\)
{辺の頂点のペア(u,v)たち}
サイズ\(|V|\times |E|\)の二次元配列\(A=a_{ve}\)
サイズ\(|V|\times |V|\)の二次元配列\(A=a_{uv}\)
struct person{
string name;
int age;
void hoge(){}
};struct person{
string name;
int age;
};
int main(){
person p;
p.name = "Mike";
p.age = 29;
cout << p.name << " " << p.name << endl;
}Mike 29
出力:
struct person{
string name;
int age;
void print(){
cout << name << " " << age << endl;
}
};
int main(){
person p;
p.name = "Mike";
p.age = 29;
p.print();
}Mike 29
出力:
struct person{
string name;
int age;
};
int main(){
person p = {"Mike",29};
cout << p.name << " " << p.name << endl;
}Mike 29
出力:
struct person{
string name;
int age;
};
int main(){
person p = {"laft",19};
person q = p;
cout << q.name << " " << q.age << endl;
}laft 19
出力:
struct person{
string name;
int age;
person(string s,int a){
name = s;
age = a;
}
};
int main(){
person p("laft",19);
cout << p.name << " " << p.age << endl;
}laft 19
出力:
struct person{
string name;
int age;
};
int main(){
vector<person> ps(1); //サイズ1のpersonのvectorを宣言
ps[0] = {"aotsuki",21}; //代入
ps.push_back(person{"laft",19}); //push_back!!
cout << ps[0].name << " " << ps[1].name;
}aotsuki laft
出力:
struct edge{
int to,weight;
};
int main(){
int V,E; cin >> V >> E; //Vは与えられた頂点数,Eは辺の数
vector<vector<edge>> a(V);//V個の空ベクトルを含むベクトル
for(int i=0;i<E;++i){
//s→tへの有向辺で重みwとして入力が与えられたとする。
int s,t,w; cin >> s >> t >> w;
a[s].push_back(edge{t,w});
}
}struct person{
string name;
int age;
};
int main(){
vector<person> ps;
// ... (psに入力などしたとする)
auto itr = ps.begin();
//itr->nameは(*itr).nameと同じ
cout << itr -> name << endl;
}struct person{
string name;
int age;
//person(string s,int a){name=s;age=s;}と等価
person(string s,int a):name(s),age(a){}
};
int main(){
person p("laft",19);
cout << p.name << " " << p.age << endl;
}こっちを使う利点は競プロではそんなにないけど、人のコードを見るとき用に知っておこう。
struct person{
string name;
int age;
person(string s,int a):name(s),age(a){}
};
int main(){
person p("laft",19);
p = person("aotsuki",21);
cout << p.name << endl;
}aotsuki
出力:
struct person{
string name;
int age;
person(string s,int a):name(s),age(a){}
};
int main(){
vector<person> ps;
ps.push_back(person("laft",19));
cout << ps[0].name << endl;
}laft
出力:
struct person{
string name;
int age;
person(string s,int a):name(s),age(a){}
};
int main(){
person q = person("aotsuki",21);//これはok
person p; //error,初期値が分からないため
p = person("laft",19);
}struct person{
string name;
int age;
//person(string s,int a):name(s),age(a){}
};
int main(){
person p; //ok,初期値は暗黙的に代入される
p = {"laft",19};//コンストラクタは宣言してないので
cout << p.name << endl;
}laft
出力:
struct person{
string name;
int age;
person(string s,int a):name(s),age(a){}
};
int main(){
vector<person> ps(3); //error!3つの要素に初期値を与えられない
vector<person> ps(3,person("laft",19)) //ok!初期値を指定してる
vector<person> ps; //ok! 要素がないので初期値問題は発生しない
vector<vector<person>> pss(3) //ok! 要素の3つのvectorに要素はない
}struct person{
string name;
int age;
person(string s,int a):name(s),age(a){}
person():name(""),age(0){}
};
int main(){
person p; //ok,初期値は明示的に代入される
p = person("laft",19);
cout << p.name << endl;
}laft
出力:
int sub(int a=0,int b=0){
return a-b;
}
int main(){
cout << sub(3,5) << " " << sub(3) << " " << sub() << endl;
// 3-5=-2 3-0=3 0-0=0
}-2 3 0
出力:
int sub(int a=0,int b){ //error
return a-b;
}
int sub(int a,int b=0){ //ok!
return a-b;
}
int sub(int a=0,int b=0){ //もちろんok!
return a-b;
}struct person{
string name;
int age;
person(string s="",int a=0):name(s),age(a){}
};
int main(){
person p; //ok,初期値は明示的に代入される
p = person("laft",19);
cout << p.name << endl;
}struct person{
string name;
int age;
person(string s="",int a=0):name(s),age(a){}
};
int main(){
vector<person> ps;
//...(入力なり代入なりしたとしよう)
sort(ps.begin(),ps.end()) //error!何が小さいか分からない
}struct person{
//省略
};
//名前がstring的に小さい時にtrue,名前が同じなら年齢が低いときにtrueを返す。
//そうでない時にはfalseを返す。このような関数を比較関数という。
bool lessper(person left,person right){
if(left.name==right.name) return left.age<right.age;
return left.name < right.name;
}
int main(){
vector<person> ps;
//...(入力なり代入なりしたとしよう)
sort(ps.begin(),ps.end(),lessper) //ok!何が小さいか定義ずみ!
}struct person{
//(ry
};
bool operator<(person left,person right){
if(left.name==right.name) return left.age<right.age;
return left.name < right.name;
}
int main(){
vector<person> ps;
//...(入力なり代入なりしたとしよう)
priority_queue<person> q; //ok!下に同じ!
sort(ps.begin(),ps.end()) //ok!何が小さい定義ずみ!
}priority_queue<int,vector<int>,greater<>> pq;
struct person{
//(ry
};
bool operator>(person left,person right){
if(left.name==right.name) return left.age>right.age;
return left.name > right.name;
}
int main(){
vector<person> ps;
//...(入力なり代入なりしたとしよう)
priority_queue<person,vector<person>,greter<>> q; //ok!下に同じ!
sort(ps.begin(),ps.end(),greater<>()) //ok!何が大きいか定義ずみ!
}struct person{
string name;
int age;
person(string s="",int a=0):name(s),age(a){
birthyear = 2019-age;
}
int get_birthyear(){
return birthyear;
}
private:
int birthyear;
};
int main(){
person p("laft",19);
cout << p.birthyear << endl; //error!外部からprivateにアクセスできない
cout << p.get_birthyear() << endl; //ok!
}//以下は今まで使ってた構造体と全く等価。
class person{
public:
string name;
int age;
person(string s="",int a=0):name(s),age(a){}
};
AtCoder Typical Contest 001 B(改題)
連結:1,3
これを……
連結:1,3
こう
判定:2,6
判定:2,6
同じグループ!
よって"Yes"を出力
判定:1,4
判定:1,4
違うグループ!
よって"No"を出力
配列を用意して、その配列に情報を入れる
| 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|
| 1 | 2 | 2 | 3 | 1 | 2 |
グループ1
グループ2
グループ3
| 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|
| 1 | 2 | 2 | 3 | 1 | 2 |
グループ1
グループ2
グループ3
例えば連結クエリ:1,3の時にこの配列を全て見て、1→2にするという処理が必要
よって連結クエリで\(O(N)\)
全体で最悪\(O(NQ)\)間に合わない…
赤い頂点が根
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 3 | 3 | 4 | 4 | 7 | 2 | 1 | 5 | 5 |
各頂点の親を入れた配列par
struct union_find_tree1{
vector<int> par;//0-indexed
union_find_tree1(int sz){ //コンストラクタ
par.resize(sz); //サイズをszに変更
for(int i=0;i<sz;++i) par[i] = i; //最初は自分が根
}
int find(int a){
while(a!=par[a]){ //親が自分自身の時、自分が根である
a = par[a]; //そうでないなら自分に親を代入して辿る
}
return a; //引数aの根が計算されたのでそれを返す。
}
void unite(int a,int b){
int root_a = find(a),root_b = find(b); //aの根,bの根を調べて代入。
par[root_a] = root_b; //根aの親をbにする
}
bool same(int a,int b){ //aとbが同じ集合なら1,違うなら0
return find(a)==find(b);
}
};
int main(){ //雑だけど、構造体の使い方の例を載せときます
int sz = 10;
union_find_tree1 uf(sz); //union_find木の変数ufをサイズszで宣言
uf.unite(1,2); //頂点1と2をunite
if(uf.same(2,3)) puts("Yes"); //2と3が同じならYes
}
struct union_find_tree1{
vector<int> par;//0-indexed
union_find_tree1(int sz){
par.resize(sz); //サイズをszに変更
for(int i=0;i<sz;++i) par[i] = i; //最初は自分が根
}
int find(int a){
if(a==par[a]) return a; //親が自分自身の時、自分が根である
else return find(par[a]); //そうでないなら自分に親を代入して辿る
}
void unite(int a,int b){
int root_a = find(a),root_b = find(b); //aの根,bの根を調べて代入。
par[root_a] = root_b; //根aの親をbにする
}
bool same(int a,int b){
return find(a)==find(b);
}
};
遅い!!!
というわけで高速化します。
十分速いけど、まだ高速化できる!
struct union_find2_1{//rankで高速化
vector<int> par;//parは添字の親(または自分が根の時自身)を示す。
vector<int> rank;//rankは木の高さ(根についてのみ実装)
union_find2_1(int sz){
par.resize(sz);
rank.assign(sz,0);
for(int i=0;i<sz;++i) par[i]=i;
}
int find(int a){//根を探す
if(par[a]==a) return a;
else return find(par[a]);
}
void unite(int a,int b){//小さい方の木の根に大きい方の根を上書きする
int root_a = find(a),root_b = find(b);
if(root_a==root_b) return; //既に同じなら終了
if(rank[root_a]>rank[root_b]){
par[root_b] = root_a;
}else if(rank[root_a]<rank[root_b]){
par[root_a] = root_b;
}else{
rank[root_a]++;
par[root_b] = root_a;
}
}
};これは償却計算量(計算量の平均みたいな)
なんでこうなるのかは難しいらしい…
僕は知らないので、興味ある人は調べてみてね
struct union_find2_2{//経路圧縮で高速化
vector<int> par;//parは添字の親(または自分が根の時自身)を示す。
union_find2_2(int sz){
par.resize(sz);
for(int i=0;i<sz;++i) par[i]=i;
}
int find(int a){//根を探す
if(par[a]==a) return a;
else return par[a] = find(par[a]); //経路圧縮!!!
}
void unite(int a,int b){
int root_a = find(a),root_b = find(b); //aの根,bの根を調べて代入。
par[root_a] = root_b; //根aの親をbにする
}
bool same(int a,int b){
return find(a)==find(b);
}
};これも償却計算量(計算量の平均みたいな)
struct union_find{//rank,経路圧縮で高速化
vector<int> par;//parは添字の親(または自分が根の時自身)を示す。
vector<int> rank;//rankは木の高さ(根についてのみ実装,0-indexed)
union_find(int sz){//コンストラクタ,sz個のノードを作成し、自分を親につける
par.resize(sz);
rank.assign(sz,0); //rankは最初0
for(int i = 0;i < sz;++i) par[i]=i;
}
int find(int a){//根を探す
if(par[a]==a) return a; //親が自身を指す時、根である
else return par[a] = find(par[a]);//根に直接つける
}
void unite(int a,int b){//小さい方の木の根に大きい方の根を上書きする
int root_a,root_b;
root_a = find(a),root_b = find(b);
if(rank[root_a]>rank[root_b]){ //rankの高い方の根に低い方の根をつける
par[root_b] = root_a;
}else if(rank[root_a]<rank[root_b]){
par[root_a] = root_b;
}else{ //rankが同じ時、適当な方につけ、つけられた方のrankを1増やす
rank[root_a]++;
par[root_b] = root_a;
}
}
bool same(int a,int b){return find(a)==find(b);}
};vector<ll> par;
ll root(ll x){
if (par[x] == x){ //根
return x;
}
else {
return par[x] = root(par[x]); //経路圧縮
}
}
void unite(ll x,ll y){
x = root(x);
y = root(y);
if (x == y){}
else{
par[x] = y; //xの親をyの親にする
}
}
ll same(ll x,ll y){
return root(x) == root(y);
}
int main(){
ll n;
cin>>n;
par.assign(n,0);
for(ll i=0;i<n;i++){
par[i]=i;
}
}
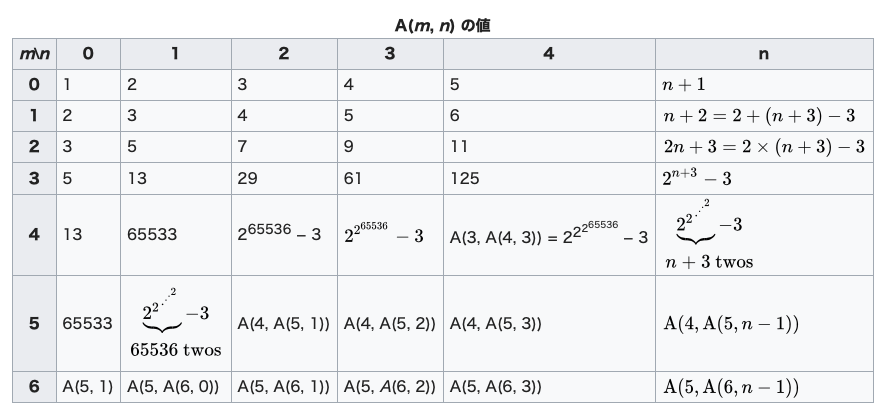
\(\alpha(n)\)はA(n,n)の逆関数
つまりは高々4
定義とかは暇な時にでも自分で見てね
http://judge.u-aizu.ac.jp/onlinejudge/index.jsp?lang=ja
もしくは
「 AOJ 」で検索
By procon2019
発表日時 2019年5月31日(金) 18:30-21:00 https://onlinejudge.u-aizu.ac.jp/beta/room.html#kmc2019_n_7



