DISTRIBUTED Analytics system for arabic search engines users' data using ASSOCIATIVE Classification mining
Ramzi Alqrainy
Opensooq.com
agenda
· Motivation
· Contributions
· DAS Architecture
(Components, Algorithms, and Analysis)
· Experimentation Setup and Results
· The Performance of DAS Under Failure Scenarios
· Conclusion and Future Work
· References
Data is the new oil
-
Today, the information stored in digital data archives is enormous and its size is still growing very rapidly.
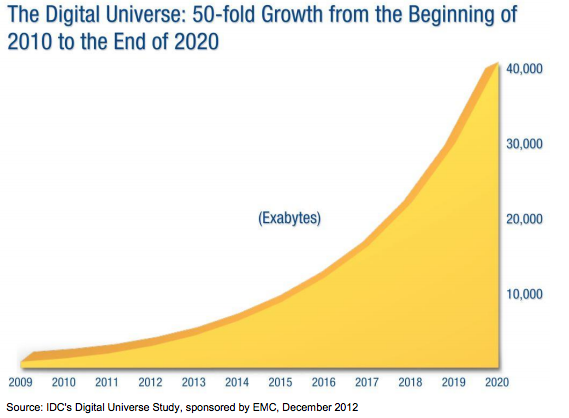
DATA IS THE NEW OIL
- The main problem is not storing DATA, it is analyzing, mining, and processing DATA . [Talia, 2012]
- Bigger and more complex problems must be solved by distributed computing.
DAS for arabic search engine
- is the study of the behavior of searcher.
- Main Features :
- Measurement of Arabic Search Engines (Precision, Recall, and F-measure)
- Personalized Arabic Search
- Statistical Report Analysis based on Associative Classification Mining (ACM)
Contributions
- Designing and implementing a distributed system for analyzing big Arabic data.
- Implementing Arabic Statistical Report Analysis based on Associative Classification Mining (ACM)
- Implementing algorithms for pre-processing Arabic events
- Normalization
- Light Stemming
- Stopwords
- Synonyms
- Handling some server failure scenarios .
Contributions (cont.)
- Using Apache Lucene and Apache Zookeeper.
- Evaluating The speed of DAS analytically .
- Comparing with Elasticsearch in terms of Index Size, Speed, Throughput, CPU Utilization, RAM Usage, Transfer Rate, and Failed Requests .
- Studying the DAS speedup .
DAS ARCHITECTURE
DAS Architecture
DAS consists of 3 subsystems :
1. Logging and Archiving Sub system (LAS)
2. Analytics Sub system (AS)
3. User Interface (UI)
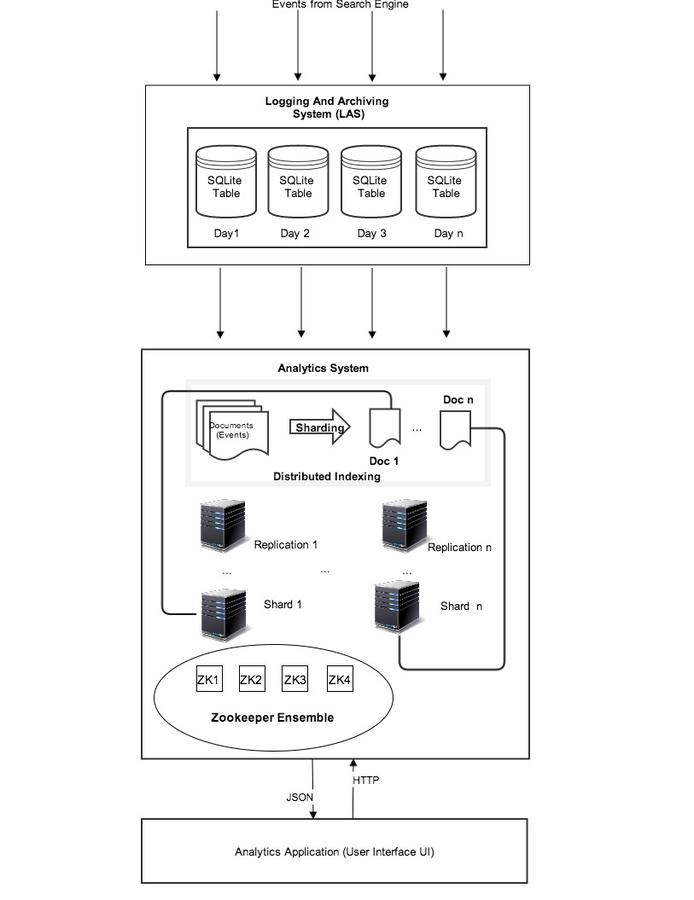
LAS
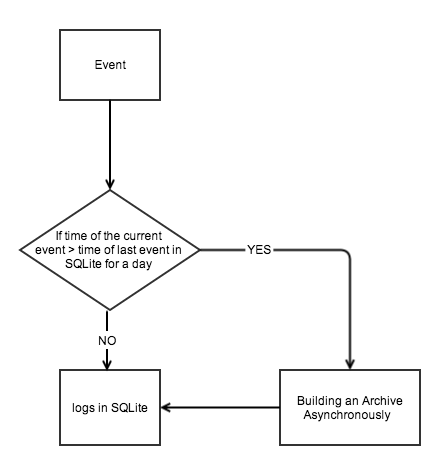
- Written in Python and SQLite.
- The events are stored in separate table, one table per day.
AS
- Distributed system written in JAVA 8
- Based on Apache Lucene.
- Uses Apache Zookeeper
- Preprocessing Arabic Events
- There are 2 main processes : Distributed Indexing and Distributed Requesting.
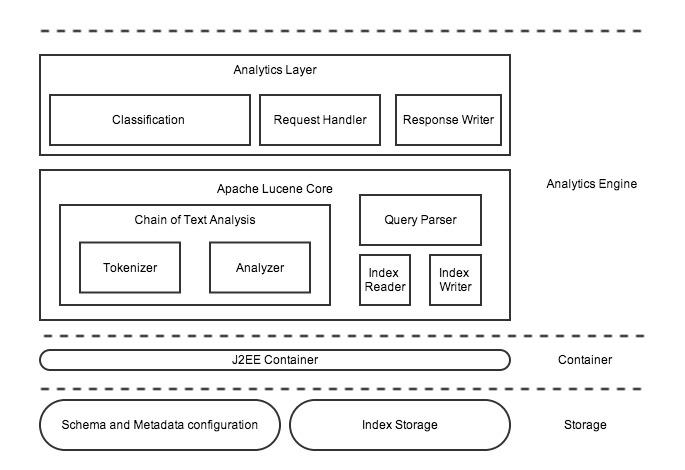
Apache lucene
Apache Lucene is a free/open source information retrieval software library, originally written in Java by Doug Cutting.
- Lucene Index Overview [McCandless, 2010]
- A Lucene index covers a set of documents
- A document is a sequence of fields
- A field is a sequence of terms
- A term is a text string
- A Lucene index consists of one or more segments
- Each segment covers a set of documents
- Each segment is a fully independent index
Classification by Association Rule Analysis on lucene
- There are 2 main methods are implemented in Lucene
- Classification-Based Association (CBA)
- Classification based on Multiple Association Rules (CMAR)
Preprocessing Arabic events
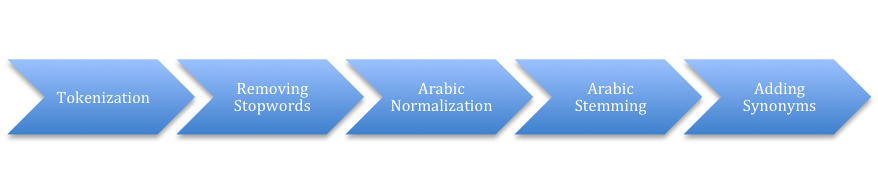
Arabic normalization and light stemming alg.
-
Remove punctuation marks.
-
Remove diacritics (such as شده ، ضمه ، فتحه).
-
Remove non letters .
-
Replace أ،إ،ا with ا.
-
Replace final ى with ي.
-
Replace final ةwith ه.
- Remove prefix فال ، و، ال ، وال ، بال .
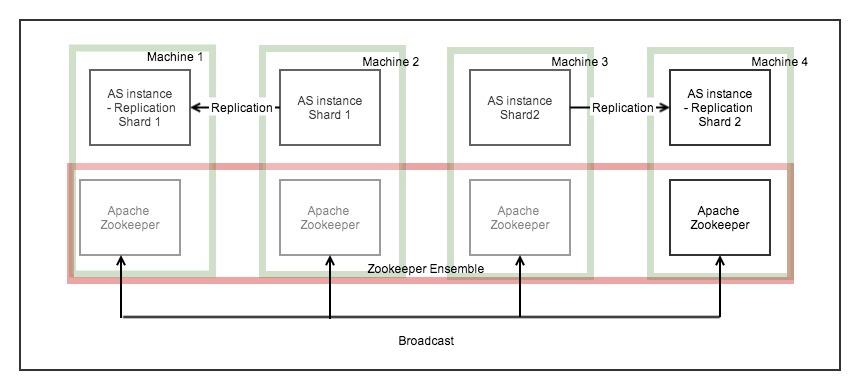
Apache zookeeper
ZooKeeper is a service for maintaining configuration information, naming, and providing distributed synchronization.
DAS uses ZooKeeper as a system of record for the cluster state, for central config, and for leader election. [Junqueira, 2013]
AS with zookeeper
AS core
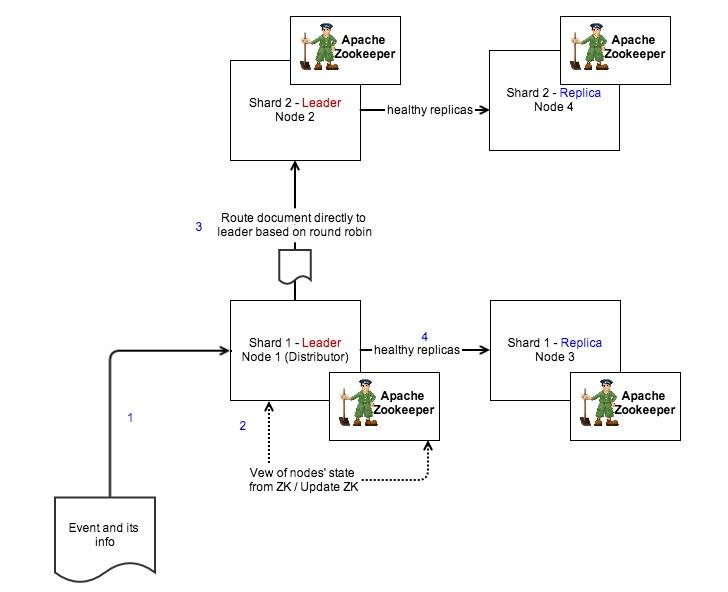
Distributed indexing and requesting
Distributed Indexing
Distributed Requesting
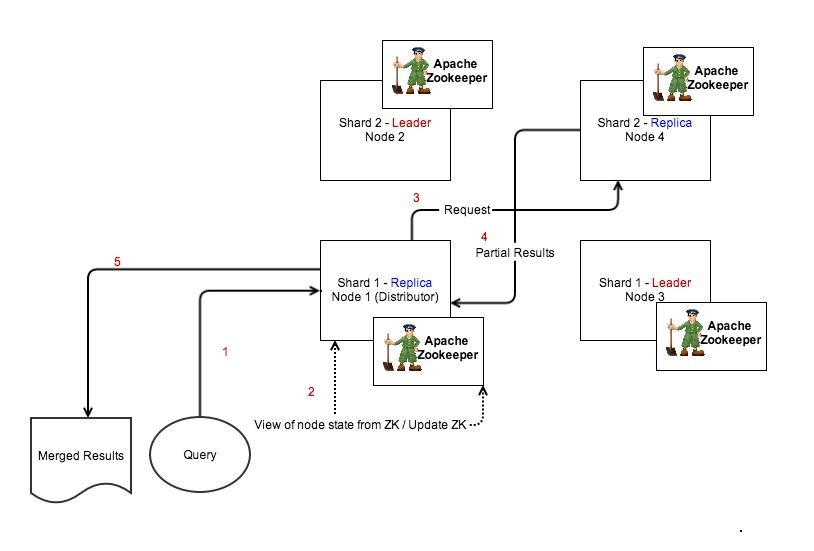
Analysis of distributed index and requesting
ANALYSIS OF DISTRIBUTED INDEX AND REQUESTING
- Distributed Indexing
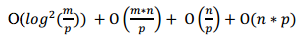
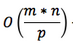
- Distributed Requesting
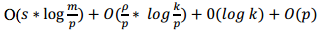
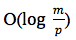
UI
- The user interface subsystem is an interface that allows the business owner to deal with statistical data.
- Written in PHP and Yii framework.
- Support Responsive Web Design (RWD) using Twitter Bootstrap
Experimentation setup and results
setup environment
- Data from Opensooq.com
- The Analytics Subsystem is implemented in a distributed fashion on 4 identical servers, 2 leaders and 2 replicas.
-
These servers were provided from Amazon Elastic Compute Cloud (Amazon EC2) which provides a resizable compute capacity in the cloud locates in Oregon with further information.

ElasticSearch (ES)
Elasticsearch is a flexible and powerful open source, distributed, real-time search and analytics engine.
Elasticsearch uses Lucene under the covers to provide the most powerful full text search capabilities available in any open source product. [Kuc, 2013]

ES Case Studies




The metrics we compared das with es
- Index Size
- Speed
- Throughput
- CPU Utilization
- RAM Usage
- Transfer Rate
- Failed Requests
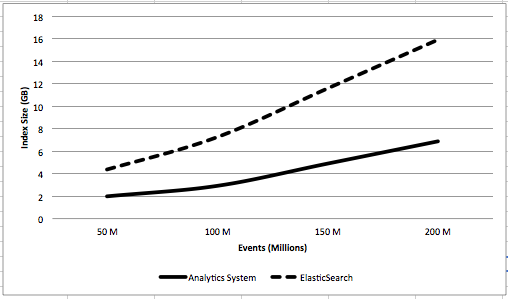
index size
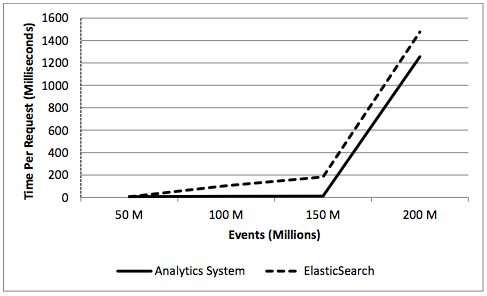
speed
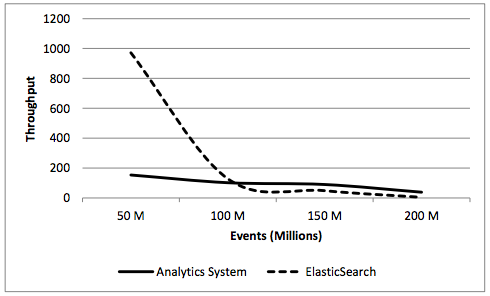
throughput
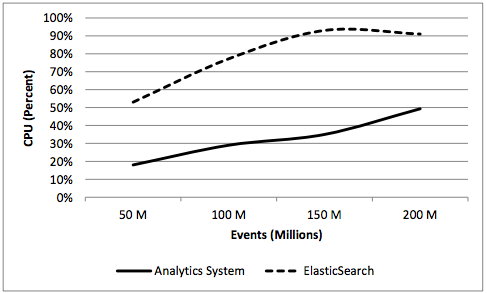
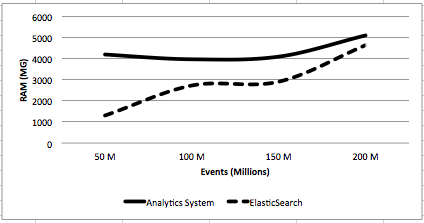
CPU and Ram utilization
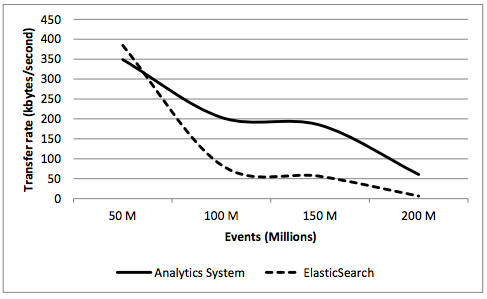
Transfer rate
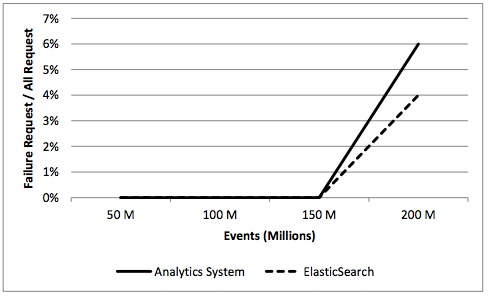
Failed Requests
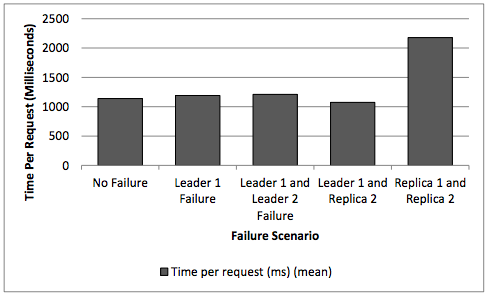
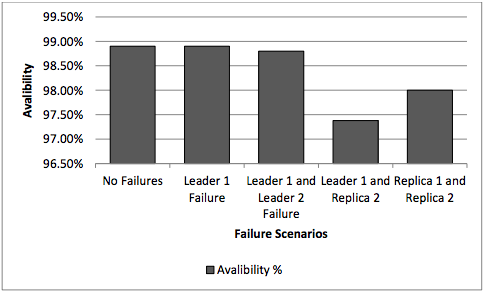
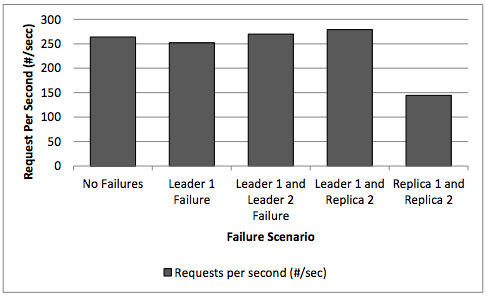
The performance of DAS under Failure scenarios
FAILURE Scenarios
- We have taken 4 scenarios to test the availability and fault tolerance :
- Leader 1 Failure
- Leader 1 and Leader 2 Failure (i.e. both leaders failures only)
- Leader 1 and Replica 2 Failure (i.e. mismatching leader and replica failure).
- Replica 1 and Replica 2 Failure (i.e. the failure of both replicas).
Speed in the Presence of Failures
Percentage of Failed requests in the Presence of Failures
throughput
Why go with a distributed solution ?
speedup
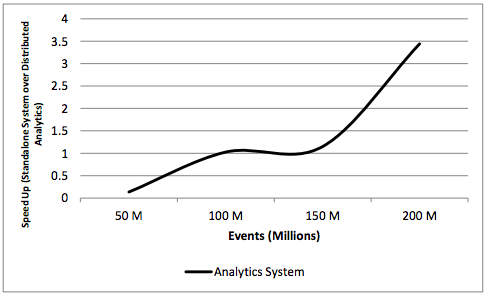
CONCLUSION AND FUTURE WORK
CONCLUSION
- DAS’s index size was 24% smaller than ES’s index.
- The time per request achieved by DAS was 21% faster than ES’s time.
- ES turned out to be more memory efficient and used 67% of the memory used by DAS on average
- ES’s CPU consumption was 2.4 times of the CPU consumed by DAS
Future work
- Distributed index with Apache Hadoop .
- DAS with Redis .
REFERENCES
- Junqueira Flavio and Reed Benjamin . (2013) ,ZooKeeper: Distributed process coordination. (1st ed). USA. O'Reilly Media. 20-134.
- Kuc Rafal and Rogozinski Marek. (2013), Mastering ElasticSearch. (1st ed).UK. Packt Publishing Ltd, (ppt. 45-156).
- McCandless Michael, Hatcher Erik, Gospodnetic Otis. (2010) Lucene in Action. (2nd ed), U.K. Manning Publications.
- Talia Domenico. (2012) Distributed Data Mining Tasks and Patterns as Services. DPA workshop.
Thank you for your attention
DAS
By Ramzi Alqrainy
