RESEARCH SOFTWARE DEVELOPMENT WORK ON DIGITAL TEXTS
Raquel Alegre
Senior Research Software Developer
UCL Research IT Services



This talk is about...
- RSDG projects on text:
- Motivation
- Results
- Lessons learnt
- Some technical details
- Digitised data from:
- British Library
- London Times Digital Archive
- ORACC and Nahrein
- Future work
- What we do at RSDG
slides.com/raquelalegre/libraries
UCL Research Software Development Group
- Custom software development
- Optimisation and refactoring
- Infrastructure
- From astrophysics to archeology
- From web development to HPC
Training:
- Software Carpentry
- Python and Advanced C++ for research
- Publications
- Events
- Mentoring
- Networking
- Assessments
- Recruitment panels
- ...
Project work:
Outreach and collaboration
slides.com/raquelalegre/libraries
Web-based interfaces to data are a common response to these, but rarely fulfil the complex needs of humanities research, and limit further research work.
Motivation
Current barries include:
- Fragmentation of communities, resources, and tools.
- Lack of interoperability.
- Complexity and incompleteness of datasets.
- Lack of technical skills, not knowing what the new possibilities are and not having the expertise to experiement with new tools.
Adapt methods usually applied to big data processing in scientific research to the humanities.
Data Spring
London Times Digital Archive
ORACC and Nahrein

Jisc Research Data Spring
Jisc Research Data Spring
-
Pilot project at UCL in collaboration with the British Library, funded by Jisc Research Data Spring in 2015.
- Purpose: Investigate how best HPC facilities can be used to facilitate the needs of researchers in humanities.
-
60000 digitised books from the British Library
- Fiction and non-fiction.
- 17th, 18th and 19th century.
- 224 GB of XML OCR'd data.
-
Focused on 2 case studies:
- History of medicine
- History of images
Case Study 1: History of medicine
How does the occurrence of diseases in published literature compare to known epidemics in the 19th century?
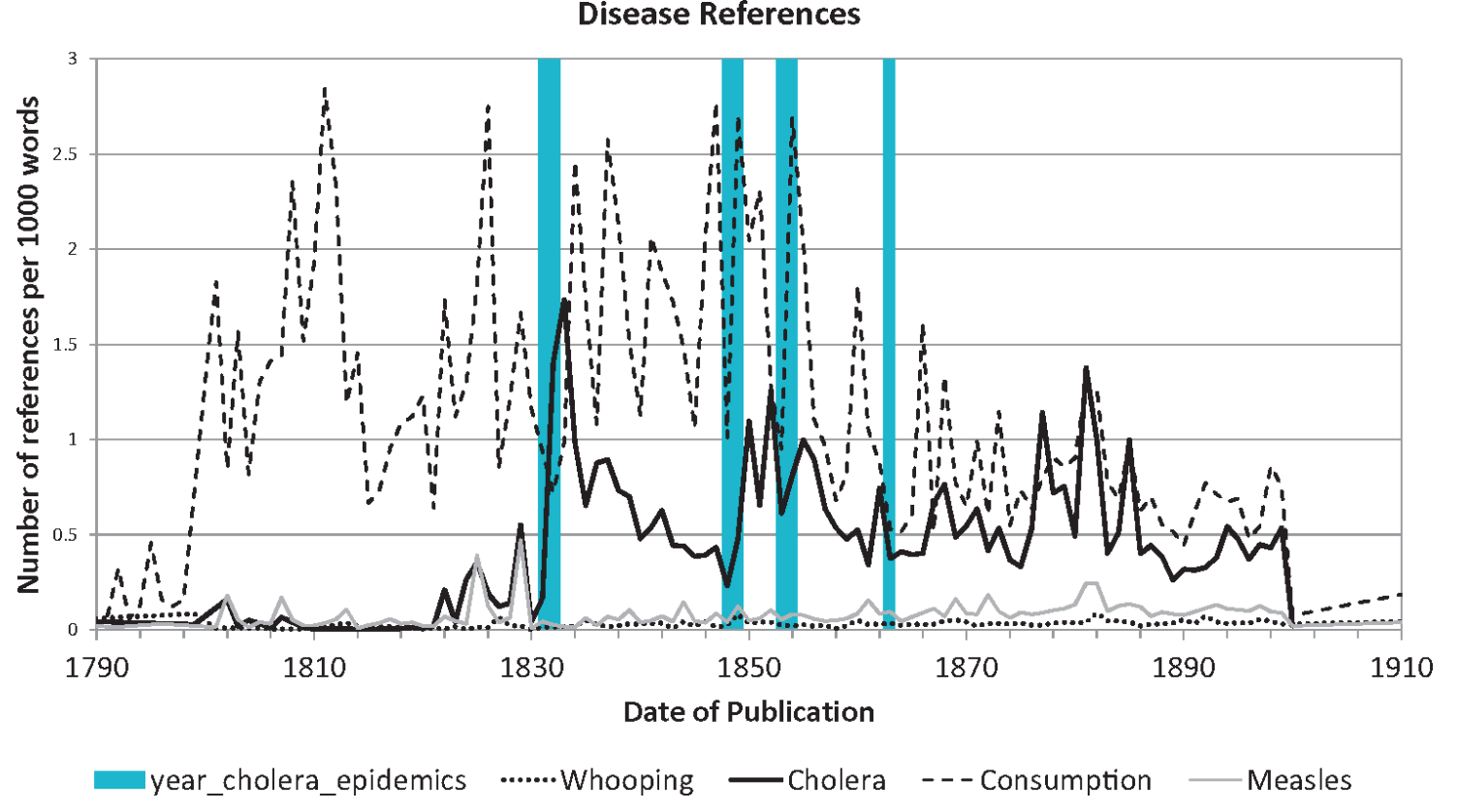
Case Study 2: History of images
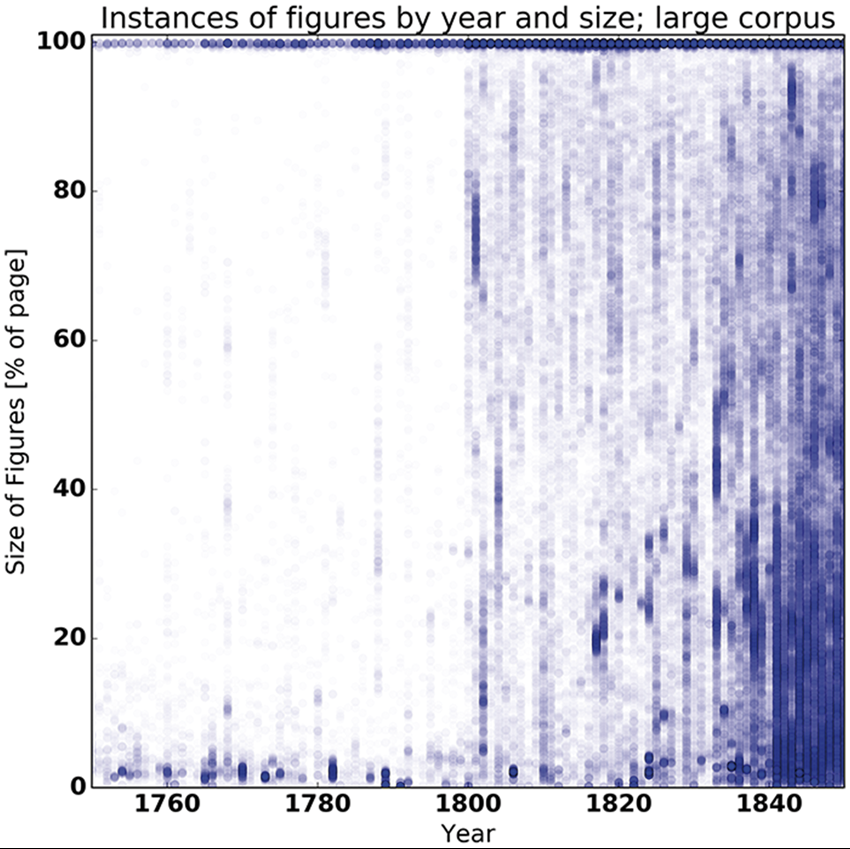
How did changes in image techniques and the size of images map onto the different genres over time? How do the findings made possible using digital humanities techniques and digital sources compare to those using traditional methods and small, hand-crafted collections?
Setting up the infrastructure
-
Data Storage on iRODS.
- iRODS is an Open Source data management tool.
- Allows access to distributed storage assets.
- Has a metadata catalogue describing the data, making queries faster than traditional storage systems.
-
High Performance Computing in Legion and Grace.
- Set up with MPI and Spark
- Easy integration with iRODS.
-
Software development:
-
Python:
- Fabric, mpi4py, pyspark, pytest, ...
-
GitHub
- Version control system where all the code is hosted.
- Issue tracker and a wiki.
- Easy to combine with CI systems like Travis and Jenkins
-
Continuous Integration on Jenkins.
- Testing was developed along with the code that is run on a daily and per-commit basis.
-
Python:
Cross-team work within RITS
-
Research Data Storage Team:
-
Storage and upkeep of the digitised text on iRODS.
-
-
Research Computing:
-
Configuration of Legion and Grace for high performance computing using MPI and Spark to run parallel queries on the texts, making it possible to run a query through the whole archive in under 20 minutes.
-
-
Research Software Development Group:
-
Development of software modules that understand the data model of the digitised texts, and development of the glueware to perform users' queries utilising the data stored by RDS and the HPC systems responsibility of RC.
-
-
Facilitation Team:
-
Enabling this work and constantly seeking ways of making our work more accessible to UCL researchers.
-
Outcomes
- Tested infrastructure to run text analysis on large datasets.
- Enabled new projects and collaborations.
- Identified infrastructural and procedural barriers when humanities researchers attempt to utilize computational research infrastructures for their own research questions.
- Demonstrated how research software engineer capacity can be most efficiently deployed in maintaining and supporting data sets, while librarians can provide an essential service in running initial, routine queries for humanities scholars.
London Times Digital Archive
London Times Digital Archive
- Provided to UCL by CENGAGE.
- All published issues from 1785 to 2009.
- < 1TB of OCR'd XML files as well as original scans.
- Infrastructure was already in place, but the data model was different.
- Interest from UCL to query the data for:
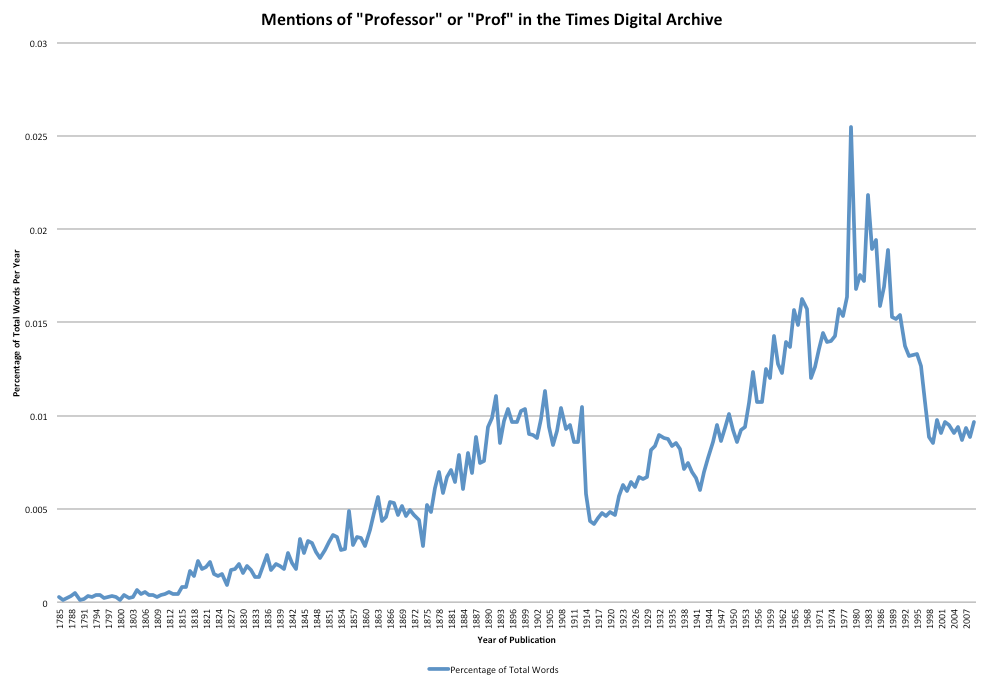
- Popularity of "Professors".
- How Netherland news are talked about in London.
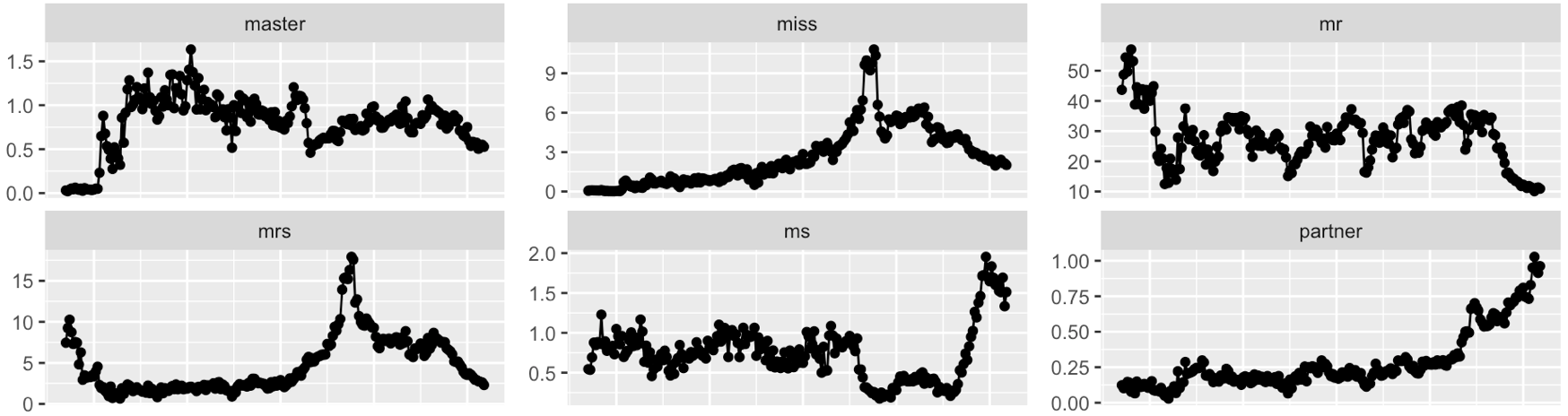
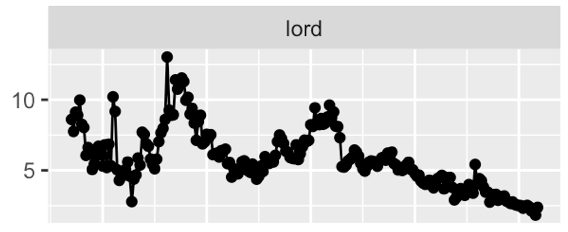
- Study on gender bias through time.
- Articles about Whitechapel.
- Term frequency related to Monopoly streets.
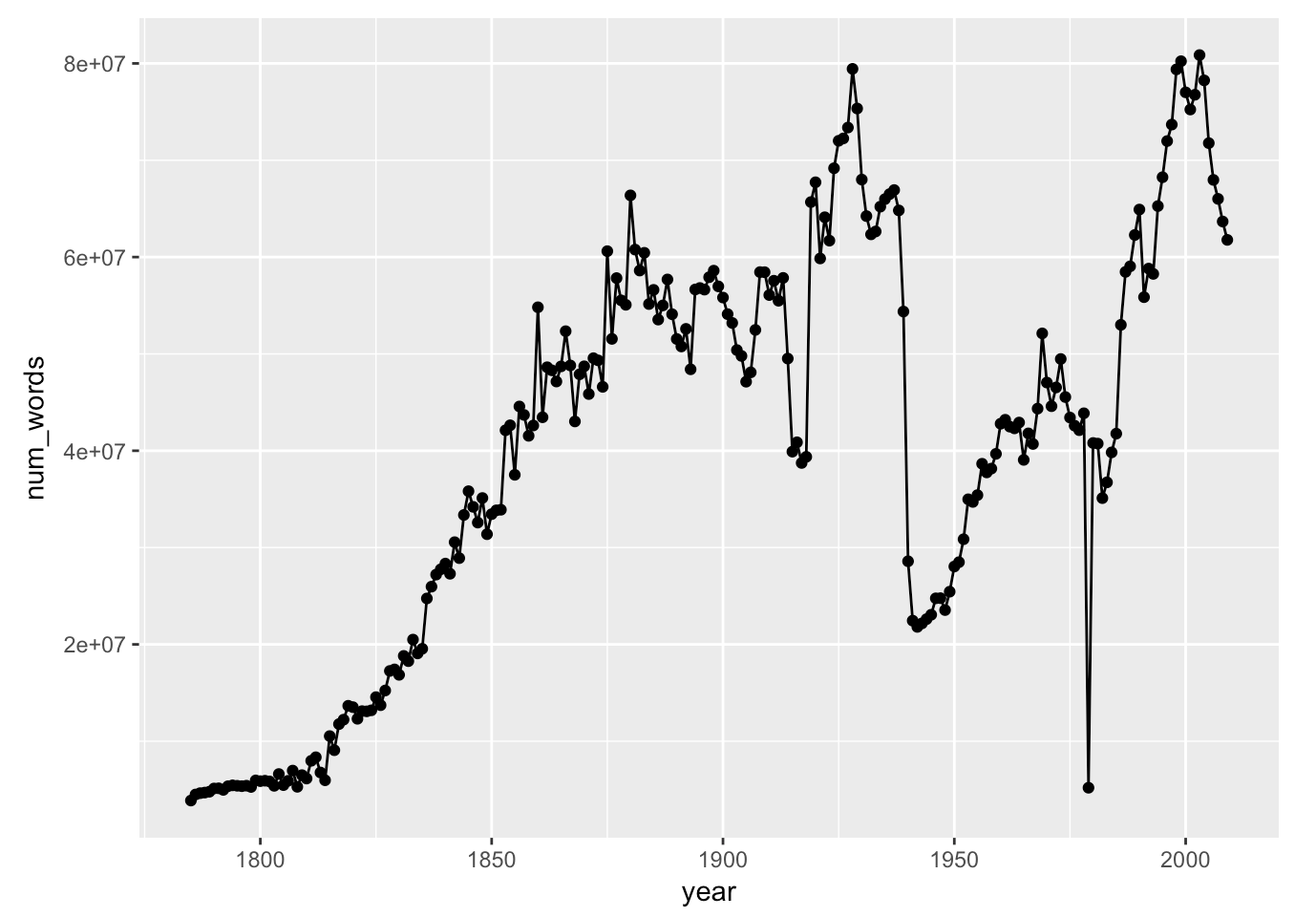
London Times - # words per year
London Times - % mentions of `Professor`
London Times - `he said` vs `she said`
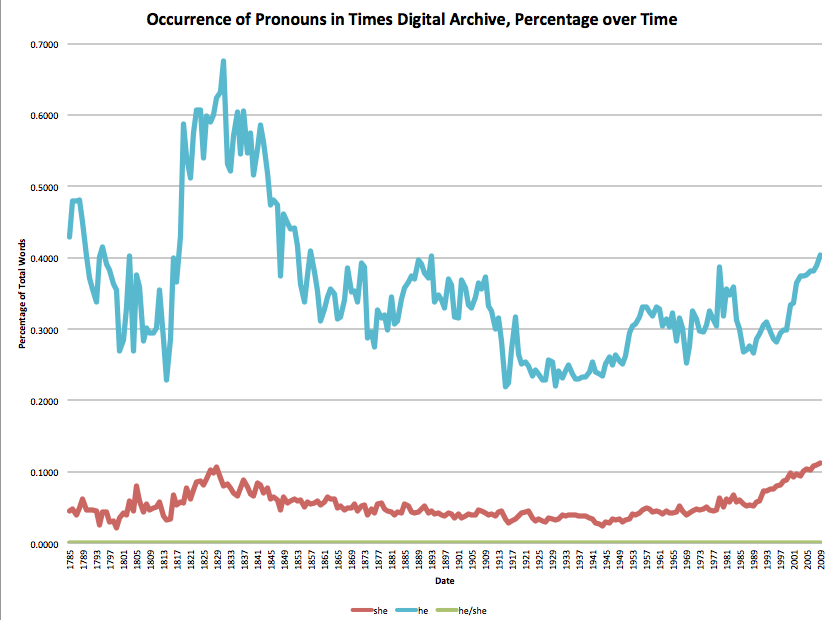
London Times - More on Gender bias through time

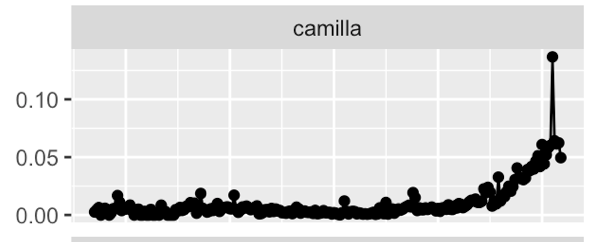
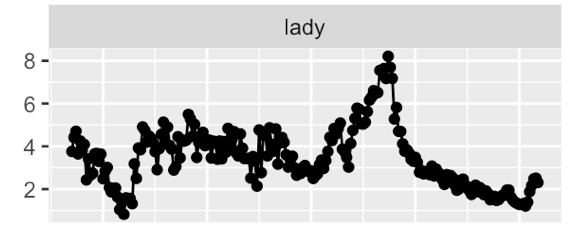
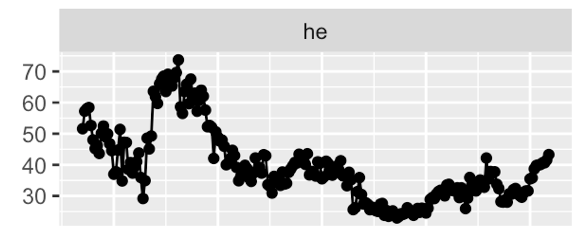
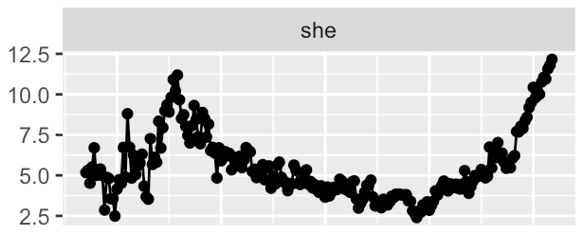
London Times - Sentiment Analysis on gender bias
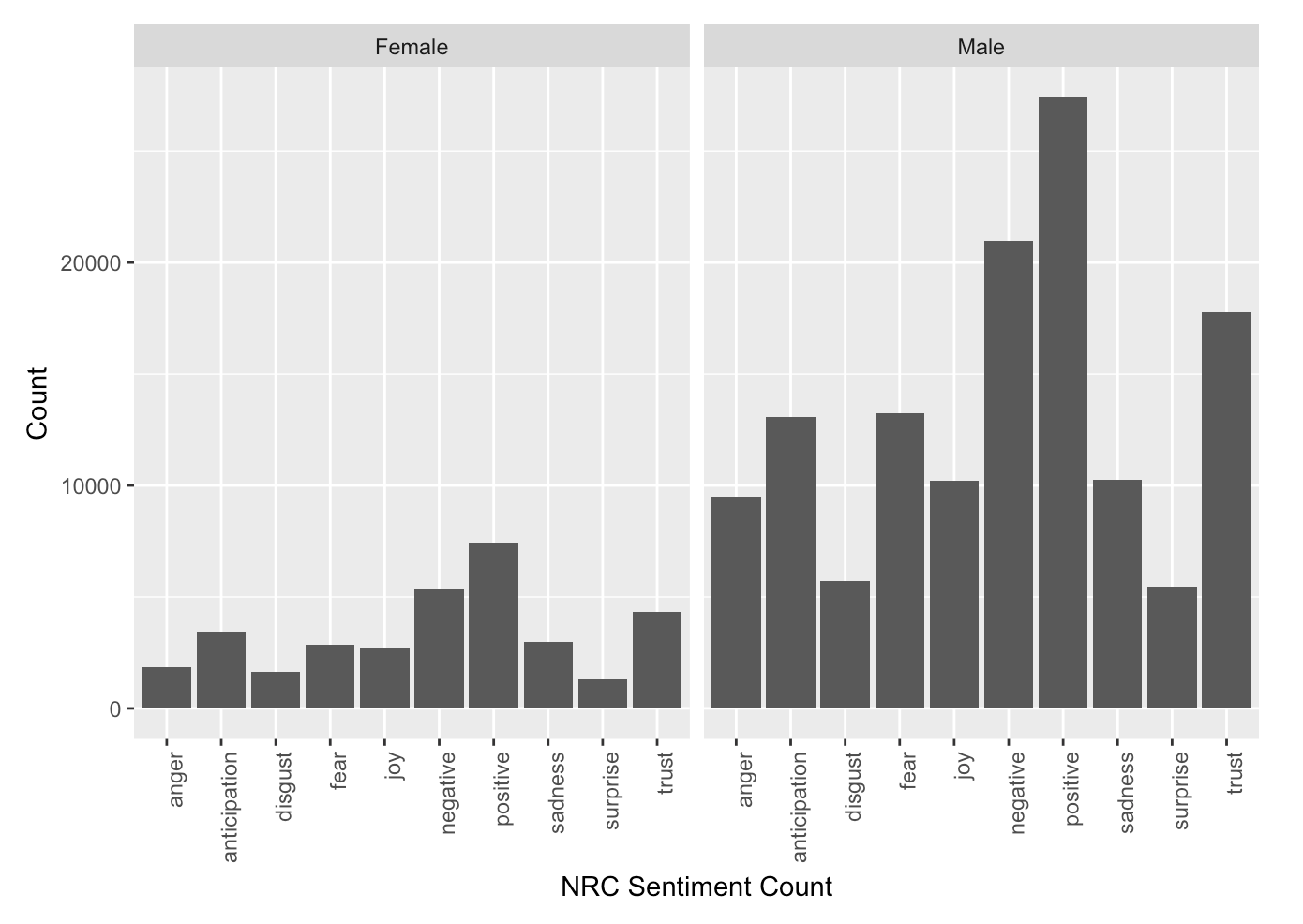
London Times - `men are` vs `women are`

Other queries run on the TDA
- Whitechapel - regex uncovered a few hundreds of articles the researchers hadn't been able to find using the newspaper's search website.
- Monopoly - term frequency for streets in the Monopoly game peak around the time it was launched.
- Netherlands - research on how relevant are news from the Netherlands in the UK, and how long news take travelling from one place to the other across time.
- Oceanic Exchanges - Undergoing study on immigration and women in technology. It will also include data from the Wellcome Trust.
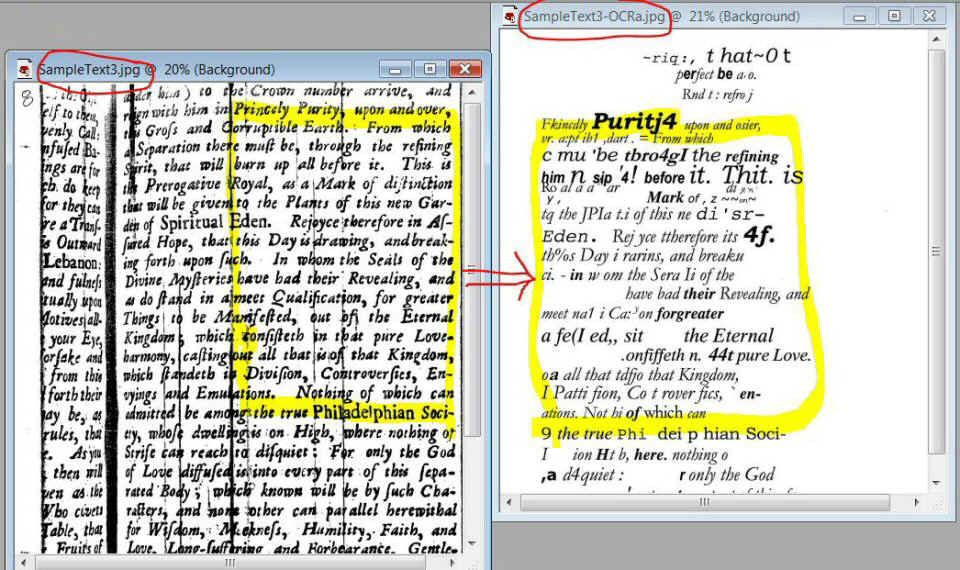
- OCR needs to be improved! But data providers don't often allow us improve it due to licensing restrictions.
Outcomes
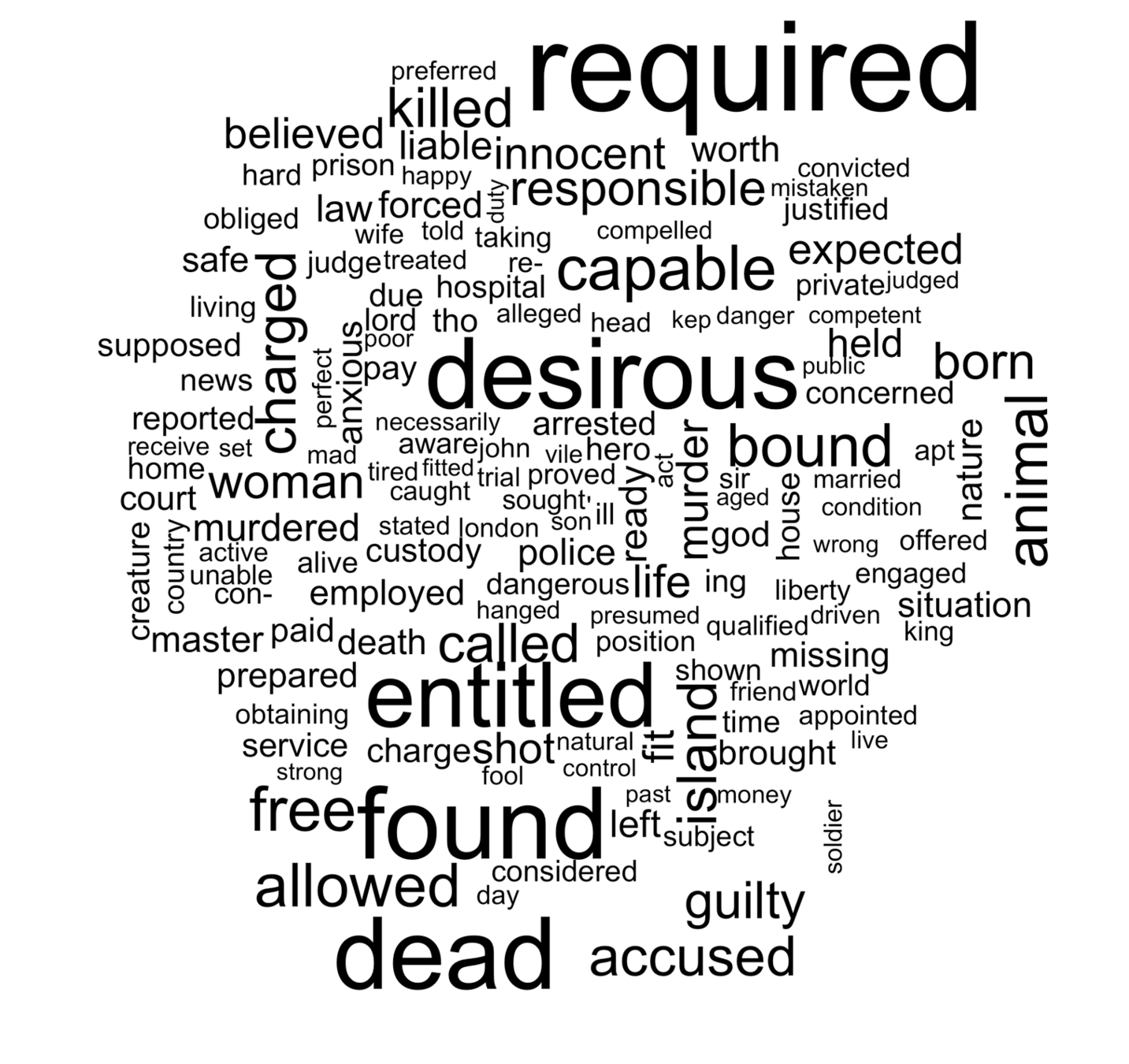
- Sentiment Analysis algorithms don't seem very precise and need more research.
- It was possible to move our code infrastructure from MPI into Spark in order to make the code base simpler and test other technologies on the existent infrastructure.
- Most of the project time was devoted to sort out problems with the infrastructure being slow instead of doing actual data analysis.
- There is still the need for human sanity check on results, which often leads to corrections and finer set up of computational queries.
Outcomes
Future Steps
- Set up query infrastructure for more data sources.
- Oceanic Exchanges.
- Gain more knowledge on what research questions our data can help with so we can make our infrastructure more readily available to UCL researchers.
- Investigate ways of improving the existent OCR work on digitised texts.
- Make training available as SwC for Libraries and Humanities.
- Create a branch of RSDG focused on Data Science to better help the UCL community.
ORACC:
The Open Richly Annotated Cuneiform Corpus
ORACC
- Open Richly Annotated Cuneiform Corpus.
- UCL History - Prof. Eleanor Robson.
- Transliterations of cuneiform texts by ORACC editors around the world.
- Collaboration with RSDG since 2013:
- PyORACC: parser of ORACC cuneiform text format
- Nammu: GUI tool for edition and validation of cuneiform texts.
- ORACC search: Text search tools for the ORACC catalogue and glossaries.
Metadata: project info, lang, protocols...
Sections:
object, parts. ...
Comments
Transliteration and lemmatization
Descriptions:
rulings, blank, ...
ASCII
Transliteration
Format


Translation
ASCII
Transliteration
Format
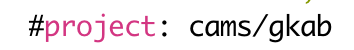
Lexical Analysis
Breaks the input text into a stream of tokens and matches with Regular Expressions:
#
project
:
cams/gkab
[new line]
+
+
+
+
t_HASH
PROJECT
t_COLON
t_ID
t_NEWLINE
r'[a-zA-Z0-9]+[/]?[a-zA-Z0-9]+'r'\:'r'\#'r'\/n'Parse tree


Some useful outcomes
- As-you-type syntax highlighting.
- Bulk parsing of the ORACC corpus is now possible.
- More reliable parsing.
- Documented and tested on UCL CI systems and Travis, ensuring reproducibility.
- Offline parsing is now possible, specially useful when working on-site.
-
Open Source - reusable code
- Current work undertaken at University of California to expand grammar to other types of texts.
ORACC Search
- The ORACC server contains several glossaries covering all the text that has been digitised in the last 20 years. These is also accompanied by metadata and information about projects that need to be discoverable by ORACC users.
- We are using ElasticSearch to store all the information and make it discoverable to users, thus replacing the current bespoke search system, and improving its discovery.
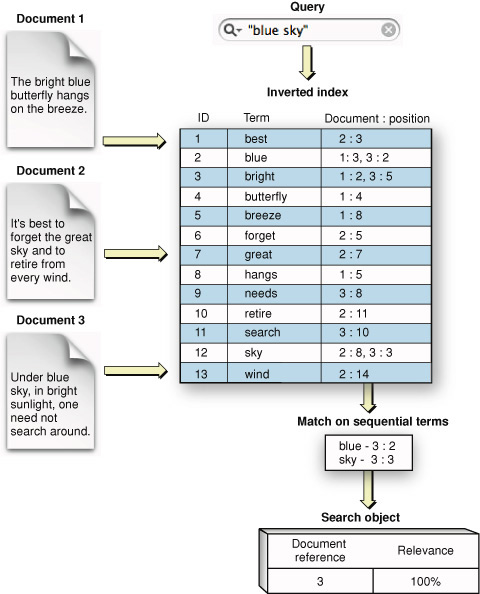
Inverted Index


Text mining tools for researchers
Text mining can be overwhelming:
| Content structure and organisation | Text processing | Statistical Analysis |
| Machine Learning | Classification methods | Model Evaluation |
So many available tools for text mining came up in the last years - difficult to choose!
- Choose a programming language: Python or R.
- Choose well-known, tested sources like NLTK or those by the Stanford NLP group.
- Hype technologies might sound confusing, but deserve an opportunity: e.g. Deep Learning
- GUI workflow tools like RapidMiner or AzureML might be a good way to get started on text mining and machine learning.
Get coding!
- Need to learn from scratch? Come to Software Carpentry, join our courses at UCL (online versions coming soon!) or ask us for materials.
- Don't have anyone to code with? Join out Slack, go to meetups or go to a hackathon!
- Don't have data to play with? Twitter is a great source of data to get started.
Text mining tools for researchers
Contact us!
-
Do you have ideas or questions you need to discuss?
- Email us at rc-softdev@ucl.ac.uk
- Tweet us @uclrits @raquelherself
-
Join our Slack channel at ucl-programming-hub.slack.com:
- Ask technical questions on the #helpme channel
- Get information on the next tech social
- Get reminders about coffee at Housman Thursdays 10am.
Acknowledgements

- UCL Centre for Digital Humanities
- Prof. Melissa Terras
- David Beavan
- Colleagues at RITS:
- Dr. James Hetherington
- Dr. Roma Klapaukh
Thank you :)
... Any questions?
Libraries
By Raquel Alegre
Libraries
Presentation for UCL Libraries about work done by UCL RSDG, focusing on data processing of digitised books and newspapers as well as work done for UCL History's Oracc/Nahrein project - November 2017




