Apache Cassandra
Introduction
Apache Cassandra is an open-source, NoSQL, wide column data store that can quickly ingest and process massive amounts of data. It’s also decentralized, distributed, scalable, highly available, fault-tolerant, and tunably consistent, with identical nodes clustered together to eliminate single points of failure and bottlenecks.
It’s extremely well-suited for managing large amounts of semi-variable but structured data (from sensors, connected appliances, and applications) for analytics, event logging, monitoring, and eCommerce purposes, particularly when high write speeds are needed.
History
Cassandra was initially developed at Facebook to power the Facebook inbox search feature. Facebook released Cassandra as an open-source project on Google code in July 2008. In March 2009 it became an Apache Incubator project, it graduated to a top-level project.
So, what’s so special about it?
- Decentralized means there’s no master-slave paradigm, and each separate node is capable of presenting itself to any end-user or client as a complete or partial replica of the database.
- Distributed means that Cassandra adds the most value when it is distributed across many nodes and even data centers.
- Scalable means that Cassandra can be easily scaled horizontally, by adding more nodes (machines) to the cluster, without disrupting your read and write workflow.
- Highly Available means that your datastore is fault-tolerant and your data remains available even if one or several nodes and data centers go down.
- Tunably Consistent means that it is possible to adjust the tradeoff between availability and consistency of data on Cassandra nodes, typically by configuring replication factorand consistency level settings.
How Apache Cassandra distributes data ?
Casandra uses a peer-to-peer distribution model, which enables it to fully distribute data in the form of variable-length rows, stored by partition keys. This happens across different cloud availability zones and multiple data centers. Cassandra is built for scalability, continuous availability, and has no single point of failure.
Many databases, such as Postgres, use a master-slave replication model, in which the writes go to a master node and reads are executed on slaves. Unfortunately, the master-slave hierarchy often creates bottlenecks. To provide high availability, fault tolerance, and scalability, Cassandra’s peer-to-peer cluster architecture provides nodes with open channels of communication.
Cassandra uses tokens to determine which node holds what data. A token is a 64-bit integer, and Cassandra assigns ranges of these tokens to nodes so that each possible token is owned by a node. Adding more nodes to the cluster or removing old ones leads to redistributing these token ranges among nodes.
A row’s partition key is used to calculate a token using a given partitioner (a hash function for computing the token of a partition key) to determine which node owns that row. That’s how Cassandra finds where the replicas are which hold that data.
Components of Cassandra
-
Node − It is the place where data is stored.
-
Data center − It is a collection of related nodes.
-
Cluster − A cluster is a component that contains one or more data centers.
-
Commit log − The commit log is a crash-recovery mechanism in Cassandra. Every write operation is written to the commit log.
-
Mem-table − A mem-table is a memory-resident data structure. After commit log, the data will be written to the mem-table. Sometimes, for a single-column family, there will be multiple mem-tables.
-
SSTable − It is a disk file to which the data is flushed from the mem-table when its contents reach a threshold value.
-
Bloom filter − These are nothing but quick, nondeterministic, algorithms for testing whether an element is a member of a set. It is a special kind of cache. Bloom filters are accessed after every query.
Data model of Cassandra
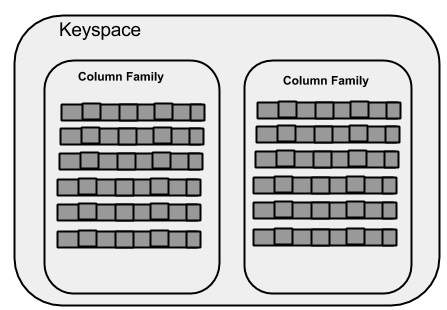
Keyspace
Keyspace is the outermost container for data in Cassandra. The basic attributes of a Keyspace in Cassandra are −
-
Replication factor − It is the number of machines in the cluster that will receive copies of the same data.
-
Replica placement strategy − It is nothing but the strategy to place replicas in the ring. We have strategies such as simple strategy (rack-aware strategy), old network topology strategy (rack-aware strategy), and network topology strategy (datacenter-shared strategy).
-
Column families − Keyspace is a container for a list of one or more column families. A column family, in turn, is a container of a collection of rows. Each row contains ordered columns. Column families represent the structure of your data. Each keyspace has at least one and often many column families.
Column Family
A column family is a container for an ordered collection of rows. Each row, in turn, is an ordered collection of columns. The following table lists the points that differentiate a column family from a table of relational databases.
| A schema in a relational model is fixed. Once we define certain columns for a table, while inserting data, in every row all the columns must be filled at least with a null value. | In Cassandra, although the column families are defined, the columns are not. You can freely add any column to any column family at any time. |
|---|---|
| Relational tables define only columns and the user fills in the table with values. | In Cassandra, a table contains columns, or can be defined as a super column family. |
A Cassandra column family has the following attributes −
-
keys_cached − It represents the number of locations to keep cached per SSTable.
-
rows_cached − It represents the number of rows whose entire contents will be cached in memory.
-
preload_row_cache − It specifies whether you want to pre-populate the row cache.
Column
A column is the basic data structure of Cassandra with three values, namely key or column name, value, and a time stamp. Given below is the structure of a column.

SuperColumn
A super column is a special column, therefore, it is also a key-value pair. But a super column stores a map of sub-columns.
Generally column families are stored on disk in individual files. Therefore, to optimize performance, it is important to keep columns that you are likely to query together in the same column family, and a super column can be helpful here.Given below is the structure of a super column.

Data Models of Cassandra and RDBMS
| RDBMS | Cassandra |
|---|---|
| RDBMS deals with structured data. | Cassandra deals with unstructured data. |
| It has a fixed schema. | Cassandra has a flexible schema. |
| In RDBMS, a table is an array of arrays. (ROW x COLUMN) | In Cassandra, a table is a list of “nested key-value pairs”. (ROW x COLUMN key x COLUMN value) |
| Database is the outermost container that contains data corresponding to an application. | Keyspace is the outermost container that contains data corresponding to an application. |
| Tables are the entities of a database. | Tables or column families are the entity of a keyspace. |
| Row is an individual record in RDBMS. | Row is a unit of replication in Cassandra. |
| Column represents the attributes of a relation. | Column is a unit of storage in Cassandra. |
| RDBMS supports the concepts of foreign keys, joins. | Relationships are represented using collections. |
Cassandra Query Language (CQL)
Cassandra provides a query language called cql. Using cql, you can
- define a schema
- insert data, and
- execute a query
CQL Data Definition Commands
-
CREATE KEYSPACE − Creates a KeySpace in Cassandra.
-
USE − Connects to a created KeySpace.
-
ALTER KEYSPACE − Changes the properties of a KeySpace.
-
DROP KEYSPACE − Removes a KeySpace
-
CREATE TABLE − Creates a table in a KeySpace.
-
ALTER TABLE − Modifies the column properties of a table.
-
DROP TABLE − Removes a table.
-
TRUNCATE − Removes all the data from a table.
-
CREATE INDEX − Defines a new index on a single column of a table.
-
DROP INDEX − Deletes a named index.
CQL Data Manipulation Commands
-
INSERT − Adds columns for a row in a table.
-
UPDATE − Updates a column of a row.
-
DELETE − Deletes data from a table.
-
BATCH − Executes multiple DML statements at once.
CQL Clauses
-
SELECT − This clause reads data from a table
-
WHERE − The where clause is used along with select to read a specific data.
-
ORDERBY − The orderby clause is used along with select to read a specific data in a specific order.
Note: CQL does not support joins.
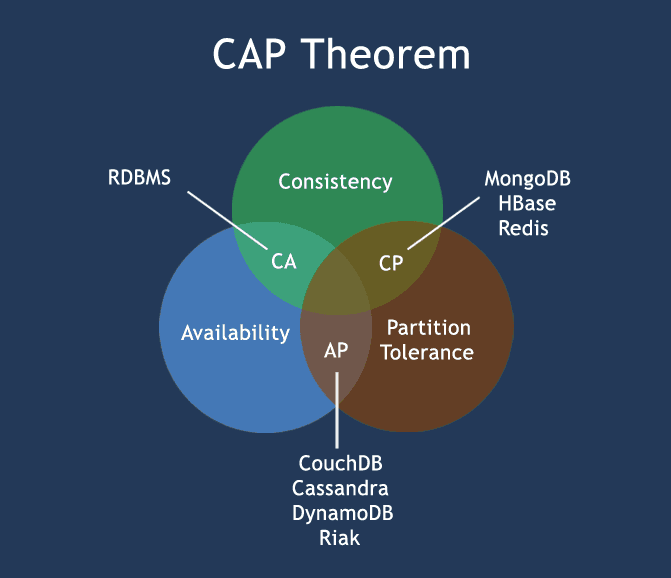
The CAP Theorem
It is impossible for a distributed data store to simultaneously provide more than two out of the following three guarantees:
- Consistency: Every read receives the most recent write or an error
- Availability: Every request receives a (non-error) response, without the guarantee that it contains the most recent write
- Partition tolerance: The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes
Cassandra’s Tunable Consistency allows you to decide what is more important to you, on a per-query level, by instructing Cassandra on how to handle any write and read request.
- High stale data potential (low consistency level) — you can risk the return of stale data by configuring Cassandra to wait for any available node. This could potentially return an out-of-date replica, but conflicts are resolved by picking the replica with the latest timestamp. This allows for the fastest query completion.
- Medium stale data potential (medium consistency level) — to reduce the probability of getting stale data while compromising on query speed, you can instruct Cassandra to reach a quorum of nodes.
- Strong data consistency (high consistency level) — if you ask Cassandra to wait for every node, you will get strong consistency, in which Cassandra always returns the latest data.
More Reads
- https://en.wikipedia.org/wiki/Apache_Cassandra
- https://cassandra.apache.org/
- https://dzone.com/articles/an-introduction-to-apache-cassandra
- https://dzone.com/articles/introduction-apache-cassandras
- https://dzone.com/articles/introduction-nosql-apache
- https://www.tutorialspoint.com/cassandra/cassandra_cqlsh.htm
- https://medium.com/@marikalam/study-guide-cassandra-data-consistency-496e5bf9cadb
Thanks
Apache Cassandra
By Ratan Kulshreshtha


