




































































Roberto Calandra PRO
Full Professor at TU Dresden. Head of the LASR Lab. Working in AI, Robotics and Touch Sensing.
Roberto Calandra
Secondmind - 14 Oct 2021
Facebook AI Research
From YouTube: https://www.youtube.com/watch?v=g0TaYhjpOfo
Robotics still heavily rely on human expertise !
On one hand, it is unfeasible to hand-design general purpose controllers
On the other hand, there is mistrust for automatic design of controllers
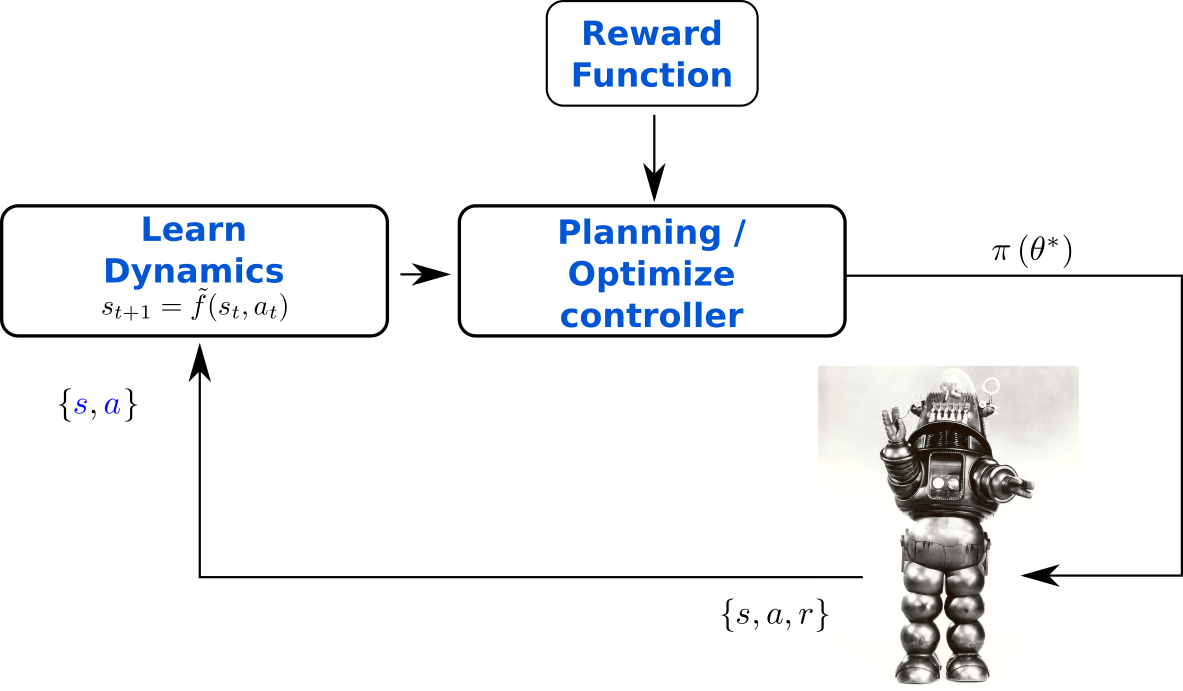
Optimized parameters
Objective function
Parameters to optimize
Policy (i.e., parametrized controller)
Action executed
Learning a controller is equivalent to optimizing the parameters of the controller
Current state
Parameters of the policy
Bio-inspired Bipedal Robot "Fox":
Calandra, R.; Seyfarth, A.; Peters, J. & Deisenroth, M. P.
Bayesian Optimization for Learning Gaits under Uncertainty
Annals of Mathematics and Artificial Intelligence (AMAI), 2015, 76, 5-23
Calandra, R.; Seyfarth, A.; Peters, J. & Deisenroth, M. P.
Bayesian Optimization for Learning Gaits under Uncertainty
Annals of Mathematics and Artificial Intelligence (AMAI), 2015, 76, 5-23
Calandra, R.; Seyfarth, A.; Peters, J. & Deisenroth, M. P.
Bayesian Optimization for Learning Gaits under Uncertainty
Annals of Mathematics and Artificial Intelligence (AMAI), 2015, 76, 5-23
Not Symmetrical (about 5° difference). Why?
Because it is walking in a circle!
Calandra, R.; Seyfarth, A.; Peters, J. & Deisenroth, M. P.
Bayesian Optimization for Learning Gaits under Uncertainty
Annals of Mathematics and Artificial Intelligence (AMAI), 2015, 76, 5-23
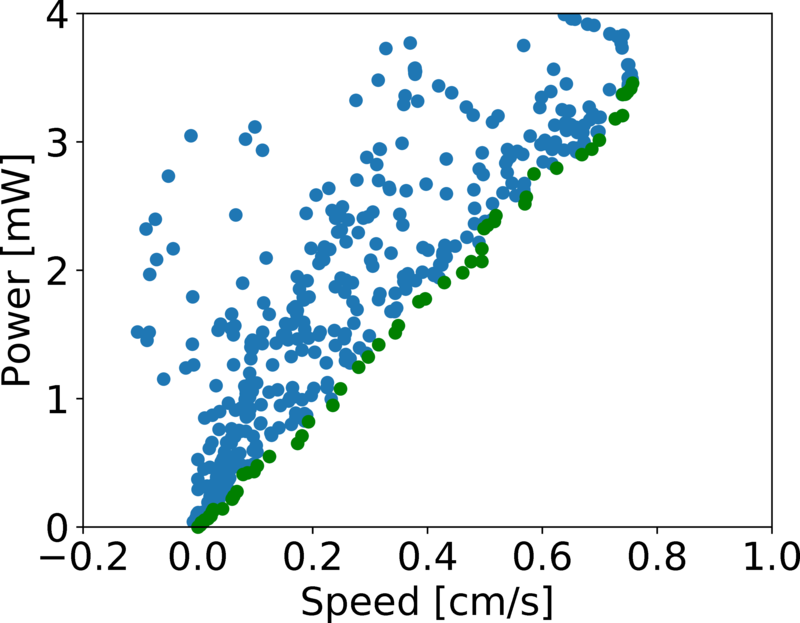
Trade-off between Walking Speed and Energy Consumption!
Pareto Front
20 Evaluations
50 Evaluations
200 Evaluations
Calandra, R.; Peters, J. & Deisenroth, M. P.
Pareto Front Modeling for Sensitivity Analysis in Multi-Objective Bayesian Optimization
NIPS Workshop on Bayesian Optimization (BayesOpt), 2014
MOP2
ZDT3
Calandra, R.; Peters, J. & Deisenroth, M. P.
Pareto Front Modeling for Sensitivity Analysis in Multi-Objective Bayesian Optimization
NIPS Workshop on Bayesian Optimization (BayesOpt), 2014
MOP2
ZDT3
Calandra, R.; Peters, J. & Deisenroth, M. P.
Pareto Front Modeling for Sensitivity Analysis in Multi-Objective Bayesian Optimization
NIPS Workshop on Bayesian Optimization (BayesOpt), 2014
Simulated hexapod:
Let's apply all the tools we have so far!
Yang, B.; Wang, G.; Calandra, R.; Contreras, D.; Levine, S. & Pister, K.
Learning Flexible and Reusable Locomotion Primitives for a Microrobot
IEEE Robotics and Automation Letters (RA-L), 2018, 3, 1904-1911
Yang, B.; Wang, G.; Calandra, R.; Contreras, D.; Levine, S. & Pister, K.
Learning Flexible and Reusable Locomotion Primitives for a Microrobot
IEEE Robotics and Automation Letters (RA-L), 2018, 3, 1904-1911
Yang, B.; Wang, G.; Calandra, R.; Contreras, D.; Levine, S. & Pister, K.
Learning Flexible and Reusable Locomotion Primitives for a Microrobot
IEEE Robotics and Automation Letters (RA-L), 2018, 3, 1904-1911
Yang, B.; Wang, G.; Calandra, R.; Contreras, D.; Levine, S. & Pister, K.
Learning Flexible and Reusable Locomotion Primitives for a Microrobot
IEEE Robotics and Automation Letters (RA-L), 2018, 3, 1904-1911
Yang, B.; Wang, G.; Calandra, R.; Contreras, D.; Levine, S. & Pister, K.
Learning Flexible and Reusable Locomotion Primitives for a Microrobot
IEEE Robotics and Automation Letters (RA-L), 2018, 3, 1904-1911
Optimized parameters
Objective function
Parameters to optimize
Context
Yang, B.; Wang, G.; Calandra, R.; Contreras, D.; Levine, S. & Pister, K.
Learning Flexible and Reusable Locomotion Primitives for a Microrobot
IEEE Robotics and Automation Letters (RA-L), 2018, 3, 1904-1911
Liao, T.; Wang, G.; Yang, B.; Lee, R.; Pister, K.; Levine, S. & Calandra, R.
Data-efficient Learning of Morphology and Controller for a Microrobot
IEEE International Conference on Robotics and Automation (ICRA), 2019
Two levels of optimization
(instead of a single bigger optimization)
Liao, T.; Wang, G.; Yang, B.; Lee, R.; Pister, K.; Levine, S. & Calandra, R.
Data-efficient Learning of Morphology and Controller for a Microrobot
IEEE International Conference on Robotics and Automation (ICRA), 2019
Liao, T.; Wang, G.; Yang, B.; Lee, R.; Pister, K.; Levine, S. & Calandra, R.
Data-efficient Learning of Morphology and Controller for a Microrobot
IEEE International Conference on Robotics and Automation (ICRA), 2019
Bansal, S.; Calandra, R.; Xiao, T.; Levine, S. & Tomlin, C. J.
Goal-Driven Dynamics Learning via Bayesian Optimization
IEEE Conference on Decision and Control (CDC), 2017, 5168-5173
Bansal, S.; Calandra, R.; Xiao, T.; Levine, S. & Tomlin, C. J.
Goal-Driven Dynamics Learning via Bayesian Optimization
IEEE Conference on Decision and Control (CDC), 2017, 5168-5173
Bansal, S.; Calandra, R.; Xiao, T.; Levine, S. & Tomlin, C. J.
Goal-Driven Dynamics Learning via Bayesian Optimization
IEEE Conference on Decision and Control (CDC), 2017, 5168-5173
There exist models that are wrong, but nearly optimal when used for control
Lambert, N.; Wilcox, A.; Zhang, H.; Pister, K. S. J. & Calandra, R.
Learning Accurate Long-term Dynamics for Model-based Reinforcement Learning
IEEE Conference on Decision and Control (CDC), 2021
(YES)
Zhang, B.; Rajan, R.; Pineda, L.; Lambert, N.; Biedenkapp, A.; Chua, K.; Hutter, F. & Calandra, R.
On the Importance of Hyperparameter Optimization for Model-based Reinforcement Learning
International Conference on Artificial Intelligence and Statistics (AISTATS), 2021
(YES)
Bansal, S.; Calandra, R.; Xiao, T.; Levine, S. & Tomlin, C. J.
Goal-Driven Dynamics Learning via Bayesian Optimization
IEEE Conference on Decision and Control (CDC), 2017, 5168-5173
(NO)
(NO)
Lambert, N.; Amos, B.; Yadan, O. & Calandra, R.
Objective Mismatch in Model-based Reinforcement Learning
Learning for Dynamics and Control (L4DC), 2020, 761-770
Z. Wang, F. Hutter, M. Zoghi, D. Matheson, and N. de Freitas.
Bayesian optimization in a billion dimensions via random embeddings.
Journal of Artificial Intelligence Research, 55:361–387, 2016
Very neat Idea!
But several wrong assumptions...
Letham, B.; Calandra, R.; Rai, A. & Bakshy, E.
Re-Examining Linear Embeddings for High-dimensional Bayesian Optimization
Advances in Neural Information Processing Systems (NeurIPS), 2020
Letham, B.; Calandra, R.; Rai, A. & Bakshy, E.
Re-Examining Linear Embeddings for High-dimensional Bayesian Optimization
Advances in Neural Information Processing Systems (NeurIPS), 2020
and more...
Thank you for your time
By Roberto Calandra
Designing and tuning controllers for real-world robots is a daunting task which typically requires significant expertise and lengthy experimentation. Bayesian optimization has shown to be a successful approach to automate these tasks with little human expertise required. In this talk, I will discuss the main challenges of robot learning, and how BO helps to overcome some of them. Using as showcase real-world applications where BO proved to be effective, I will also discuss how the challenges encountered in robotics applications can guide the development of new BO algorithms.



