




















































































Roberto Calandra PRO
Full Professor at TU Dresden. Head of the LASR Lab. Working in AI, Robotics and Touch Sensing.
Roberto Calandra
Perspectives in Data-Driven Materials Design Summer School - 28 August 2025
Learning, Adaptive Systems, and Robotics (LASR) Lab
Machine Learning
Robotics
Touch
Sensing
Engineering still heavily rely on human expertise !
On one hand, it is often unfeasible to hand-design complex systems
On the other hand, there is mistrust for automatic design
Optimized parameters
Objective function
Parameters to optimize
Single minimum
(e.g., convex functions)
Multiple minimum
(a.k.a., global optimization)
First-order
(we can measure gradients)
Zero-order
(no gradients available)
Noise-less
(repeating the evaluation yield the same result)
Stochastic
(repeating the evaluation yield different results)
Nice and easy to solve
(e.g., with gradient descent)
Cheap Evaluation
(virtually infinite number of evaluations allowed)
Difficult to optimize
Expensive Evaluation
(limited to tens or hundreds of evaluations)
Here we want to use BO!
e.g.,
We can create a surrogate model
Gradient descent
[credit: Marc Deisenroth]
[credit: Marc Deisenroth]
Large variety of models used throughout the literature:
The most commonly used (at the moment)
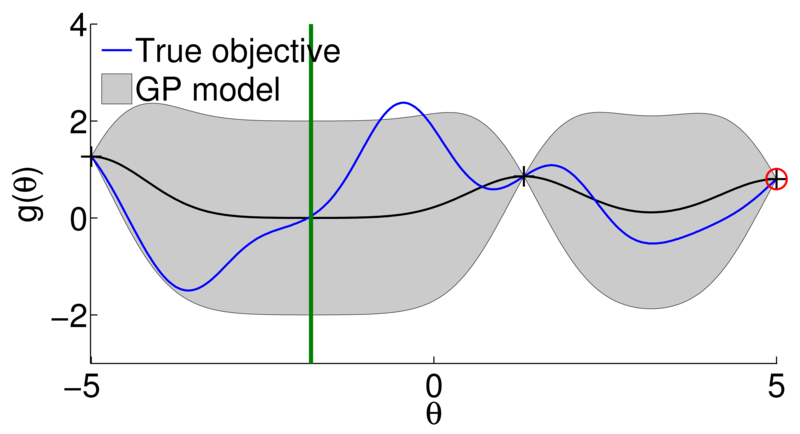
Surrogate model (a.k.a. response surface) need to accurately approximate (and generalize) the underlying function based on the available data
Additional reading:
Rasmussen, C. E. & Williams, C. K. I.
Gaussian Processes for Machine Learning
The MIT Press, 2006
Mean of a GP = Kernel ridge regression
Square exponential
parameters of the GP
(often referred to as hyperparameters)
Multiple ways to optimize the hyperparameters
Additional reading:
Rasmussen, C. E. & Williams, C. K. I.
Gaussian Processes for Machine Learning
The MIT Press, 2006
Pro:
Cons:
[credit: Marc Deisenroth]
* But not always
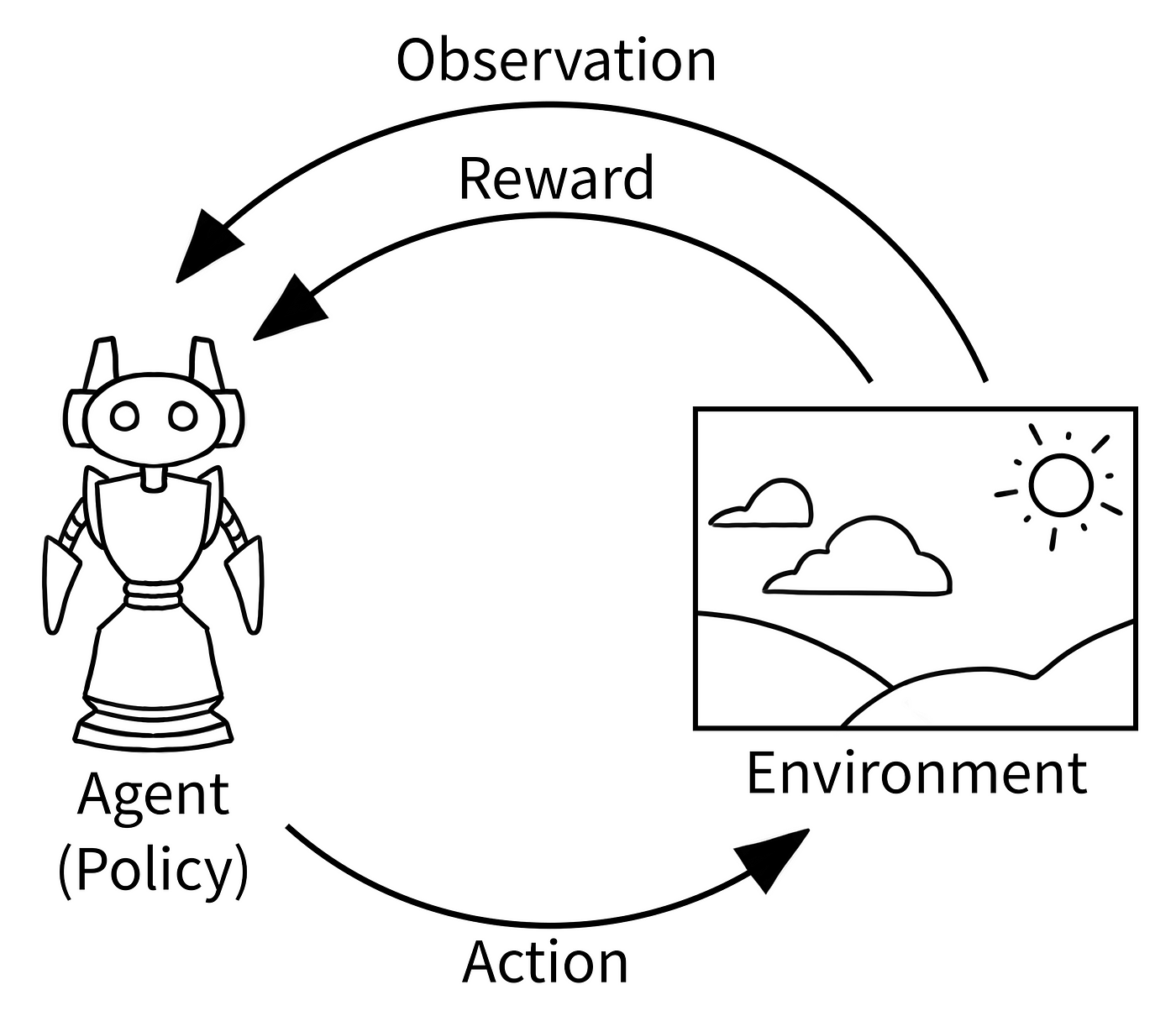
Policy (i.e., parametrized controller)
Action executed
Learning a controller is equivalent to optimizing the parameters of the controller
Current state
Parameters of the policy
Bio-inspired Bipedal Robot "Fox":
Calandra, R.; Seyfarth, A.; Peters, J. & Deisenroth, M. P.
Bayesian Optimization for Learning Gaits under Uncertainty
Annals of Mathematics and Artificial Intelligence (AMAI), 2015, 76, 5-23
Calandra, R.; Seyfarth, A.; Peters, J. & Deisenroth, M. P.
Bayesian Optimization for Learning Gaits under Uncertainty
Annals of Mathematics and Artificial Intelligence (AMAI), 2015, 76, 5-23
Calandra, R.; Seyfarth, A.; Peters, J. & Deisenroth, M. P.
Bayesian Optimization for Learning Gaits under Uncertainty
Annals of Mathematics and Artificial Intelligence (AMAI), 2015, 76, 5-23
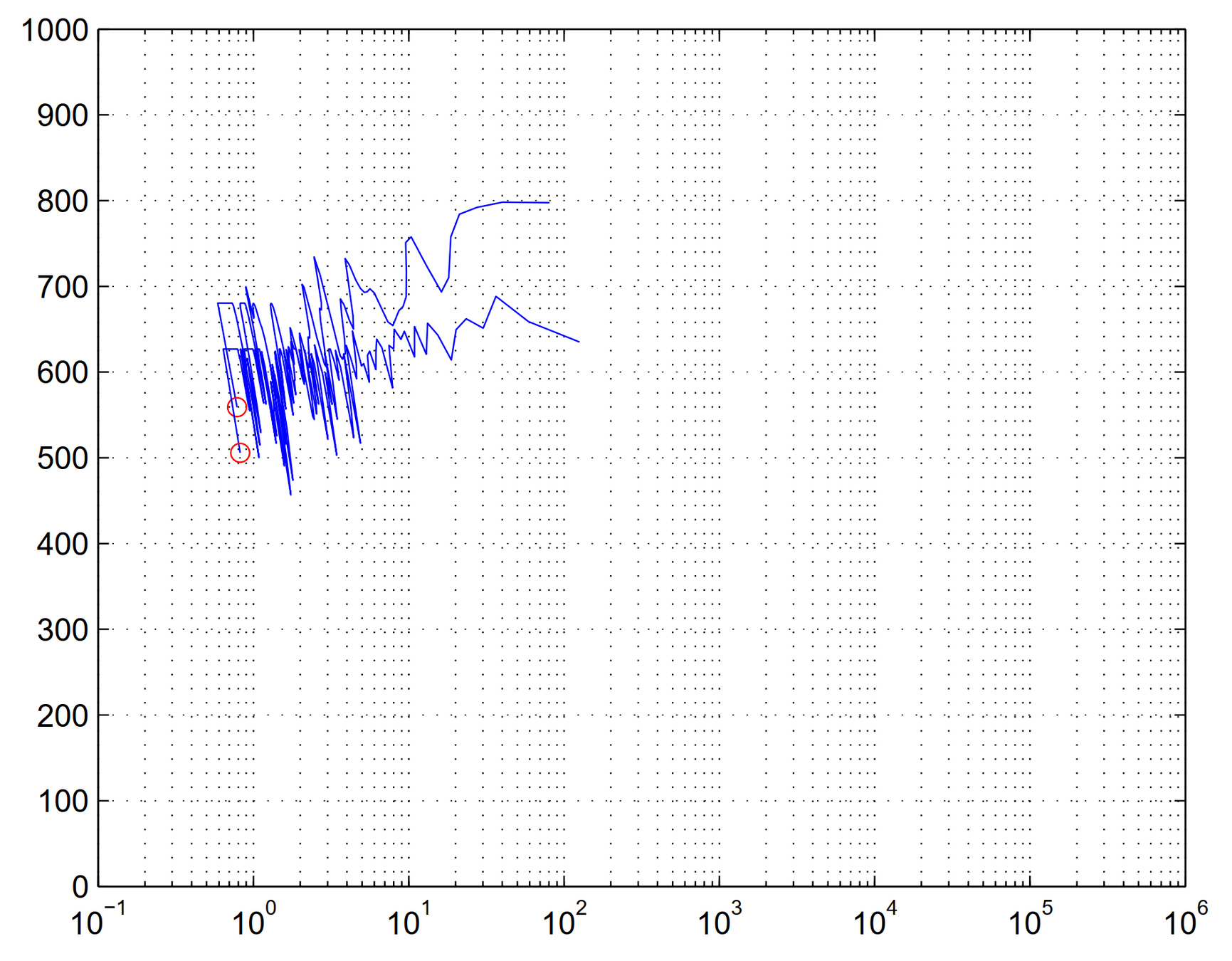
Not Symmetrical (about 5° difference). Why?
Because it is walking in a circle!
Calandra, R.; Seyfarth, A.; Peters, J. & Deisenroth, M. P.
Bayesian Optimization for Learning Gaits under Uncertainty
Annals of Mathematics and Artificial Intelligence (AMAI), 2015, 76, 5-23
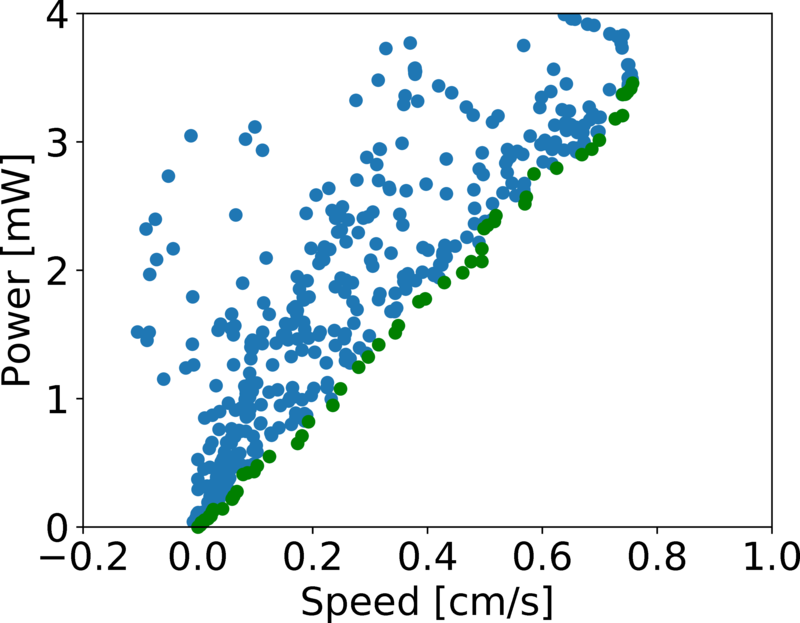
Trade-off between Walking Speed and Energy Consumption!
Pareto Front
20 Evaluations
50 Evaluations
200 Evaluations
Calandra, R.; Peters, J. & Deisenroth, M. P.
Pareto Front Modeling for Sensitivity Analysis in Multi-Objective Bayesian Optimization
NIPS Workshop on Bayesian Optimization (BayesOpt), 2014
MOP2
ZDT3
Calandra, R.; Peters, J. & Deisenroth, M. P.
Pareto Front Modeling for Sensitivity Analysis in Multi-Objective Bayesian Optimization
NIPS Workshop on Bayesian Optimization (BayesOpt), 2014
MOP2
ZDT3
Calandra, R.; Peters, J. & Deisenroth, M. P.
Pareto Front Modeling for Sensitivity Analysis in Multi-Objective Bayesian Optimization
NIPS Workshop on Bayesian Optimization (BayesOpt), 2014
Simulated hexapod:
Let's apply all the tools we have so far!
Yang, B.; Wang, G.; Calandra, R.; Contreras, D.; Levine, S. & Pister, K.
Learning Flexible and Reusable Locomotion Primitives for a Microrobot
IEEE Robotics and Automation Letters (RA-L), 2018, 3, 1904-1911
Yang, B.; Wang, G.; Calandra, R.; Contreras, D.; Levine, S. & Pister, K.
Learning Flexible and Reusable Locomotion Primitives for a Microrobot
IEEE Robotics and Automation Letters (RA-L), 2018, 3, 1904-1911
Yang, B.; Wang, G.; Calandra, R.; Contreras, D.; Levine, S. & Pister, K.
Learning Flexible and Reusable Locomotion Primitives for a Microrobot
IEEE Robotics and Automation Letters (RA-L), 2018, 3, 1904-1911
Yang, B.; Wang, G.; Calandra, R.; Contreras, D.; Levine, S. & Pister, K.
Learning Flexible and Reusable Locomotion Primitives for a Microrobot
IEEE Robotics and Automation Letters (RA-L), 2018, 3, 1904-1911
Yang, B.; Wang, G.; Calandra, R.; Contreras, D.; Levine, S. & Pister, K.
Learning Flexible and Reusable Locomotion Primitives for a Microrobot
IEEE Robotics and Automation Letters (RA-L), 2018, 3, 1904-1911
Optimized parameters
Objective function
Parameters to optimize
Context
Yang, B.; Wang, G.; Calandra, R.; Contreras, D.; Levine, S. & Pister, K.
Learning Flexible and Reusable Locomotion Primitives for a Microrobot
IEEE Robotics and Automation Letters (RA-L), 2018, 3, 1904-1911
Liao, T.; Wang, G.; Yang, B.; Lee, R.; Pister, K.; Levine, S. & Calandra, R.
Data-efficient Learning of Morphology and Controller for a Microrobot
IEEE International Conference on Robotics and Automation (ICRA), 2019
Two levels of optimization
(instead of a single bigger optimization)
Liao, T.; Wang, G.; Yang, B.; Lee, R.; Pister, K.; Levine, S. & Calandra, R.
Data-efficient Learning of Morphology and Controller for a Microrobot
IEEE International Conference on Robotics and Automation (ICRA), 2019
Liao, T.; Wang, G.; Yang, B.; Lee, R.; Pister, K.; Levine, S. & Calandra, R.
Data-efficient Learning of Morphology and Controller for a Microrobot
IEEE International Conference on Robotics and Automation (ICRA), 2019
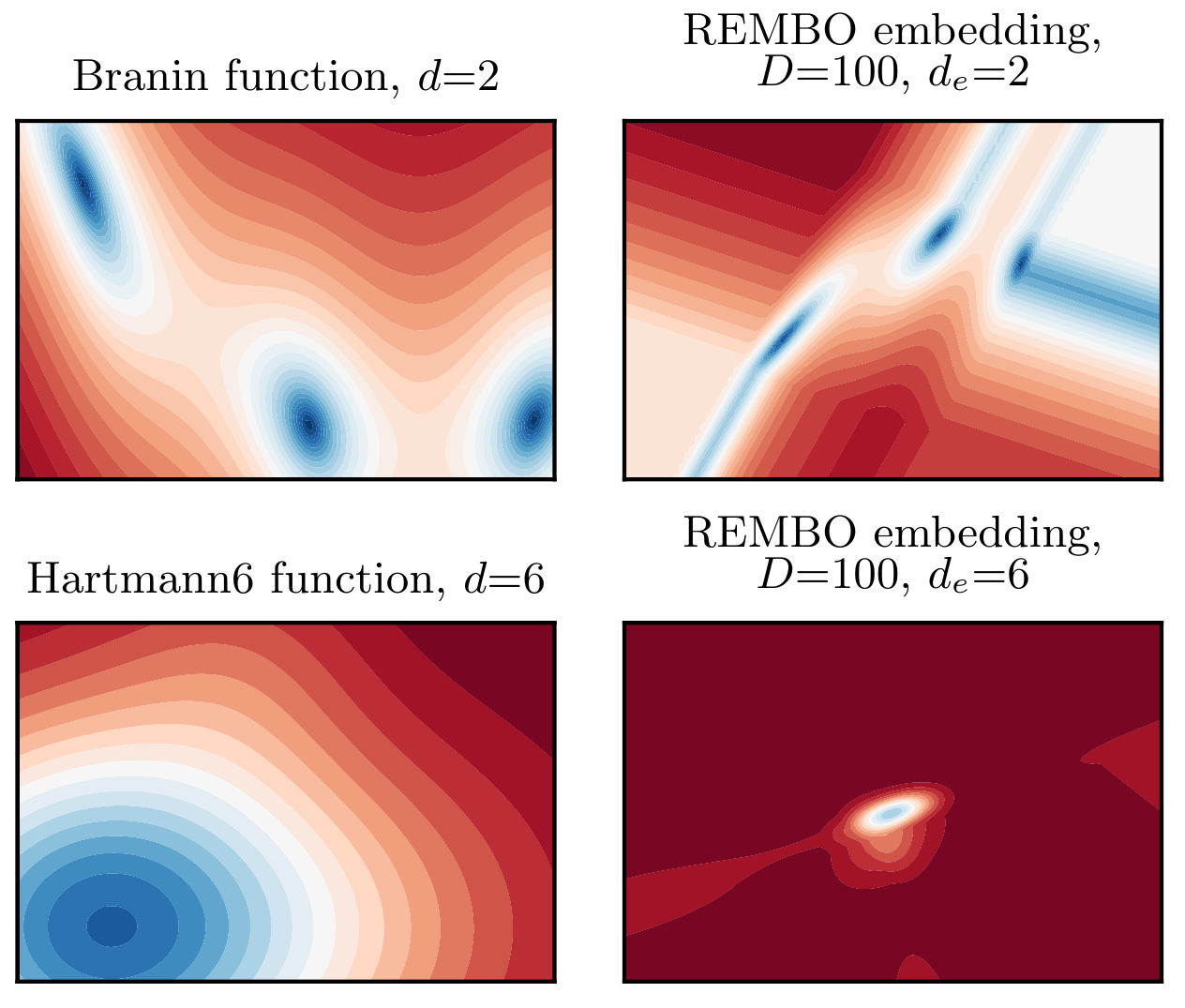
Z. Wang, F. Hutter, M. Zoghi, D. Matheson, and N. de Freitas.
Bayesian optimization in a billion dimensions via random embeddings.
Journal of Artificial Intelligence Research, 55:361–387, 2016
Very neat Idea!
But several wrong assumptions...
Letham, B.; Calandra, R.; Rai, A. & Bakshy, E.
Re-Examining Linear Embeddings for High-dimensional Bayesian Optimization
Advances in Neural Information Processing Systems (NeurIPS), 2020
Letham, B.; Calandra, R.; Rai, A. & Bakshy, E.
Re-Examining Linear Embeddings for High-dimensional Bayesian Optimization
Advances in Neural Information Processing Systems (NeurIPS), 2020
Local convergence guaranteed*
Simple to implement
Computationally light
Does not generalize
Data-inefficient
No convergence guarantees
Challenging to learn model
Computationally intensive
Data-efficient
Generalize to new tasks
Evidence from neuroscience that humans use both approaches! [Daw et al. 2010]
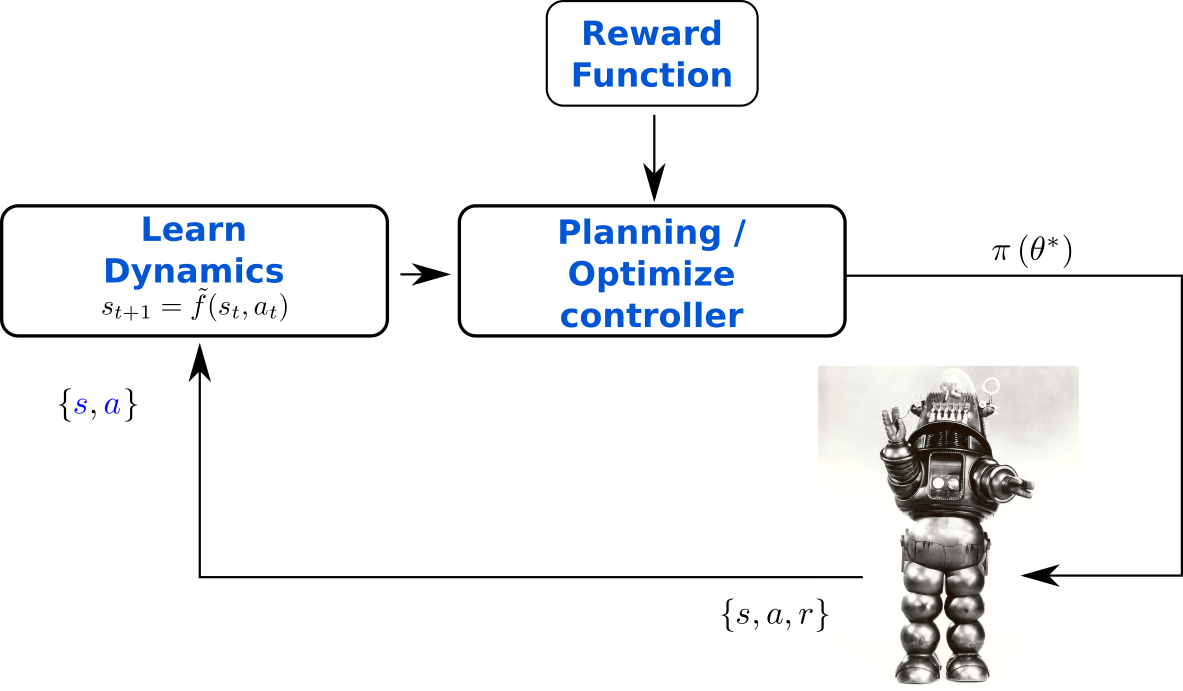
Chua, K.; Calandra, R.; McAllister, R. & Levine, S.
Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models
Advances in Neural Information Processing Systems (NIPS), 2018, 4754-4765
Chua, K.; Calandra, R.; McAllister, R. & Levine, S.
Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models
Advances in Neural Information Processing Systems (NIPS), 2018, 4754-4765
Chua, K.; Calandra, R.; McAllister, R. & Levine, S.
Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models
Advances in Neural Information Processing Systems (NIPS), 2018, 4754-4765
Lambert, N.O.; Drew, D.S.; Yaconelli, J; Calandra, R.; Levine, S.; & Pister, K.S.J.
Low Level Control of a Quadrotor with Deep Model-Based Reinforcement Learning
IEEE Robotics and Automation Letters (RA-L), 2019, 4, 4224-4230
Belkhale, S.; Li, R.; Kahn, G.; McAllister, R.; Calandra, R. & Levine, S.
Model-Based Meta-Reinforcement Learning for Flight with Suspended Payloads
IEEE Robotics and Automation Letters (RA-L), 2021, 6, 1471-1478
Lambeta, M.; Chou, P.-W.; Tian, S.; Yang, B.; Maloon, B.; Most, V. R.; Stroud, D.; Santos, R.; Byagowi, A.; Kammerer, G.; Jayaraman, D. & Calandra, R.
DIGIT: A Novel Design for a Low-Cost Compact High-Resolution Tactile Sensor with Application to In-Hand Manipulation
IEEE Robotics and Automation Letters (RA-L), 2020, 5, 3838-3845
Lambeta, M.; Chou, P.-W.; Tian, S.; Yang, B.; Maloon, B.; Most, V. R.; Stroud, D.; Santos, R.; Byagowi, A.; Kammerer, G.; Jayaraman, D. & Calandra, R.
DIGIT: A Novel Design for a Low-Cost Compact High-Resolution Tactile Sensor with Application to In-Hand Manipulation
IEEE Robotics and Automation Letters (RA-L), 2020, 5, 3838-3845
Lambert, N.; Wilcox, A.; Zhang, H.; Pister, K. S. J. & Calandra, R.
Learning Accurate Long-term Dynamics for Model-based Reinforcement Learning
IEEE Conference on Decision and Control (CDC), 2021, [available online: https://arxiv.org/abs/2012.09156]
(YES)
Zhang, B.; Rajan, R.; Pineda, L.; Lambert, N.; Biedenkapp, A.; Chua, K.; Hutter, F. & Calandra, R.
On the Importance of Hyperparameter Optimization for Model-based Reinforcement Learning
International Conference on Artificial Intelligence and Statistics (AISTATS), 2021
(YES)
Bansal, S.; Calandra, R.; Xiao, T.; Levine, S. & Tomlin, C. J.
Goal-Driven Dynamics Learning via Bayesian Optimization
IEEE Conference on Decision and Control (CDC), 2017, 5168-5173
(NO)
(NO)
Lambert, N.; Amos, B.; Yadan, O. & Calandra, R.
Objective Mismatch in Model-based Reinforcement Learning
Learning for Dynamics and Control (L4DC), 2020, 761-770
Multiplicative Error -- Doomed to accumulate
Lambert, N.; Wilcox, A.; Zhang, H.; Pister, K. S. J. & Calandra, R.
Learning Accurate Long-term Dynamics for Model-based Reinforcement Learning
IEEE Conference on Decision and Control (CDC), 2021, [available online: https://arxiv.org/abs/2012.09156]
(from O(t) to O(1) for any given t)
Calandra, R.; Owens, A.; Jayaraman, D.; Yuan, W.; Lin, J.; Malik, J.; Adelson, E. H. & Levine, S.
More Than a Feeling: Learning to Grasp and Regrasp using Vision and Touch
IEEE Robotics and Automation Letters (RA-L), 2018, 3, 3300-3307
Collected 6450 grasps from over 60 training objects over ~2 weeks.
Calandra, R.; Owens, A.; Jayaraman, D.; Yuan, W.; Lin, J.; Malik, J.; Adelson, E. H. & Levine, S.
More Than a Feeling: Learning to Grasp and Regrasp using Vision and Touch
IEEE Robotics and Automation Letters (RA-L), 2018, 3, 3300-3307
83.8% grasp success on 22 unseen objects
(using only vision yields 56.6% success rate)
Thank you!
By Roberto Calandra




