










































Roberto Calandra PRO
Full Professor at TU Dresden. Head of the LASR Lab. Working in AI, Robotics and Touch Sensing.
Roberto Calandra
Facebook AI Research
Mediterranean Machine Learning Summer School - 13 January 2021
Slides online at: https://slides.com/rcalandra/m2l-2020/
[Calandra, R.; Seyfarth, A.; Peters, J. & Deisenroth, M. P. Bayesian Optimization for Learning Gaits under Uncertainty Annals of Mathematics and Artificial Intelligence (AMAI), 2015, 76, 5-23]
How do we tune the parameters of the controller?
All of these methods were impractical for this problem.
What else can we use?
Bayesian optimization!
Optimized parameters
Objective function
Parameters to optimize
Single minimum
(e.g., convex functions)
Multiple minimum
(a.k.a., global optimization)
First-order
(we can measure gradients)
Zero-order
(no gradients available)
Noise-less
(repeating the evaluation yield the same result)
Stochastic
(repeating the evaluation yield different results)
Nice and easy to solve
(e.g., with gradient descent)
Cheap Evaluation
(virtually infinite number of evaluations allowed)
Difficult to optimize
Expensive Evaluation
(limited to tens or hundreds of evaluations)
Here we want to use BO!
Oil drilling
Design and manufacturing
Drug design
Robotics
Hyperparameters optimization
Vibrant community dedicated to automated machine learning (AutoML)
e.g.,
We can create a surrogate model
Gradient descent
[credit: Marc Deisenroth]
[credit: Marc Deisenroth]
Large variety of models used throughout the literature:
By far the most commonly used (at the moment)
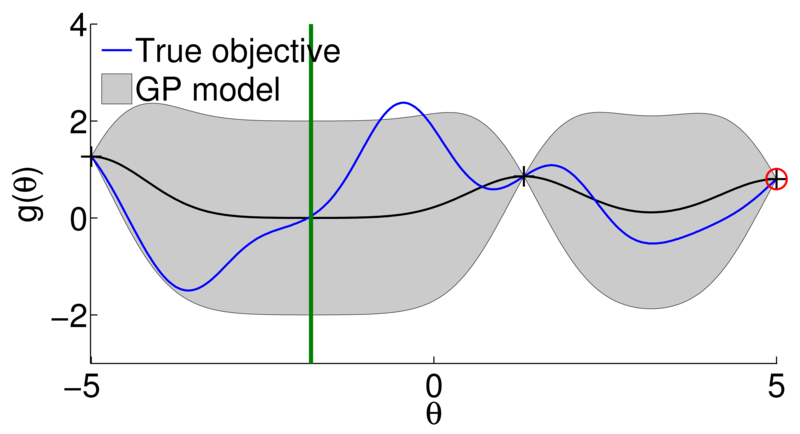
Surrogate model (a.k.a. response surface) need to accurately approximate (and generalize) the underlying function based on the available data
Additional reading:
Rasmussen, C. E. & Williams, C. K. I.
Gaussian Processes for Machine Learning
The MIT Press, 2006
Mean of a GP = Kernel ridge regression
Square exponential
parameters of the GP
(often referred to as hyperparameters)
Multiple ways to optimize the hyperparameters
Additional reading:
Rasmussen, C. E. & Williams, C. K. I.
Gaussian Processes for Machine Learning
The MIT Press, 2006
Pro:
Cons:
[credit: Marc Deisenroth]
* But not always
[Calandra, R.; Seyfarth, A.; Peters, J. & Deisenroth, M. P. Bayesian Optimization for Learning Gaits under Uncertainty Annals of Mathematics and Artificial Intelligence (AMAI), 2015, 76, 5-23]
[Calandra, R.; Seyfarth, A.; Peters, J. & Deisenroth, M. P. Bayesian Optimization for Learning Gaits under Uncertainty Annals of Mathematics and Artificial Intelligence (AMAI), 2015, 76, 5-23]
Not Symmetrical (about 5° difference). Why?
Because it is walking in a circle!
[Calandra, R.; Seyfarth, A.; Peters, J. & Deisenroth, M. P. Bayesian Optimization for Learning Gaits under Uncertainty Annals of Mathematics and Artificial Intelligence (AMAI), 2015, 76, 5-23]
Numberless extensions in the literature:
Optimized parameters
Objective function
Parameters to optimize
Context
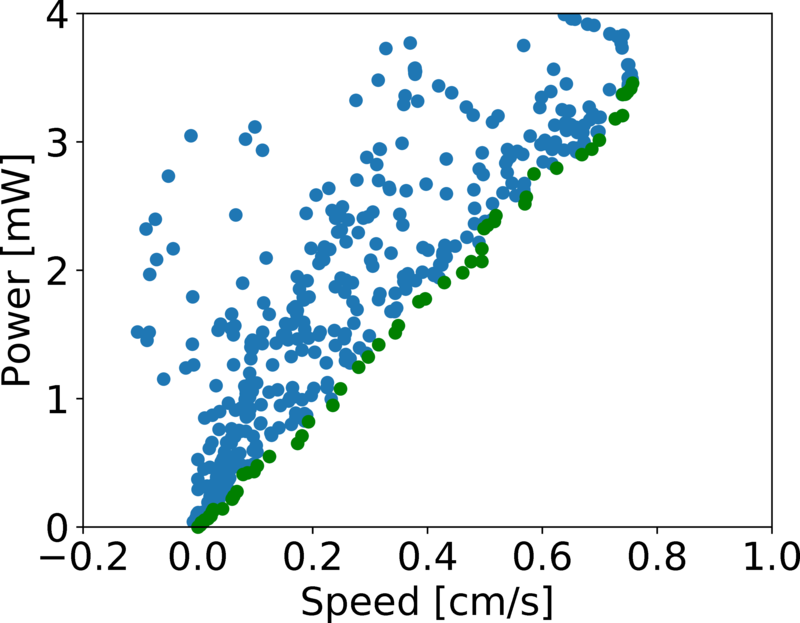
[Yang, B.; Wang, G.; Calandra, R.; Contreras, D.; Levine, S. & Pister, K. Learning Flexible and Reusable Locomotion Primitives for a Microrobot IEEE Robotics and Automation Letters (RA-L), 2018, 3, 1904-1911]
Simulated hexapod:
Pareto Front
[Knowles, J. ParEGO: A hybrid algorithm with on-line landscape approximation for expensive multiobjective optimization problems IEEE Transactions on Evolutionary Computation, 2006, 10, 50-66]
[Yang, B.; Wang, G.; Calandra, R.; Contreras, D.; Levine, S. & Pister, K. Learning Flexible and Reusable Locomotion Primitives for a Microrobot IEEE Robotics and Automation Letters (RA-L), 2018, 3, 1904-1911]
[Yang, B.; Wang, G.; Calandra, R.; Contreras, D.; Levine, S. & Pister, K. Learning Flexible and Reusable Locomotion Primitives for a Microrobot IEEE Robotics and Automation Letters (RA-L), 2018, 3, 1904-1911]
[Yang, B.; Wang, G.; Calandra, R.; Contreras, D.; Levine, S. & Pister, K. Learning Flexible and Reusable Locomotion Primitives for a Microrobot IEEE Robotics and Automation Letters (RA-L), 2018, 3, 1904-1911]
[Yang, B.; Wang, G.; Calandra, R.; Contreras, D.; Levine, S. & Pister, K. Learning Flexible and Reusable Locomotion Primitives for a Microrobot IEEE Robotics and Automation Letters (RA-L), 2018, 3, 1904-1911]
Easy to use, for educational purposes
Well mantained, my choice atm
No active development
No active development
No active development
No active development
Please give Feedback at: https://tinyurl.com/m2l-bayesian-optimization
Questions ?
Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R. P. & de Freitas, N.
Taking the human out of the loop: A review of Bayesian optimization
Proceedings of the IEEE, IEEE, 2016, 104, 148-175
Rasmussen, C. E. & Williams, C. K. I.
Gaussian Processes for Machine Learning
The MIT Press, 2006
Knowles, J.
ParEGO: A hybrid algorithm with on-line landscape approximation for expensive multiobjective optimization problems
IEEE Transactions on Evolutionary Computation, 2006, 10, 50-66
Hutter, F.; Hoos, H. H. & Leyton-Brown, K.
Sequential model-based optimization for general algorithm configuration
Learning and Intelligent Optimization (LION), Springer, 2011, 507-523
Snoek, J.; Larochelle, H. & Adams, R. P.
Practical Bayesian Optimization of Machine Learning Algorithms
arXiv preprint arXiv:1206.2944, 2012
Simulated hexapod:
[Yang, B.; Wang, G.; Calandra, R.; Contreras, D.; Levine, S. & Pister, K. Learning Flexible and Reusable Locomotion Primitives for a Microrobot IEEE Robotics and Automation Letters (RA-L), 2018, 3, 1904-1911]
[Yang, B.; Wang, G.; Calandra, R.; Contreras, D.; Levine, S. & Pister, K. Learning Flexible and Reusable Locomotion Primitives for a Microrobot IEEE Robotics and Automation Letters (RA-L), 2018, 3, 1904-1911]
[Yang, B.; Wang, G.; Calandra, R.; Contreras, D.; Levine, S. & Pister, K. Learning Flexible and Reusable Locomotion Primitives for a Microrobot IEEE Robotics and Automation Letters (RA-L), 2018, 3, 1904-1911]
By Roberto Calandra
[M2L - 13 January 2021]




