CMSC 304
Social and Ethical Issues in Information Technology

Fairness + Algorithmic Bias
Bias
Algorithms
Accountability
Quiz Review


- authors describe a "leap of faith" when applying patterns found in historical data to predict individual outcomes, assuming that "unknown outcomes...in the life trajectory of an individual follow the patterns they have found."
- machine learning systems trained on historical data are likely to reflect "historical prejudices against certain social groups, prevailing cultural stereotypes, and existing demographic inequalities," leading the system to "replicate these very same dynamics." This means that even if the system is built with good intentions, it can still reinforce and perpetuate existing inequalities due to biases embedded in the data.


Announcements
- Our activity on Wednesday will be online, pls bring your laptops and a charger!
- If you haven't already, please check your email and respond to the survey
Recap: Data, Information, Knowledge, Wisdom
- New information is always slotted into current knowledge, your brain doesn’t erase every time
- Knowledge exists before data and information-- our worldview shapes them
- a worldview = implicit assumptions, perspectives, or biases that shape how data is collected, interpreted, and presented
- Just like an individual's worldview affects how they perceive and interpret the world
- a dataset's worldview can include:
- selecting which data to collect. This is guided by assumptions and priorities
- deciding how to collect it. Surveys, instruments, sensor placement, cookies, etc
- what NOT to collect. Populations of interest, generalizations, etc.
Recap: Data Worldviews
-
There's no such a thing as "raw data" or "objective data"
-
"Data need to be imagined as data to exist and function as such, and the imagination of data entails an interpretative base"
- a person selects which data is relevant
- a person cleans that data
- a person has to give the data context and meaning
-
"Data need to be imagined as data to exist and function as such, and the imagination of data entails an interpretative base"
- It's not possible to create systems that are completely independent of human thought processes
- this makes sense, because what are we trying to do with AI in the first place? Replicate human capabilities!
- Data not only produces knowledge, it is also the product of human knowledge


When we ignore data's worldview, we get "bias"
- The term "bias" is overloaded
Function or method overloading occurs when multiple functions or methods have the same name but different parameter lists (either in number, type, or both).

When we ignore data's worldview, we get "bias"
- The term "bias" is overloaded
- in statistics it means "a systematic tendency for the true value and estimated value for a population differ"
- common example = selection bias: sample is not chosen randomly, so estimates are inaccurate
- we want to measure median income of a county, so we post a survey QR code at the bank and ask people to fill it out
- common example = selection bias: sample is not chosen randomly, so estimates are inaccurate
- in cognitive science it means a "brain shortcut" we use to make decisions. Sometimes those decisions are irrational
- optimism bias: believe things will work out
- status quo bias: do something because it requires less cognitive effort (hungry judges)
- in statistics it means "a systematic tendency for the true value and estimated value for a population differ"
When we ignore data's worldview, we get "bias"
- The term "bias" is overloaded
- in statistics it means "a systematic tendency for the true value and estimated value for a population differ"
- in cognitive science it means a "brain shortcut" we use to make decisions. Sometimes those decisions are irrational
- colloquially, people use the term to insinuate someone has inclination for or against some people, ideas, or things, leading to injustice
- in AI ethics, bias means using past data to make future judgements or predictions in ways that may disproportionally affect different groups
Algorithmic Decision-making
-
What is an algorithm?
- A set of rules and procedures that leads to a decision
- Could be machine learning, or simply control flow logic (rule-based if-then-else)
-
What can algorithms do for us?
- They improve accuracy and efficiency over human decision-making
- Algorithms can make decisions faster and more consistently than humans
- We can just create the model to be optimal, since it's just numbers (right?)
-
How can algorithms harm us?
- "An algorithm is only as good as ..."
- its training data
- its designer
- Widespread rapid adoption can encode bias, threaten fairness, erase privacy, transparency, and due process
- "An algorithm is only as good as ..."

What is fairness to an algorithm?
due process:
a legal principle ensuring that everyone is entitled to a fair and impartial procedure before being deprived of life, liberty, or property.
...
For algorithms in society, this means that people should have the right to:
- Understand how algorithms affect them
- Challenge and correct unfair or biased outcomes
- Access their data and control how it is used
- Seek recourse if harmed by algorithmic decisions
Burton, Emanuelle; Goldsmith, Judy; Mattei, Nicholas; Siler, Cory; Swiatek, Sara-Jo. Computing and Technology Ethics: Engaging through Science Fiction (pp. 117-118). MIT Press.
hungry judges
a study of parole boards in 2011 found that parole was granted nearly 65% of the time at the start of a session, barely above 0% right before a meal break, and again nearly 65% after a break
...
hungry judges are harsher judges!

The promise of "algorithms"
- Many modern systems rely on some combination of data, algorithms, AI/ML to make decisions and manage complex processes
- sometimes you'll see this called buzzwords "data-driven" or "AI-powered"
- Automated decision-making systems are typically meant to improve and enhance human decision-making
- medical diagnosis
- bail and sentencing
- finance and lending
- product recommendation
- The implication is that human decision-making is flawed, and automated systems can remove human bias, inefficiency, limitation for information processing, speed, etc.
Fairness in Algorithmic Decision-making
- Algorithms require formalization of what to compute
- you need to actually write an equation of your goal i.e. an objective function
- What is the cost of making each decision?
- you need to actually write an equation of your goal i.e. an objective function
- You also need to write an equation for evaluating the results for accuracy and fairness
- If we want to use algorithms to make decisions, it forces us to be precise about what we think "fairness" is and how we define it
- Let us now look at how we can define fairness

\text{cost} = f(\text{benefit}, \text{risks})
https://web.stanford.edu/class/cs182/
Fairness in Machine Learning
- Machine learning algorithms will inevitably make mistakes
- “Fairness” asks: how are those mistakes distributed across individuals and groups?
- e.g. do certain sub-populations suffer a disproportionately high rate of errors?
https://www.fdic.gov/analysis/cfr/consumer/2018/documents/aaron-roth.pdf
Solon Barocas and Moritz Hardt, "Fairness in Machine Learning", NeurIPS 2017

Criteria for Algorithmic Accountability
- Does it work? (Efficiency to achieve public safety)
- Is it fair? (Fairness)
- Can people understand how it works? (Transparency)
- Can people appeal its judgment? (Due Process)
- Does it use information that an individual might reasonably expect to remain private? (Privacy)
https://web.stanford.edu/class/cs182/
How do we balance the value of an algorithm in terms of achieving public safety against other values beyond fairness?
- What else do we value? How do encode that in law or policy?

Human Decision-making
Example: Ford Pinto

https://www.classiccarstodayonline.com/classic-car-print-advertisements/ford-1974-ford-pinto-ad-a/
https://www.tortmuseum.org/ford-pinto/#images-1

-
Since $137 M > $49.5 M, they said "meh"
-
It did not go well
-
500-900 people burned to death.
-
Ford found not guilty of homicide. Did the recall afterwards. Incurred legal fees.
-
Human Decision-making
Example: Ford Pinto
Expected payout for potential accidents:
- Estimated incidents: 180 burn deaths, 180 serious burn injuries, and 2,100 vehicles lost in fires annually.
- Value assigned per fatality: $200,000
- Value per injury: $67,000
- Value per vehicle lost: $700
- Using these figures, Ford calculated the total cost of settlements for burn deaths, injuries, and vehicle losses to be approximately $49.5 million.
Cost to fix the fuel tank design:
- $11 part cost per vehicle
- With 12.5 million vehicles and 1.5 million light trucks potentially affected, the total cost to fix all vehicles was calculated at approximately $137 million.
-
Since $137 M > $49.5 M, they said "meh"
-
It did not go well
-
500-900 people burned to death.
-
Ford found not guilty of homicide. Did the recall afterwards. Incurred legal fees.
-
Human Decision-making
Example: Ford Pinto
Expected payout for potential accidents:
- Estimated incidents: 180 burn deaths, 180 serious burn injuries, and 2,100 vehicles lost in fires annually.
- Value assigned per fatality: $200,000
- Value per injury: $67,000
- Value per vehicle lost: $700
- Using these figures, Ford calculated the total cost of settlements for burn deaths, injuries, and vehicle losses to be approximately $49.5 million.
Cost to fix the fuel tank design:
- $11 part cost per vehicle
- With 12.5 million vehicles and 1.5 million light trucks potentially affected, the total cost to fix all vehicles was calculated at approximately $137 million.
Human Involvement in Algorithmic Decision-making
The "Loop"

Think about the difference between using automated systems with different levels of:
- severity of harm
- probability of harm
Human Involvement in Algorithmic Decision-making
The "Loop"
Human-out-of-the-loop (Quadrant 3)
Where the probability of harm is low & severity of harm is low, the system no longer needs humans to help make a decision. In this scenario, the AI runs on its own without human supervision.
Human-over-the-loop (Quadrants 1 and 4)
Humans mediate when it's determined an automated system has failed. However, if humans are not paying attention, AI will continue without human intervention.
Human-in-the-loop (Quadrant 2)
Probability of harm and the severity of harm is high, requires a human to be part of that decision. AI provides suggestions to humans. If there is no human to make a decision, no action is executed.
HUMAN OVER THE LOOP
Example 1: Traffic prediction systems. Automated system will suggest shortest route to next destination. Humans can overturn that decision.
Example 2: Some cybersecurity solutions. Important company data is protected by a firewall and encrypted. Hackers are unlikely to penetrate your firewall and decrypt encrypted data. However, if they do, severity is high. For insidious new attacks, humans should pay close attention to what is happening.
HUMAN OUT OF THE LOOP
Example 1: Recommendation engines. Many e-commerce sites will help consumers find the products they are most likely to buy, Spotify recommends songs you want to listen to next. The probability of damage is low, and the severity of seeing disliked shoes or hearing disliked songs is also low. Humans are not necessary. What about recommending news articles?
Example 2: Translators. Except in highly delicate situations, AI-based translation systems are improving at such a rapid rate that we will not need humans soon. AI is learning how to conduct basic translation and how to translate the meaning of slang and localized meanings of words.
HUMAN IN THE LOOP
Example 1: Medical diagnosis and treatment. AI can help a doctor to determine what is wrong with you. Furthermore, AI can suggest treatment for you by examining the outcomes from other patients with a similar diagnosis. The AI will be aware of patient outcomes that our doctor is not aware of. AI is making our doctors more educated, and we want our doctors to make the final decision.
Example 3: Lethal Automated Weapon Systems (LAWS). Severity of harm is so high (shooting the wrong target) that it overrides whatever the probability of harm is (for now). In "rights-conscious nations," no LAWS can fire without human confirmation.
...
DODD 3000.09 requires that all systems, including LAWS, be designed to “allow commanders and operators to exercise appropriate levels of human judgment over the use of force.” [...for now]
Predictive Policing
- Several large city police departments are using "analytics" to try and predict where crimes will occur
- send more police to those areas to get ahead of the crime
- If there are more police in an area looking for something to do, more crime will be found
- more scrutiny by police in that area
- leads to "overpolicing"
Overpolicing refers to a situation where law enforcement agencies disproportionately focus their efforts and resources on certain communities, areas, or groups of people, often leading to excessive or unnecessary police presence and intervention. This can result in frequent stops, searches, arrests, and surveillance, particularly targeting marginalized communities, such as racial or ethnic minorities, low-income neighborhoods, or other vulnerable populations.
Weblining
- Allusion to "redlining," a practice of offering services on a selective basis (e.g. home loans or insurance)
- redlining: "withholding of home-loan funds or insurance from neighborhoods considered poor economic risks."
- outlawed by the Fair Housing Act of 1968, we can still see its impacts today
- These "analytics" typically use people's home address (or some other data as a proxy ) as a basis for service availability or price
- tends to result in services being more expensive, or unavailable to neighborhoods that are predominantly poor or have a majority of ethnic minorities
- This lets businesses discriminate against certain groups, while staying within the bounds of law that forbid making such decisions on the basis of race
A proxy is an indirect measure or substitute that is used to represent a variable or concept that is unavailable to measure directly. Proxies are often used when the true variable of interest cannot be observed or measured directly due to practical, ethical, or technical constraints.
~~~
Some proxies can be used to indirectly infer "protected characteristics" like race, gender, religion:
- geographic Location or Zip Code
- first name and surname analysis
- language preference
- alma mater (e.g. HBCU)
Targeted Advertising
- Retailers collect customer purchasing information to predict shoppers' choices and habits, and to advertise according to these
- Advertising servers can also target users for reasons other than shopping
- The Cambridge Analytica scandal (2016-2018)
- Unauthorized harvesting of personal data from millions of Facebook users
- CA used this data to create psychological profiles of voters
- used to target individuals with personalized political advertisements and misinformation campaigns
- Also in 2016 it was shown that Google was displaying ads for high-paying jobs to men more frequently than women
- based on historical characteristics
- Prediction task: who would click on the ad and be successfully hired?
- The Cambridge Analytica scandal (2016-2018)
Sentencing + Bail Software
- Judges in parole cases use "analytics" to determine the likelihood that an individual will re-offend
- this is called recidivism
- Black defendants were 2x as likely to be flagged incorrectly as high-risk, whereas white defendants were 2x as likely to be incorrectly flagged as low-risk
- People tend to be un-concerned with this until it comes for them...
Hiring and Admissions
- Almost universally, algorithms completely control where job ads appear on hiring websites, social media, etc.
- The placement of these ads can reflect historic bias on perceived race, gender, economic, or educational status
- "See? They don't click on our ads, women don't want these high-stress jobs, they want to stay at home and chill with bebe"
- Then, after using ads to "filter" which candidates apply, they also use algorithms to sort and rank resumes and application, reinforcing that bias
- "We ranked Brad #1, since he looks like the other guys at the top, he must be headed there too!"
- This kind of thing happens for college admissions also
The problem with measures
eGFR=175×(\text{Serum Creatinine})^{
−1.154}
×(\text{Age})^{
−0.203}
×(0.742 \text{ if female})×(1.21 \text{ if Black})
- "race multiplier" based on the long-standing but now discredited theory that Black individuals had higher muscle mass, which supposedly increased creatinine levels.
- This assumption fails to consider individual variations within racial groups and led to overestimating kidney function in many Black patients
- made them appear healthier, delaying the diagnosis of kidney disease, making them ineligible for the transplant waiting list
- from a study in the late 1990s, it was widely adopted into clinical practice across the U.S. and internationally. Not addressed until 2022
- Bloodwork seems like it should be objective, but there is bias there as well
- Glomerular filtration rate (GFR) is used to quantify severity of kidney disease
- For Black patients, the formula multiplied the result by a factor of 1.21, while for non-Black patients, it did not apply this multiplier:

Big Data + Bias at its worst
- In all of these examples, "big data" can reproduce existing patterns of bias and discrimination, even when such discrimination is entirely unintentional!
- Many times there is "reinforcement learning" or feedback loops that amplify this and keep people in their place
someone is poor
they have low credit score
potential employer checks credit score, rejects b/c too low
person stays poor
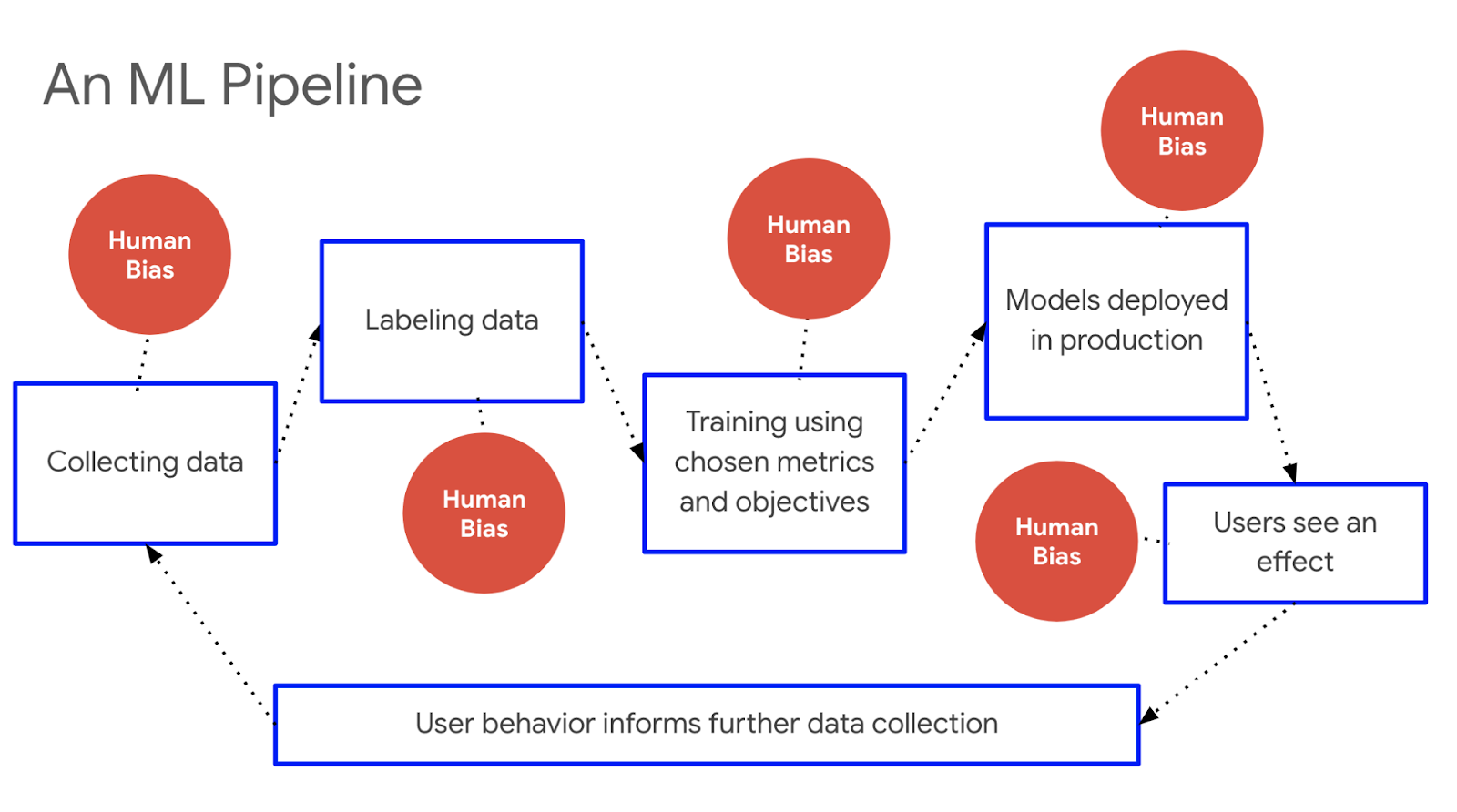
Bias Amplification
Big Data + Bias at its best
- Three main positive roles for algorithms and big data for promoting positive social change
- Synecdoche (this is a wild word I only learned recently. It means "to use something as an example that stands in for a larger whole")
- Diagnostics
- Rebuttal
Big Data + Bias at its best
- Three main positive roles for algorithms and big data for promoting positive social change
- Synecdoche (this is a wild word I only learned recently. It means "to use something as an example that stands in for a larger whole")
- As each new example of bias is unearthed and discussed, it helps the issue gain new attention, which comes with resources and calls for change
- Some great positive outcomes in large, automated decision-making systems to identify people suffering from drug and depression issues, and matching them with treatment options, cutting rates of suicide and overdoses
- Bias can be used for good: In finance there have been massive decreases in fraud and credit card theft through the use of ML systems that are biased by users' individual behavioral data, able to detect anomalies
- Diagnostics
- Rebuttal
- Synecdoche (this is a wild word I only learned recently. It means "to use something as an example that stands in for a larger whole")
Big Data + Bias at its best
- Three main positive roles for algorithms and big data for promoting positive social change
- Synecdoche (this is a wild word I only learned recently. It means "to use something as an example that stands in for a larger whole")
- Diagnostics
- Since systems can be tested for bias, we can use them to perform diagnosis, audit, or "debug" decisions that we have made in the past, and to highlight fairness issues in existing sociotechnical systems
- Rebuttal
Big Data + Bias at its best
- Three main positive roles for algorithms and big data for promoting positive social change
- Synecdoche (this is a wild word I only learned recently. It means "to use something as an example that stands in for a larger whole")
- Diagnostics
- Rebuttal
- We can use large amounts of data to argue against the use of that data in a particular way
- for example, researchers were able to convince Immigration and Customs Enforcement Agency (ICE) to NOT create a system
- ICE wanted a system that predicts whether an immigrant will be a "positive contributing member of society"
- Researchers were able to show that no system could perform that analysis with the proposed data
- We can use large amounts of data to argue against the use of that data in a particular way
So as a developer, is it your fault?
- Cowgill et al. 2020 conducted a study to answer the question:
- Are biases introduced by biased data or biased developers??
- Since CS professionals are not representative of the general population that will be impacted by their system (higher socio-economic status, more education, etc.), do they therefore write biased algorithms?
- Since data has a worldview, and historical data encodes any bias that was present at that time, is it the data that causes the bias?
- In their study they examined over 400 AI professionals and analyzed their characteristics and code and found that there is no evidence that minority or low-implicit-bias workers generate better, less biased code.
- They found that overwhelmingly, better data leads to less biased algorithms
- Are biases introduced by biased data or biased developers??
Activity: Choose one w/ your table










Feedback Loops
Social media: A user interacts with content supporting a particular political view → the system recommends similar content → user continues engaging with similar content, deepening their viewpoint → system reinforces this trend by recommending even more similar content, creating an echo chamber.
Health analytics: A person in a low-income area with limited healthcare access has a poor health outcome → the model predicts high risk for future health issues, prioritizing emergency treatment over preventive care → person receives only limited treatment → health does not improve → cycle repeats.
Activity #1
2 main notions of fairness
- Individual fairness
- Group fairness
https://chrispiech.github.io/probabilityForComputerScientists/en/examples/fairness/
Example: ads that target software engineers
Task: build a classifier that predicts whether a user is a Software Engineer, in order to serve them a relevant ad
-
Inputs: user data
- Browsing history, location, language, interests…
- Outputs: predict whether the user is a Software Engineer (SWE)
our moral intuition tells us we should NOT include race and gender in our input dataset for this task!
- How do we know if the classifier we built is “fair”?
-
What do we mean by fair?
- equal vs equitable opportunity?
- fair for whom? individual? group?
Remember how we can evaluate classifiers
-
TPR (true positive rate): something that is good for the individual
- SWE classifier, likely to graduate, likely to get a loan
- also called Recall: "Of all the actual positive instances, how many did the model correctly identify as positive?" It's important in situations where it is critical to identify as many positive instances as possible (maximum coverage), even if it means allowing some false positives.
-
FPR (false positive rate): something that is harmful for the individual
- Likely to recommit a crime, likely to go bankrupt, screening for terrorists
- "Of all the actual negative instances, how many did the model incorrectly classify as positive?" It reflects the model's tendency to produce false alarms.
-
Precision: the ratio of true positive predictions to the total number of positive predictions made by the model (both true positives and false positives).
- Precision answers the question, "Of all the instances that the model predicted as positive, how many were actually positive?" It reflects the accuracy of the positive predictions made by the model.
precision = coverage
recall = accuracy of the things you want to detect


actual thing you want to detect
not the thing you want to detect
Precision Recall Primer
Evaluating for bias: Precision
- We want to make sure our classifier is good to go, so we check the rates individually for different groups
- we do this, because we took CMSC 304 and learned that there can be socio-economic, gender, and racial disparities when serving targeted ads
- looking good, the Precision for low- income is approximately the same as for high income
- This means that across the board, there's a ~75% probability that a person that is a SWE will be identified as a SWE, from their user data
- now they can enjoy that ad


low income
high income
Precision
Evaluating for bias: Recall
- hmm, the Recall for low income is much lower than it is for high income
- smaller recall = for lower income people who are actually software engineers, more of them are being classified as "not software engineers" and not getting served the ad
- is this a good or bad thing?
- maybe good if you hate ads
- maybe bad if those ads are for high paying jobs
- is this a good or bad thing?
- We want to make sure our classifier is good to go, so we check the rates individually for different groups
- we do this, because we took CMSC 304 and learned that there can be socio-economic, gender, and racial disparities when serving targeted ads

low income
high income
Recall
Precision and Recall as Probabilities
- a more concise way to write them
- the vertical line means "given", or "out of how many?"

Pr (Y = \text{SWE | } \hat{Y} = \text{SWE})
Pr (\hat{Y} = \text{SWE | } Y = \text{SWE})
- Y hat = predicted class
- Y = true class
"Given (out of) all the predicted SWE's, how many were actually SWE's?"
"Given (out of) all the actual SWE's, how many did the model correctly identify as SWE?"

low income
high income
low income
high income
Why might this be?
- Recall might be lower for a group if:
- those examples are underrepresented in the training data
- The model may not learn to recognize patterns or features associated with that group effectively.
- As a result, the model might miss positive instances (e.g., correctly identifying members of that group), leading to lower recall
- if the training data has different features between groups. e.g. maybe SWE's with higher income have more time to surf the web, so there is more rich data
- there may be proxies for income status in the dataset, e.g. zip code, last name, bank cookies
- those examples are underrepresented in the training data
- How can we fix it?
How to fix it?
- How can we fix it?
- and how will we know it's fixed?
- option 1: aim for statistical parity
- equalize [positive thing] among the groups
Pr (\hat{Y} = \text{SWE | } \text{Rich ppl}) = Pr (\hat{Y} = \text{SWE | } \text{Poor ppl}) = ...
note the nuanced difference between this and recall:
- here we just want to equalize the positive thing regardless of whether it's correct or not
Pr (\hat{Y} = \text{SWE | } \text{Group} = n) = \frac{\text{TP} + \text{FP}}{\text{\#people in dataset}}
Pr (\hat{Y} = \text{SWE | } Y = \text{SWE}) = \frac{TP}{\text{all actual SWEs}}
- recall is the percentage of correct positives
- Y hat = predicted class
- Y = true class
For strict statistical parity, the goal is to equalize the "positive" outcomes only
How to fix it?
- How can we fix it?
- and how will we know it's fixed?
- option 2: aim for equal odds
- equalize [correct positive thing] among the groups (recall): SWE's that are correctly identified as SWE
- also equalize [incorrect positive thing] (false positive rate): people that are incorrectly identified as SWE
Pr (\hat{Y} = \text{SWE | } Y=\text{SWE}, \text{Rich}) = Pr (\hat{Y} = \text{SWE | } Y=\text{SWE},\text{Poor}) = ...
Pr (\hat{Y} = \text{SWE | } Y = \text{SWE}) = \frac{TP}{\text{all actual SWEs}}
- recall is the percentage of correct positives
- Y hat = predicted class
- Y = true class
- false positive rate is the percentage of incorrect positives out of all negatives
Pr (\hat{Y} = \text{SWE | } Y = \text{not SWE}) = \frac{FP}{\text{all people in dataset that aren't SWEs}}
As with everything, Pros and Cons
Strict Statistical Parity / Group Fairness
Pros
- easy to understand and explain
- provides equal access to opportunities
- ensures no group is underrepresented
Cons
- may overlook individual merit, potentially leading to reverse discrimination
- may reduce overall model accuracy, particularly if base rates differ across groups
- does not address differences in error rates (e.g., false positives/negatives) across groups
Rule of Thumb (context sensitive!!): Use SSP when the cost of false alarms is low
- e.g. serving ads
- loan applications
As with everything, Pros and Cons
Equal Odds
Pros
- ensures equal TPR and FPR across groups
- balances opportunities with minimizing harm
- reduces the risk of unfair treatment due to errors
Cons
- harder to understand and explain, requiring technical expertise
- can conflict with other fairness goals like overall accuracy or statistical parity.
- difficult to achieve in practice, especially with differing base rates
Rule of Thumb (context sensitive!!): Use EO when the cost of false alarms is high
- e.g. sentencing software
- predicting need for chemotherapy
A caution about metrics
- Metrics can help us determine whether we are on the right track
- but we should not have an over-reliance on metrics
- they often don't tell the whole story
- they can't cancel deeper issues in the data and in society, or where data doesn't exist
- Metrics are very utilitarian, and it can be important to:
- not reduce individuals to the groups they belong to
- recognize possible harms with the "optimization mindset"
- Some notions of fairness are mutually exclusive, so you cannot find one definition of fairness to rule them all
- for example, equalized odds and demographic parity (Barocas et al., 2017)
Fairness + Algorithmic Bias
By Rebecca Williams



