CMSC 304
Social and Ethical Issues in Information Technology

Evaluating AI
AI & Machine Learning
Model Cards
Quiz Review

Quiz Review
Announcements
- Check your email for the one I sent about your peer feedbacks and due date for revisions!
- Paper grades will be replaced once revisions are in
- Check with TA if you have a question that's not answered in the rubric or comments
- This week we return back to our usual rhythm. As a reminder our usual policies are:
- Pls don't bring laptops and do other work in class
- Short reading quiz on Monday (today!)
- (short) reflection journal due this Friday
- The reading for next Monday is lorge, I recommend starting early
- I've left some notes in the margins for items to focus on, and also some general questions in the bookmark
AI vs. ML vs. DL

https://blogs.nvidia.com/blog/whats-difference-artificial-intelligence-machine-learning-deep-learning-ai/
-
AI has been a topic of imagination and research since 1956, where computer scientists formally established the field.
-
Early machine learning included artificial neural networks inspired by biology of our brains: interconnections between neurons. Basically laughed at until 2012.
-
Computer vision emerged as a major application area for machine learning, though it initially required significant hand-coding.
-
Deep learning starting in 2015 made advances on all of the above. This recent AI explosion driven by the availability of GPUs.

Graphical Processing Unit (GPU)
a specialized electronic circuit designed to accelerate the processing of images and videos. Prior to AI/ML, they were primarily used for rendering graphics in computers and gaming systems.
...
They are highly effective at parallel processing, which allows them to handle many computations simultaneously. This capability significantly speeds up tasks that involve large-scale data processing, making them essential for training complex machine learning models.
Colloquially, systems that use any of these tend to be called "algorithms"
Algorithmic Decision-making
-
What is an algorithm?
- A set of rules and procedures that leads to a decision
- Could be machine learning, or simply control flow logic (rule-based if-then-else)
-
What can algorithms do for us?
- They improve accuracy and efficiency over human decision-making
- Algorithms can make decisions faster and more consistently than humans
- We can just create the model to be optimal, since it's just numbers (right?)
-
How can algorithms harm us?
- "An algorithm is only as good as ..."
- its training data
- its designer
- Widespread rapid adoption can encode bias, threaten fairness, erase privacy, transparency, and due process
- "An algorithm is only as good as ..."
What is fairness to an algorithm?
due process:
a legal principle ensuring that everyone is entitled to a fair and impartial procedure before being deprived of life, liberty, or property.
...
For algorithms in society, this means that people should have the right to:
- Understand how algorithms affect them
- Challenge and correct unfair or biased outcomes
- Access their data and control how it is used
- Seek recourse if harmed by algorithmic decisions
Burton, Emanuelle; Goldsmith, Judy; Mattei, Nicholas; Siler, Cory; Swiatek, Sara-Jo. Computing and Technology Ethics: Engaging through Science Fiction (pp. 117-118). MIT Press.
hungry judges
a study of parole boards in 2011 found that parole was granted nearly 65% of the time at the start of a session, barely above 0% right before a meal break, and again nearly 65% after a break
...
hungry judges are harsher judges!

The promise of "algorithms"
- Many modern systems rely on some combination of data, algorithms, AI/ML to make decisions and manage complex processes
- sometimes you'll see this called buzzwords "data-driven" or "AI-powered"
- Automated decision-making systems are typically meant to improve and enhance human decision-making
- medical diagnosis
- bail and sentencing
- finance and lending
- product recommendation
- The implication is that human decision-making is flawed, and automated systems can remove human bias, inefficiency, limitation for information processing, speed, etc.
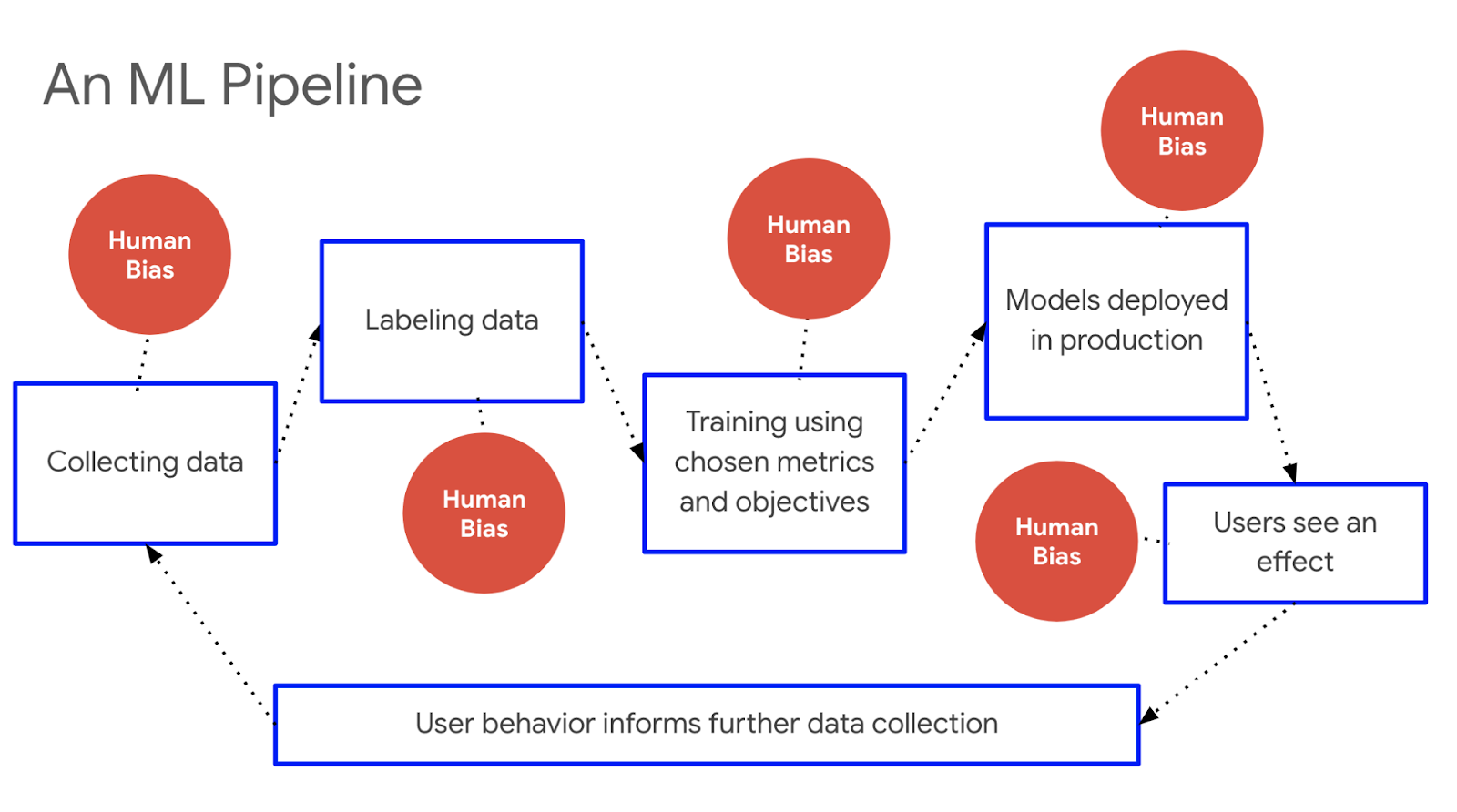
Fairness in Algorithmic Decision-making
- Algorithms require formalization of what to compute
- you need to actually write an equation of your goal i.e. an objective function
- What is the cost of making each decision?
- you need to actually write an equation of your goal i.e. an objective function
- You also need to write an equation for evaluating the results for accuracy and fairness
- Is accuracy the same thing as fairness?
What is fairness to an algorithm?

\text{cost} = f(\text{benefit}, \text{risks})
https://web.stanford.edu/class/cs182/
Criteria for Algorithmic Accountability
- Does it work? (Efficiency to achieve public safety)
- Can people understand how it works? (Transparency)
- Is it fair? (Fairness)
- Can people appeal its judgment? (Due Process)
- Does it use information that an individual might reasonably expect to remain private? (Privacy)
https://web.stanford.edu/class/cs182/
How can we evaluate algorithmic systems to ensure these?
What does Artificial Intelligence have to do with ethics?
Today, many (most?) ethical decisions are written in software
- ranking
- optimization
- recommendations
- content moderation
- When you start dealing with multiple, often competing, objectives or try to account for intangibles like “freedom” and “well-being,” a satisfactory mathematical solution doesn’t always exist.
question: what unintended social consequences arise from the code we write?
question: can we identify potentially unethical code before it hurts people?
https://web.stanford.edu/class/cs182/
Design and Values
Catchphrases:
- Whenever we create a computer system, we select options from a set of design choices
- Our design choices encode a set of values
- e.g. I could make this colorblind friendly, but men have anough advantages already
- e.g. I could
- sometimes your design choices will be limited by regulation
- e.g. dark patterns GDPR
- unsubscribe
- whose values do we use, and why?
- Do Artifacts Have Politics?
- Data is Not Neutral
- some say that exploring and discussing these values is part of your civic duty as a computing professional
Design and Values
- To move from intuition to ethic, we need to surface our values
- In order to examine and evaluate competing values, we have to make them explicit and make them strange
- how do different design choices change outcomes?
- When you start dealing with multiple, often competing, objectives or try to account for intangibles like “freedom” and “well-being,” a satisfactory mathematical solution doesn’t always exist.
- remember:
- goal is NOT to calculate the right answer
- goal is NOT to persuade until unanimous
- goal is to systematically surface and weigh benefits and harms
- ultimately make a decision you can live with
What is Machine Learning?
- We have a wide range of students in this class!
- Sophomores, Juniors, Seniors
- Some have taken courses in Machine Learning, AI, Data Science, some haven't
- Some people have had internships where they work on these areas, some haven't
- Some people have done some self learning / personal projects in these areas
- I want to make sure this module can be understood by everyone, regardless of your pre-reqs, work history, etc.
- SO: if you're already a pro, you may already have experience with these topics
- As you're following along with each topic, think about something that you struggled with when you first learned this stuff
- Think about how you could help a classmate that is feeling a bit lost
- If you learn something new, jot it down!
- SO: if you're already a pro, you may already have experience with these topics
- There will be a quiz question next week on this stuff (there's a reading if you don't catch it all today)
What is Machine Learning?
- The process is the same as "human learning"
- We just need to re-align our vocab

Information about the world
Brain
Complete task based on learned information
Training Data
Prediction
Model
What is Machine Learning?
- To mathify it, let's use an analogy: fitting a line to some points
Information about the world
Brain
Complete task based on learned information
Training Data
Prediction
Model
y = 1.85x - 0.5




rows = individual items
What is Machine Learning?
- To mathify it, let's use an analogy: fitting a line to some points
Information about the world
Brain
Complete task based on learned information
Training Data
Prediction
Model
y = 1.85x - 0.5

What is Machine Learning?
- To mathify it, let's use an analogy: fitting a line to some points
Information about the world
Brain
Complete task based on learned information
Training Data
Prediction
Model
y = 1.85x - 0.5


What is Machine Learning?
- To mathify it, let's use an analogy: fitting a line to some points
y = 1.85x - 0.5
question: is this a "good" model?
How could you evaluate this model to find out?
What is Machine Learning?
- To mathify it, let's use an analogy: fitting a line to some points
y = 1.85x - 0.5
question: is this a "good" model?
How could you evaluate this model to find out?
What is Machine Learning?
- To mathify it, let's use an analogy: fitting a line to some points
y = 1.85x - 0.5
question: is this a "good" model?

"total error"?
sure, but what are the bounds? what's an acceptable value vs. unacceptable?
What is Machine Learning?
- To mathify it, let's use an analogy: fitting a line to some points
y = 1.85x - 0.5
question: is this a "good" model?

more interesting measures:
on average, how much error can we expect in our prediction?
how much variation can we expect in that error?
You may recognize this problem as Linear Regression
What is Machine Learning?
- One of the tasks in machine learning is regression
- in statistics and machine learning, regression means predicting a quantitative dependent variable y based on one or more independent variables x (also called features).
- examples: house price prediction, traffic flow prediction
- Another common task is classification
- classification means predicting a categorical label or class L for a given input based on its features x, y...
- examples: Classifying emails as "spam" or "not spam", identifying objects in images (e.g., "cat," "dog," "car"), assigning multiple topics or tags to a document
Information about the world
Brain
Complete task based on learned information
Training Data
Prediction
Model

image from https://paperswithcode.com/task/classification
let's take a closer look at the "classification" task
What is Machine Learning?
Information about the world
Brain
Complete task based on learned information
Training Data
Prediction
Model



\text{L = ``cat'' if }x < 2.5 \\ \text{else} \\ L = \text{``dog''}
possible model?
x = lbs of food eaten
y = neediness
What is Machine Learning?
Information about the world
Brain
Complete task based on learned information
Training Data
Prediction
Model
\text{L = ``cat'' if }x < 2.5 \\ \text{else} \\ L = \text{``dog''}
x = lbs of food eaten
y = neediness
cat zone
dog zone


What is Machine Learning?
Information about the world
Brain
Complete task based on learned information
Training Data
Prediction
Model
L = f(x,y)
x = lbs of food eaten
y = neediness
cat zone
dog zone

What is Machine Learning?
Information about the world
Brain
Complete task based on learned information
Training Data
Prediction
Model
cat zone
dog zone
question: are these "good" models?
How could you evaluate these models to find out which is better?
L = f(x,y)
How Can We Evaluate Algorithms?
- Let's look at our data again and try a few decision boundaries


How Can We Evaluate Algorithms?
- Let's look at our data again and try a few decision boundaries

instead of measuring error, we can look at accuracy
\text{Accuracy} = \frac{\# \text{correct}}{\text{total}}
A = \frac{6}{7} = 85.7\%
How Can We Evaluate Algorithms?
- Let's look at our data again and try a few decision boundaries

instead of measuring error, we can look at accuracy
\text{Accuracy} = \frac{\# \text{correct}}{\text{total}}
A = \frac{7}{7} = 100\%
How Can We Evaluate Algorithms?
- Let's look at our data again and try a few decision boundaries
instead of measuring error, we can look at accuracy
\text{Accuracy} = \frac{\# \text{correct}}{\text{total}}
A = \frac{6}{7} = 85.7\%


How Can We Evaluate Algorithms?
- Let's look at our data again and try a few decision boundaries
instead of measuring error, we can look at accuracy
\text{Accuracy} = \frac{\# \text{correct}}{\text{total}}
A = \frac{6}{7} = 85.7\%
A = \frac{7}{7} = 100\%
A = \frac{6}{7} = 85.7\%
How Can We Evaluate Algorithms?
- Let's look at our data again and try a few decision boundaries
instead of measuring error, we can look at accuracy
\text{Accuracy} = \frac{\# \text{correct}}{\text{total}}
A = \frac{6}{7} = 85.7\%
A = \frac{7}{7} = 100\%
A = \frac{6}{7} = 85.7\%

we can also ask, which classes get confused with others?
How Can We Evaluate Algorithms?
- Let's look at the model's confusion between classes
instead of measuring error, we can look at accuracy
\text{Accuracy} = \frac{\# \text{correct}}{\text{total}}
A = \frac{6}{7} = 85.7\%
A = \frac{7}{7} = 100\%
A = \frac{6}{7} = 85.7\%
we can also ask, which classes get confused with others?
How Can We Evaluate Algorithms?
- Let's look at the model's confusion between classes


How Can We Evaluate Algorithms?
- Let's look at the model's confusion between classes
How Can We Evaluate Algorithms?
- Let's look at the model's confusion between classes
predicted labels
true labels
How Can We Evaluate Algorithms?
- Let's look at the model's confusion between classes
predicted labels
true labels
2
1
0
3
How Can We Evaluate Algorithms?
- Let's look at the model's confusion between classes
predicted labels
true labels
3
0
1
2
predicted labels
true labels
3
0
1
2
How Can We Evaluate Algorithms?
- Let's look at the model's confusion between classes
predicted labels
true labels
3
0
1
2
predicted labels
true labels
3
0
1
2
Rows are called False Negatives
Columns are called False Positives
Entries on the diagonal are called True Positives
- False Negative = error of omission. Item was predicted as "dog," was in fact a "cat"
- False Positive = error of commission. Item was predicted as "cat," was in fact a "dog"
This is called a Confusion Matrix
Now you try!
Suppose we are evaluating a machine learning algorithm that is trying to perform object detection in this image
We specify three objects of interest that we want the model to classify. These are our labels L
L = {tree, bicycle, shoe}
Here are the model's output predictions

Let's evaluate how the model performed!
Step 1: fill in the data table
Step 2: complete the confusion matrix
true labels
predicted labels

Step 3: tally the errors
- How many true positives?
- How many false negatives?
- How many false positives?

Step 1: fill in the data table
Step 2: complete the confusion matrix

true labels
predicted labels

Step 3: tally the errors
- How many true positives?
- How many false negatives?
- How many false positives?
Step 2: complete the confusion matrix
true labels
predicted labels
Step 1: fill in the data table
7
Step 3: tally the errors
- How many true positives?
- How many false negatives?
- How many false positives?
So overall accuracy = 7/14 = 50%
...
Is this enough to describe the performance?
Step 2: complete the confusion matrix
Step 1: fill in the data table
FN = 1
7
true labels
predicted labels
Step 3: tally the errors
- How many true positives?
- How many false negatives?
- How many false positives?
Step 2: complete the confusion matrix
Step 1: fill in the data table
FN = 1
FN = 1
7
true labels
predicted labels
Step 3: tally the errors
- How many true positives?
- How many false negatives?
- How many false positives?
Step 2: complete the confusion matrix
Step 1: fill in the data table
FN = 1
FN = 1
7
true labels
predicted labels
FN = 5
7
Step 3: tally the errors
- How many true positives?
- How many false negatives?
- How many false positives?
Step 2: complete the confusion matrix
7
7
Step 1: fill in the data table
FN = 1
FN = 1
FN = 5
true labels
predicted labels
FP = 5
Step 3: tally the errors
- How many true positives?
- How many false negatives?
- How many false positives?
Step 2: complete the confusion matrix
7
7
Step 1: fill in the data table
FN = 1
FN = 1
FN = 5
true labels
predicted labels
FP = 5
FP = 1
Step 3: tally the errors
- How many true positives?
- How many false negatives?
- How many false positives?
Step 2: complete the confusion matrix
7
7
Step 1: fill in the data table
FN = 1
FN = 1
FN = 5
true labels
predicted labels
FP = 5
FP = 1
FP = 1
7
Step 3: tally the errors
- How many true positives?
- How many false negatives?
- How many false positives?
true labels
predicted labels
If you're not a fan of this whole summing across the rows and columns thing...
instead you can break them down into 2x2's and then sum them in the 3rd dimension
| Positive | Negative | |
|---|---|---|
| Positive | TP | FN |
| Negative | FP | ~ |
FN = 1
FP = 5
| tree | not tree | |
| tree | 5 | |
| not tree | ~ |
true labels
predicted labels

true labels
predicted labels
If you're not a fan of this whole summing across the rows and columns thing...
instead you can break them down into 2x2's and then sum them in the 3rd dimension
| Positive | Negative | |
|---|---|---|
| Positive | TP | FN |
| Negative | FP | ~ |
FN = 1
FN = 1
FN = 5
FP = 5
FP = 1
FP = 1
| tree | not tree | |
| tree | 5 | |
| not tree | ~ |
true labels
predicted labels
| bike | not bike | |
| bike | 1 | |
| not bike | ~ |
true labels
predicted labels
| shoe | not shoe | |
| shoe | 1 | |
| not shoe | ~ |
true labels
predicted labels
true labels
predicted labels
If you're not a fan of this whole summing across the rows and columns thing...
instead you can break them down into 2x2's and then sum them in the 3rd dimension
| Positive | Negative | |
|---|---|---|
| Positive | TP | FN |
| Negative | FP | ~ |
FN = 1
FN = 1
FN = 5
FP = 5
FP = 1
FP = 1
| tree | not tree | |
| tree | 5 | FN =1 |
| not tree | ~ |
true labels
predicted labels
| bike | not bike | |
| bike | 1 | FN = 1 |
| not bike | ~ |
true labels
predicted labels
| shoe | not shoe | |
| shoe | 1 | FN = 5 |
| not shoe | ~ |
true labels
predicted labels
true labels
predicted labels
If you're not a fan of this whole summing across the rows and columns thing...
instead you can break them down into 2x2's and then sum them in the 3rd dimension
| Positive | Negative | |
|---|---|---|
| Positive | TP | FN |
| Negative | FP | ~ |
FN = 1
FN = 1
FN = 5
FP = 5
FP = 1
FP = 1
| tree | not tree | |
| tree | 5 | FN =1 |
| not tree | FP = 5 | ~ |
true labels
predicted labels
| bike | not bike | |
| bike | 1 | FN = 1 |
| not bike | FP = 1 | ~ |
true labels
predicted labels
| shoe | not shoe | |
| shoe | 1 | FN = 5 |
| not shoe | FP = 1 | ~ |
true labels
predicted labels
Interpreting Evaluation Results
To interpret the results, we need to know "out of how many?" for each class
- For False Positives, we want to know how much each class was over-reported, out of how many opportunities?
- For False Negatives, we want to know how many we missed, out of how many opportunities?
- For True Positives, we want to know how many we got right, out of all opportunities?

predicted labels
true labels

We have some class imbalance
Interpreting Evaluation Results
To interpret the results, we need to know "out of how many?" for each class
- For False Positives, we want to know how much each class was over-reported, out of how many opportunities?
- For False Negatives, we want to know how many we missed, out of how many opportunities?
- For True Positives, we want to know how many we got right, out of all opportunities?
predicted labels
true labels
We have some class imbalance
Summary of the possible outcomes
- True Positives (TP): The number of positive instances correctly classified as positive. E.g., predicting "shoe" when it actually is a shoe.
- False Positives (FP): The number of negative instances incorrectly classified as positive. E.g., predicting "shoe" when it actually is not a shoe.
- True Negatives (TN): The number of negative instances correctly classified as negative. E.g., predicting it is not a shoe when it actually is not a shoe.
- False Negatives (FN): The number of positive instances incorrectly classified as negative. E.g., predicting as "tree" or "bicycle" when it actually is a shoe.
When we have class imbalance, we should report these as percentages or rates, or "out of how many?"
predicted labels
true labels
Summary of the possible outcomes
When we have class imbalance, we should report these as percentages or rates, or "out of how many?"
\text{Recall} = \text{TPR} = \frac{\text{TP}}{TP + FN}
For reasons, we call the True Positive Rate Recall
- True Positives (TP): The number of positive instances correctly classified as positive. E.g., predicting "shoe" when it actually is a shoe.
- False Positives (FP): The number of negative instances incorrectly classified as positive. E.g., predicting "shoe" when it actually is not a shoe.
- True Negatives (TN): The number of negative instances correctly classified as negative. E.g., predicting it is not a shoe when it actually is not a shoe.
- False Negatives (FN): The number of positive instances incorrectly classified as negative. E.g., predicting as "tree" or "bicycle" when it actually is a shoe.
Recall uses all positives as denominator
predicted labels
true labels
Summary of the possible outcomes
When we have class imbalance, we should report these as percentages or rates, or "out of how many?"
\text{Recall} = \text{TPR} = \frac{\text{TP}}{TP + FN}
For reasons, we call the True Positive Rate Recall
- True Positives (TP): The number of positive instances correctly classified as positive. E.g., predicting "shoe" when it actually is a shoe.
- False Positives (FP): The number of negative instances incorrectly classified as positive. E.g., predicting "shoe" when it actually is not a shoe.
- True Negatives (TN): The number of negative instances correctly classified as negative. E.g., predicting it is not a shoe when it actually is not a shoe.
- False Negatives (FN): The number of positive instances incorrectly classified as negative. E.g., predicting as "tree" or "bicycle" when it actually is a shoe.
Recall uses all positives as denominator
predicted labels
true labels
Summary of the possible outcomes
When we have class imbalance, we should report these as percentages or rates, or "out of how many?"
\text{Recall} = \text{TPR} = \frac{\text{TP}}{TP + FN}
For reasons, we call the True Positive Rate Recall
- True Positives (TP): The number of positive instances correctly classified as positive. E.g., predicting "shoe" when it actually is a shoe.
- False Positives (FP): The number of negative instances incorrectly classified as positive. E.g., predicting "shoe" when it actually is not a shoe.
- True Negatives (TN): The number of negative instances correctly classified as negative. E.g., predicting it is not a shoe when it actually is not a shoe.
- False Negatives (FN): The number of positive instances incorrectly classified as negative. E.g., predicting as "tree" or "bicycle" when it actually is a shoe.
Recall uses all positives as denominator
\text{Precision} = \frac{\text{TP}}{TP + FP}
Precision uses predicted positives as denominator
predicted labels
true labels
Summary of the possible outcomes
When we have class imbalance, we should report these as percentages or rates, or "out of how many?"
\text{Recall} = \text{TPR} = \frac{\text{TP}}{TP + FN}
For reasons, we call the True Positive Rate Recall
- True Positives (TP): The number of positive instances correctly classified as positive. E.g., predicting "shoe" when it actually is a shoe.
- False Positives (FP): The number of negative instances incorrectly classified as positive. E.g., predicting "shoe" when it actually is not a shoe.
- True Negatives (TN): The number of negative instances correctly classified as negative. E.g., predicting it is not a shoe when it actually is not a shoe.
- False Negatives (FN): The number of positive instances incorrectly classified as negative. E.g., predicting as "tree" or "bicycle" when it actually is a shoe.
Recall uses all positives as denominator
\text{Precision} = \frac{\text{TP}}{TP + FP}
Precision uses predicted positives as denominator

An ideal classifier has Precision = 1 and Recall = 1
Summary of the possible outcomes
When we have class imbalance, we should report these as percentages or rates, or "out of how many?"
\text{Recall} = \text{TPR} = \frac{\text{TP}}{TP + FN}
For reasons, we call the True Positive Rate Recall
Recall uses all positives as denominator
\text{Precision} = \frac{\text{TP}}{TP + FP}
Precision uses predicted positives as denominator
Precision and Recall are both asking about "how many correct" but from different perspectives:
- Recall: "Out of all the positive examples in our dataset, how many did the classifier get right?
- recall gets worse with more false negatives (missed detections)
- Precision: "Out of all the examples that the classifier predicted as positive, how many were actually positive?
- precision gets worse with more false positives (over-eager detections)
Your turn! Calculate the Precision & Recall
When we have class imbalance, we should report these as percentages or rates, or "out of how many?"
\text{Recall} = \text{TPR} = \frac{\text{TP}}{TP + FN}
Recall uses all positives as denominator
\text{Precision} = \frac{\text{TP}}{TP + FP}
Precision uses predicted positives as denominator

| Tree | Bicycle | Shoe | Overall | |
|---|---|---|---|---|
| Precision | ||||
| Recall |
Your turn! Calculate the Precision & Recall
When we have class imbalance, we should report these as percentages or rates, or "out of how many?"
\text{Recall} = \text{TPR} = \frac{\text{TP}}{TP + FN}
Recall uses all positives as denominator
\text{Precision} = \frac{\text{TP}}{TP + FP}
Precision uses predicted positives as denominator
| Tree | Bicycle | Shoe | Overall | |
|---|---|---|---|---|
| Precision | .5 | .5 | .5 | .5 |
| Recall | .83 | .5 | .16 | .5 |
Now we can explain our classifier with much more descriptive language that can help others understand whether it might treat some classes differently than others!
- the shoe class is more likely to be missed
- trees are least likely to be missed
- all classes have about the same chance of false detections
Your turn! Calculate the Precision & Recall
When we have class imbalance, we should report these as percentages or rates, or "out of how many?"
\text{Recall} = \text{TPR} = \frac{\text{TP}}{TP + FN}
Recall uses all positives as denominator
\text{Precision} = \frac{\text{TP}}{TP + FP}
Precision uses predicted positives as denominator
| Tree | Bicycle | Shoe | Overall | |
|---|---|---|---|---|
| Precision | .5 | .5 | .5 | .5 |
| Recall | .83 | .5 | .16 | .5 |
There's one more summary metric we can compute, called F1 Score:
\text{F1} = 2* \frac{(\text{precision} \times \text{recall})}{\text{precision} + \text{recall}}
harmonic mean of precision & recall
HM, compared to arithmetic mean, tends to mitigate the impact of large outliers and puts more importance on the impact of small ones
Your turn! Calculate the Precision & Recall
When we have class imbalance, we should report these as percentages or rates, or "out of how many?"
\text{Recall} = \text{TPR} = \frac{\text{TP}}{TP + FN}
Recall uses all positives as denominator
\text{Precision} = \frac{\text{TP}}{TP + FP}
Precision uses predicted positives as denominator
| Tree | Bicycle | Shoe | Overall | |
|---|---|---|---|---|
| Precision | .5 | .5 | .5 | .5 |
| Recall | .83 | .5 | .16 | .5 |
| F1 | .62 | .5 | .25 | .46 |
There's one more summary metric we can compute, called F1 Score:
\text{F1} = 2* \frac{(\text{precision} \times \text{recall})}{\text{precision} + \text{recall}}
harmonic mean of precision & recall
HM, compared to arithmetic mean, tends to mitigate the impact of large outliers and puts more importance on the impact of small ones
A Metric Ton of Metrics

https://en.wikipedia.org/wiki/Precision_and_recall
Documenting Classifier Performance and Trade-offs
- Precision Recall Curves
- Model Cards
Visualizing Classifier Trade-offs
https://scikit-learn.org/1.5/auto_examples/model_selection/plot_precision_recall.html

- We computed precision and recall for just one instance of this model
- In real world settings, there are often multiple parameters that we can tune to optimize the number of False Positives, False Negatives, and True Positives that we get
- stuff in the actual model's equation are called hyperparameters
- most of the time, we get a confidence value as output, which needs to be turned into a categorical label L
- probability of an observation belonging to each class determines which label it gets
Visualizing Classifier Trade-offs
- We computed precision and recall for just one instance of this model
- In real world settings, there are often multiple parameters that we can tune to optimize the number of False Positives, False Negatives, and True Positives that we get
- stuff in the actual model's equation are called hyperparameters
- most of the time, we get a confidence value as output, which needs to be turned into a categorical label L
- probability of an observation belonging to each class determines which label it gets
- we can "sweep a curve" over all possible thresholds, and plot the resulting P and R
https://scikit-learn.org/1.5/auto_examples/model_selection/plot_precision_recall.html

Course Rhythm
Text
- bullet
- bullet

Values to sweep?

PR Curves Example
https://stripe.com/en-gi/guides/primer-on-machine-learning-for-fraud-protection

Precision
0.0
1.0
Model Cards
- Model cards are used by algorithm developers and companies to summarize the key performance metrics of their developed system
- essential for reproducibility, transparency, and benchmarking
- conceived by Google in 2018
- include key details:
- the model type
- the training parameters and experimental info (MLFlow is good for experiment tracking)
- which datasets were used to train your model
- the model’s evaluation results
- should also provide a comprehensive assessment of a model’s intended usage, limitations, risks and mitigations, and ethical and safety considerations
https://modelcards.withgoogle.com/about
Example: Object Detection Model Card
https://modelcards.withgoogle.com/object-detection


Example: ChatGPT-o1 System Card
https://openai.com/index/openai-o1-system-card/

Computing Metrics in Python
- You'll probably use skikit-learn for Machine Learning
- Depending on your industry, you'll need to report any of these evaluation results
- We practiced computing these by hand, because scikit-learn doesn't actually give you all the metrics you may need
- scikit-learn doesn't compute FPR for you (is this true? https://machinelearningmastery.com/roc-curves-and-precision-recall-curves-for-classification-in-python/

https://scikit-learn.org/1.5/auto_examples/model_selection/plot_cost_sensitive_learning.html#sphx-glr-auto-examples-model-selection-plot-cost-sensitive-learning-py
Why we messing with all these metrics?
Stay tuned: these are so important for when we talk about fairness in AI

Public Service Announcement
Any time someone doesn't report at least precision and recall, but ideally a confusion matrix, it's as good as....


https://stats.stackexchange.com/questions/423/what-is-your-favorite-data-analysis-cartoon?page=2&tab=votes#tab-top
AI and Machine Learning
By Rebecca Williams



