Knowledge Base Population from German Language Text Leveraging Graph Embeddings
1. Präsentation von Marco Lehner
Problem Description
Reporters lose time for investigating topics twice and performing tedious and easily automatable tasks.
Readers having a hard time finding (background) information on topics of interest.
Newsrooms can't use their collected information in its entirety since it's not machine readable.
Proposed Solution:
Knowledge Base Population
Knowledge base population systems add extracted information to existing Knowledge Bases (KB).
Knowledge Extraction often consists three steps:
- Entity Recognition
- Relation Extraction
- Entity Linking
Challenges
Absence
Extracted Entities are not part of a given KB.
Latency
Knowledge needs to be served to users in real-time.
Evolving Information (not tackled)
Change of facts over time needs to be represented in the KB.
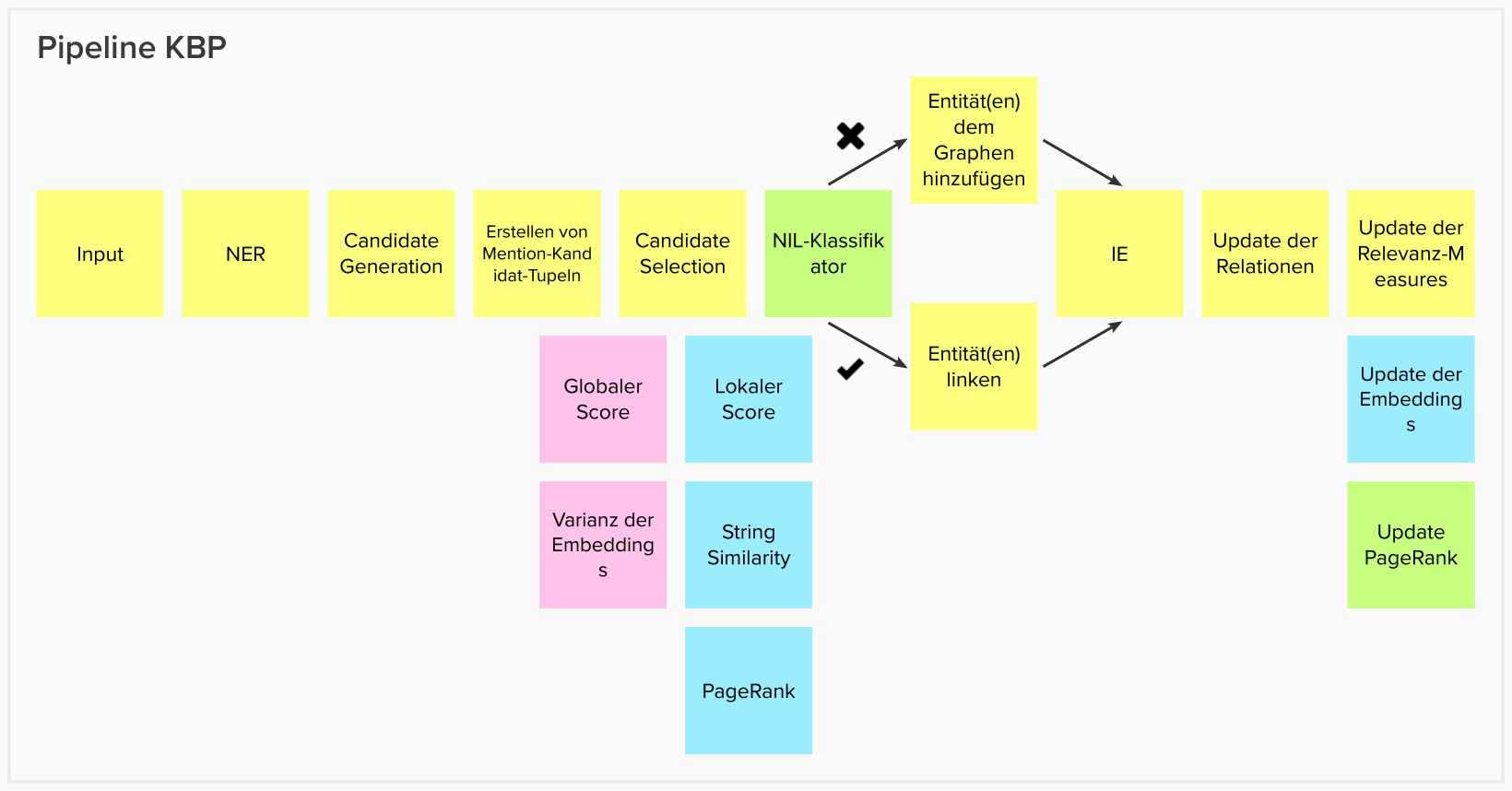
Architecture
Background
- >88 Millionen Knoten
- >1 Terrabyte
- Based on OS rdf4j
- Support of Rank Calculation
- Low Latency
- Bulk Loading
- Optimized for graphs >1B triples
Input
Any text document in german language.
Best results on documents with many entities.
NER
Python wrapper for Stanford Core NLP.
- Support of 66 human languages
- High precision in German NER tasks
- High speed
Candidate Generation
- Get surface form of entity
- Search KB for matching labels
- Create Tupel
- ID
- Label
- Node embedding
- String similarity
- PageRank
Local score
}
Candidate Selection
- Select the tuple with highest local score for each candidate
- Create set of those tuples
- Calculate variance of embeddings
- Randomly change tuples in the set
- If variance is lower, replace old best set
- Break after n iterations or converging global scores.
Global Score
Weighted product of embedding variance and local score.
Entity Classification
- Identify causing tuple
- Mark tuple as NIL
- Recalculate set's global score without tuple
(Baseline)
While the set's global score is below a given threshold
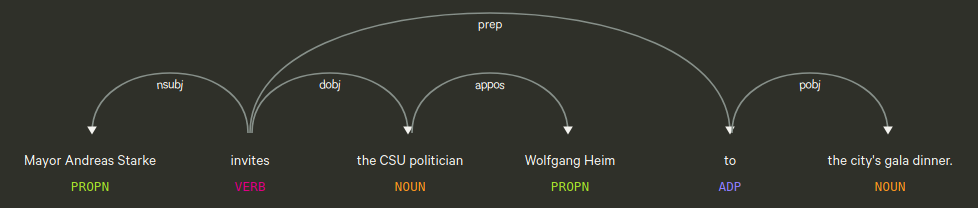
Relation Extraction
- Identify sentence with more than one entity.
- Get dependendy tree of this sentence
- Use lowest verb in tree containing two entities as relation.
(Baseline)
KB Population
- Add new nodes to graph
- Add new relations to graph
- Recalculate GraphRank
- Recalculate embeddings of new and neighboring nodes.
(Baseline)
Calculation of embeddings
Parravicini uses node2vec to calculate embeddings. It is not possible to get embeddings for new nodes.
Therefore GraphSAINT is (probably) used to calculate the embeddings. GraphSAGE trains an encoding function on a subset of the graph which later calculates embeddings for unseen parts of the graph. The structure of the graph has to remain stable.
Todos
- Implement GraphSAINT
- Research German relation extraction frameworks
- Develop evaluation concept
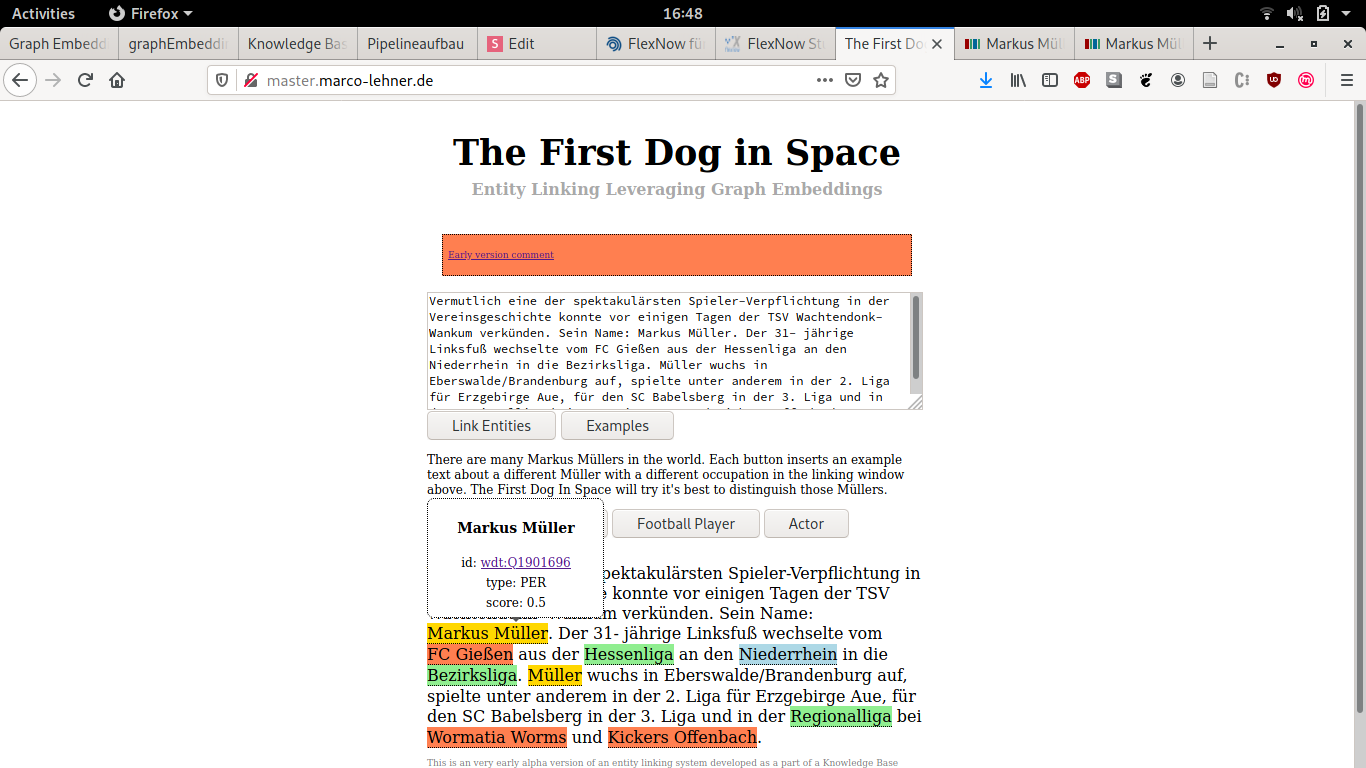
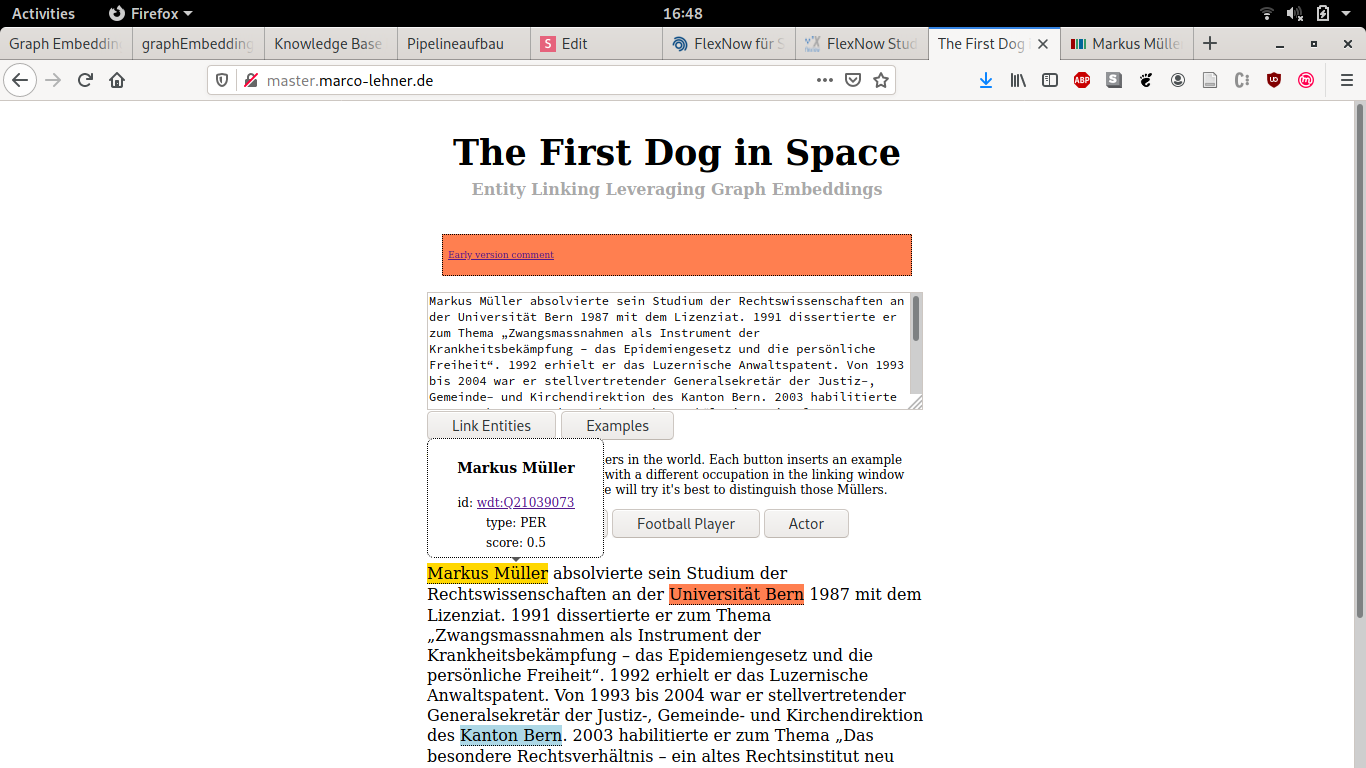
Demo
Knowledge Base Population from German Language Text Leveraging Graph Embeddings
By redadmiral


