












Renato Cordeiro Ferreira
Scientific Programmer @ JADS | PhD Candidate @ USP | Co-founder & Coordinator @CodeLab
An Integrated Implementation of
Probabilistic Graphical Models
2019
Renato Cordeiro Ferreira
Advisor: Alan Mitchel Durham
IME-USP
Probabilistic
Graphical Models
for sequence labeling
Definitions
Model:
A simplified declarative representation that encodes the relevant elements of an experiment or real situation
Probabilistic Model:
A model that is mathematically described using random variables, i.e. functions that maps events \( s \) of a given sample space \( \Omega \) to a discrete or continuous space
Example
Model:
\(N\) is the number of faces in the die (ignores color, material, etc.)
Algorithm:
Generate numbers in the interval \( [1, N] \) (simulate rolling the dice)
Probabilistic Model:
\( \Omega = \{1, \ldots, N\} \), \( P(s) = 1/N \)
\( Even: S \longrightarrow \{0,1\} \) (outcome is even)
Definitions
Multidimensional Probabilistic Model:
Probabilistic model that describes a complex problem with a set of random variables \( \mathcal{X} = \{ Y_1, \ldots, Y_m, X_1, \ldots, X_n \} \)
Joint distribution:
Probability distribution \( P(\mathcal{X}) = P(Y_1, \ldots, Y_m, X_1, \ldots, X_n) \) which can be queried to reason over the model:
- MAP assignment: \( \mathrm{MAP}(\mathbf{Y} \mid \mathbf{X} = \mathbf{x}) = \mathrm{arg\,max}_{\mathbf{y}} P(\mathbf{y}, \mathbf{x}) \)
- Posterior probability distribution: \( P(\mathbf{Y} \mid \mathbf{X} = \mathbf{x}) \)
Example
Sickness diagnosis problem:
Set of patients \( P \)
- Sick? \( S: P \rightarrow \{0, 1\} \)
- Fever? \( T: P \rightarrow \{0, 1\} \)
- Hypertension? \( B: P \rightarrow \{0, 1\} \)
Queries:
Given a patient has fever and hypertension
- Is he sick or not? \( \mathrm{MAP}(S \mid B = 1, T = 1) \)
- How likely is he sick? \( P(S = 1 \mid B = 1, T = 1) \)
output
input
input
Definitions
Probabilistic Graphical Model (PGM):
A probabilistic model that uses a graph to compactly describe the dependencies between random variables and show a factorization of their joint distribution
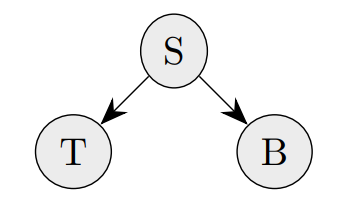
Bayesian Network (BN):
A PGM whose graph is a directed acyclic graph (DAG)
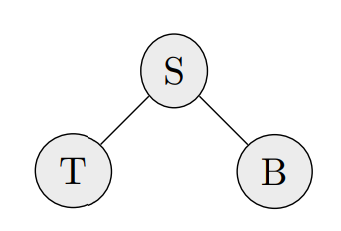
Markov Network (MN):
A PGM whose graph has only undirected edges
Example
Bayesian Network:
A BN for the sickness diagnosis example
(arrows indicate states that influence others)
Generative
Factorization in terms of
Conditional Probability Distributions (CPDs):
\( P(S, T, B) = P(S) P(T | S) P(B | S) \)
Example
Markov Network:
A MN for the sickness diagnosis example
(edges indicate that there is a connection)
Factorization in terms of Factor Functions
\( \Phi(C_i): \mathrm{Im}(C_i) \longrightarrow \mathbb{R}^+ \) where \( C_i \) is a click of the graph: \( P(S, T, B) \propto \Phi(S) \Phi(T, S) \Phi(B, S) \Phi(T) \Phi(B) \)
Generative
Example
Conditional Random Field:
A MN that ignores the clicks related only to input variables (to avoid their complexity)
Factorization in terms of Factor Functions
\( \Phi(C_i): \mathrm{Im}(C_i) \longrightarrow \mathbb{R}^+ \) where \( C_i \) is a click of the graph: \( P(S | T, B) \propto \Phi(S) \Phi(T, S) \Phi(B, S) \)
Discriminative
Definitions
Generative model:
A probabilistic model that factorizes \( P(\mathbf{Y}, \mathbf{X}) \) between the output variables \( \mathbf{Y} \) and the input variables \( \mathbf{X} \)
Discriminative model:
A probabilistic model that factorizes \( P(\mathbf{Y} \mid \mathbf{X}) \) between the output variables \( \mathbf{Y} \) and the input variables \( \mathbf{X} \)
Generative and discriminative equivalents:
Every generative PGM has a discriminative PGM that is structurally equal but represent different distributions
Generative
\( P(S | T, B) \propto \)
\( \Phi(S) \Phi(T, S) \Phi(B, S) \)
Discriminative
\( P(S, T, B) = \)
\( P(S) P(T | S) P(B | S) \)
Increases overfitting
with less data
Generalizes better
with more data
Generative vs Discriminative
Models \(P(\mathbf{X})\), dependencies
between input variables
Requires less knowledge
about the domain described
Ignores \(P(\mathbf{X})\) dependencies
between input variables
Can generate sequences to simulate the process described
Definitions
Structured prediction:
The outcome of the queries over the model represent the structure of a complex object (such as a text or an image) in opposition to a single value
Sequence labeling:
Classify the elements of a sequence in a set of categories
Sequence alignment:
Find a consensus between annotations of a sequence
Example
Dishonest Casino with a game of dices:
- Fair: \( P(s) = 1/6 \)
- Loaded: \( P(1) = 1/2 \)
One player asks a refund for a judge
Sequence labeling:
Given a sequence of outcomes observed by the player during the game:
6 1 4 4 1 2 3 4 6 6 6 2 2 4 6
- When was each die used? (MAP assignment)
- What is the most likely die used on each turn of the game? (Posterior probability)
Example
Dishonest Casino with a game of dices:
- Fair: \( P(s) = 1/6 \)
- Loaded: \( P(1) = 1/2 \)
Two players ask a refund for a judge
Sequence alignment:
Given two different sequences of outcomes observed by the players:
6 1 4 4 1 2 3 4 6 6 6 2 2 4 6
6 1 2 2 4 1 4 3 4 6 6 6 1 2 4 6
- Which outputs observed by the players correspond to the same turns of the game?
PGMs for sequence labeling and alignment:
Subcategories of Bayesian and Markov Networks:
Definitions
| Hidden Markov Model | HMM |
| Hidden Semi-Markov Model | HSMM |
| Pair Hidden Markov Model | PHMM |
| Pair Hidden Semi-Markov Model | PHSMM |
| Stochastic Context-Free Grammar | SCFG |
| Context-Sensitive Hidden Markov Model | CsHMM |
| Linear Chain Conditional Random Field | LCCRF |
| Semi-Markov Conditional Random Field | Semi-CRF |
BN
MN
Dynamic
Bayesian Network
Conditional
Random Field
Hidden
Markov Model
+ Discrete vars.
+ Linear out. vars.
Probabilistic Graphical Model
Bayesian Network
Markov Network
+ DAG
+ Undirected edges
+ Show process through time
+ Ignore deps. between in. vars.
Naive Bayes
Logistic Regression
+ 1 out. var.
+ 1 out. var.
Hierarchy of Mathematical Assumptions
Linear-Chain
CRF
Hidden Semi-Markov Model
+ decouple
duration
Pair Hidden
Markov Model
Pair Hidden Semi-Markov Model
Semi-Markov
CRF
+ Multiple sequences
+ Multiple sequences
Context-Sensitive Hidden Markov Model
Stochastic Context-Free Grammar
+ Memory between states
Sequence labeling
Sequence alignment
Generative
Discriminative
+ decouple
duration
+ decouple
duration
+ Multiple
subsequences
Non-local dependencies
Integrated
Algorithms
Algorithms (SRGs)
Viterbi:
Calculates the MAP assignment using a dynamic programming algorithm over an input sequence x
for models equivalent to regular grammars
Forward-Backward:
Calculates the posterior probability distribution by combining the forward and backward dynamic programming algorithms over an input sequence x
for models equivalent to regular grammars
def HMM::viterbi(x)
# Initialization
γ = NArray.zeros(@states.length, x.length)
γ[@begin, 0] = 1
# Iteration
for j in 1..x.length do
for k in @states do
i = j - 1
for p in k.predecessors do
prob = γ[p, i]
∗ p.τ(k)
∗ k.ε(x[i..j])
if (prob > γ[k, j]) then
γ[k, j], π[k, j] = prob, p
# Termination
best = γ[@end, x.length]
y = traceBack(x, γ, π)
return best, y, γHMM's Viterbi
x
j
i
k
p
γ[p][i]
ε(x[i..j])
τ(p)
Iterate until finding the best labeling sequence
Memory: \( O(LS) \)
Time: \( O(SCL) \)
S
L
L
S
L
C
def GHMM::viterbi(x)
# Initialization
γ = NArray.zeros(@states.length, x.length)
γ[@begin, 0] = 1
# Iteration
for j in 1..x.length do
for k in @states do
ds = k.durations(1, [j, @max_bt].min)
for d in ds do
i = j - d
for p in k.predecessors do
prob = γ[p, i]
∗ p.τ(k)
∗ k.δ(d)
∗ k.ε(x[i..j])
if (prob > γ[k, j]) then
γ[k, j], π[k, j] = prob, { p, d }
# Termination
best = γ[@end, x.length]
y = traceBack(x, γ, π)
return best, y, γ
GHMM's Viterbi
x
j
d
i
k
p
γ[p][i]
x[i..j]
ε(x[i..j])
δ(d)
τ(p)
Iterate until finding the best labeling sequence
Memory: \( O(LS) \)
Time: \( O(LSBP) \)
S
L
L
S
B
C
LC
def PHMM::viterbi(xs)
# Initialization
γ = NArray.zeros(@states.length, xs[0].length, xs[1].length)
γ[@begin, 0, 0] = 1
# Iteration
for js in 1..xs[0].length, 1..xs[1].length do
for k in @states do
is = []
is.push(js[0] - k.Δ(0))
is.push(js[1] - k.Δ(1))
emissions = []
emissions.push(xs[0][is[0]]) if k.emits?(0)
emissions.push(xs[1][is[1]]) if k.emits?(1)
for p in k.predecessors do
prob = γ[p, *is]
∗ p.τ(k)
∗ k.ε(*emissions)
if (prob > γ[k, *js]) then
γ[k, *js], π[k, *js] = prob, p
# Termination
best = γ[@end, xs[0].length, xs[1].length]
y = traceBack(xs, γ, π)
return best, y, γPHMM's Viterbi
x₀
i
i-1
k
p
γ[p, i-1, j-1]
ε(x[i-1..i], x[j-1..j])
τ(p)
Iterate until finding the best labeling sequence
Memory: \( O(L²S) \)
Time: \( O(L²SP) \)
x₁
j
j-1
ε(x[i-1..i], x[j-1..j])
γ[p, i-1, j-1]
S
L
L
L
S
P
L
S
L
def viterbi(xs)
# Initialization
γ = NArray.zeros(@states.length, *xs.map(|x| x.length))
γ[@begin, *xs.map(|x| 0)] = 1
# Iteration
for js in xs.map(|x| (1..x.length)) do
for k in @states do
max_durations = js.map(|j| [j, @max_backtracking].min)
durations = k.possibleDurations(1, max_durations)
for ds in durations do
is = js.zip(ds).map(|j,d| j-d)
for p in k.predecessors do
max = γ[p, *is]
∗ p.τ(s)
∗ k.δ(ds)
∗ k.ε(xs.zip(is).zip(js).map(|x,i,j| x[i..j]))
if (max > γ[k, *js].max) then
γ[k, *js] = { max, p, d }
# Termination
best = maxProbabilityForLastPosition(γ)
y = traceBack(xs, γ)
return best, y, γGPHMM's Viterbi
Iterate until finding the best labeling sequence
Memory: \( O(LᴺS) \)
Time: \( O(LᴺSBᴺP) \)
S
Lᴺ
Lᴺ
S
Bᴺ
P
Lᴺ
S
N
N
N
x₀
j₀
i₀
k
p
γ[p, i₀, i₁]
ε(x₀[i₀..j₀], x₁[i₁..j₁])
τ(p)
x₁
j₁
i₁
ε(x₀[i₀..j₀], x₁[i₁..j₁])
γ[p, i₀, i₁]
d₀
d₁
δ(d₀)
δ(d₁)
Algorithms (SCFGs)
CYK (Cocke-Younger-Kasami):
Calculates the MAP assignment using a dynamic programming algorithm over an input sequence x
for models equivalent to context-free grammars
Inside-Outside:
Calculates the posterior probability distribution by combining the forward and backward dynamic programming algorithms over an input sequence x
for models equivalent to context-free grammars
CM's CYK
def cyk(x)
# Initialization
γ = NArray.zeros(@states.length, x.length, x.length)
(0..@states.length).each { |j| γ[@begin, j, j] = 1 }
# Iteration
for j in (1..x.length) do
for w in (2..j+1) do
i = j-w
for k in @states do
l = i + k.left_emissions
r = j - k.right_emissions
for children in choose(k.children, k.cardinality) do
for cuts in divide(l, r, k.cardinality) do
children_cuts = children.zip(cut)
max = children_cuts.reduce(1) do |acc, child, interval|
acc * γ[child, interval] ∗ p.τ(child))
max *= k.ε(x[i..l], x[r..j])
if (max > γ[k, i, j].max) then
γ[k, i, j] = { max, p }
# Termination
best = maxProbabilityForLastPosition(γ)
y = traceBack(x, γ)
return best, y, γi
j
w
l
r
k
c₁
x
x[i..l]
x[r..j]
c₂
q₁
x[l..q₁ ]
x[q₁ ..r]
τ(c₂)
τ(c₁)
γ[c₁][l..q₁]
γ[c₂][q₁..r]
ε(x[i..l], x[r..j])
Memory: \( O(L²S) \)
Iterate until finding the best labeling tree
Time: \( O(L³SC²) \)
S
L
L
L
L
S
S
L
C²
L
C²L
L
GCM's CYK
def cyk(x)
# Initialization
γ = NArray.zeros(@states.length, x.length, x.length)
(0..@states.length).each { |j| γ[@begin, j, j] = 1 }
# Iteration
for j in (1..x.length) do
for w in (2..j+1) do
i = j-w
for k in @states do
max_durations = js.map(|j| [j, @max_backtracking].min)
durations = k.possibleDurations(1, max_durations)
for ds in durations do
l = i + d * k.left_emissions
r = j - d * k.right_emissions
for children in choose(k.children, k.cardinality) do
for cuts in divide(l, r, k.cardinality) do
children_cuts = children.zip(cut)
max = children_cuts.reduce(1) do |acc, child, interval|
acc * γ[child, interval] ∗ p.τ(child))
max *= δ(d) * k.ε(x[i..l], x[r..j])
if (max > γ[k, i, j].max) then
γ[k, i, j] = { max, p, d }
# Termination
best = maxProbabilityForLastPosition(γ)
y = traceBack(x, γ)
return best, y, γi
j
w
l
r
k
c₁
x
x[i..l]
x[r..j]
c₂
q₁
x[l..q₁ ]
x[q₁ ..r]
τ(c₂)
τ(c₁)
γ[c₁][l..q₁]
γ[c₂][q₁..r]
ε(x[i..l], x[r..j])
Memory: \( O(L²S) \)
Iterate until finding the best labeling tree
Time: \( O(L³SBC²) \)
S
L
L
L
L
S
S
L
C²
L
C²L
L
B
d
d
δ(d)
δ(d)
GPCM's CYK
def cyk(x)
# Initialization
γ = NArray.zeros(@states.length, x.length, x.length)
(0..@states.length).each { |j| γ[@begin, j, j] = 1 }
# Iteration
for j in (1..x.length) do
for w in (2..j+1) do
i = j-w
for k in @states do
max_durations = js.map(|j| [j, @max_backtracking].min)
durations = k.possibleDurations(1, max_durations)
for ds in durations do
l = i + d * k.left_emissions
r = j - d * k.right_emissions
for children in choose(k.children, k.cardinality) do
for cuts in divide(l, r, k.cardinality) do
children_cuts = children.zip(cut)
max = children_cuts.reduce(1) do |acc, child, interval|
acc * γ[child, interval] ∗ p.τ(child))
max *= δ(d) * k.ε(x[i..l], x[r..j])
if (max > γ[k, i, j].max) then
γ[k, i, j] = { max, p, d }
# Termination
best = maxProbabilityForLastPosition(γ)
y = traceBack(x, γ)
return best, y, γi
j
w
l
r
k
c₁
x
x[i..l]
x[r..j]
c₂
q₁
x[l..q₁ ]
x[q₁ ..r]
τ(c₂)
τ(c₁)
γ[c₁][l..q₁]
γ[c₂][q₁..r]
ε(x[i..l], x[r..j])
Memory: \( O(L²S) \)
Iterate until finding the best labeling tree
Time: \( O(L³SBC²) \)
S
L
L
L
L
S
S
L
C²
L
C²L
L
B
d
d
δ(d)
δ(d)
Integrated
implementation
ToPS' Probabilistic Models
| Model | Acronym |
|---|---|
| Independent and Identically Distributed Model | IID |
| Variable Length Markov Chain | VLMC |
| Inhomogeneous Markov Chain | IMC |
| Periodic Inhomogeneous Markov Chain | PIMC |
| Maximal Dependence Decomposition | MDD |
| Similarity Based Sequence Weighting | SBSW |
| Multiple Sequential Model | VLMC |
| Hidden Markov Model | HMM |
| Generalized Hidden Markov Model | GHMM |
| Pair Hidden Markov Model | PHMM |
| Context-Sensitive Hidden Markov Model | CSHMM |
PGMs
Models
Features of a Probabilistic Model
\(P(\mathbf{x})\)
Evaluate
Calculate the probability of
a sequence given a model
Generate
Draw random sequences
from a model
Train
Estimate parameters of the
model from a dataset
Serialize
Save parameters of a model
for later reuse
Calculate
Find the posterior probabilities
of an input sequence
Label
Find the MAP assignment
for an input sequence
PGMs only
Characteristics
Multifaceted abstraction
Multifaceted abstraction
ToPS' published hierarchy of probabilistic models
Composite
+
Decorator
Unfactored interface
Unfactored
implementation
Unfactored interface and implementation
Lang
Config
Model
Exception
App
Lang
Config
Model
Exception
App
ToPS' main component. It holds all code for probabilistic models as an independent shared library
All probabilistic models make their calculations based on a discrete numeric alphabet
Lang
Config
Model
Exception
App
ToPS' language component.
It holds the implementation of a domain specific language (DSL)
to describe probabilistic models
ToPS' DSL is based on ChaiScript, an embedded script language designed to be integrated with C++
Lang
Config
Model
Exception
App
ToPS' auxiliary layer. It holds a C++ based intermediate representation of probabilistic models
ToPS' config structures store parameters to train and define of probabilistic models
Lang
Config
Model
Exception
App
ToPS' exceptions, representing all errors that can happen during the execution of ToPS
Lang
Config
Model
Exception
App
ToPS' command-line applications, allowing end users to execute tasks on the probabilistic models
New Architecture
\( P(\mathbf{x}) \)
Probabilistic Models
(COMPOSITE)
Trainer
Estimates parameters of a model from a dataset
Evaluator
Calculates the probability of a sequence given a model
Generator
Draws random sequences from the model
Serializer
Saves parameters of the model for later reuse
Calculator
Finds the posterior probabilities
of an input sequence
Labeler
Finds the MAP assignment
for an input sequence
Boss
Secretary
Secretary
Secretary
Secretary
Secretary
Secretary
Architecture: SECRETARY pattern¹
Boss
Secretary
[1] R. C. Ferreira, Í. Bonadio, and A. M. Durham, “Secretary pattern: decreasing coupling while keeping reusability”,
Proceedings of the 11th Latin-American Conference on Pattern Languages of Programming. The Hillside Group, p. 14, 2016.
SECRETARY: Class diagram
SECRETARY: Sequence diagram
Model Hierarchy: Interfaces
tops::model::ProbabilisticModel
Root of the hierarchy, implements 4 secretaries: Trainer, Evaluator, Generator and Serializer
tops::model::DecodableModel
Node of the hierarchy, descends directly from ProbabilisticModel and implements all parent's secretaries plus 2: Calculator and Labeler
tops::model::ProbabilisticModelDecorator
Node of the hierarchy, descends directly from ProbabilisticModel and adds functionalities around the implementation of parent's secretaries
Model Hierarchy: CRTP
The curiously recurring template pattern (CRTP) is an idiom in C++ in which a class X derives from a class template instantiation using itself as template argument. [...] Some use cases for this pattern are static polymorphism and other metaprogramming techniques [...]
Wikipedia, Curiously Recurring Template Pattern
tops::model::ProbabilisticModelCRTP
tops::model::DecodableModelCRTP
tops::model::ProbabilisticModelDecoratorCRTP
Implement FACTORY METHOD's for secretaries, define virtual methods that secretaries delegate to and host code reused between subclasses
Independent and Identically Distributed (IID)
Responsibilities
- Train with Burge's smoothed histogram
- Train with Stanke's smoothed histogram
- Train with kernel density algorithm
- Train with maximum likelihood
- Draw random symbols
- Evaluate the probability of symbols
- Serialize to store parameter on disk
- Get its vector of probabilities
- Get its alphabet size
Collaborators
- None
Variable Length Markov Chain (VLMC)
Responsibilities
- Train with context algorithm
- Train with fixed length algorithm
- Train with interpolation algorithm
- Draw a random symbol
- Draw a random sequence
- Evaluate the probability of a symbol
- Evaluate the probability of a sequence
- Serialize to store parameter on disk
- Get its context tree
Collaborators
- Context Tree
Inhomogeneous Markov Chain (IMC)
Responsibilities
- Train with WAM algorithm
- Draw a random symbol
- Draw a random sequence
- Evaluate the probability of a symbol
- Evaluate the probability of a sequence
- Serialize to store parameter on disk
- Get its VLMCs
Collaborators
- VLMC
Periodic Inhomogeneous Markov Chain (PIMC)
Responsibilities
- Train with interpolation algorithm
- Draw a random symbol
- Draw a random sequence
- Evaluate the probability of a symbol
- Evaluate the probability of a sequence
- Serialize to store parameter on disk
- Get its VLMCs
Collaborators
- VLMC
Maximal Dependency Decomposition (MDD)
Responsibilities
- Train with standard algorithm
- Draw a random symbol
- Draw a random sequence
- Evaluate the probability of a symbol
- Evaluate the probability of a sequence
- Serialize to store parameter on disk
- Get its consensus sequence
- Get its consensus model
- Get its MDD tree
Collaborators
- Other Probabilistic Models
- Consensus Sequence
- MDD Tree
Similarity Based Sequence Weighting (SBSW)
Responsibilities
- Train with standard algorithm
- Draw a random symbol
- Draw a random sequence
- Evaluate the probability of a symbol
- Evaluate the probability of a sequence
- Serialize to store parameter on disk
- Get its skip offset
- Get its skip length
- Get its skip sequence
- Get its normalizer
Collaborators
- Other Probabilistic Models
Multiple Sequential Model (MSM)
Responsibilities
- Evaluate the probability of a symbol
- Evaluate the probability of a sequence
- Draw a random symbol
- Draw a random sequence
- Serialize to store parameter on disk
- Get its submodels
- Get its maximum length
Collaborators
- Other Probabilistic Models
Hidden Markov Model (HMM)
Responsibilities
- Train with maximum-likelihood algorithm
- Train with baum-welch algorithm
- Draw a random symbol
- Draw a random sequence
- Evaluate the probability of a symbol
- Evaluate the probability of a sequence
- Calculate the posterior distribution
- Label a sequence
- Get its states
- Get its observation alphabet
Collaborators
- HMM's State
- IID
Pair Hidden Markov Model (PHMM)
Responsibilities
- Train with maximum-likelihood algorithm
- Train with baum-welch algorithm
- Draw random symbols
- Draw random sequences
- Evaluate the probability of symbols
- Evaluate the probability of sequences
- Calculate the posterior distribution
- Label an alignment of sequence
- Get its states
- Get its observation alphabet
Collaborators
- PHMM's State
- IID
Generalized Hidden Markov Model (GHMM)
Responsibilities
- Draw a random symbol
- Draw a random sequence
- Evaluate the probability of a symbol
- Evaluate the probability of a sequence
- Calculate the posterior distribution
- Label a sequence
- Get its states
- Get its observation alphabet
Collaborators
- GHMM's State
- IID
- Other Probabilistic Models
GHMM's Forward
def GHMM::forward(x)
α = NArray.zeros(@states.length, x.length)
α[@begin.id, 0] = 1
for j in (1..x.length) do
for k in @states do
max_duration = [j, @max_backtracking].min
durations = k.possibleDurations(1, max_duration)
for d in durations do
for p in k.predecessors do
α[p.id, j] *= α[p.id, j−d] ∗ p.τ(s) ∗ k.δ(d) ∗ k.ε(x[j−d+1..j])
full = S.reduce(|max, k| [γ[k.id, x.length], max].max)
return full, αGHMM's Backward
def GHMM::backward(x, max_backtracking)
γ_b[1] ← 1
for j ∈ |x|..0 do
for k ∈ S do
for s ∈ S_k do
max_duration ← min(j, max_backtracking)
D_s ← possibleDurations_s(1, max_duration)
for d ∈ D_s do
α_s[j] ← α_s[j] * α_p[j−d] ∗ τ_p(s) ∗ δ_s(d) ∗ ε_s(x[j−d+1 : j])
full ← max{s ∈ S}(γ_s[|x|]))
return { full, α }By Renato Cordeiro Ferreira
Presentation for my Master's defense at IME-USP




