Jeff Taylor
Principal Data Consultant
Fulton Analytics
How To Tune A Multi-Terabyte Database For Optimum Performance



Jeff Taylor
Principal Data Consultant
Fulton Analytics

A Senior Data Engineer, Architect & Consultant. Friend Of Redgate. Octopus Insider. Over 25 years of experience specializing in performance tuning and critical data issues.
Currently serving as the President of the Jacksonville SQL Server Users Group and is an active board member of the Jacksonville Development Users Group.





Cellphones
Don't forget to silence your cellphones!

Don't forget to tag and tweet!
#SQLSatOregon

Thank You Sponsors!









Jeff Taylor
Principal Data Consultant
Fulton Analytics
How To Tune A Multi-Terabyte Database For Optimum Performance
Questions
- What is your role (How many DBA's)?
- What Versions of SQL Server are you using in Production?
- What Editions of SQL Server are you using in Production?
- How many Terabytes is your largest table?
- How many Terabytes is your largest database?

Problems Encountered
- Queries take minutes to run, processes take hours to finish, and application timeouts have to be extended.
- Databases so large index maintenance was not able to complete each night.
- New Indexes take 4-8 hours to create on tables with billions of records.
- Full backups take 12+ hours.
- Database log mode is kept in Simple mode due to transaction log backups being unable to keep up.
- Using nested Virtual Hard Drives for data in a VM Host VHD
- The entire database was in a single file in a single filegroup - PRIMARY.
First things First
- Hire a DBA
- Preferably one who knows servers and storage (SANs)
- Move to Enterprise Edition


Agenda
-
Review configuration, test Network, Server, and SAN performance.
- Determine what kind of data you have.
- Determine criteria and filters used for queries.
- Review and adjust Data Types/Data Sizes.
- Move/Fix Data.
- Release unused space in PRIMARY filegroup
Would you rather use this?

Or This?

Would you rather use a pickup?

Or a tractor trailer?

Would you rather use a garden hose?

Or this or a spillway?

Or better yet four spillways?

First we need better design

First we need better design
- Review and Test Current System
- Review and adjust Infrastructure Design
- Review and change Data Types/Data Sizes
- Create Logical Separation/Physical Location
Measure Throughput
- SQL Server File IO Per DB
WITH Agg_IO_Stats
AS
(
SELECT
DB_NAME(database_id) AS database_name,
CAST(SUM(num_of_bytes_read + num_of_bytes_written) / 1048576 / 1024.
AS DECIMAL(12, 2)) AS io_in_gb
FROM sys.dm_io_virtual_file_stats(NULL, NULL) AS DM_IO_Stats
GROUP BY database_id
),
Rank_IO_Stats
AS
(
SELECT
ROW_NUMBER() OVER(ORDER BY io_in_gb DESC) AS row_num,
database_name,
io_in_gb,
CAST(io_in_gb / SUM(io_in_gb) OVER() * 100
AS DECIMAL(5, 2)) AS pct
FROM Agg_IO_Stats
)
SELECT R1.row_num, R1.database_name, R1.io_in_gb, R1.pct,
SUM(R2.pct) AS run_pct
FROM Rank_IO_Stats AS R1
JOIN Rank_IO_Stats AS R2
ON R2.row_num <= R1.row_num
GROUP BY R1.row_num, R1.database_name, R1.io_in_gb, R1.pct
ORDER BY R1.row_num;Measure Throughput
- SQL Server File IO Per DB

Latency Per DB File
- SQL Server Latetency Per File
SELECT
--virtual file latency
[ReadLatency] =
CASE WHEN [num_of_reads] = 0
THEN 0 ELSE ([io_stall_read_ms] / [num_of_reads]) END,
[WriteLatency] =
CASE WHEN [num_of_writes] = 0
THEN 0 ELSE ([io_stall_write_ms] / [num_of_writes]) END,
[Latency] =
CASE WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0 ELSE ([io_stall] / ([num_of_reads] + [num_of_writes])) END,
--avg bytes per IOP
[AvgBPerRead] =
CASE WHEN [num_of_reads] = 0
THEN 0 ELSE ([num_of_bytes_read] / [num_of_reads]) END,
[AvgBPerWrite] =
CASE WHEN [io_stall_write_ms] = 0
THEN 0 ELSE ([num_of_bytes_written] / [num_of_writes]) END,
[AvgBPerTransfer] =
CASE WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0 ELSE
(([num_of_bytes_read] + [num_of_bytes_written]) /
([num_of_reads] + [num_of_writes])) END,
LEFT ([mf].[physical_name], 2) AS [Drive],
DB_NAME ([vfs].[database_id]) AS [DB],
--[vfs].*,
[mf].[physical_name]
FROM
sys.dm_io_virtual_file_stats (NULL,NULL) AS [vfs]
JOIN sys.master_files AS [mf]
ON [vfs].[database_id] = [mf].[database_id]
AND [vfs].[file_id] = [mf].[file_id]
ORDER BY [WriteLatency] DESC;
GOLatency Per DB File
- SQL Server Latetency Per File

Measure Throughput
- Crystal Disk Mark
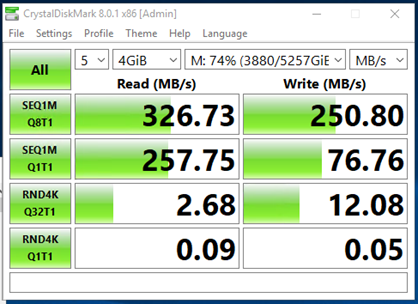
Initial Server Results
Sequential 1 MB file 8 threads 1 process
Sequential 1MB file 1 thread 1 process
Random 4k 32 processes 1 thread
Random 4k 1 thread 1 thread
Measure Throughput
- Crystal Disk Mark
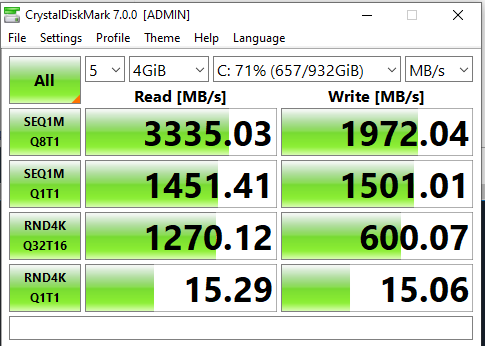
My Laptop Results
Sequential 1 MB file 8 threads 1 process
Sequential 1MB file 1 thread 1 process
Random 4k 32 processes 16 threads
Random 4k 1 thread 1 thread
Measure Throughput
- Crystal Disk Mark
Comparison - Initial Server vs. My Laptop
Measure Throughput
- Crystal Disk Mark
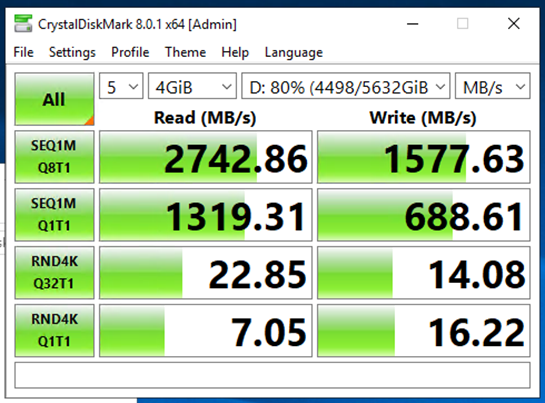
Server After Upgrades
Measure Throughput
- Crystal Disk Mark
Comparison - Initial Server vs. After Adjustments
Measure Throughput
- diskspd - (formally sqlio) - Before Test - 64k Reads
Command Line: diskspd -b64K -d300 -o32 -t10 -h -r -w0 -L -Z1G -c20G M:\test.dat
Input parameters:
timespan: 1
-------------
duration: 300s
warm up time: 5s
cool down time: 0s
measuring latency
random seed: 0
path: 'M:\test.dat'
think time: 0ms
burst size: 0
software cache disabled
hardware write cache disabled, writethrough on
write buffer size: 1073741824
performing read test
block size: 65536
using random I/O (alignment: 65536)
number of outstanding I/O operations: 32
thread stride size: 0
threads per file: 10
using I/O Completion Ports
IO priority: normalMeasure Throughput
- diskspd - (formally sqlio) - Before Test - 64k Reads
Read IO
thread | bytes | I/Os | MiB/s | I/O per s | AvgLat | LatStdDev | file
-----------------------------------------------------------------------------------------------------
0 | 3436183552 | 52432 | 10.92 | 174.77 | 182.901 | 882.749 | M:\test.dat (20GiB)
1 | 3441950720 | 52520 | 10.94 | 175.07 | 182.813 | 879.862 | M:\test.dat (20GiB)
2 | 3442933760 | 52535 | 10.94 | 175.12 | 183.085 | 879.030 | M:\test.dat (20GiB)
3 | 3436445696 | 52436 | 10.92 | 174.79 | 183.459 | 883.685 | M:\test.dat (20GiB)
4 | 3442606080 | 52530 | 10.94 | 175.10 | 182.791 | 876.278 | M:\test.dat (20GiB)
5 | 3439525888 | 52483 | 10.93 | 174.94 | 182.975 | 890.304 | M:\test.dat (20GiB)
6 | 3437494272 | 52452 | 10.93 | 174.84 | 183.032 | 890.014 | M:\test.dat (20GiB)
7 | 3438608384 | 52469 | 10.93 | 174.90 | 182.996 | 882.304 | M:\test.dat (20GiB)
8 | 3440115712 | 52492 | 10.94 | 174.97 | 183.638 | 890.562 | M:\test.dat (20GiB)
9 | 3440115712 | 52492 | 10.94 | 174.97 | 182.891 | 877.021 | M:\test.dat (20GiB)
-----------------------------------------------------------------------------------------------------
total: 34395979776 | 524841 | 109.34 | 1749.47 | 183.058 | 883.195Measure Throughput
- diskspd - (formally sqlio) - After Test - 64k Reads
Command Line: diskspd -b64K -d300 -o32 -t10 -h -r -w0 -L -Z1G -c20G J:\test.dat
Input parameters:
timespan: 1
-------------
duration: 300s
warm up time: 5s
cool down time: 0s
measuring latency
random seed: 0
path: 'J:\test.dat'
think time: 0ms
burst size: 0
software cache disabled
hardware write cache disabled, writethrough on
write buffer size: 1073741824
performing read test
block size: 65536
using random I/O (alignment: 65536)
number of outstanding I/O operations: 32
thread stride size: 0
threads per file: 10
using I/O Completion Ports
IO priority: normalMeasure Throughput
- diskspd - (formally sqlio) - After Test - 64k Reads
Read IO
thread | bytes | I/Os | MiB/s | I/O per s | AvgLat | LatStdDev | file
-----------------------------------------------------------------------------------------------------
0 | 69446729728 | 1059673 | 220.74 | 3531.88 | 9.055 | 11.633 | J:\test.dat (20GiB)
1 | 80267247616 | 1224781 | 255.14 | 4082.18 | 7.837 | 7.692 | J:\test.dat (20GiB)
2 | 79802073088 | 1217683 | 253.66 | 4058.52 | 7.883 | 8.170 | J:\test.dat (20GiB)
3 | 79711305728 | 1216298 | 253.37 | 4053.91 | 7.892 | 7.596 | J:\test.dat (20GiB)
4 | 11169824768 | 170438 | 35.50 | 568.07 | 55.935 | 403.657 | J:\test.dat (20GiB)
5 | 80384884736 | 1226576 | 255.51 | 4088.16 | 7.825 | 6.320 | J:\test.dat (20GiB)
6 | 80713220096 | 1231586 | 256.55 | 4104.86 | 7.794 | 7.703 | J:\test.dat (20GiB)
7 | 10342301696 | 157811 | 32.87 | 525.98 | 60.756 | 198.219 | J:\test.dat (20GiB)
8 | 81465507840 | 1243065 | 258.94 | 4143.12 | 7.722 | 5.959 | J:\test.dat (20GiB)
9 | 403767296 | 6161 | 1.28 | 20.53 | 1570.195 | 2666.786 | J:\test.dat (20GiB)
-----------------------------------------------------------------------------------------------------
total: 573706862592 | 8754072 | 1823.58 | 29177.21 | 10.964 | 103.685Measure Throughput
- diskspd - (formally sqlio) - Before Test - 64k Writes
Command Line: diskspd -b64K -d300 -o32 -t10 -h -r -w100 -L -Z1G -c20G M:\test.dat
Input parameters:
timespan: 1
-------------
duration: 300s
warm up time: 5s
cool down time: 0s
measuring latency
random seed: 0
path: 'M:\test.dat'
think time: 0ms
burst size: 0
software cache disabled
hardware write cache disabled, writethrough on
write buffer size: 1073741824
performing write test
block size: 65536
using random I/O (alignment: 65536)
number of outstanding I/O operations: 32
thread stride size: 0
threads per file: 10
using I/O Completion Ports
IO priority: normalMeasure Throughput
- diskspd - (formally sqlio) - Before Test - 64k Writes
Write IO
thread | bytes | I/Os | MiB/s | I/O per s | AvgLat | LatStdDev | file
-----------------------------------------------------------------------------------------------------
0 | 2722496512 | 41542 | 8.65 | 138.47 | 231.917 | 45.290 | M:\test.dat (20GiB)
1 | 2722693120 | 41545 | 8.66 | 138.48 | 231.933 | 45.672 | M:\test.dat (20GiB)
2 | 2723217408 | 41553 | 8.66 | 138.51 | 231.896 | 45.642 | M:\test.dat (20GiB)
3 | 2723217408 | 41553 | 8.66 | 138.51 | 231.891 | 45.729 | M:\test.dat (20GiB)
4 | 2721775616 | 41531 | 8.65 | 138.43 | 231.934 | 45.574 | M:\test.dat (20GiB)
5 | 2722234368 | 41538 | 8.65 | 138.46 | 231.977 | 45.615 | M:\test.dat (20GiB)
6 | 2723282944 | 41554 | 8.66 | 138.51 | 231.900 | 45.705 | M:\test.dat (20GiB)
7 | 2722889728 | 41548 | 8.66 | 138.49 | 231.897 | 45.448 | M:\test.dat (20GiB)
8 | 2723020800 | 41550 | 8.66 | 138.50 | 231.919 | 45.629 | M:\test.dat (20GiB)
9 | 2721579008 | 41528 | 8.65 | 138.42 | 232.005 | 45.789 | M:\test.dat (20GiB)
-----------------------------------------------------------------------------------------------------
total: 27226406912 | 415442 | 86.55 | 1384.79 | 231.927 | 45.609Measure Throughput
- diskspd - (formally sqlio) - After Test - 64k Writes
Command Line: diskspd -b64K -d300 -o32 -t10 -h -r -w100 -L -Z1G -c20G J:\test.dat
Input parameters:
timespan: 1
-------------
duration: 300s
warm up time: 5s
cool down time: 0s
measuring latency
random seed: 0
path: 'J:\test.dat'
think time: 0ms
burst size: 0
software cache disabled
hardware write cache disabled, writethrough on
write buffer size: 1073741824
performing write test
block size: 65536
using random I/O (alignment: 65536)
number of outstanding I/O operations: 32
thread stride size: 0
threads per file: 10
using I/O Completion Ports
IO priority: normalMeasure Throughput
- diskspd - (formally sqlio) - After Test - 64k Writes
Write IO
thread | bytes | I/Os | MiB/s | I/O per s | AvgLat | LatStdDev | file
-----------------------------------------------------------------------------------------------------
0 | 10689511424 | 163109 | 33.98 | 543.68 | 58.842 | 55.344 | J:\test.dat (20GiB)
1 | 10661265408 | 162678 | 33.89 | 542.25 | 58.982 | 61.204 | J:\test.dat (20GiB)
2 | 10862985216 | 165756 | 34.53 | 552.51 | 57.889 | 47.318 | J:\test.dat (20GiB)
3 | 10706419712 | 163367 | 34.03 | 544.54 | 58.736 | 59.966 | J:\test.dat (20GiB)
4 | 10694164480 | 163180 | 33.99 | 543.92 | 58.814 | 51.372 | J:\test.dat (20GiB)
5 | 10790567936 | 164651 | 34.30 | 548.82 | 58.263 | 57.034 | J:\test.dat (20GiB)
6 | 10759634944 | 164179 | 34.20 | 547.25 | 58.445 | 59.746 | J:\test.dat (20GiB)
7 | 10420158464 | 158999 | 33.12 | 529.98 | 60.330 | 61.604 | J:\test.dat (20GiB)
8 | 10647830528 | 162473 | 33.85 | 541.56 | 59.015 | 70.884 | J:\test.dat (20GiB)
9 | 10049814528 | 153348 | 31.95 | 511.15 | 62.517 | 61.650 | J:\test.dat (20GiB)
-----------------------------------------------------------------------------------------------------
total: 106282352640 | 1621740 | 337.85 | 5405.66 | 59.157 | 58.894Measure Throughput
- diskspd - (formally sqlio) - Comparison 64k
Read Random 64k IO
thread | bytes | I/Os | MiB/s | I/O per s | AvgLat | LatStdDev
------------------------------------------------------------------------------------------------
Before total: 34395979776 | 524,841 | 109.34 | 1749.47 | 183.058 | 883.195
After total: 573706862592 | 8,754,072 | 1,823.58 | 29,177.21 | 10.964 | 103.685
Write Random 64k IO
thread | bytes | I/Os | MiB/s | I/O per s | AvgLat | LatStdDev
-------------------------------------------------------------------------------------------------
Before total: 27226406912 | 415,442 | 86.55 | 1,384.79 | 231.927 | 45.609
After total: 106282352640 | 1,621,740 | 337.85 | 5,405.66 | 59.157 | 58.894
Read Sequential 64k IO
thread | bytes | I/Os | MiB/s | I/O per s | AvgLat | LatStdDev
-------------------------------------------------------------------------------------------------
Before total: 51745456128 | 789,573 | 164.49 | 2,631.90 | 121.740 | 324.619
After total: 558304985088 | 8,519,058 | 1,774.71 | 28,395.44 | 11.227 | 116.484
Write Sequential 64k IO
thread | bytes | I/Os | MiB/s | I/O per s | AvgLat | LatStdDev
-------------------------------------------------------------------------------------------------
Before total: 20625096704 | 314,714 | 65.57 | 1,049.05 | 304.779 | 158.935
After total: 89771278336 | 1,369,801 | 285.37 | 4,565.85 | 70.075 | 174.488Verify Network Setup
- Do you have Multi-Path Setup from SAN To Host or SAN to Physical?
- What is Multi-Path? Multiple Network cards in your server/VM Host.
- What is your connection speed from your server/host to SAN?
- 1GB?
- 8GB?
- 10GB?
- 25GB?
- 40GB?
- 100GB?
- Connections X Bandwidth = more throughput
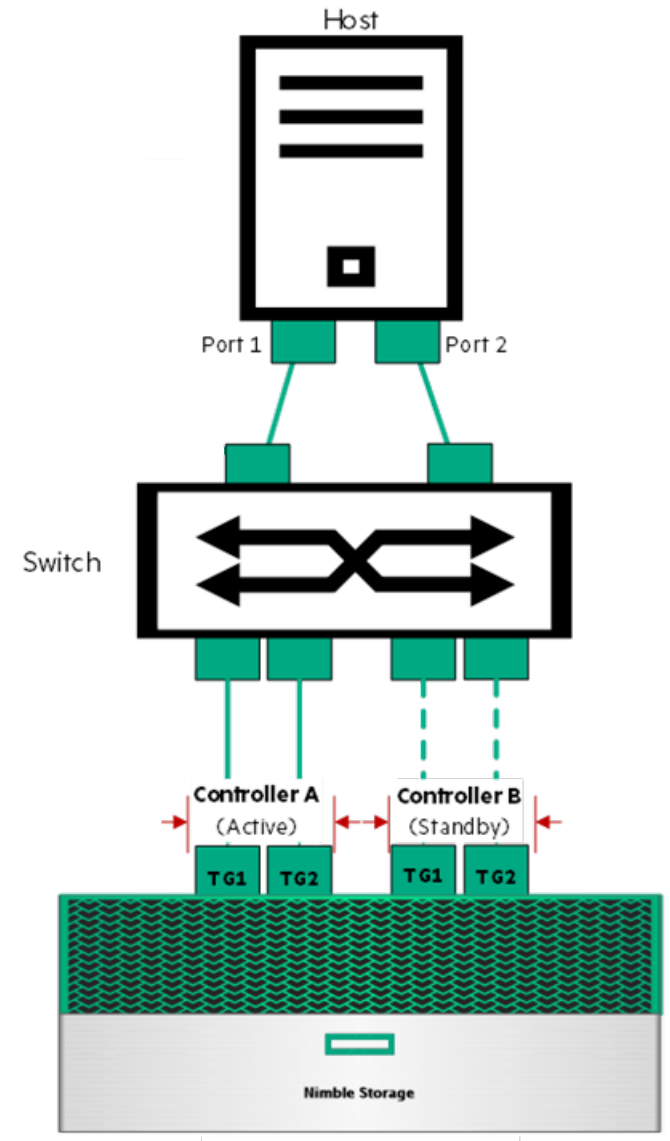
Verify Network Setup
- Are Jumbo Frames Enabled?
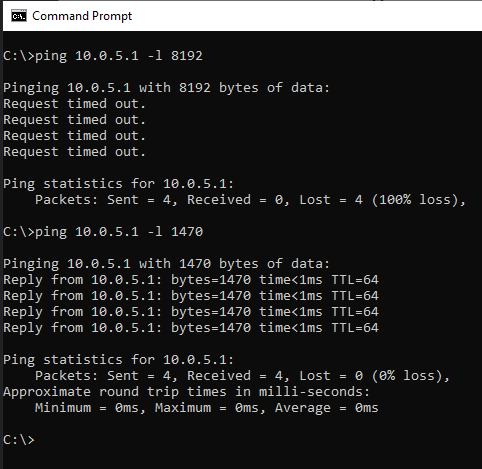
Verify Network Setup
- Work with your Infrastructure/IT/SAN team
- Validate how many NICs (network cards) are in your Server/VM Host connected to your SAN.
- Validate the bandwidth of those connections to the switch.
- Validate the switch is able to support the bandwidth.
- Validate there are multiple connections from the switch to your SAN.
- Validate the latency the SAN is showing internally is low latency (5ms or less).
- Validate on your server that all NICs are connected and active to the SAN.
- Validate the data is on its own network.
- Validate Jumbo frames are enabled on that network.
- Validate at all levels there are redundancies.
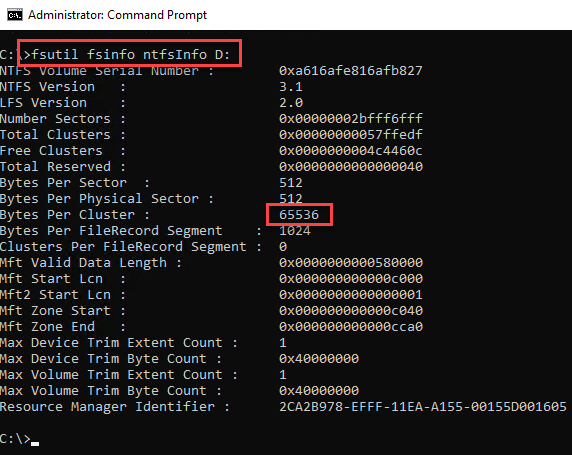
Drive Configuration
- Are your Data and Log drives formatted in 64k blocks?
fsutil fsinfo ntfsInfo D: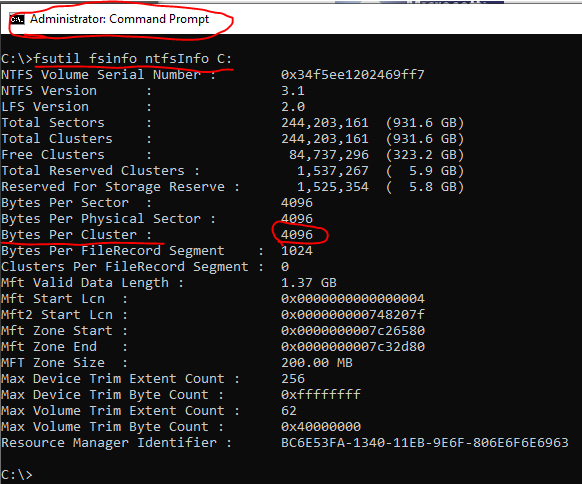
Drive Configuration
Disk Partition Alignment Best Practices for SQL Server - https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008/dd758814(v=sql.100)
Disk performance may be slower than expected when you use multiple disks - https://docs.microsoft.com/en-US/troubleshoot/windows-server/performance/disk-performance-slower-multiple-disks
- Disk Offset (Windows Server 2008 and older)
- 20-30% performance enhancement fixing offset
Drive Configuration
- For older OS, is your drive alignment correct? - Consult your SAN best practices
wmic partition get BlockSize, StartingOffset, Name, Index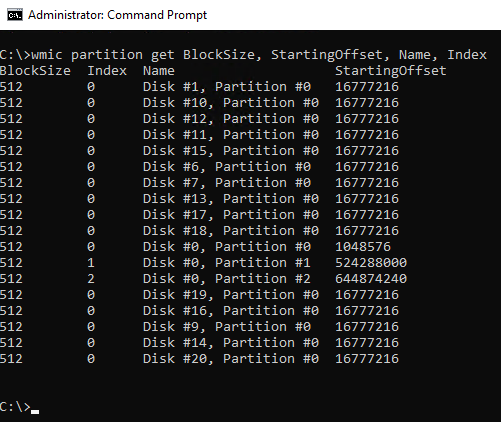
Drive Configuration
- Are you using NVMe, SSD, spinning rust or a combination?
- Is your SAN managing your disk configuration (Nimble/HP) or is your SAN administrator?
- Are you using RAID?
- Is your RAID the same for your data drives as your log drives?
- RAID 0 - Striping - Not fault tolerant, minimum 2 drives
- RAID 1 - Mirroring - No hot-swap, one drive failure, minimum 2 drives
- RAID 5 - Striping with parity - Hot-swap, one drive failure, reads fast, writes slower, minimum 3 drives
- RAID 6 - Striping with double parity - Hot-swap, two drive failure, reads/writes slower than RAID 5, minimum 4 drives
- RAID 10 - Mirroring and Striping - Fastest, rebuilds faster than 5 and 6, more drives, most expensive
Know Your Data
- Inserting, Updating, Deleting (CRUD) OLTP
- Insert Only (i.e. Logging)
- Data Warehouse
- Does it make sense to Partition?
How do you query and or filter your data?
- Date
- Bit (Active? Unfulfilled?)
- Int (Identifier, Status)
-
If partitioning, what column makes sense? Primary Key Id? Datetime?
- Are you using your clustered keys in queries and are your indexes supporting your queries?
Data Retention - Partioning
- Do you really need 2.5+ billion records in that table?
- Determine your retention periods (1 year? 2 years? 7 years?)
- Does all of the data need to be on hot storage?
- Determine your typical searching range. (Month, Quarter, Year)
- Based on number of records per period may also determine partitioning structure.
Does your database use unicode data types?
- nchar
- nvarchar
- ntext
*n stands for National Language
Latin, Greek, Cyrillic, Armenian, Hebrew, Arabic, Syriac, Thaana, Devanagari, Bengali, Gurmukhi, Oriya, Tamil, Telugu, Kannada, Malayalam, Sinhala, Thai, Lao, Tibetan, Myanmar, Georgian, Hangul, Ethiopic, Cherokee, Canadian Aboriginal Syllabics, Khmer, Mongolian, Han (Japanese, Chinese, Korean ideographs), Hiragana, Katakana, and Yi
- Do you really need unicode characters?
Does your database use Text/NText/Image?
- They are Deprecated!
- Move the data to a new varchar(max)/varbinary(max) column.
- Just changing the data type won't help performance or space savings. I tried!
Is there a difference between nvarchar vs. varchar?
- nvarchar uses 2 bytes (or more) per character
- varchar uses 1 byte per character
DECLARE @test1 NVARCHAR(4000), @test2 VARCHAR(4000),
@test1size BIGINT, @test2size BIGINT;
SET @test1 = 'My Text Data Test';
SET @test2 = 'My Text Data Test';
SET @test1size = DATALENGTH(@test1)
SET @test2size = DATALENGTH(@test2)
SELECT
DATALENGTH(@test1) AS Test1
,DATALENGTH(@test2) AS Test2
,FORMAT(@test1size * 600000000,'###,###') AS Test1SizeBytes
,FORMAT(@test2size * 600000000,'###,###') AS Test2SizeBytes
,FORMAT((@test1size * 600000000)/1024/1024,'###,###') AS Test1SizeMB
,FORMAT((@test2size * 600000000)/1024/1024,'###,###') AS Test2SizeMB
,FORMAT((@test1size * 600000000)/1024/1024/1024,'###,###') AS Test1SizeGB
,FORMAT((@test2size * 600000000)/1024/1024/1024,'###,###') AS Test2SizeGBSize Difference


bigint vs. int vs. smallint vs. tinyint
-
bigint - 8 bytes - Nine quintillion two hundred twenty three quadrillion three hundred seventy two trillion thirty six billion eight hundred fifty four million seven hundred seventy five thousand eight hundred and seven (9,223,372,036,854,775,807)
-
int - 4 bytes - Two billion one hundred forty-seven million four hundred eighty-three thousand six hundred forty-seven (2,147,483,647)
-
smallint - 2 bytes - Thirty two thousand seven hundred and sixty seven (32,767)
- tinyint - 1 byte - Two hundred and fifty five (255)
Negative Max
- If you need more than int, smallint, have you considered going negative max to start?
- Starting at Negative Max int (-2,147,483,648) gives you a total of 4,294,967,294 rows - Four billion, two hundred and ninety-four million, nine hundred and sixty-seven thousand, two hundred and ninety-four.
- Starting at Negative Max smallint (-32,768) gives you a total of 65,534 rows - Sixty thousand five hundred thirty-four.
DECLARE
@test1 bigint, @test2 int, @test3 SMALLINT, @test4 TINYINT,
@test1size BIGINT, @test2size BIGINT, @test3size BIGINT, @test4size BIGINT;
SELECT @test1 = 9223372036854775807, @test2 = -2147483648, @test3 = 32767, @test4 = 255;
SELECT @test1size = DATALENGTH(@test1), @test2size = DATALENGTH(@test2), @test3size = DATALENGTH(@test3),
@test4size = DATALENGTH(@test4);
SELECT
DATALENGTH(@test1) AS Test1,
DATALENGTH(@test2) AS Test2,
DATALENGTH(@test3) AS Test3,
DATALENGTH(@test4) AS Test4,
FORMAT(@test1size * 600000000, '###,###') AS Test1SizeBytes,
FORMAT(@test2size * 600000000, '###,###') AS Test2SizeBytes,
FORMAT(@test3size * 600000000, '###,###') AS Test3SizeBytes,
FORMAT(@test4size * 600000000, '###,###') AS Test4SizeBytes,
FORMAT((@test1size * 600000000) / 1024 / 1024, '###,###') AS Test1SizeMB,
FORMAT((@test2size * 600000000) / 1024 / 1024, '###,###') AS Test2SizeMB,
FORMAT((@test3size * 600000000) / 1024 / 1024, '###,###') AS Test3SizeMB,
FORMAT((@test4size * 600000000) / 1024 / 1024, '###,###') AS Test4SizeMB,
FORMAT((@test1size * 600000000) / 1024 / 1024 / 1024, '###,###') AS Test1SizeGB,
FORMAT((@test2size * 600000000) / 1024 / 1024 / 1024, '###,###') AS Test2SizeGB,
(@test3size * 600000000) / 1024 / 1024 / 1024 AS Test3SizeGB,
(@test4size * 600000000) / 1024 / 1024 / 1024 AS Test4SizeGB;Size Difference


Datetime & Datetime2 Difference
- Datetime - 3 precision - Data Size - 8 bytes - Accuracy Rounded to increments of .000, .003, or .007 seconds
- Datetime2(#) - 0 to 7 precision - Data Size 6 - 8 Bytes - Accuracy of 100ns.
- The default precision is 7 digits.
- 6 bytes for precisions less than 3
- 7 bytes for precisions 3 and 4.
- All other precisions require 8 bytes.
Datetime & Datetime2 Difference
DECLARE @date0 DATETIME2(0), @date1 DATETIME2(1), @date2 datetime2(2),
@date3 datetime2(3), @date4 datetime2(4), @date5 datetime2(5),
@date6 datetime2(7),@date7 datetime2(7), @originaldate DATETIME
SET @originaldate = GETDATE()
SELECT @date0 = @originaldate, @date1 = @originaldate, @date2 = @originaldate,
@date3 = @originaldate, @date4 = @originaldate, @date5 = @originaldate,
@date6 = @originaldate, @date7 = @originaldate
SELECT @originaldate AS [DateTime], DataLength(@originaldate) AS [Size]
SELECT @date0 AS [DateTime2-0], DataLength(@date0) AS [Size]
SELECT @date1 AS [DateTime2-1], DataLength(@date1) AS [Size]
SELECT @date2 AS [DateTime2-2], DataLength(@date2) AS [Size]
SELECT @date3 AS [DateTime2-3], DataLength(@date3) AS [Size]
SELECT @date4 AS [DateTime2-4], DataLength(@date4) AS [Size]
SELECT @date5 AS [DateTime2-5], DataLength(@date5) AS [Size]
SELECT @date6 AS [DateTime2-6], DataLength(@date6) AS [Size]
SELECT @date7 AS [DateTime2-7], DataLength(@date7) AS [Size]Datetime & Datetime2 Difference
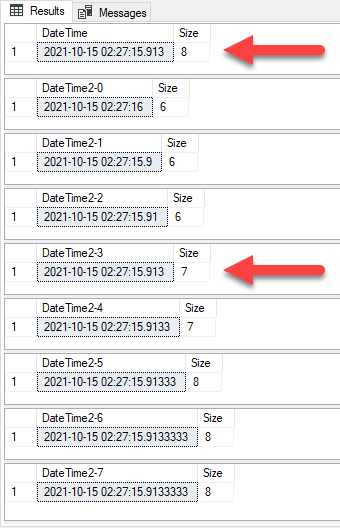
- Notice Datetime and Datetime2(3) have the same precision, but one is 1 byte less.
- If you had one table, which had CreatedDatetime and ModifiedDatetime and converted them to Datetime2(3) in one table with 2.5 billion records, that would save you 5GB of space for that one adjustment.
Datetime & Datetime2 Data Sizes
DECLARE @test1 DATETIME, @test2 DATETIME2(0), @test3 DATETIME2(3), @test1size BIGINT, @test2size BIGINT, @test3size BIGINT, @samedt DATETIME;
SET @samedt = GETDATE(); SET @test1 = @samedt; SET @test2 = @samedt; SET @test3 = @samedt;
SET @test1size = DATALENGTH(@test1); SET @test2size = DATALENGTH(@test2); SET @test3size = DATALENGTH(@test3);
SELECT
@test1, @test2, @test3,
DATALENGTH(@test1) AS Test1,
DATALENGTH(@test2) AS Test2,
DATALENGTH(@test3) AS Test3
SELECT
FORMAT((@test1size * 600000000)/1024/1024,'###,###') AS Test1SizeMB
,FORMAT((@test2size * 600000000)/1024/1024,'###,###') AS Test2SizeMB
,FORMAT((@test3size * 600000000)/1024/1024,'###,###') AS Test3SizeMB
,FORMAT((@test1size * 600000000)/1024/1024/1024,'###,###') AS Test1SizeGB
,FORMAT((@test2size * 600000000)/1024/1024/1024,'###,###') AS Test2SizeGB
,FORMAT((@test3size * 600000000)/1024/1024/1024,'###,###') AS Test3SizeGB
Table Data Size Example
- CreatedDatetime - 8 vs. 6
- ModifiedDatetime - 8 vs. 6
- OrderDate - 8 vs. 6 (or 3)
- FullfilledDate - 8 vs. 6 (or 3)
- ReturnDate - 8 vs. 6 (or 3)
- nvarchar - 8000 vs. 4000
- 5 Datetime Columns = 20GB down to 10 or 5GB
- 1 nvarchar to varchar column 4TB to 2TB
- Over 2TB savings per table!
- Now multiply those savings by however many tables you have with multi-million or billion records
- Savings can be seen on SAN/Disk space, backup size and time, restore time, and bytes transferred in application.
1 Table with 600 million Rows
Instant File Initialization
- Before data migration turn on Instant File Initialization for the service and group/account which is executing the scripts, or be in the administrative group when creating the filegroups.
- Why? Speed up file growth on disk. Doesn't zero write-out files. It will affect query performance. You may see long wait latches on page allocations during growth.
- It will also speed up restoring databases
Instant File Initialization
- Check to see if it is already enabled
SELECT
servicename AS Service_Display_Name,
service_account AS Service_Account,
instant_file_initialization_enabled
FROM
sys.dm_server_services
WHERE
servicename LIKE 'SQL Server (%';
Instant File Initialization
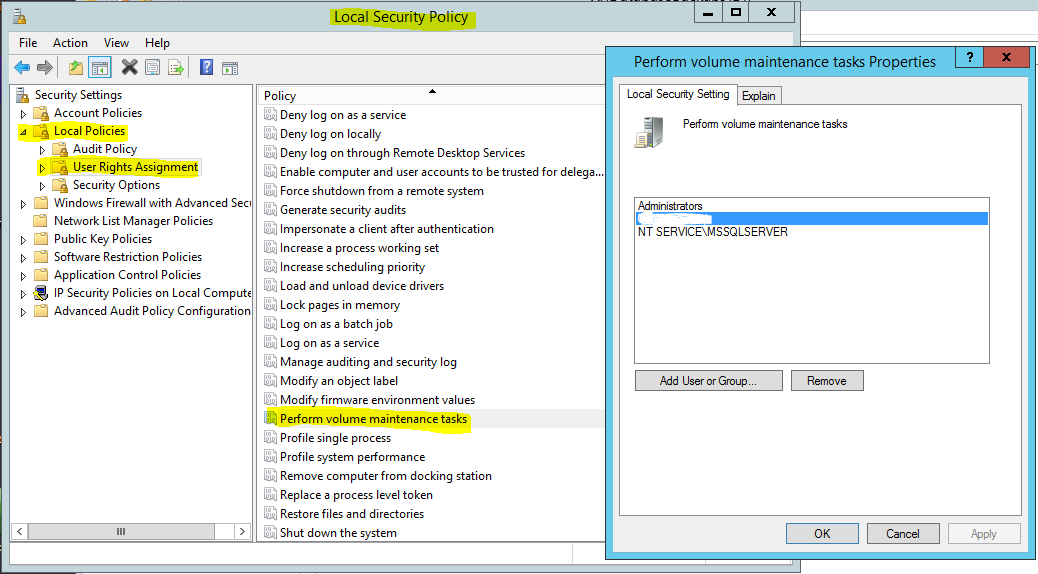
Local Security Policy
Instant File Initialization
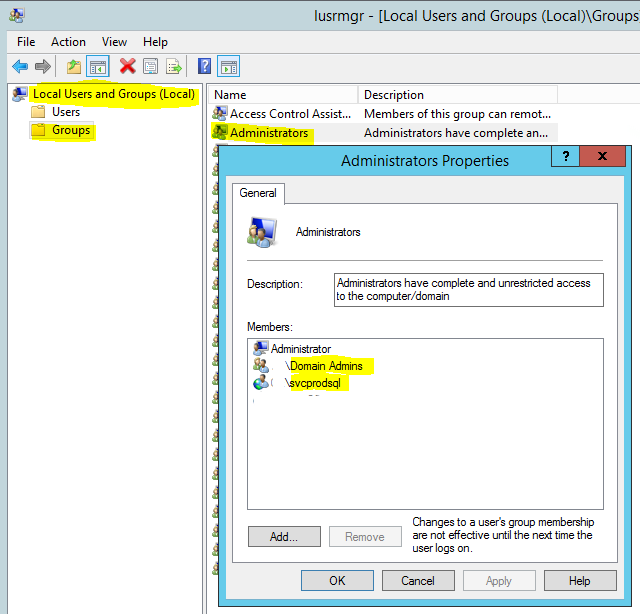
Local Administrative Group
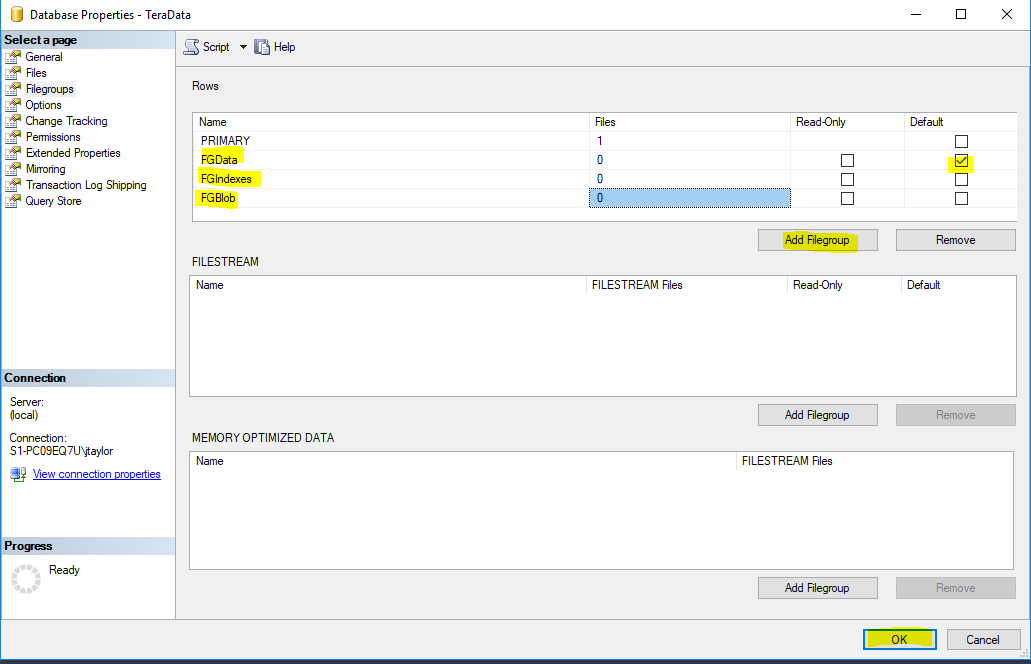
Create File Groups
- File Group for Data - FGData
- File Group for Indexes - FGIndexes
- File Group for Blob Data - FGBlob
- Partition File Groups - (Examples: PSMonth201610, PSYear2016, PSMonthly90)
- Change Default File Group to FGData for new objects.
Create File Groups
USE [master]
GO
ALTER DATABASE [TeraData] ADD FILEGROUP [FGData]
GO
ALTER DATABASE [TeraData] ADD FILEGROUP [FGIndexes]
GO
ALTER DATABASE [TeraData] ADD FILEGROUP [FGBlob]
GO
USE [TeraData]
GO
IF NOT EXISTS (SELECT name FROM sys.filegroups
WHERE is_default=1 AND name = N'FGData')
ALTER DATABASE [TeraData]
MODIFY FILEGROUP [FGData] DEFAULT
GOCreate File Groups
Create Files
- Create at least one file for each file group. - Place on separate drives.
USE [master]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = 'TeraData_FGBlob',
FILENAME = N'D:\Databases\TeraData_FGBlob.ndf' ,
SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [FGBlob]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = 'TeraData_FGData',
FILENAME = N'E:\Databases\TeraData_FGData.ndf' ,
SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [FGData]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = 'TeraData_FGIndexes',
FILENAME = N'F:\Databases\TeraData_FGIndexes.ndf' ,
SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [FGIndexes]
GOCreate Files
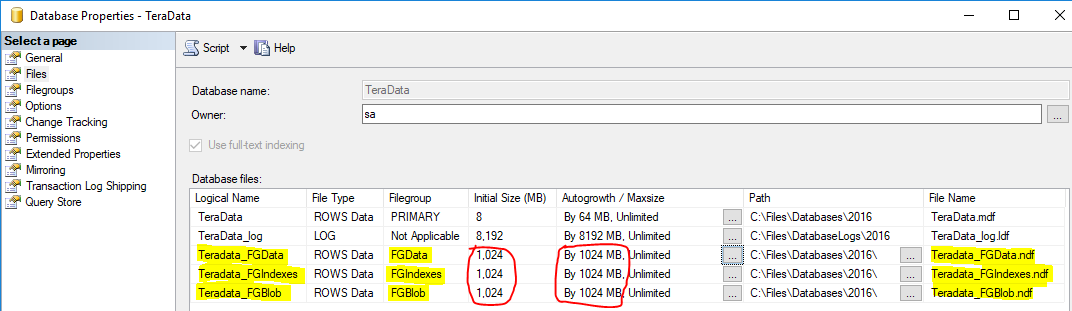
Partitioning
USE [TeraData]
GO
ALTER DATABASE [TeraData] ADD FILEGROUP [PG_Empty]
GO
ALTER DATABASE [TeraData] ADD FILEGROUP [PG_2017_10]
GO
ALTER DATABASE [TeraData] ADD FILEGROUP [PG_2017_11]
GO
ALTER DATABASE [TeraData] ADD FILEGROUP [PG_2017_12]
GO
ALTER DATABASE [TeraData] ADD FILEGROUP [PG_2018_01]
GO
ALTER DATABASE [TeraData] ADD FILEGROUP [PG_2018_02]
GO
ALTER DATABASE [TeraData] ADD FILEGROUP [PG_2018_03]
GO
ALTER DATABASE [TeraData] ADD FILEGROUP [PG_2018_04]
GO
ALTER DATABASE [TeraData] ADD FILEGROUP [PG_2018_05]
GO
ALTER DATABASE [TeraData] ADD FILEGROUP [PG_2018_06]
GO
ALTER DATABASE [TeraData] ADD FILEGROUP [PG_2018_07]
GO
ALTER DATABASE [TeraData] ADD FILEGROUP [PG_2018_08]
GO
ALTER DATABASE [TeraData] ADD FILEGROUP [PG_2018_09]
GO
ALTER DATABASE [TeraData] ADD FILEGROUP [PG_2018_10]
GOPartitioning
USE [TeraData]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_PG_Empty',
FILENAME = N'C:\Files\Databases\TeraData_PG_Empty.ndf' , SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_Empty]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_PG_2017_10',
FILENAME = N'C:\Files\Databases\TeraData_PG_2017_10.ndf' , SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_2017_10]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_PG_2017_11',
FILENAME = N'C:\Files\Databases\TeraData_PG_2017_11.ndf' , SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_2017_11]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_PG_2017_12',
FILENAME = N'C:\Files\Databases\TeraData_PG_2017_12.ndf' , SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_2017_12]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_PG_2018_01',
FILENAME = N'C:\Files\Databases\TeraData_PG_2018_01.ndf' , SIZE = 1MB , FILEGROWTH = 128MB)
TO FILEGROUP [PG_2018_01]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_PG_2018_02',
FILENAME = N'C:\Files\Databases\TeraData_PG_2018_02.ndf', SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_2018_02]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_PG_2018_03',
FILENAME = N'C:\Files\Databases\TeraData_PG_2018_03.ndf', SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_2018_03]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_PG_2018_04',
FILENAME = N'C:\Files\Databases\TeraData_PG_2018_04.ndf', SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_2018_04]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_PG_2018_05',
FILENAME = N'C:\Files\Databases\TeraData_PG_2018_05.ndf', SIZE = 1MB , FILEGROWTH = 128MB)
TO FILEGROUP [PG_2018_05]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_PG_2018_06',
FILENAME = N'C:\Files\Databases\TeraData_PG_2018_06.ndf', SIZE = 1MB , FILEGROWTH = 128MB)
TO FILEGROUP [PG_2018_06]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_PG_2018_07',
FILENAME = N'C:\Files\Databases\TeraData_PG_2018_07.ndf', SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_2018_07]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_PG_2018_08',
FILENAME = N'C:\Files\Databases\TeraData_PG_2018_08.ndf', SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_2018_08]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_PG_2018_09',
FILENAME = N'C:\Files\Databases\TeraData_PG_2018_09.ndf', SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_2018_09]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_PG_2018_10',
FILENAME = N'C:\Files\Databases\TeraData_PG_2018_10.ndf', SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_2018_10]
GOPartitioning
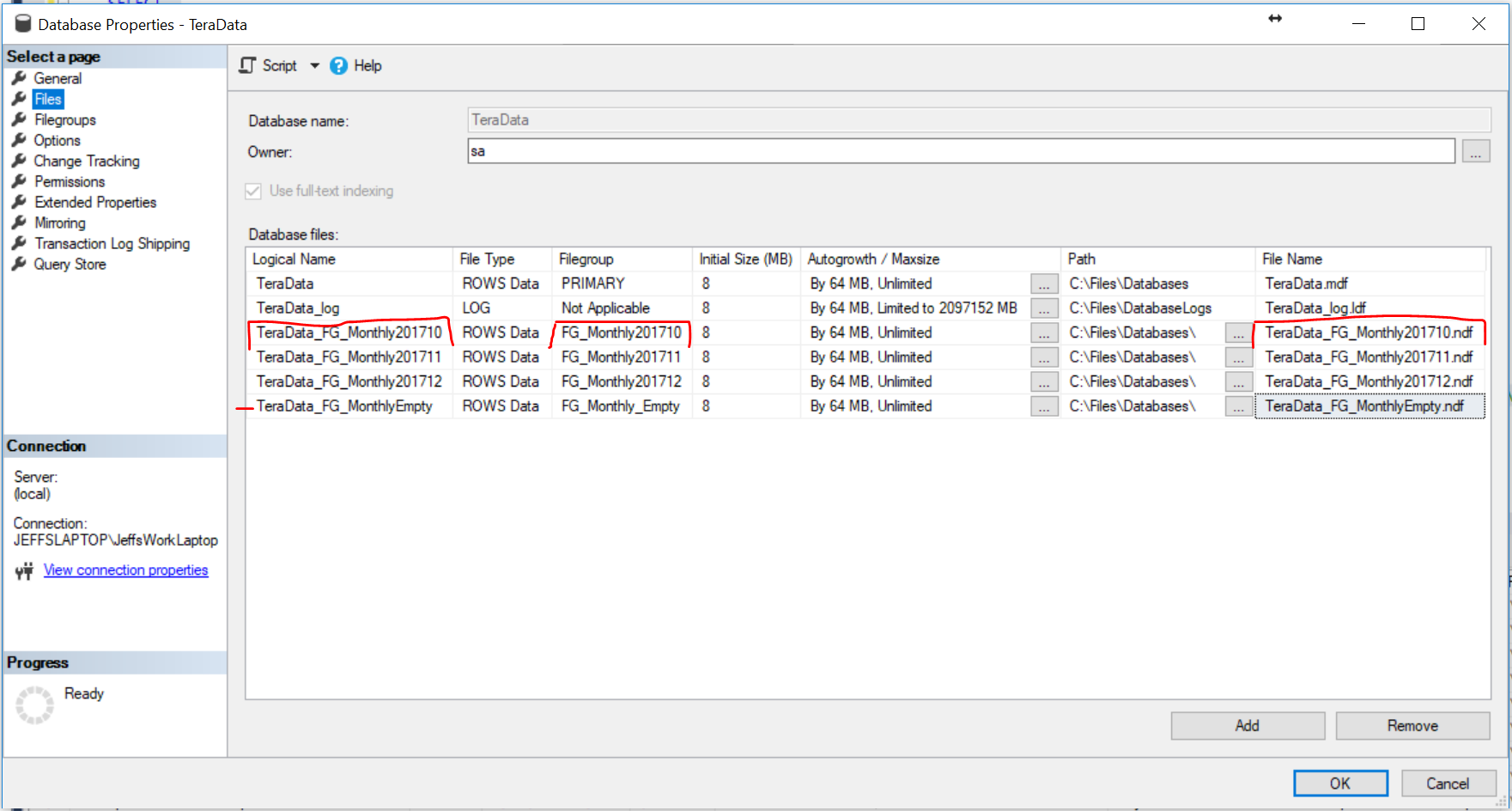
Partitioning
USE [TeraData]
GO
CREATE PARTITION FUNCTION [PF_Monthly](datetime) AS RANGE Right FOR VALUES (
N'2017-10-01',
N'2017-11-01',
N'2017-12-01',
N'2018-01-01',
N'2018-02-01',
N'2018-03-01',
N'2018-04-01',
N'2018-05-01',
N'2018-06-01',
N'2018-07-01',
N'2018-08-01',N'2018-09-01',N'2018-10-01')
GO
CREATE PARTITION SCHEME [PS_Monthly] AS PARTITION [PF_Monthly] TO (
[PG_Empty],
[PG_2017_10],
[PG_2017_11],
[PG_2017_12],
[PG_2018_01],
[PG_2018_02],
[PG_2018_03],
[PG_2018_04],
[PG_2018_05],
[PG_2018_06],
[PG_2018_07],
[PG_2018_08],[PG_2018_09],[PG_2018_10])
GOPartitioning
CREATE TABLE [dbo].[ErrorLog](
[ErrorLogId] [INT] IDENTITY(-2147483648,1) NOT NULL,
[PageName] [VARCHAR](200) NULL,
[ErrorLabel] [VARCHAR](100) NULL,
[CustomErrorMessage] [VARCHAR](200) NULL,
[CreatedDatetime] [DATETIME] NOT NULL,
[ServerName] [VARCHAR](20) NULL,
[ServerIPAddress] [VARCHAR](16) NULL,
CONSTRAINT [PK_ErrorLog] PRIMARY KEY CLUSTERED
(
[ErrorLogId] ASC,
[CreatedDatetime] ASC
) WITH (DATA_COMPRESSION = PAGE)
ON [PS_Monthly]([CreatedDatetime])) ON [PS_Monthly]([CreatedDatetime])
GO
CREATE NONCLUSTERED INDEX [IX_ErrorLog_ErrorLabel_PageName] ON [dbo].[ErrorLog]
(
[ErrorLabel],
[PageName]
)WITH (SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE) ON [PS_Monthly]([CreatedDatetime])
GO
ALTER TABLE [dbo].[ErrorLog] ADD CONSTRAINT [DF_ErrorLog_CreatedDatetime]
DEFAULT (GETDATE()) FOR [CreatedDatetime]
GOMore Performance
- If greater performance is needed create multiple files per file group.
- Place multiple files on multiple LUNS/Drives
Create Multiple Files
USE [master]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_FGBlob1',
FILENAME = N'D:\Databases\TeraData_FGBlob1.ndf',
SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [FGBlob]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_FGBlob2',
FILENAME = N'E:\Databases\TeraData_FGBlob2.ndf',
SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [FGBlob]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_FGBlob3',
FILENAME = N'F:\Databases\TeraData_FGBlob3.ndf',
SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [FGBlob]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_FGBlob4',
FILENAME = N'G:\Databases\TeraData_FGBlob4.ndf',
SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [FGBlob]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_FGData1',
FILENAME = N'G:\Databases\TeraData_FGData1.ndf',
SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [FGData]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_FGData2',
FILENAME = N'F:\Databases\TeraData_FGData2.ndf',
SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [FGData]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_FGData3',
FILENAME = N'E:\Databases\TeraData_FGData3.ndf',
SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [FGData]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_FGData4',
FILENAME = N'D:\Databases\TeraData_FGData4.ndf',
SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [FGData]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_FGIndexes1', FILENAME = N'D:\Databases\TeraData_FGIndexes1.ndf',
SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [FGIndexes]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_FGIndexes2', FILENAME = N'E:\Databases\TeraData_FGIndexes2.ndf',
SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [FGIndexes]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_FGIndexes3', FILENAME = N'F:\Databases\TeraData_FGIndexes3.ndf',
SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [FGIndexes]
GO
ALTER DATABASE [TeraData] ADD FILE ( NAME = N'TeraData_FGIndexes4', FILENAME = N'G:\Databases\TeraData_FGIndexes4.ndf',
SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [FGIndexes]
GOCreate Multiple Files
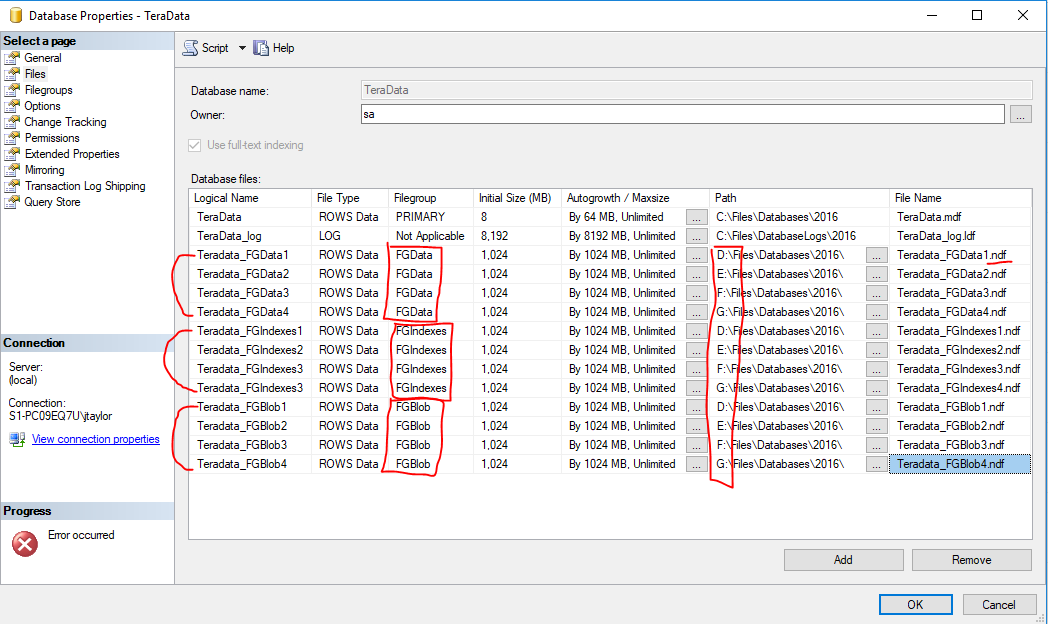
File Size
- Pre-Grow Files - Attempt to determine size of new files, based on data size, index size and blob storage, so you don't have to have file growths during the data migration process.
- Divide the total by however many files you end up selecting.
File Size
File Growth
- Ensure all files in the filegroup have the same auto-growth setting to distribute the data evenly between all files in a filegroup.
-
Enabled trace flag T1117 which distributes the data evenly between all files in a filegroup. (2014 and older versions).
- Enabled 'Autogrow All Files' Flag (2016+ versions).
File Growth
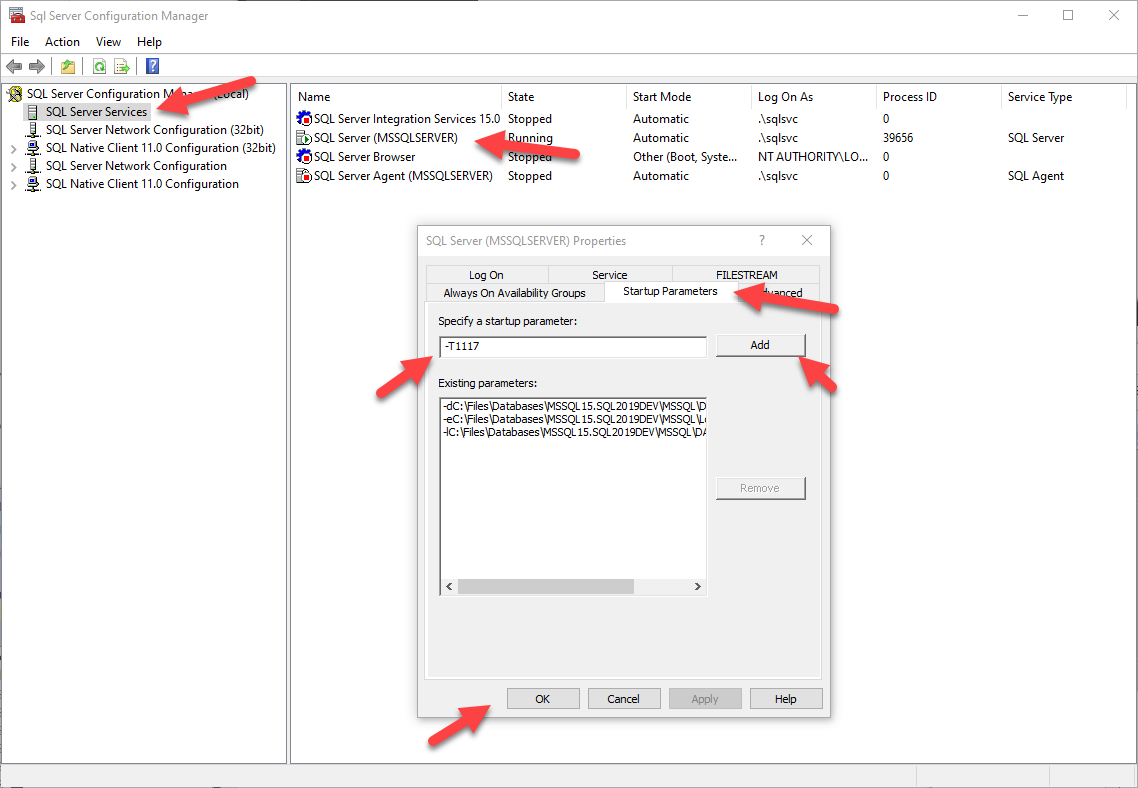
File Growth
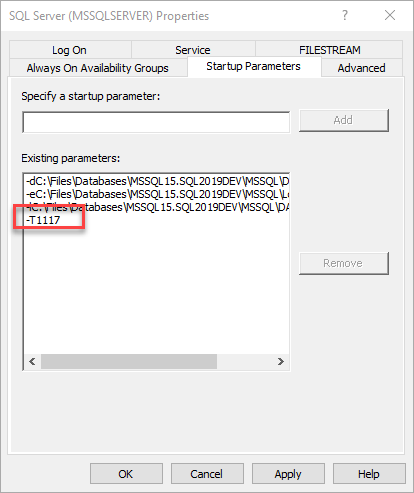
File Growth
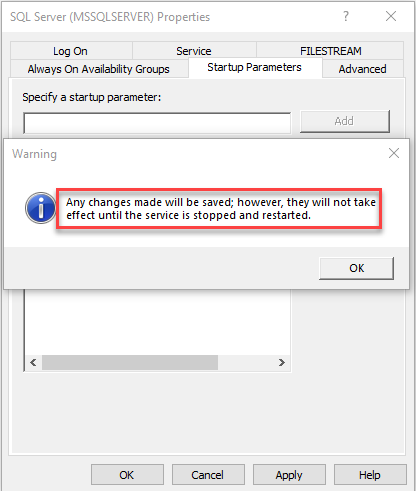
File Growth
* note - Autogrow All Files Flag - Single User Mode
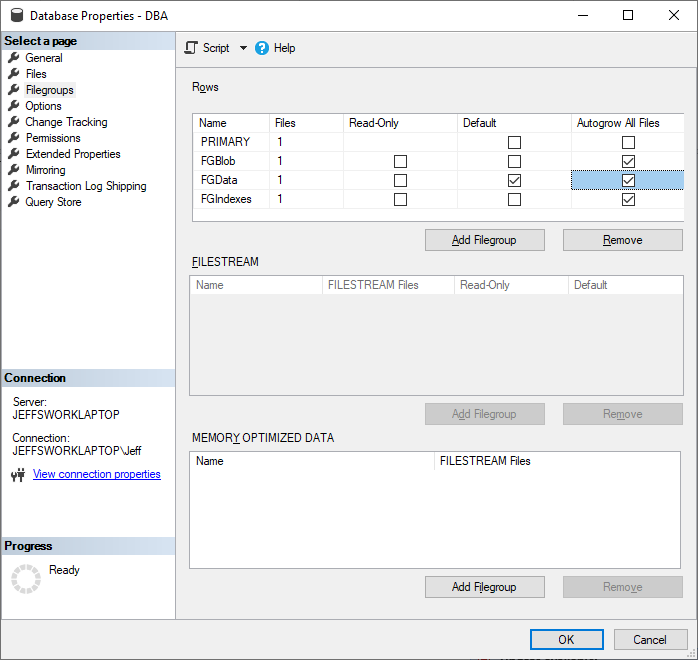
File Growth
USE [master];
GO
ALTER DATABASE [TeraData] MODIFY FILEGROUP [FGData] AUTOGROW_ALL_FILES;
GO
ALTER DATABASE [TeraData] MODIFY FILEGROUP [FGIndexes] AUTOGROW_ALL_FILES;
GO
ALTER DATABASE [TeraData] MODIFY FILEGROUP [FGBlob] AUTOGROW_ALL_FILES;
GOALTER DATABASE statement failed.
Msg 5070, Level 16, State 2, Line 29
Database state cannot be changed while other users are using the database 'TeraData'File Growth
USE master;
SELECT
c.session_id,
DB_NAME(s.database_id) AS DatabaseName,
s.host_name,
s.program_name,
s.client_interface_name,
s.login_name,
s.nt_domain,
s.nt_user_name,
s.original_login_name,
c.connect_time,
s.login_time
FROM
sys.dm_exec_connections AS c
JOIN sys.dm_exec_sessions AS s
ON c.session_id = s.session_id;
File Growth
USE [master];
GO
ALTER DATABASE [TeraData] SET SINGLE_USER WITH NO_WAIT;
GO
ALTER DATABASE [TeraData] MODIFY FILEGROUP [FGData] AUTOGROW_ALL_FILES;
GO
ALTER DATABASE [TeraData] MODIFY FILEGROUP [FGIndexes] AUTOGROW_ALL_FILES;
GO
ALTER DATABASE [TeraData] MODIFY FILEGROUP [FGBlob] AUTOGROW_ALL_FILES;
GO
ALTER DATABASE [TeraData] SET MULTI_USER WITH NO_WAIT;
GOThe filegroup property 'AUTOGROW_ALL_FILES' has been set.
The filegroup property 'AUTOGROW_ALL_FILES' has been set.
The filegroup property 'AUTOGROW_ALL_FILES' has been set.Do you have any heap tables?
- Create clustered indexes on the heap tables. - Insure created on the correct new FGData Filegroup with compression if possible.
VLFs - Virtual Log Files
- Check your database for your VLFs before performing table migrations to new filegroups.
- Make sure your log file growth is set to a specific size, not a percentage.
- Make sure your growth size is large enough to not create too many VLFs.
- This will increase the performance of transactions, backups, and restores.

Pedro Lopes VLF script - https://github.com/microsoft/tigertoolbox/blob/master/Fixing-VLFs/Fix_VLFs.sql
Moving Blob Data Types
-
You have to create a new table to relocate blob storage.
- Create a new table.
- Copy data to the new table.
- Check table record counts.
- Drop old table.
- Rename the new table.
- Create Indexes.
Moving Blob Data Types
CREATE TABLE [dbo].[UserResumes]
(
[UserResumeId] [INT] IDENTITY(1, 1) NOT NULL,
[UserResume] [VARCHAR](MAX) NULL,
[UserId] [INT] NOT NULL,
[PrimaryResume] [BIT] NOT NULL CONSTRAINT [DF_UserResumes_PrimaryResume] DEFAULT (0),
[CreatedDatetime] [DATETIME2](0) NOT NULL,
[ModifiedDatetime] [DATETIME2](0) NOT NULL,
) ON [FGData] TEXTIMAGE_ON [FGBlob] WITH (DATA_COMPRESSION = PAGE);
GO
ALTER TABLE [dbo].[UserResumes] ADD CONSTRAINT [PK_UserResumes] PRIMARY KEY CLUSTERED ([UserResumeId] ASC)
WITH (DATA_COMPRESSION = PAGE, ONLINE = OFF) ON [FGData];
GO
CREATE NONCLUSTERED INDEX [IX_UserResumes_UserId_Includes] ON [dbo].[UserResumes]
(
[UserId] ASC
)
INCLUDE([PrimaryResume],[UserResumeId]) WITH (DATA_COMPRESSION = PAGE,
SORT_IN_TEMPDB = ON, ONLINE = OFF) ON [FGIndexes]
GOMoving Data
-
If you have millions/billions of records, batching records to move may be appropriate. If you can schedule a maintenance window, perhaps use simple mode for faster performance as well.
- Always batch by your clustered key for best performance.
Moving Data
SELECT
COUNT(*) AS ObjectCount,
ISNULL(ps.[name], f.[name]) AS [FileGroup]
FROM
[sys].[indexes] AS i
LEFT JOIN sys.partition_schemes AS ps
ON ps.data_space_id = i.data_space_id
LEFT JOIN sys.filegroups AS f
ON f.data_space_id = i.data_space_id
LEFT OUTER JOIN sys.all_objects AS o
ON o.object_id = i.object_id
LEFT OUTER JOIN sys.schemas AS s
ON s.schema_id = o.schema_id
WHERE
OBJECTPROPERTY(i.[object_id], 'IsUserTable') = 1
GROUP BY
ISNULL(ps.[name], f.[name])- Count objects in each file group
Moving Data
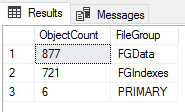
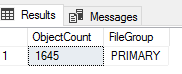
- Count objects in each file group
Moving Data
SELECT
s.[name] + '.' + OBJECT_NAME(i.[object_id]) AS [TableName],
i.[index_id] AS [IndexId],
i.[name] AS [IndexName],
i.[type_desc] AS [IndexType],
CASE
WHEN ps.data_space_id IS NULL THEN
'No'
ELSE
'Yes'
END AS [Partitioned],
ISNULL(ps.[name], f.[name]) AS [FileGroup]
FROM
[sys].[indexes] AS i
LEFT JOIN sys.partition_schemes AS ps
ON ps.data_space_id = i.data_space_id
LEFT JOIN sys.filegroups AS f
ON f.data_space_id = i.data_space_id
LEFT OUTER JOIN sys.all_objects AS o
ON o.object_id = i.object_id
LEFT OUTER JOIN sys.schemas AS s
ON s.schema_id = o.schema_id
WHERE
OBJECTPROPERTY(i.[object_id], 'IsUserTable') = 1
ORDER BY
s.[name] + '.' + OBJECT_NAME(i.[object_id]),
[IndexName];- Find all Objects in each filegroup
Moving Data
- Find all Objects in each filegroup
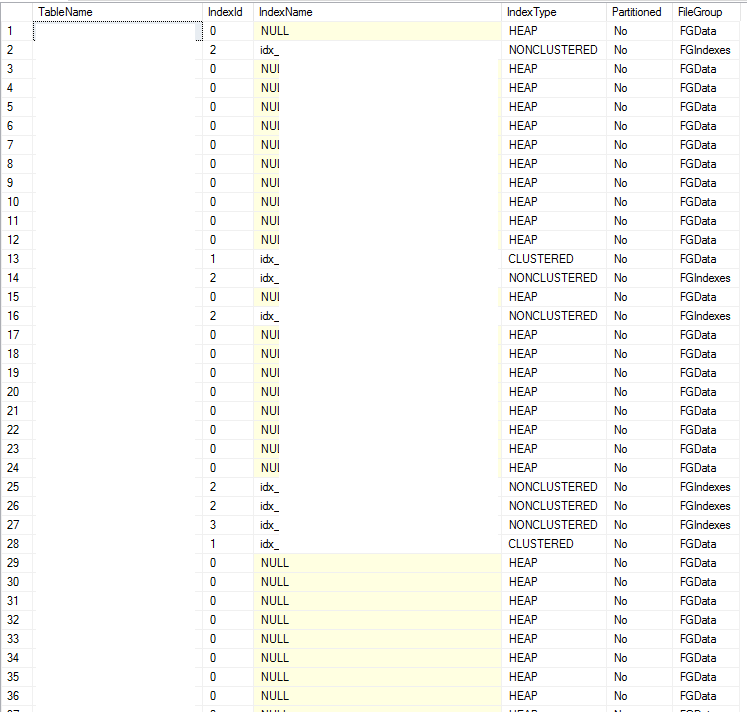
Moving Data
- Easy way to move Clustered Indexes without rebuilding table - (if no blob usage)
CREATE UNIQUE CLUSTERED INDEX [PK_Users] ON [dbo].[User]
(
[UserId] ASC
) WITH (DROP_EXISTING = ON, DATA_COMPRESSION = PAGE, SORT_IN_TEMPDB = ON) ON [FGData]
GOCompression
- Use Page Compression for Tables and Indexes
- Use Columnstore compression for Data Warehouse or archive tables



63.1% Space Savings
89.7% Space Savings
Compression
- Estimate compression for tables
EXEC sp_estimate_data_compression_savings 'dbo','Votes',NULL,NULL,'PAGE'
EXEC sp_estimate_data_compression_savings 'dbo','Votes',NULL,NULL,'COLUMNSTORE'
EXEC sp_estimate_data_compression_savings 'dbo','Votes',NULL,NULL,'COLUMNSTORE_ARCHIVE'
- Estimation will also include indexes
Compression
-
When Building/Rebuilding Tables, and Clustered Indexes use Compression (DATA_COMPRESSION = PAGE) and place in FGData filegroup. Don't forget (TEXTIMAGE_ON FGBlob) for LOB
-
When Building/Rebuilding Non-clustered Indexes use Compression (DATA_COMPRESSION = PAGE) and place in FGIndexes filegroup
-
Columnstore is best for Archive/Log Tables - (DATA_COMPRESSION = COLUMNSTORE or DATA_COMPRESSION = COLUMNSTORE_ARCHIVE) and place in FGData filegroup
-
Sort In TempDB to minimize file bloat - SORT_IN_TEMPDB = ON
- Don't use Fillfactor
Compression
CREATE TABLE [dbo].[UserResumes]
(
[UserResumeId] [INT] IDENTITY(1, 1) NOT NULL,
[UserResume] [VARCHAR](MAX) NULL,
[UserId] [INT] NOT NULL,
[PrimaryResume] [BIT] NOT NULL CONSTRAINT [DF_UserResumes_PrimaryResume] DEFAULT (0),
[CreatedDatetime] [DATETIME2](0) NOT NULL,
[ModifiedDatetime] [DATETIME2](0) NOT NULL,
) ON [FGData] TEXTIMAGE_ON [FGBlob] WITH (DATA_COMPRESSION = PAGE);
GO
ALTER TABLE [dbo].[UserResumes] ADD CONSTRAINT [PK_UserResumes] PRIMARY KEY CLUSTERED ([UserResumeId] ASC)
WITH (DATA_COMPRESSION = PAGE, ONLINE = OFF) ON [FGData];
GO
CREATE NONCLUSTERED INDEX [IX_UserResumes_UserId_Includes] ON [dbo].[UserResumes]
(
[UserId] ASC
)
INCLUDE([PrimaryResume],[UserResumeId])
WITH (DATA_COMPRESSION = PAGE, SORT_IN_TEMPDB = ON, ONLINE = OFF) ON [FGIndexes]
GOCompression
CREATE TABLE [Dim].[Student]
(
[StudentKey] [int] NOT NULL IDENTITY(-2147483648, 1),
[UserId] [int] NOT NULL,
[FillName] [varchar] (200) NOT NULL,
[EmailAddress] [varchar] (200) NOT NULL,
[City] [varchar] (50) NULL,
[State] [varchar] (50) NULL,
[Zip] [varchar] (10) NULL,
[Long] [decimal] (12, 9) NULL,
[Lat] [decimal] (12, 9) NULL
) ON [FGData]
GO
CREATE CLUSTERED COLUMNSTORE INDEX [CCS_Dim_Student] ON [Dim].[Student] ON [FGData]
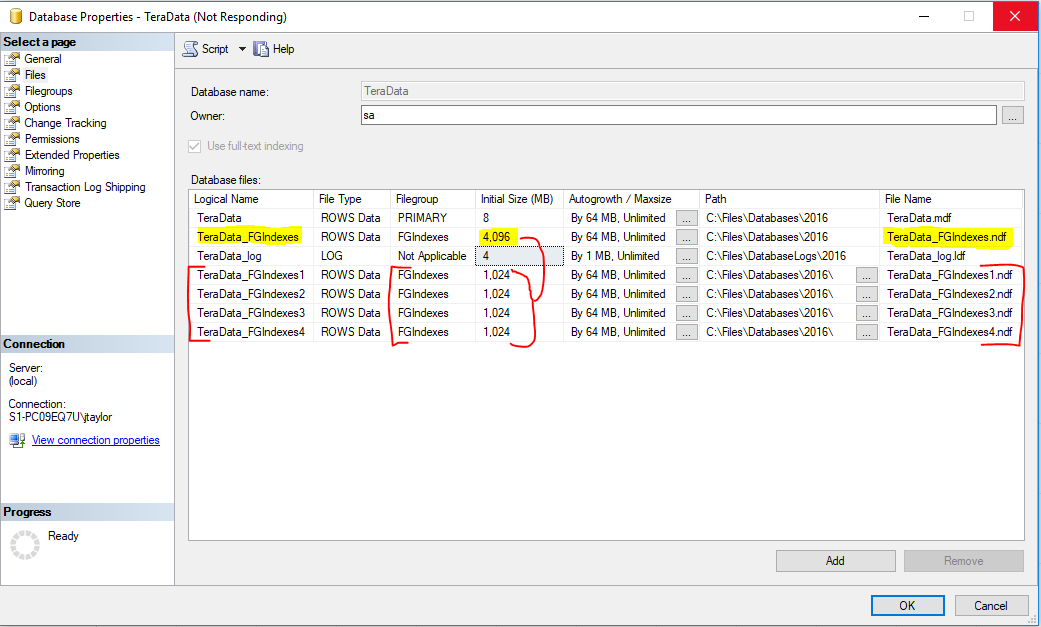
GORedistribute 1 to 4 files
-
If you end up needing more performance, you can add more files to each file group.
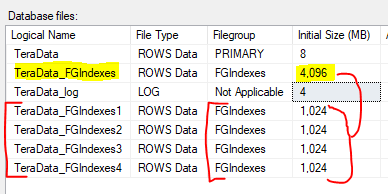
-
Your file groups are now lopsided.
- There is a way to fix that.
USE [MyDatabase]
GO
DBCC SHRINKFILE (N'MyDatabase_FGIndexes' , EMPTYFILE)
GO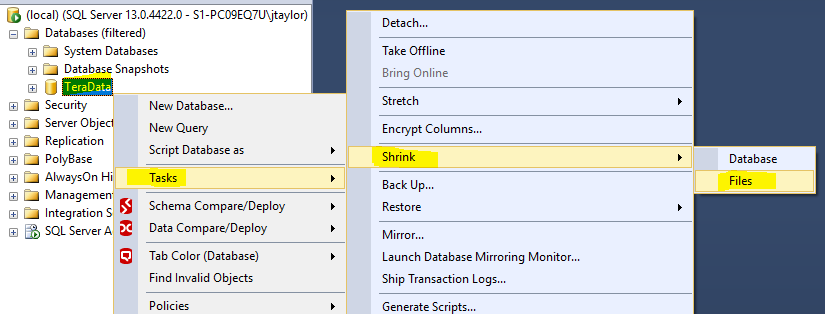
Redistribute 1 to 4 files
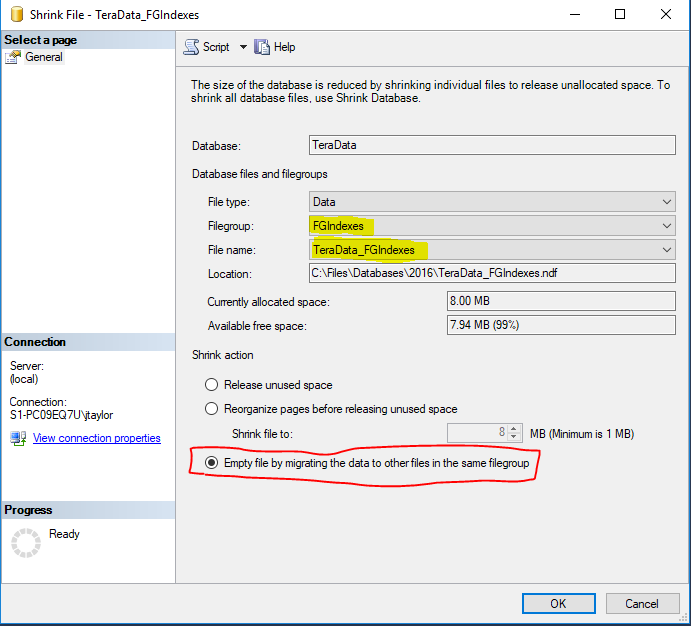
Redistribute 1 to 4 files
Remove Original File in File Group
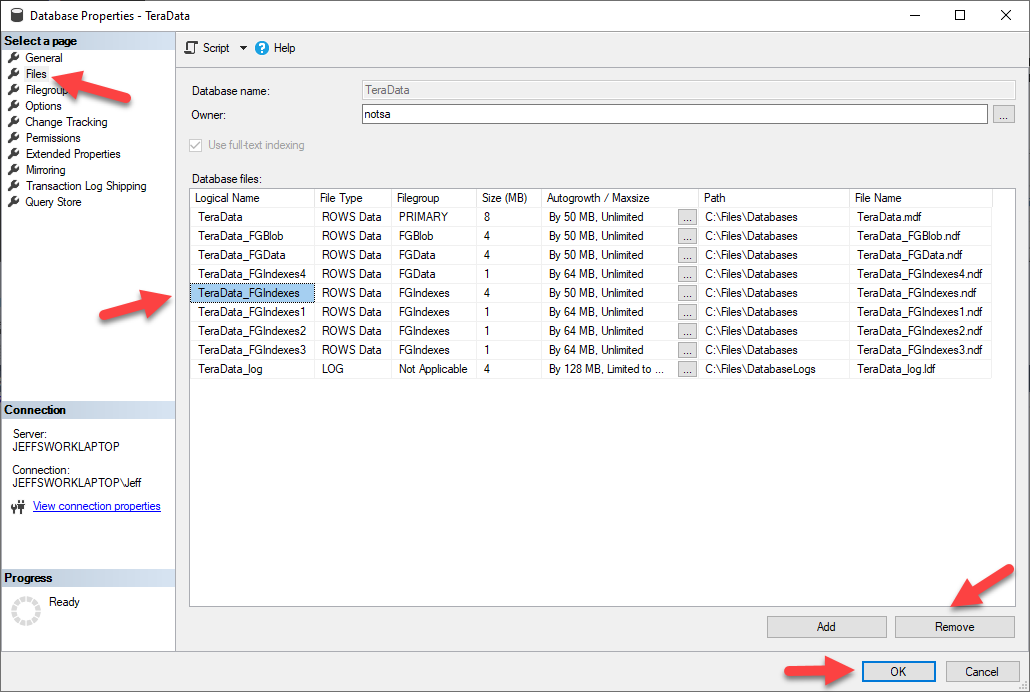
Remove Original File in File Group
USE [TeraData]
GO
ALTER DATABASE [TeraData] REMOVE FILE [TeraData_FGIndexes]
GOFixing Data Types
- Create new column.
- Copy data to new column.
- Check that values match 100% for column.
- Drop old column.
- Rename new column.
Cleanup
- Shrink Primary File Group
USE [MyDatabase]
GO
DBCC SHRINKFILE (N'MyDatabase' , 0, TRUNCATEONLY)
GOCleanup
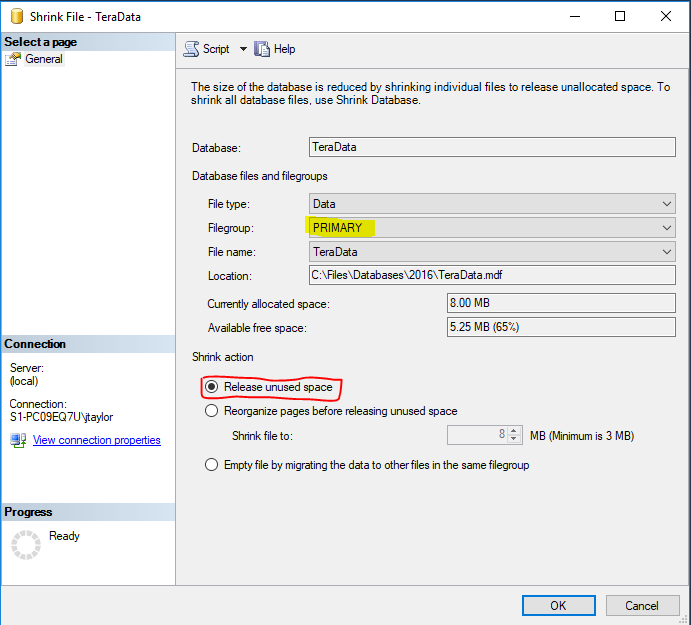
Overall Performance Results
- Overall database size cut in less than half original size using better data types (varchar, datetime2) (4TB to 1.55TB)
- Overall database size down further to 1/3rd of the original size using Page/Columnstore Compression. (4TB down to 500GB)
- Single file database file now spread across multiple LUNS/Disks with multiple (12) files reducing latency from 1,000+ms to less than 20ms.
- Backup speed and restore speed cut in half. (Compression, data types, Instant File Initialization)
- Throughput went from 200/300MBPS to over 2,000mbps (Multi-Path, Jumbo Frames, 1GB to 8GB Fiber/10GB/25GB/40GB Ethernet.)
Resources
DateTime Data Types/Sizes
https://msdn.microsoft.com/en-us/library/ms186724.aspxnchar/nvarchar Data Types/Sizes
https://msdn.microsoft.com/en-us/library/ms186939.aspxbigint/int/smallint/tinyint
https://docs.microsoft.com/en-us/sql/t-sql/data-types/int-bigint-smallint-and-tinyint-transact-sql
text/ntext/image
https://learn.microsoft.com/en-us/sql/t-sql/data-types/ntext-text-and-image-transact-sql

Questions
Thank you
Jeff Taylor


Thank you for attending my session today. If you have any additional questions please don't hesitate to reach out. My contact information is below. Please don't forget to evaluate my session!
How To Tune A Multi-Terabyte Database For Optimum Performance
By reviewmydb
How To Tune A Multi-Terabyte Database For Optimum Performance
This session will cover how to tune a multi-terabyte database where all of the data is stored a single file, primary file group. We will look at file groups, managing indexes and moving large amounts of data.



