Starting from Scratch with Scala Native
Richard Whaling
M1 Finance
Scala Days North America 2018
This talk is about:
- Scala Native
- Systems progamming
but also:
- Working with emerging technology
- OS as platform
(or how to get things done without the JVM)
Talk Outline
- Introduction to Scala Native
- Introduction to Systems Programming
- Case Study: Google NGrams
- Find Maximum
- Sort
- Aggregate and Sort
- Performance vs JVM
- Reflections: When, Where, Why?
About Me
Twitter: @RichardWhaling
Scala Native contributor, but speaking only for myself
Author of "Modern Systems Programming in Scala", coming soon from Pragmatic
Data Engineer at M1 Finance
Scala Native is:
- Scala!
- A scalac/sbt plugin
- An LLVM-based AOT compiler
- Great for command-line tools
- No JVM
- Includes implementations of some JDK classes
- Types and functions for C interop
The Basics
object Hello {
def main(args: Array[String]):Unit = {
println("Hello, Scala Days!")
}
}This just works!
The Basics
import scalanative.native._, stdio._
object Hello {
def main(args: Array[String]):Unit = {
printf(c"Hello, Scala Days!\n")
}
}This just works!
The Basics
import scalanative.native._, stdio._
object Hello {
def main(args: Array[String]):Unit = {
val who:CString = c"Scala Days"
stdio.printf(c"Hello, %s!\n", who)
}
}it really is the glibc printf()
Systems Programming 101
Certain data types are primitive: Ints, Floats, and Bytes
All unmanaged data has an address, represented by a pointer
Pointers are typed, but can be cast to another type at compile time
Pointers are a numeric type and support arithmetic operations
Casting allows one to emulate more robust type systems (awkardly)
Systems Programming 102
A struct is a data structure with typed fields and static layout
The address of any field of a struct is known at compile-time
An array is a typed, sequence-like data structure with static layout
The address of any item in an array is computable in constant time
Arrays can contain primitives, pointers, arrays, and structs
Structs can contain primitives, pointers, arrays, and structs
Systems Programming 103
Strings are not a first-class data type; a string is just a pointer to bytes
Since we don't know array size at runtime, strings are painful
What's a CString?
+--------+----+----+----+----+----+----+----+----+----+----+----+----+----+----+
| Offset | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D |
+--------+----+----+----+----+----+----+----+----+----+----+----+----+----+----+
| Char | H | e | l | l | o | , | | w | o | r | l | d | ! | |
| Hex | 48 | 65 | 6C | 6C | 6F | 2C | 20 | 77 | 6F | 72 | 6C | 64 | 21 | 00 |
+--------+----+----+----+----+----+----+----+----+----+----+----+----+----+----+
- Just like in C, strings are zero-terminated arrays of characters
- The length of a CString is not stored as metadata
- The value of a CString itself is the address of the first character
- CString is just an alias for Ptr[CChar]
- And CChar is just an alias for Byte
- Like other Ptr types in Scala Native, CStrings are mutable.
What's a CString?
val str:CString = c"hello, world"
val str_len = strlen(str)
printf(c"the string '%s' at %p is %d bytes long\n", str, str, str_len)
printf(c"the CString value 'str' is %d bytes long\n", sizeof[CString])
for (offset <- 0L to str_len) {
val chr:CChar = str(offset)
printf(c"'%c' is %d bytes long and has binary value %d\n",
chr, sizeof[CChar], chr)
}- We scan for the end of the string with strlen()
- The length from strlen() does NOT include the null terminator
- We can retrieve individual characters by str(offset)
- Array lookup by offset is a constant time operation
What's a CString?
val str = c"hello, world"
val str_len = strlen(str)
printf(c"the string '%s' at %p is %d bytes long\n", str, str, str_len)
printf(c"the value 'str' itself is %d bytes long\n", sizeof[CString])
for (offset <- 0L to str_len) {
val chr_addr = str + offset // pointer address arithmetic
val chr = !chr_addr // pointer address dereference
stdio.printf(c"'%c'\t(%d) at address %p is %d bytes long\n",
chr, chr, chr_addr, sizeof[CChar])
}- addition (+)
-
dereference (!)
A CString is a Ptr[Byte], so we can re-implement array lookup with two basic pointer operators:
What's a CString?
the string 'hello, world' at address 0x5653b7aa0974 is 12 bytes long
the Ptr[Byte] value 'str' itself is 8 bytes long
'h' (104) at address 0x5653b7aa0974 is 1 bytes long
'e' (101) at address 0x5653b7aa0975 is 1 bytes long
'l' (108) at address 0x5653b7aa0976 is 1 bytes long
'l' (108) at address 0x5653b7aa0977 is 1 bytes long
'o' (111) at address 0x5653b7aa0978 is 1 bytes long
',' (44) at address 0x5653b7aa0979 is 1 bytes long
' ' (32) at address 0x5653b7aa097a is 1 bytes long
'w' (119) at address 0x5653b7aa097b is 1 bytes long
'o' (111) at address 0x5653b7aa097c is 1 bytes long
'r' (114) at address 0x5653b7aa097d is 1 bytes long
'l' (108) at address 0x5653b7aa097e is 1 bytes long
'd' (100) at address 0x5653b7aa097f is 1 bytes long
'' (0) at address 0x5653b7aa0980 is 1 bytes long
Stack Allocation
- Pointers can refer to stack or heap addresses (or Zones)
- Stack pointers are valid for the duration of the calling function
- Zones are awesome but not covered in this talk
val short_lived_int:Ptr[Int] = stackalloc[Int]
val three_short_lived_ints:Ptr[Int] = stackalloc[Int](3)
val uninitialized_string_buffer:CString = stackalloc[CChar](16)
Heap Allocation
val short_lived_int:Ptr[Int] = stackalloc[Int]
val three_short_lived_ints:Ptr[Int] = stackalloc[Int](3)
val uninitialized_string_buffer:CString = stackalloc[CChar](16)
val uninitialized_buffer:Ptr[Byte] = malloc(1024)
val three_ints:Ptr[Int] = malloc(3 * sizeof[Int]).cast[Ptr[Int]]
val six_ints:Ptr[Int] = realloc(three_ints.cast[Ptr[Byte], 6 * sizeof[Int])
.cast[Ptr[Int]]
def heapalloc[T](num:Int = 1) = malloc(num * sizeof[T]).cast[Ptr[T]]- malloc gives us a Ptr[Byte] of the requested size
- in Scala Native we cast the result of malloc
- realloc resizes a malloc-managed pointer
- realloc may invalidate old pointers - use sparingly!
- no GC - malloc leaks unless you call free(ptr)
C FFI
@extern object mystdio {
def fgetc(stream: Ptr[FILE]): CInt = extern
def fgets(str: CString, count: CInt, stream: Ptr[FILE]): CString = extern
def fputc(ch: CInt, stream: Ptr[FILE]): CInt = extern
@name("scalanative_libc_stdin")
def stdin: Ptr[FILE] = extern
@name("scalanative_libc_stdout")
def stdout: Ptr[FILE] = extern
}
val buffer = stackalloc[Byte](1024)
val line = mystdio.fgets(buffer, 1023, mystdio.stdin)- Scala Native's C-style types make C interop easy
- Simple to create a binding for standard or third-party C functions
- Without the JVM, we rely on ANSI/POSIX C functions
- Scala can often improve on C in terms of safety and clarity
A few C functions
def fprintf(stream: Ptr[FILE], format: CString, args: CVararg*): CInt
def fgets(str: CString, count: CInt, stream: Ptr[FILE]): CString
def sscanf(buffer: CString, format: CString, args: CVararg*): CInt
def strcmp(lhs: CString, rhs: CString): CInt
def strncpy(dest: CString, src: CString, count: CSize): CStringLet's be real: the C stdlib's string facilities are badly broken.
We'll be ensuring safety in three ways:
- Relying on a few less-broken functions like fgets()
- Statically limiting the maximum size of our strings
- Wrapping a few particularly problematic functions
Whew!
Now we're (finally) ready to write some real programs!
Systems programming is never trivial, but Scala Native presents the fundamental concepts more clearly than C.
Scala Native's compiler is state-of-the-art, but the DSL it provides for C-style memory semantics is more powerful than any compiler.
The techniques we've learned will let us write programs with dramatically different performance characteristics than JVM Scala.
Google NGrams
- Tab-delimited text files
- Each line has word - year - count - doc_count
- Separated by 1st letter
- "A" ~2GB
Word counts for the entire Google Books corpus, ~50GB total
This is big enough data to ask some interesting questions:
- What's the most frequent word?
- What are the top 20 words?
- What are the top 20 words aggregated
over all years?
Google NGrams
A'Aang_NOUN 1879 45 5
A'Aang_NOUN 1882 5 4
A'Aang_NOUN 1885 1 1
A'Aang_NOUN 1891 1 1
A'Aang_NOUN 1899 20 4
A'Aang_NOUN 1927 3 1
A'Aang_NOUN 1959 5 2
A'Aang_NOUN 1962 2 2
A'Aang_NOUN 1963 1 1
A'Aang_NOUN 1966 45 13
A'Aang_NOUN 1967 6 4
A'Aang_NOUN 1968 5 4
A'Aang_NOUN 1970 6 2
A'Aang_NOUN 1975 4 1
A'Aang_NOUN 2001 1 1
A'Aang_NOUN 2004 3 1
A'que_ADJ 1808 1 1
A'que_ADJ 1849 2 1
A'que_ADJ 1850 1 1
A'que_ADJ 1852 4 3Maximum Count (JVM)
var max = 0
var max_word = ""
var max_year = 0
for (line <- scala.io.Source.stdin.getLines) {
val split_fields = line.split("\\s+")
val word = split_fields(0)
val year = split_fields(1)
val count = split_fields(2).toInt
if (count > max) {
max = count
max_word = word
max_year = year
}
}
println(s"max count: ${max_word}, ${max_year}; ${max} occurrences")
Maximum Count (Native)
val linebuffer = stackalloc[Byte](1024)
val max_count = stackalloc[Int]
val max_word = stackalloc[Byte](1024)
val max_year = stackalloc[Int]
while (fgets(stdin, linebuffer, 1023) != null) }
scan_and_compare(linebuffer, 1023, max_count, max_word, max_year)
}
printf(c"maximum word count: %d %s %d\n", max_count, max_word, max_year)
Our strategy:
- Allocate storage for the current max and a single line of input
- While we can read lines from stdin into the line_buffer:
- pass the line_buffer and pointers to the current max into a scan_and_compare() function
Find Maximum Count
def scan_and_compare(buffer:Ptr[Byte], max_count:Ptr[Int],
max_word:Ptr[Byte], max_year:Ptr[Int]):Unit = {
val tmp_count = stackalloc[Int]
val tmp_word = stackalloc[Byte](1024)
val tmp_year = stackalloc[Int]
val tmp_doc_count = stackalloc[Int]
val scan_result = sscanf(buffer, c"%1023s %d %d %d\n",
tmp_word,tmp_count, tmp_year, tmp_doc_count)
if (scan_result != 4) {
throw new Exception("Bad sscanf result")
}
if (!tmp_count > !max_count) {
val word_length = strlen(temp_word)
safer_strncpy(temp_word, max_word, 1024)
!max_count = !temp_count
!max_year = !temp_year
}
}
- stack allocation is basically free
- checking scanf results is a PAIN
- the dereference operator ! lets us treat pointers as mutable cells
Performance
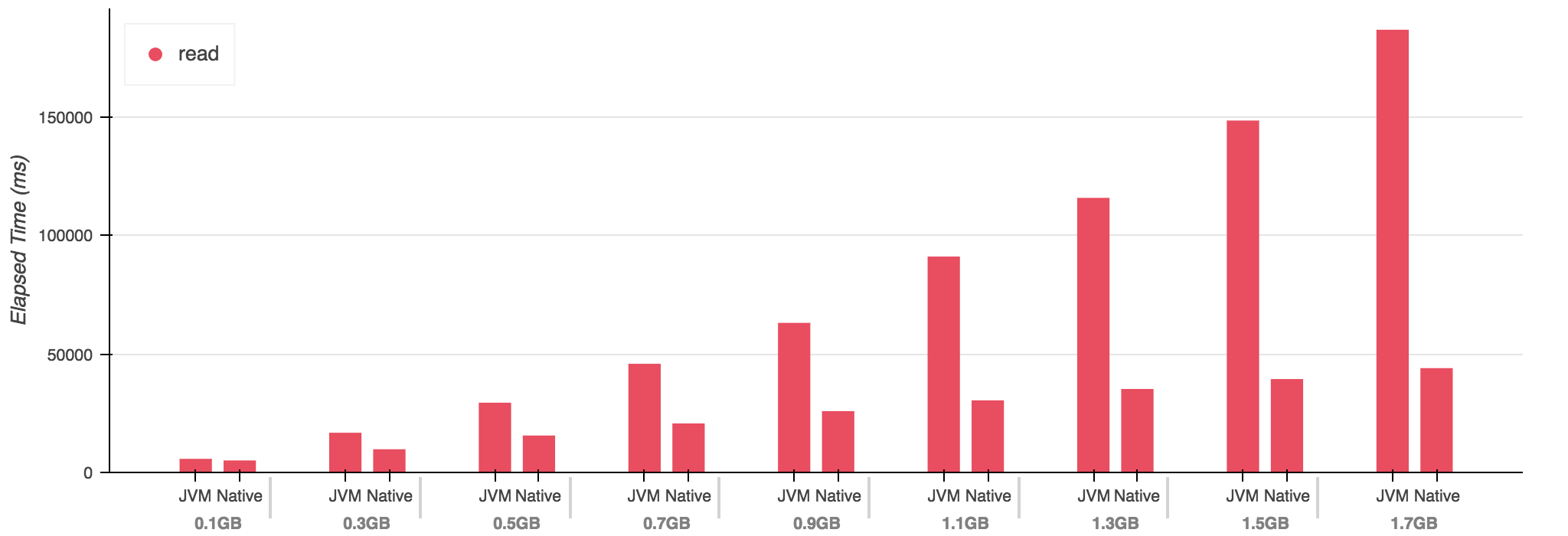
- The performance differential starts small but diverges rapidly
- This program should not generate a large heap -
- The JVM implementation allocates heavily, however
- Whereas our native implementation only allocates on the stack
Sorting NGrams
- Tab-delimited text files
- Each line has word - year - count - doc_count
- Separated by 1st letter
- "A" ~2GB
Word counts for the entire Google Books corpus, ~50GB total
For our next trick:
- Sort the entire "A" file
- This will use heap much more intensively
- Little garbage - most memory allocated stays around
- (This is the inverse of the last program we wrote)
Sorting: JVM
case class NGram(word:String, count:Int, year:Int, doc_count:Int)
def read_input(input:Source):ArrayBuffer[NGram] = {
val data = ArrayBuffer[NGram]()
var lines_read = 0
for (line <- scala.io.Source.stdin.getLines) {
val split_fields = line.split("\\s+")
val word = split_fields(0)
val year = split_fields(1).toInt
val count = split_fields(2).toInt
val doc_count = split_fields(3).toInt
val new_item = NGram(word, year, count, doc_count)
data += new_item
}
return data
}Sorting: JVM
def main(args:Array[String]):Unit = {
val data:ArrayBuffer[NGram] = read_input(scala.io.Source.stdin)
val by_count_ascending = Ordering.by { n:NGram => n.count }.reverse
val sorted = data.sorted(by_count_ascending)
val show_count = if (lines_read < 20) lines_read else 20
for (i <- 0 until show_count) {
println(s"${sorted(i).word} ${sorted(i).count}")
}
}Sorting: Native
How do we do this in a Native idiom?
- Model NGramData as a Struct
- Read input into an array of NGramData
- Resize array as necessary
- Sort array when done.
This will require more techniques than the prior case:
- structs
- malloc/realloc
- qsort
What's a CStruct?
type StructPoint = CStruct2[Int, Int]
val point = stackalloc[StructPoint]
point._1 = 5
point._2 = 12
+--------+----+----+----+----+----+----+----+----+
| Offset | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+--------+----+----+----+----+----+----+----+----+
| Value | 5 | 12 |
+--------+----+----+----+----+----+----+----+----+
| Hex | 05 | 00 | 00 | 00 | 0C | 00 | 00 | 00 |
+--------+----+----+----+----+----+----+----+----+- A struct is a composite data type in contiguous memory
- The fields of a struct have a static layout at compile time
- Arrays of structs are extraordinarily efficient
- Structs are allocated on the stack or heap explicitly
- Structs are (currently) treated like tuples
- Scala-Native 0.4 will add named fields
Modeling an NGram
case class NGram(word:String, count:Int, year:Int, doc_count:Int)
type NGramData = CStruct4[CString, Int, Int, Int]- Basically, an NGram is a Tuple4
- Strings in structs are tricky
- The Struct contains the address of the string, not the content
- We will need to separately allocate space for string content
- These strings will need to outlive our line-input function
- So we need something longer-lived than stackalloc
Sorting: Native
final case class WrappedArray[T](var data:Ptr[T], var used:Int, var capacity:Int)
def makeWrappedArray[T](size:Int):WrappedArray[T] = {
val data = malloc(size * sizeof[T]).cast[Ptr[T]]
return WrappedArray(data, 0, size)
}
def growWrappedArray[T](array:WrappedArray[T], size:Int):Unit = {
val new_capacity = array.capacity + size
val new_size = new_capacity * sizeof[T]
val new_data = realloc(array.data.cast[Ptr[Byte]], new_size)
wa.data = new_data
wa.capacity = new_capacity
}
- realloc() is potentially expensive
- in the worst case it can require copying the entire array to a new location
- we can manage this cost by adjusting the "chunk size" that we allocate and grow by
Sorting: Native
def qsort(data:Ptr[Byte],
num:Int,
size:Long,
comparator:CFunctionPtr2[Ptr[Byte], Ptr[Byte], Int]):Unit = extern
def sort_alphabetically(a:Ptr[Byte], b:Ptr[Byte]):Int = {
val a_string_pointer = a.cast[Ptr[CString]]
val b_string_pointer = b.cast[Ptr[CString]]
return string.strcmp(!a_string_pointer, !b_string_pointer)
}
def sort_by_count(p1:Ptr[Byte], p2:Ptr[Byte]):Int = {
val ngram_ptr_1 = p1.cast[Ptr[NGramData]]
val ngram_ptr_2 = p2.cast[Ptr[NGramData]]
val count_1 = !ngram_ptr_1._2
val count_2 = !ngram_ptr_2._2
return count_2 - count_1
}- Once we have an array of structs, we can sort it with qsort()
- qsort takes a function pointer for its comparator
- Allows for "generic" objects via unsafe casting!
Sorting: Native
val block_size = 65536 * 16 // ~ 1 million items - too big?
val linebuffer = stackalloc[Byte](1024)
var array = makeWrappedArray[NGramData](block_size)
while (stdio.fgets(line_buffer, 1023, stdin) != null) {
if (array.used == array.capacity) {
growWrappedArray(array, block_size)
}
parseLine(line_buffer, array.data + array.used)
array.used += 1
}
qsort.qsort(array.data.cast[Ptr[Byte]], array.used,
sizeof[NGramData], by_count)
val to_show = if (array.used <= 20) array.used else 20
for (i <- 0 until to_show) {
stdio.printf(c"word n: %s %d\n", !(array.data + i)._1, !(array.data + i)._2)
}
Sorting: Native
def parseLine(line_buffer:Ptr[Byte], data:Ptr[NGramData]):Unit = {
val word = data._1
val count = data._2
val year = data._3
val doc_count = data._4
val sscanf_result = stdio.sscanf(line_buffer, c"%ms %d %d %d\n", word, year, count, doc_count)
if (sscanf_result < 4) {
throw new Exception("input error")
}
}
- Because we pass in a valid Ptr[NGramData] we don't have to use stackalloc
- We do have to allocate space for the string but here I'm letting sscanf do it for me with the "%ms" format
Performance
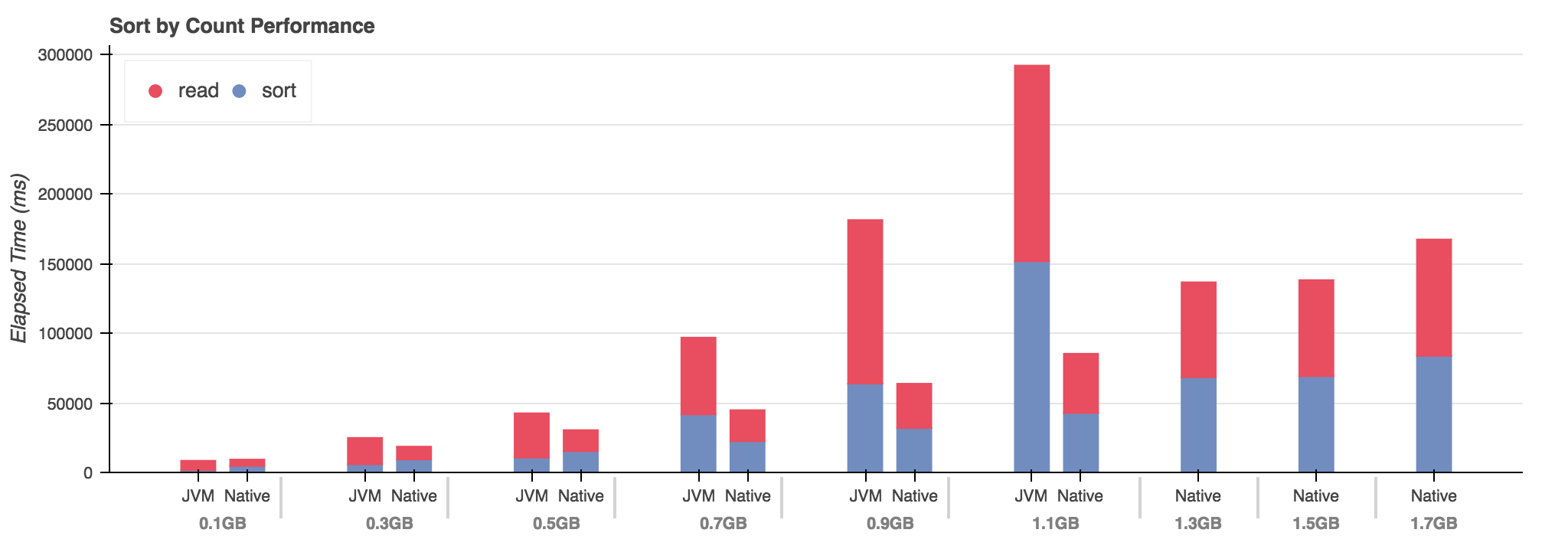
- Equivalent performance at start.
- JVM initially has faster sort, Native has faster IO
- JVM maintains faster sort until 0.7GB
- After 1.1GB JVM cannot complete on a 7.0GB Docker VM
Aggregating NGrams
- Tab-delimited text files
- Each line has word - year - count - doc_count
- Separated by 1st letter
- "A" ~2GB
Word counts for the entire Google Books corpus, ~50GB total
Final use case:
- Group together occurrences of a word for all years
- Then sort total counts
- This should use less total heap because we store less
- We can avoid storing the whole dataset because input is sorted by word
Aggregation: JVM
def read_input(input:Source):ArrayBuffer[NGram] = {
val data = ArrayBuffer[NGram]()
var prev_word = ""
for (line <- scala.io.Source.stdin.getLines) {
val split_fields = line.split("\\s+")
// ... check for errors
val word = split_fields(0)
val year = split_fields(1).toInt
val count = split_fields(2).toInt
val doc_count = split_fields(3).toInt
if (word == prev_word) {
data.last.count += count
} else {
val new_item = NGram(word, year, count, doc_count)
data += new_item
prev_word = word
}
}
return data
}Aggregation: Native
Our strategy:
- Almost identical code to the previous exercise
- Read input into an array of NGramData
- Resize as necessary
- Sort at the end
- Check to see if the word we have is new or not
- If not a new word, add its count to previous item
- Return a true/false flag from parseLine
- if parseLine returns true, then increment a.used
What we'll change:
Aggregation: Native
var prev_item:Ptr[NGramData] = null
while (stdio.fgets(line_buffer, 1023, stdin) != null) {
if (array.used == array.capacity) {
growWrappedArray(array, block_size)
}
val is_new_word = parseLine(line_buffer, array.data + array.used, prev_item)
if (is_new_word) {
prev_item = array.data + array.used
array.used += 1
}
}
- We track a pointer to the last item we read
- We always read into array.data + array.used
- We return a flag from parseLine to indicate a new word
- We bump array.used and prev_item only if the word is new
Aggregation: Native
def parseLine(line_buffer:CString, prev_item:Ptr[NGramData],
current_item:Ptr[NGramData]):Boolean = {
val temp_word = stackalloc[Byte](1024)
val temp_count = current_item._2
val temp_year = current_item._3
val temp_doc_count = current_item._4
sscanf(line_buffer, c"%1023s %d %d %d\n", temp_word, temp_year, temp_count, temp_doc_count)
val new_word_length = strlen(temp_word)
if (prev_item == null) {
val new_word_buffer = malloc(new_word_length + 1)
safer_strncpy(temp_word, new_word_buffer, 1023)
!current_item._1 = new_word_buffer
return true
}
else if (strcmp(temp_word, !prev_item._1) == 0) {
!current_item._2 = !current_item._2 + !temp_count
return false
} else {
val new_word_buffer = malloc(new_word_length + 1)
safer_strncpy(temp_word, new_word_buffer, 1023)
current_item._1 = new_word_buffer
return true
}
}
Performance
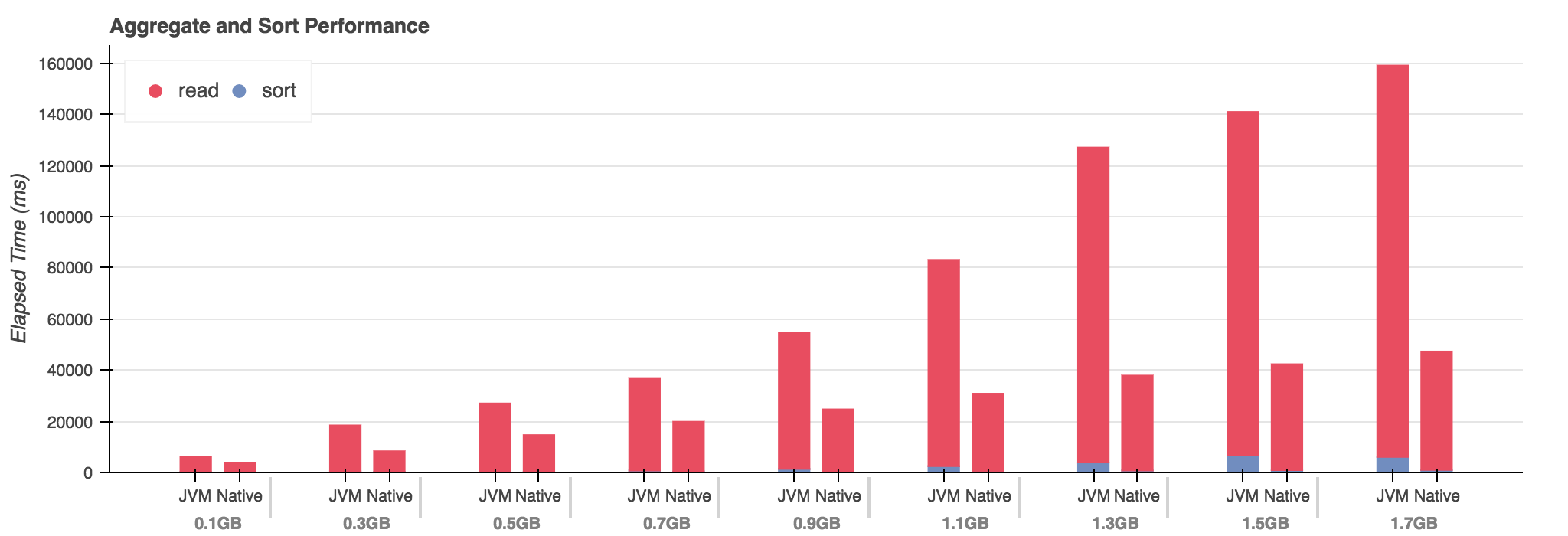
- Native wins again, initial factor of 2x
- Native consistently has faster sort by 2x
- Sort remains under 1s for Native, diverges for JVM
- Hypothesis: data set is too small for JIT to fully warm?
Reflections
I hope that I've demonstrated that:
- There are substantial benefits to using a C-style memory model within the context of a larger, garbage-collected programming environment
- The legacy JVM memory model seems to perform unusually poorly for heavy IO/large heap situations
If you accept this, it raises the question:
where could it be appropriate to use Scala Native?
Reflections
Caveats:
- Performance isn't everything
- Unsafe memory is unsafe
- C programs are best below 10000 loc
- Working on large shared C codebases is hard
However:
- We are getting better at decomposing systems into parts
- More and more meaningful problems can be solved by small, elegant programs
- The community is getting very good at metaprogramming





Reflections
I suggest that two of the highest profile applications of Scala fall into this big-heap/heavy-io domain:
- Functional/Relational data pipelines (Spark)
- Event-based, low latency services (Akka, Finagle, etc)
Existing Scala projects in these areas are outstanding software. But there are hardware changes on the horizon.

- This is persistent memory (NVRAM)
- Durable, byte-addressable storage
- Large, heterogeneous heaps
- RDMA - read and write over the network
This will break every assumption about storage, memory, and cache hierarchy made by legacy systems.
Hardware is Changing


Reflections
To the extent that a hard break with the past is necessary, Scala Native is not a step back, but a step forward.
Thank You!
Twitter: @RichardWhaling
Starting from Scratch in Scala Native (NYC)
By Richard Whaling




