The biggest data of all?
A brief introduction to logs
Richard Whaling
@RichardWhaling
Spantree Technology Group
This is a talk about logs

Why are logs so hard to get right?
-
Logs as a data problem
-
Logs as a resource planning problem
-
Logs as an architectural problem
(And how do we do better?)
This is a talk about data
Data as method:
-
Measure everything
-
Design experiments
-
Plan for the future
Benchmarks
-
Testing 3 log analysis systems:
-
Elasticsearch
-
OkLog
-
Humio
-
-
Chosen to illustrate technical differences
-
Not a "versus" talk
-
I use all of them
About me
Disclosure
- We've consulted for Humio
- We are Elastic partners
What are logs?
A log is a record of the events occurring within an organization’s systems and networks.
Logs are composed of log entries.
Each entry contains information related to a specific event that has occurred within a system or network.
NIST Special Publication 800-92:
http://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-92.pdf
The tricky part
- As your system continues to operate, your logs are unbounded.
- They will grow to infinity if you don't do something about them.
- The variable factor is: how fast do they grow?
Estimation
- How many bytes is each log event? (Size, S)
- How many events occur per minute? (Rate, R)
- How many minutes in an hour? (60)
- How many hours in a day? (24)
S * R * 60 * 24
Estimation
- Let's assume S = 100 bytes
at 1 events/minute: 100 * 1 * 60 * 24 = 144 KB / Day
Estimation
- Let's assume S = 100 bytes
at 1 events/minute: 100 * 1 * 60 * 24 = 144 KB / Day
at 1,000 events/minute: 100 * 1000 * 60 * 24 = 144 MB / Day
Estimation
- Let's assume S = 100 bytes
at 1 events/minute: 100 * 1 * 60 * 24 = 144 KB / Day
at 1,000 events/minute: 100 * 1000 * 60 * 24 = 144 MB / Day
at 1,000,000 events/minute: 100 * 1000000 * 60 *24 = 144 GB / Day
...
Transport
- Where do I have to send all these events?
- Does a centralized server become a bottleneck?
- Does bandwidth to a hosted service become a bottleneck?
- How do I buffer for bursts of activity?
Transport
- You might have a transport issue if:
- Your logs are bursty
- You are scaling vertically
- Your network bandwidth is insufficient
For a self-hosted system, capacity is much more likely to be a bottleneck
Rotation and Retention
We fit an unbounded stream of events into a finite system by discarding older events, i.e., log rotation.
Two ways to plan for capacity and retentions:
- Resource driven:
- Budget / Cost per day = Days of retention
- Requirement driven:
- Required retention * cost per day = Budget
Why Keep Logs at all?
- Compliance
- Security
- Operations
- Development
(Although these are not entirely distinct categories, they provide distinct perspectives and use cases)
1. Compliance
- Some events must be retained for 3-7 years (PCI, FISMA, HIPAA)
- Some events must be retained forever.
- Generally no usability requirements whatsoever.
- Bulk tape storage can be entirely sufficient.
2. Security
- Retention is still key
- But so is responsiveness
- Detecting anomalies as quickly as possible is essential
- Seconds of buffering lag or backpressure count
- Many high-throughput filter and anomaly detection processes
- Can typically work on lower-volume subsets of logs
- Ad-hoc queries for more active investigation
3. Operations
- In an ideal world, ops would never have to look at logs
- But unexpected phenomena are a reality
- Diagnostics, root cause analysis
- Ad-hoc queries over high-volume system logs
- Handling unstructured logs is essential
- Scalable expressive search is a must
- What about business events?
4. Development
- Developers work with application logs, produced by the code they write
- Business events should generally all appear at this level
- Structured logging is a possibility
- Business and product metrics are vital
- Dashboards
- Level of detail matters
- ...
Bending the cost curve
How do we build a log analysis system that is efficient enough to meet all these needs, without imposing an enormous operational burden?
A poorly maintained system can be worse than useless.
Real systems always have tradeoffs.
(Let's not create more problems than we solve)
Benchmarks
Experiment Design
-
Testing 3 log analysis systems:
-
Elasticsearch
-
OkLog
-
Humio
-
-
Chosen to illustrate technical differences
-
Not a "versus" talk
-
I use all of them
Experiment Design
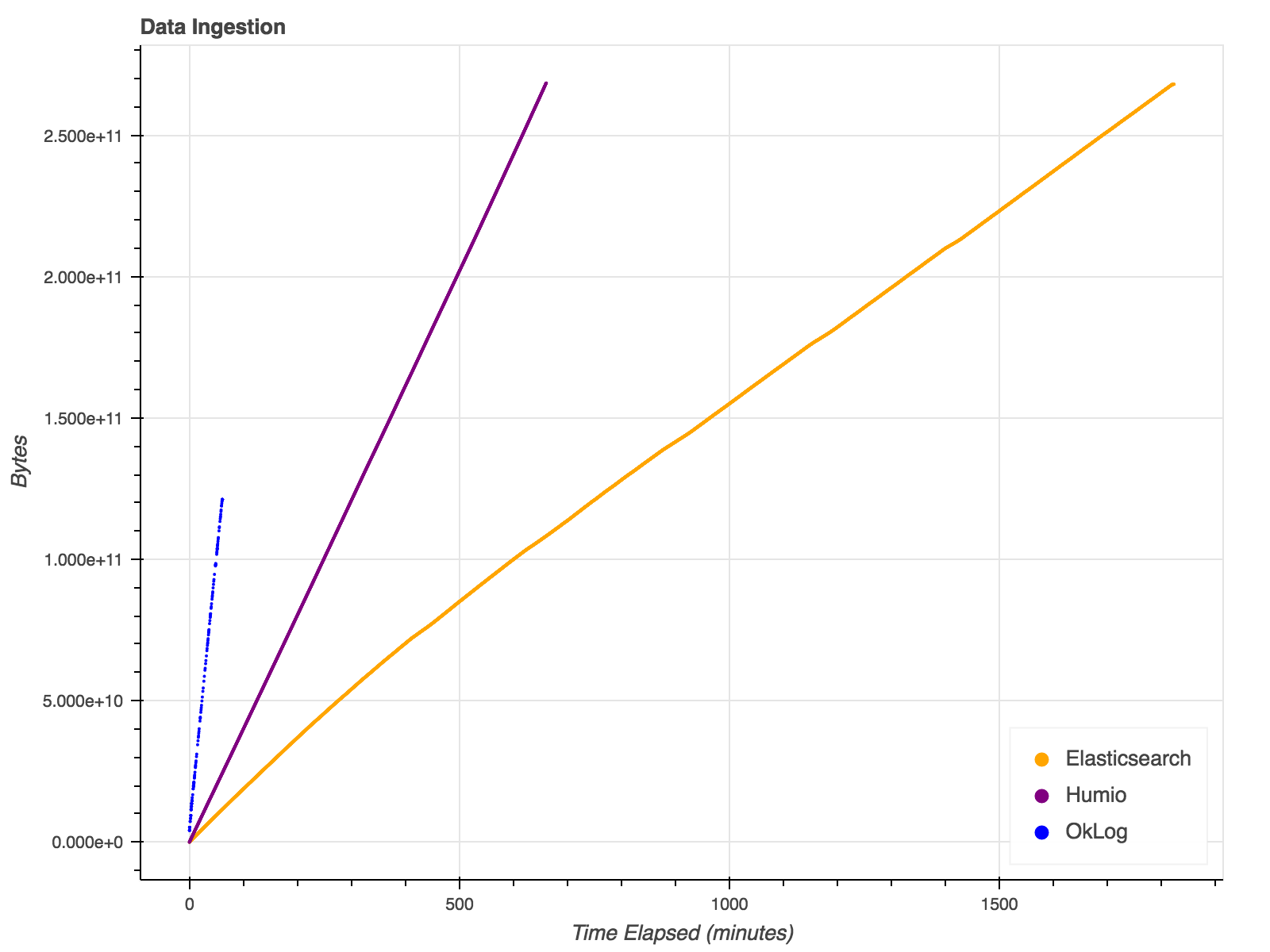
- Bulk Ingestion/Capacity testing on all databases
- Simulated 100GB of web services logs over 24 hours
- Query testing on each database:
- Designed to isolate interesting characteristics
- Not directly comparable between products
Experiment Design
- AWS r3.2xlarge instances -- 8 CPU, 61 GiB RAM
- Dedicated DB Node + Dedicated Driver/Instrumentation Node
- Prometheus as metrics database as well as collection
- Lightweight scrapers to expose data to Prometheus
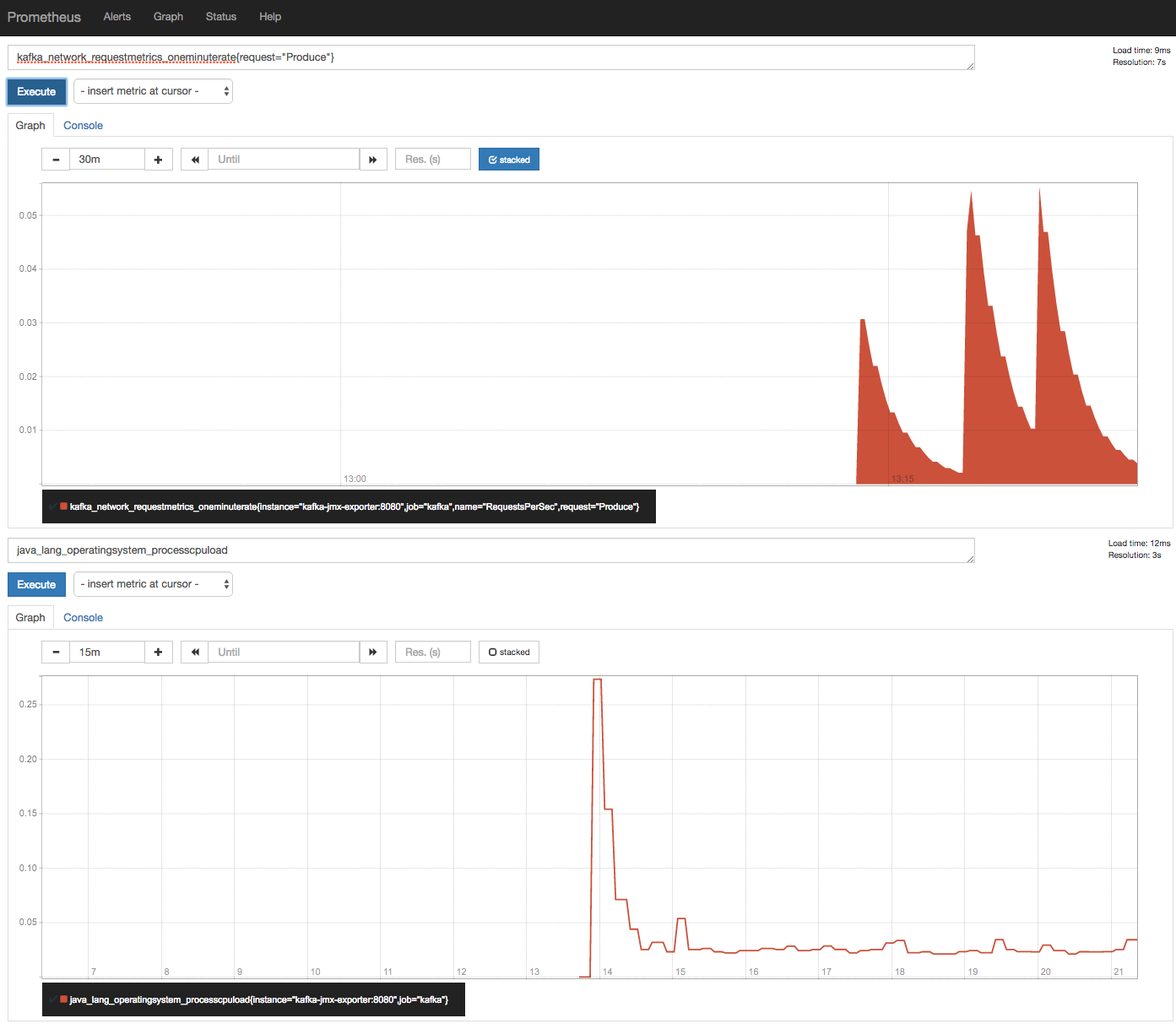
Experiment Design
- AWS r3.2xlarge instances -- 8 CPU, 61 GiB RAM
- Dedicated DB Node + Dedicated Driver/Instrumentation Node
- Prometheus as metrics database as well as collection
- Lightweight scrapers to expose data to Prometheus
Versions:
OkLog 0.2.1
Humio 0.0.37
Elasticsearch 5.2.1

Credit: Digital Ocean, "How To Install Elasticsearch, Logstash, and Kibana (ELK Stack) on Ubuntu 14.04"
Inverted Index
Text
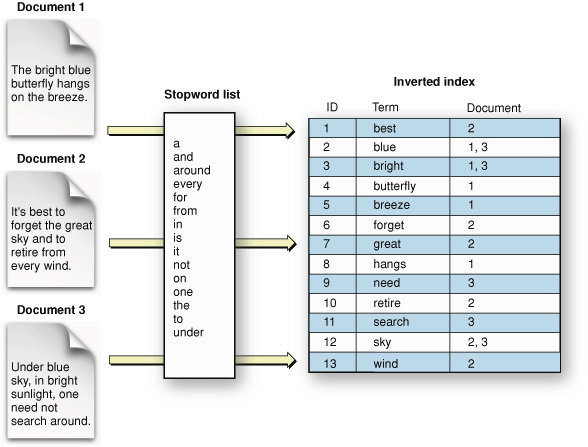
Credit: "Search Basics", Apple SearchKit Developer guide
Lucene
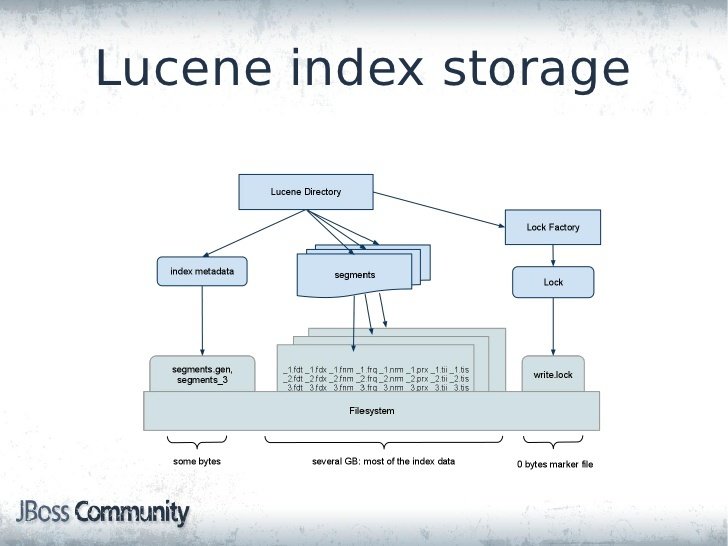
Elasticsearch:
Query Characteristics
- Fast responses to simple queries
- Query complexity => slower queries
- Aggressive Caching
- Fast Aggregations
- Comprehensive query language
- Excellent for structured data
- Paging Slow
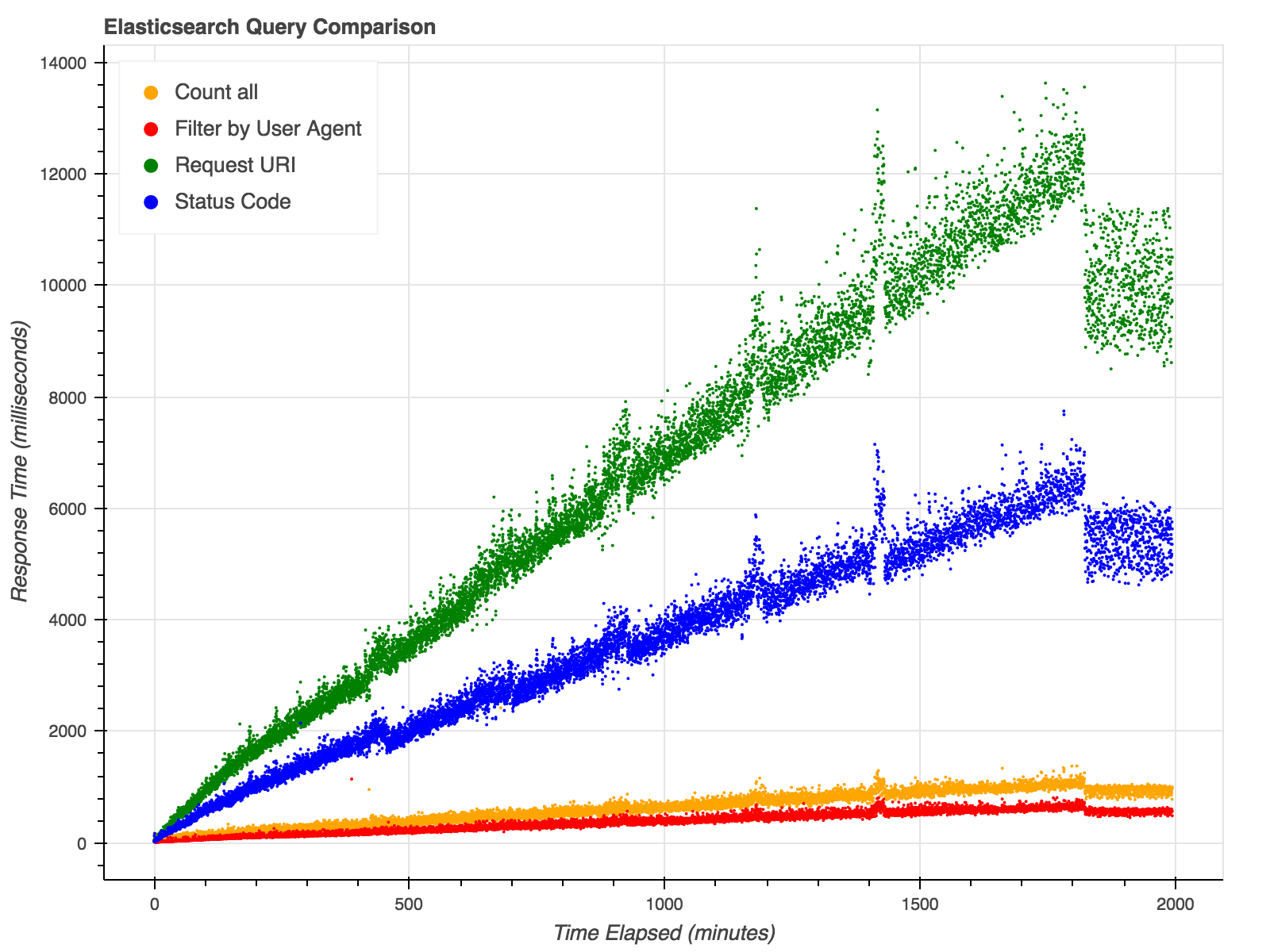
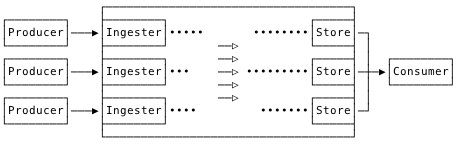
Architecture
Compaction
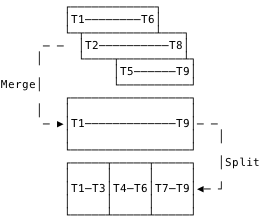
OkLog:
Query Characteristics
- No Index
- Fast Grep
- Fast Full Scans
- "Firehose" streaming
- No aggregations
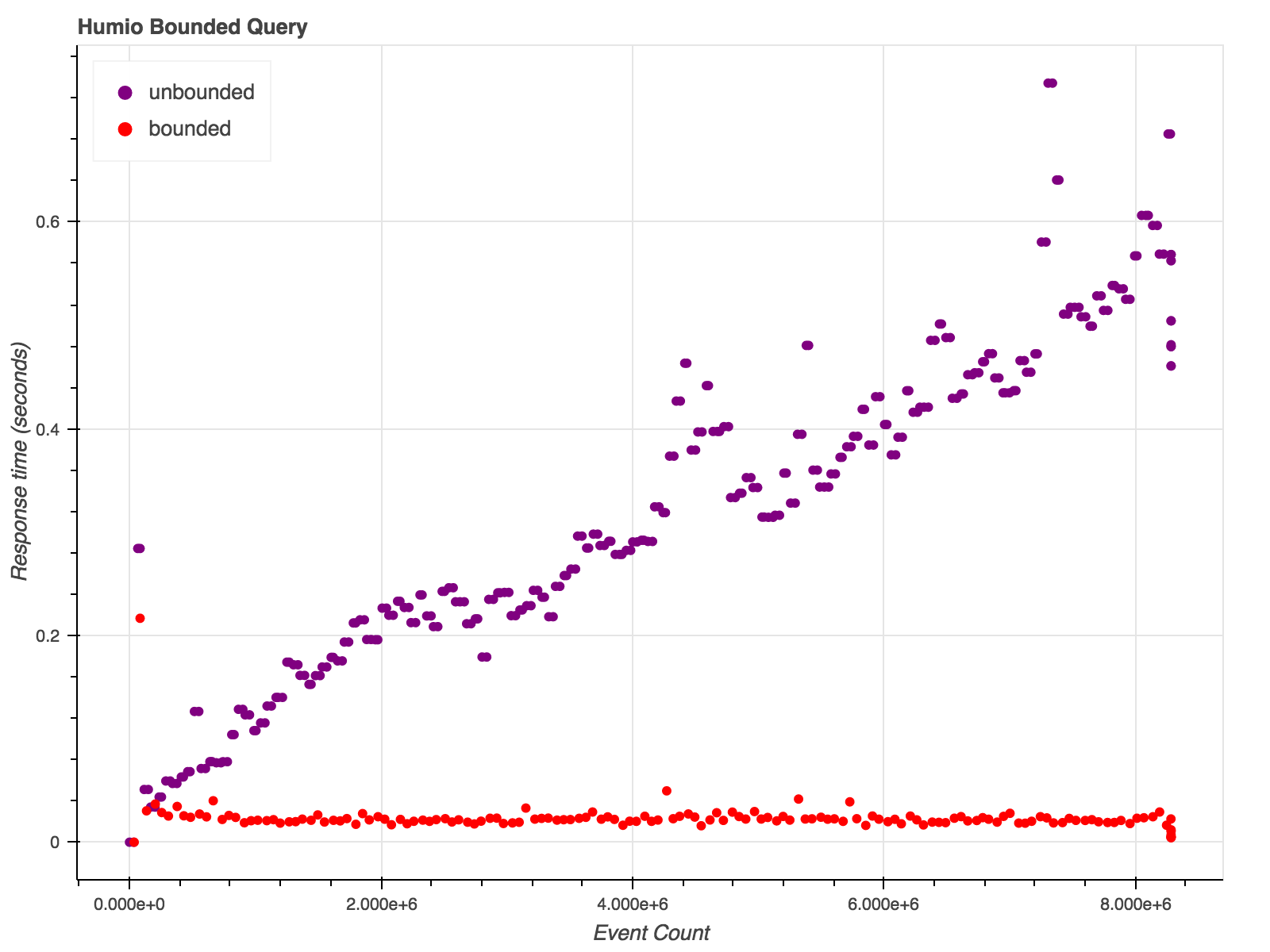
- Bounded queries in constant time
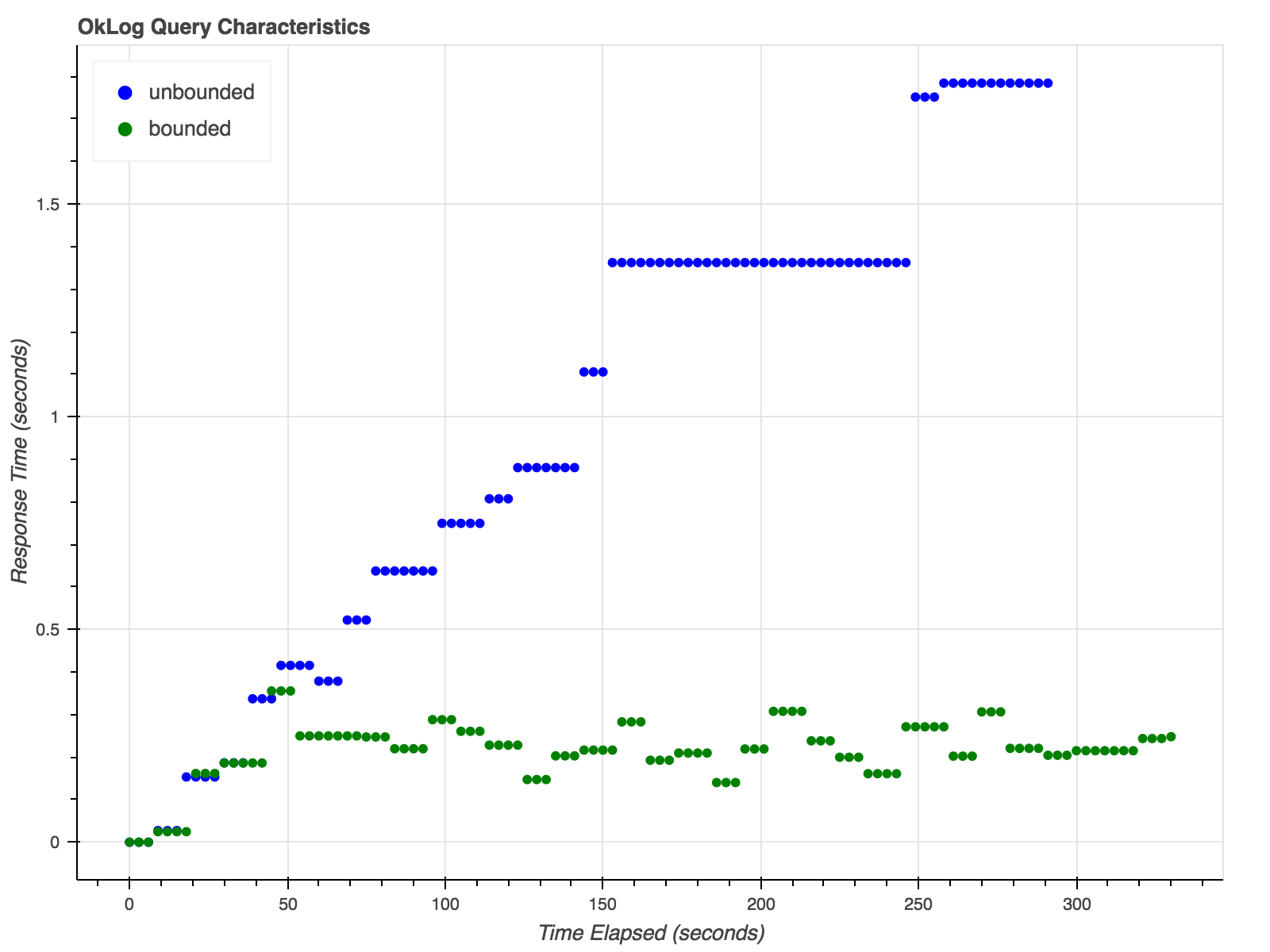

Humio: Architecture
- No Index
- Segmented by time and multiple tags
- Heavy compression at ingest time
- Actor model for distributed deployment
- Subscriptions
- Pre-computed aggregations
- "Unix pipes" query language
Humio:
Query Characteristics
- Fast Grep
- Fast Full Scans
- "Firehose" streaming
- Structured data
- Streaming aggregations
- Bounded queries in constant time
- Historical queries in linear time
| Elasticsearch | OkLog | Humio |
|---|---|---|
| Ad Hoc Queries | Streaming Queries | Streaming Queries |
| Global Aggregations | Bounded Queries | Prepared Aggregation |
| Structured Data | Unstructured Data | Structured Data |
| Full Text | Grep | Grep |
| Global Search | Ingestion | Compression |
Different Strengths
Hard Decisions
- What are my non-negotiable requirements?
- How constrained are my resources?
- Structured or unstructured logs?
- Vertical or horizontal scaling?
- Ingestion or Capacity Bottleneck?
- Usability?
Bending the cost curve
Tiers of service:
- Metrics: high frequency, low detail
- Fast Logs: structured data and application logs
- Big Logs: unstructued data and system logs
- Compliance: cold storage
Retrofitting
- Unstructured log support essential
- Vertical scaling preferred to horizontal
- Integrations
- Dashboards and visualizations
- Self-hosted or SaaS?
Designing from Scratch
- Close integration of logs with metrics
- Time-series database (Prometheus, InfluxDB, etc)
- Alignment with cluster middleware (k8s, Mesos?)
- Invest in structured logging
- Vertical or horizontal scaling?
- Self-hosted or SaaS?
One Last Thought
What Are Logs?

Credit: @mipsytipsy (Charity Majors):
#loghaiku
Thanks!
The biggest data of all? A brief introduction to logs
By Richard Whaling




