Execução Em clusters e GPUs
Como conseguir o máximo de seu modelo ML/DL
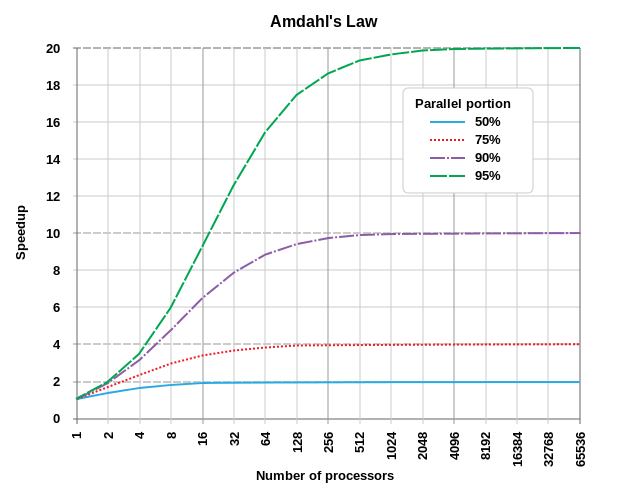
Amdahl's law
Paralelização


Horizontal
Vertical
Clusters
Trabalha-se com uma arquitetura master-slave, nos utilizando das próprias habilidades da biblioteca para criar novos "workers"
GPU
De forma similar, a biblioteca é capaz de se utilizar de todo o poder computacional do hardware, porém temos uma instalação customizada.
Uma combinação de ambos é o melhor cenário
Paralelização de entrada
CPU-Bound
Tarefas que são restritas pela velocidade/frequência de processamento e não paralelizáveis podem ser uma bottleneck em nosso processo. A solução é tentar criar unidades paralelizáveis para otimização.
IO-Bound
Operações de leitura e escrita podem ser uma bottleneck. Trabalhar com maneiras thread-safe de lidar com isso é recomendado.
Dependência de modelos
Existe uma dependência entre modelos e isso causa um bottleneck.
Soluções possíveis:
- Trabalhar com um único modelo complexo;
- Trabalhar com pipelines (manuais ou automatizadas);
Treinamento
Tensorflow, Pytorch, Theano são bibliotecas extremamente avançadas que são capazes de se paralelizar em demanda.
Em um ambiente de cluster, algumas instruções especiais são necessárias. Podemos utilizar o sistema de multi-worker do TensorFlow por exemplo.
Outras opções
Por exemplo, utilizamos um cluster Slurm:
from hostlist import expand_hostlist
task_index = int( os.environ['SLURM_PROCID'] )
n_tasks = int( os.environ['SLURM_NPROCS'] )
tf_hostlist = [ ("%s:22222" % host) for host in
expand_hostlist( os.environ['SLURM_NODELIST']) ]
# implementações diversas
cluster = tf.train.ClusterSpec( {"your_taskname" : tf_hostlist } )
server = tf.train.Server( cluster.as_cluster_def(),
job_name = "your_taskname",
task_index = task_index )
# Podemos começar a criar nós apra processamento dessa forma
for idx in range(n_tasks):
with tf.device("/job:your_taskname/task:%d" % idx ):Saída e Predição
Serviços
Transformação de um modelo pré treinado em um serviço, pra provisionamento via requisições
Swarm
Criamos vários workers para a predição do resultado e uma vez que a predição seja realizado finalizá-los.
Links
GEML: Execução em clusters e GPUs
By Robson Cruz




