Making Distributed systems sane again
Welcome
Setting up a context

Signoi
In other words
Machine learning
To be more precise...

Evolution of Infrastructure



CLIENT

ELB/ALB
COMPUTE
STORAGE
PAST....
NOW
NOW....


Traffic through Internet gateway

Into application load balancer with SSL termination

Into bastion host within public subnet

Into kubernetes worker nodes in private subnets

Public and private subnets wrapped within availability zone.

Distributed across 3 availability zones for redundancy

Wrapped around by autoscaling group

Drived by Terraform and Kubectl via Travis CI

Let's wrap it by stages
Let's wrap it by stages
And so on ....
DEV
QA
PROD
Let's wrap it by region
And so on ....

US
EUROPE
- HA Mongo Cluster
And deploy
- HA Rabbitmq cluster
- HA Redis cluster
- Percona cluster
- ETCD
- Kubernetes master controller
- Pilosa cluster (Bitmap indexing)
- Fluentd cluster / Log aggregator daemon
- HA Reverse proxy / Gateway
- Exporter agent (Metrics/Logs/Traces)
- Ingress Controller
- External-dns
And services...

- User service
- Subscription service
- Uploader service
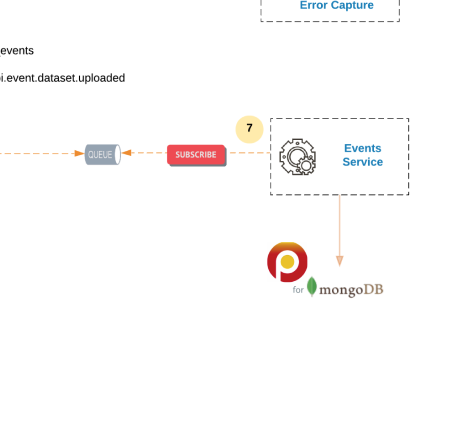
- Events service
- Notify service
......
Services
- Accounts service
- Interpretation processor
- Dataset service
- Tokenzier, Lemmatizer service
- Web hook service
How do we design systems that is
- Deterministic
- Fault tolerant
- Highly available
- Resilient
- Observable
5 Quest for Distributed Systems at scale
Thrive for stateless
1
A service with no side effects.
A service which does not rely on cache to serve request.
A service which does not rely on another service to serve request.
Service A requires that service B to exists and function.
Example:
- Your service talks to database.
- Your service does cache invalidation.
- Your service deployment requires defined sequence of structure.
Litmus test
Key Idea
Delicate intents by events.
Your service intent is to make database call for persistence, emit an event.
Your service intent is to make email, emit an event.


Immutable infrastructure
2
Provision resource creation as well as deletion.
Allow your infrastructure to be function of time.
Allow your infrastructure to be reproducable.
Litmus test
Service/resource deployment requires DEVops.
Service deployment requires reaching to aws console/cli.
Dependency management is a manual process. Eg: You cannot delete vpc because ec2 is attached to it.
Key Idea
Resource creation and teardown should be your religion.
- Tools like terraform enforces immutability and provides dependency management
Benefits
You know how to fail and come back up and not the other way around.
You remove human's error prone brain function during dependency management.
It is the best documentation of your infrastructure that you will ever have.
Reverts are super easy. Time travel.
In Signoi
We spin up entirely new set of infrastructure in 10 minutes.
Kubernetes
Cloudfront
Ec2 worker nodes
ECR
Security groups, NACL,
ALB
VPC,
3 AZs,
Private and public subnets,
Bastion hosts,
and 35 Load Balancers and 60+ services.
HA mongo cluster
HA redis cluster
HA Pilosa cluster
Exporters
Agents
Fluentd
.....
In Signoi
We spin up dev cluster during weekdays and destroy during weekends.
Observable at glance
3
A service with entry and exit path.
A distributed system with shortest time to root cause analysis.
A distributed systems with trace continuity across process boundaries.
Litmus test
Service does have context of outbound and inbound request.
Service does not propagate context across process boundaries.
Your trace is limited to function call stack within the process.
How to achieve observability?
Instrument and profile every execution path
- Request Response lifecycle
- Http request
- Event from rabbitmq
- Event to rabbitmq
- Database transaction
- ....
Use instrumented http client with custom transport layer.
Use monitor api for database to trace transactions.
Use transport headers for messaging systems to trace events.
Benefits

Favor operator abstraction in persistence
4
Database deployment with automatic backup and recovery.
Unified API to manage all the above irrespective of your database stack.
Automatic promotion and demotion of master/slave db cluster.
Litmus test
You have to hire DBAs.
Your backups and restores are manual.
You require manual work during master/slave replication failure.
Your data storage classes are not well defined. For eg: /data, /journal, /logs
How to achieve?
- Wrap your persistence layer with operators. Eg: Percona.
- Provision backup/recovery and co-ordinator agent along side your database of choice.
- Prefer sentinel client over default database client.
- Provision sentinel cluster for automatic master/slave promotion.
- Wrap the underlying details with configuration. Eg: Kubernetes operator, Custom Resource defintions
Understand hidden cost of Open Source
5
Litmus test
README says "Blazingly fast reverse proxy"
README says "Compiles in < 1 sec"
Official website says "Community Edition"
How to achieve?
- Validate if piece of software follows industry standards for instrumentation and profilings.Eg: Open telemetry, Open census, Open tracing.
- Validate if it comes with sentinel and replication controller built in (DBS)
- Validate if they provide operators for backups and recovery.
- Validate if they have quick release cycles.
In Signoi
- $50,000 per year for mongo operator.
- $25,000 for opencensus exporter for load balancer.
- Incomplete set of terraform modules for kubernetes provisioning of External DNS, Ingress Controller, Storage Class ...
Lastly,
- Design for request propagation and cancelation across process boundaries.
- Abstract storage provisioning with operators and sentinel clusters.
- Allow systems to fail as soon as possible.
- Profile everything to better understand the nature of your systems.
- Use circuit breaker for dependent services.
Thank you
Making distributed systems sane again (l1)
By robus




