Comment construire un cache d'API sans se prendre la tête grâce aux surrogate keys ?
Romain Commandé

Disclaimer
- On n'a rien inventé !
- Présentation sans prétention
- Partage d'astuce
- Documenté sur le blog de Fastly
Architecture
Content
API
API
API
API
FRONT API
FRONT APP
Text
Du cache ?
SERVEUR WEB
Résultat
Internet
URL
CACHE
Du cache sur une API ?
Pas aussi simple !
On expose de la donnée qui doit rester cohérente
Exemple

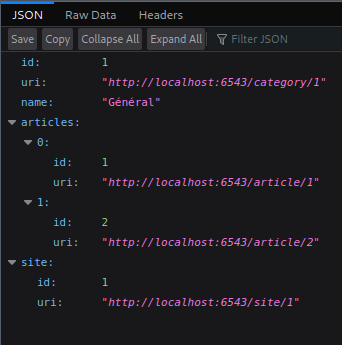
Exemple
Comment invalider correctement le cache ?
À la main
for item in models:
for subitem in item.subitems:
for subsubitem in subitem.subitems:
invalid_cache(subsubitem)
for subsubitem in subitem.other_subitems:
invalid_cache(subsubitem)
invalid_cache(subitem)
invalid_cache(item)😭
Se brancher sur les hooks et suivre les relations de l'ORM
🤔
?
Merci les surrogate keys !

Surrogate key
- Clé artificielle
- Contient l'ensemble des ressources chargées par une URI
- Ajoutée dans les headers de la réponse de l'API
"Site-1 Category-1 Category-2 Category-3"
Hook SQLAlchemy
Un middleware
def surrogate_keys_tween(request):
request.surrogate_keys = set()
response = handler(request)
response.headers["Surrogate-Key"] = " ".join(request.surrogate_keys)
return responsefrom pyramid.threadlocal import get_current_request
from sqlalchemy import event
@event.listens_for(SomeSessionOrFactory, 'loaded_as_persistent')
def loaded_as_persistent(session, instance):
key = f"{instance.__class__.__name__}-{instance.id}"
get_current_request().surrogate_keys.add(key)Les besoins côté code
Côté cache
- Fonctionnement classique
- Partitionner le cache en 2 parties
- Stocker également les associations surrogate key <=> uri
Alimentation
| Key | Value |
|---|---|
| /site | [{id: 1, ...}, {id: 2, ...}, ...] |
| Key | Value |
|---|---|
| Site-1 | ["/site"] |
| Site-2 | ["/site"] |
Surrogate-Key: Site-1 Site-2/site
Alimentation
| Key | Value |
|---|---|
| /site | [{id: 1, ...}, {id: 2, ...}, ...] |
| /site/1 | {id: 1, ...} |
| Site-1 | ["/site", "/site/1"] |
| Site-2 | ["/site"] |
| Category-1 | ["/site/1"] |
| Category-2 | ["/site/1"] |
| Category-3 | ["/site/1"] |
Surrogate-Key: Site-1 Category-1 Category-2 Category-3/site/1
Invalidation
| Key | Value |
|---|---|
| /site/ | [{id: 1, ...}, {id: 2, ...}, ...] |
| /site/1 | {id: 1, ...} |
| Site-1 | ["/site", "/site/1"] |
| Site-2 | ["/site"] |
| Category-1 | ["/site/1"] |
| Category-2 | ["/site/1"] |
| Category-3 | ["/site/1"] |
surrogate key : Site-1
import itertools
from monprojet.cache import redis_client, redis_paginator, scan_iter, sscan_iter
def store_response(path, surrogate_keys, response):
pipe = redis_client.pipeline()
for surrogate_key in surrogate_keys:
pipe.sadd(f"associations:{surrogate_key}", path)
pipe.set(f"responses:{path}", pickle.dumps(response))
pipe.execute()
def invalid(surrogate_keys_str):
surrogate_keys = surrogate_keys_str.split(" ")
pipe = redis_client.pipeline()
association_keys = [
association_key.decode("utf-8")
for surrogate_key in surrogate_keys
for association_key in scan_iter(0, match=f"associations:{surrogate_key}")
]
response_keys = (
"responses:{}".format(key.decode("utf-8"))
for asso in association_keys
for key in sscan_iter(asso, 0)
)
for key in set(itertools.chain(association_keys, response_keys)):
pipe.delete(key)
pipe.execute()Comment détecte-t-on les modifications de modèle ?
SQLAlchemy !
from sqlalalchemy import event
@db.event.listens_for(SomeSessionOrFactory, "after_begin")
def handle_after_begin(session, transaction, connection):
session.surrogate_keys = set()
@db.event.listens_for(SomeSessionOrFactory, "before_flush")
def handle_before_flush(session, flush_context, instances):
session.surrogate_keys |= get_surrogate_keys_for_modified_objects(session)
@db.event.listens_for(SomeSessionOrFactory, "before_commit")
def handle_before_commit(session):
session.surrogate_keys |= get_surrogate_keys_for_modified_objects(session)
@db.event.listens_for(SomeSessionOrFactory, "after_commit")
def handle_after_commit(session):
invalid(" ".join(sorted(session.surrogate_keys)))
def get_surrogate_keys_for_modified_objects(session):
return (
set(f"{instance.__class__.__name__}-{instance.id}" for instance in session.new)
| set(f"{instance.__class__.__name__}-{instance.id}" for instance in session.dirty)
| set(f"{instance.__class__.__name__}-{instance.id}" for instance in session.deleted)
)Ça fonctionne ...
- C'était simple à mettre en place malgré la complexité du problème
- Le cache semble s'invalider correctement
- Fonctionne sur un graph de données simple ou complexe
- On peut se passer de politique d'expiration des clés
... dans certaines limites
- Si on fait une modification directement en base
- Utiliser l'API
- python-mysql-replication
- surrogate key == 1024 bytes max
- J'ai identifié un cas qui ne fonctionne pas en préparant cette présentation :
- Pas d'invalidation des collections lors de la création d'un nouvel élément
- N'existait pas dans la front-api chez Ooreka
- Solvable (sûrement) facilement (car pas testé)

@rcommande
Comment construire un cache d'API sans se prendre la tête grâce aux surrogate keys ?
By Romain Commandé
Comment construire un cache d'API sans se prendre la tête grâce aux surrogate keys ?
Une solution peu coûteuse pour améliorer les performances de son application web est d’utiliser une système de cache. Mais lorsque l’on veut mettre en place du cache sur une API, on est rapidement confronté à une problématique de taille : la cohérence des données. Dans cette présentation, nous essayerons de montrer que l’on peut résoudre ce soucis simplement grâce à l’usage des “surrogate keys” et à quelques bons outils Python.




