Retour d'expérience : Chaînes de production de données
Romain Commandé 2018-04-05
"Code (application ou portion) dont l'objectif est de récupérer de la donnée en entrée (source / input) afin de produire de la nouvelle donnée en sortir (cible) d'après un plan et des règles de transformation définis à l'avance"
Moi
Python

Un outil de choix
- Très bien outillé pour la production de données
- Réflexion entièrement basé sur ce que propose Python nativement
- On oublie les libs externes (NumPy, Pandas, etc...)
Approche naïve
- On se rend pas toujours compte que l´on est dans un process de production de données
- On écrit du code sans trop se poser de question
- Code pas très lisible
- Complexité inutile
- Pas maintenable
- Don't panic -> Étape obligatoire
Exemple
Du code ! On veut du code !

Le découpage
- découper son algo en fonction
- Factorisation des traitements
- Rentre son code compréhensible au premier coup d’œil
- Jusqu'où faut-il aller ?

Modèle : les chaînes de production

Chaîne de production
- Ce qui se fait de mieux pour produire
- Petites unités de production chaînées entre elles
- Responsabilité réduite
- Pas de conscience du reste du process
Les générateurs

Les générateurs
- Objet itératable basé sur une fonction
- L’exécution peut être interrompu
- Renvoyer un résultat intermédiaire
-
yield remplace return
-
On va à la prochaine itération en appelant next() (méthode en Python 2, fonction built-in en Python 3)
Différences
- Chaines de production inversées (PULL)
- Streaming : Gérer de gros volumes de données les doigts dans le nez

Exemple
Du code ! Encore du code !
Les coroutines

Les coroutines
- Connu des Devs Python, rarement utilisées
- Basées sur les générateurs
- Envoi de données (PUSH / PULL)
- Demande un peu de boilerplate (initialisation)
- Souvent implémentées sous forme de boucles infinies
Exemple
Du code ! On veut du code je te dis !
Une problématique commune

Production de données Mappy
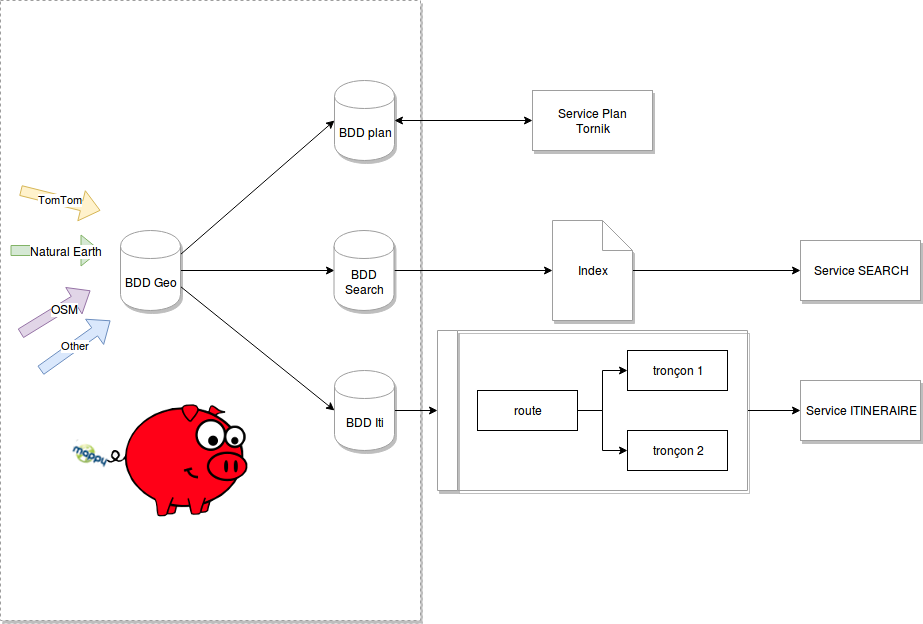
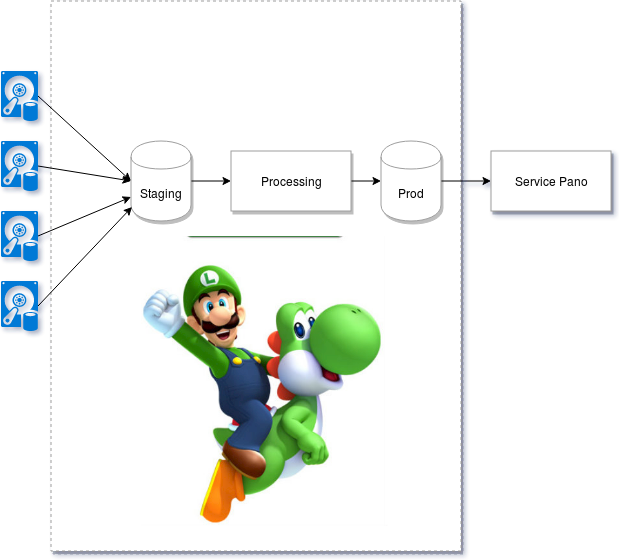
Production de données Vues immersives OUTDOOR
Production de données Ooreka ?
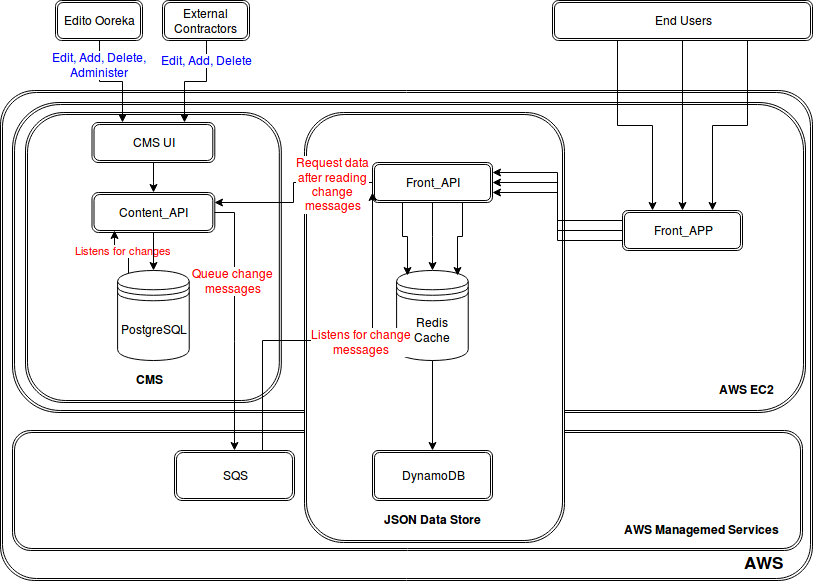
Mise à jour / synchronisation de données

On code !
Spoiler : badaboum !

On code !
- La gestion est extrêmement complexe
- Le code que vous avez écrit est ignoble -> premier jet
- Le debug est ingérable
- Vous dormez mal la nuit
- On retravaille le code et l'archi
- Le nouveau code n'est pas terrible

On fait comment, alors ?
- On le fait pas !
- En vrai, on va le faire quand même ;-)
- On ne va vraiment pas le faire, c'est ce qu'il faut retenir
- On va se faire aider
- Disons plutôt, qu'on va aider quelqu'un d'autre à le faire
L'inspiration : Make

Make
- Commande Unix
- Compiler une application
- Source -> binaire
- Choisi le chemin le plus rapide
- Ne recompile que ce qui a changé
- Rien de magique : ce base sur les dates de modification de fichiers
Se faire aider par un plombier

Le "make" de la donnée
- Application / framework en Python
- Développé et libérer par Spotify
- Utilisé en interne
- Alimentation de clusters Hadoop (stats d'écoute)
- Gestion de workflow complexe
- Outil graphique
- Parallelisme
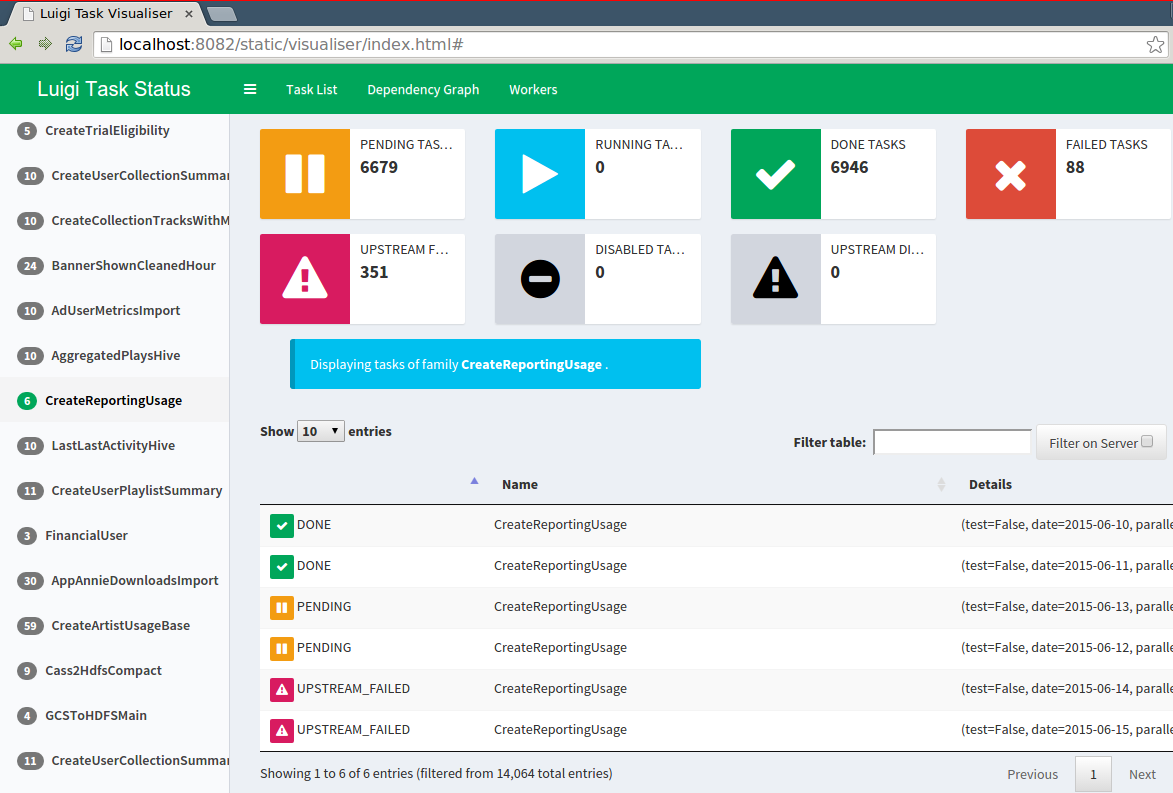
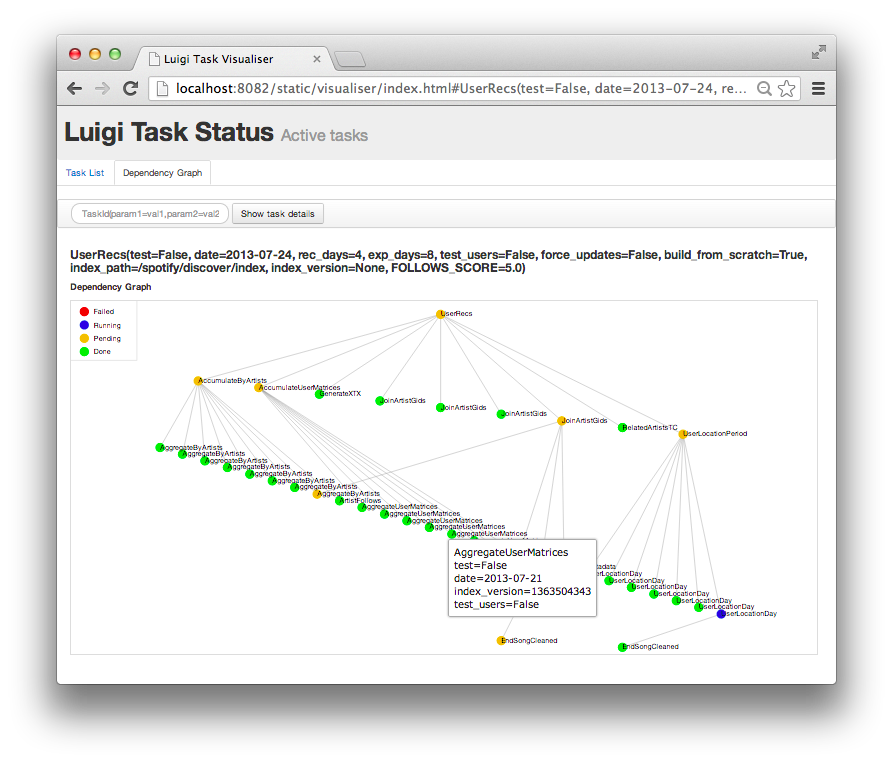
Luigi : Task
- Unité de calcul
- Simple classe Python
- Hérite de luigi.Task
- Définit des paramètres
- Chaîné avec d'autres tasks
- Chaînage static ou dynamic
- Écrit les données (output) dans une Target
Luigi : Target
- Simple classe Python
- Doit avoir une méthode exists()
- Doit garantir l'atomicité des données
Luigi : invalidation / update
- Luigi boucle sur toute les tasks
- Appel la méthode exists() de toutes les targets
- Relance toutes les tâches non traitées
- Ne pas supprimer les données intermédiaires
- Targets menteuses
- Ne gère pas les changement de code
Exemple
Du code ! On aiiiiiiiiiiiime le code !
Conseils

Retravailler sa chaîne de production en permanence
La granularité est importante
La production de données, c'est du code !
1 bug == 1 test
Ne jamais supprimer de la donnée
Tester le code ET la donnée
Performance VS scalabilité ? SIMPLITÉ !
Des questions ?

Applaudissements !

Chaîne de production de données
By Romain Commandé




