IBM BigData
@RomeoKienzler
Preface
Most of the Technologies mentioned in this presentation are available in the IBM Cloud Free Tier at no cost, please have a look http://ibm.biz/joinIBMCloud
State of the Art
- SQL (42%)
- R (33%)
- Python (26%)
- Excel (25%)
- Java, Ruby, C++ (17%)
- SPSS, SAS (9%)
Limits
- Main Memory
- CPU <> Main Memory Bandwidth
- CPU
- Storage <> Main Memory Bandwidth (either Single node or SAN)
Hadoop

Hadoop

Why is Hadoop so fast?
Time to read 1 TB from Disk
- 1 disk - 3.4h
- 10 disks - 20m
- 100 disks - 2m
- 1000 disks - 12s
Time to read 1 TB from Main Memory
- 1 node - 100s
- 10 nodes - 10s
- 100 nodes - 1s
- 1000 nodes - 100ms
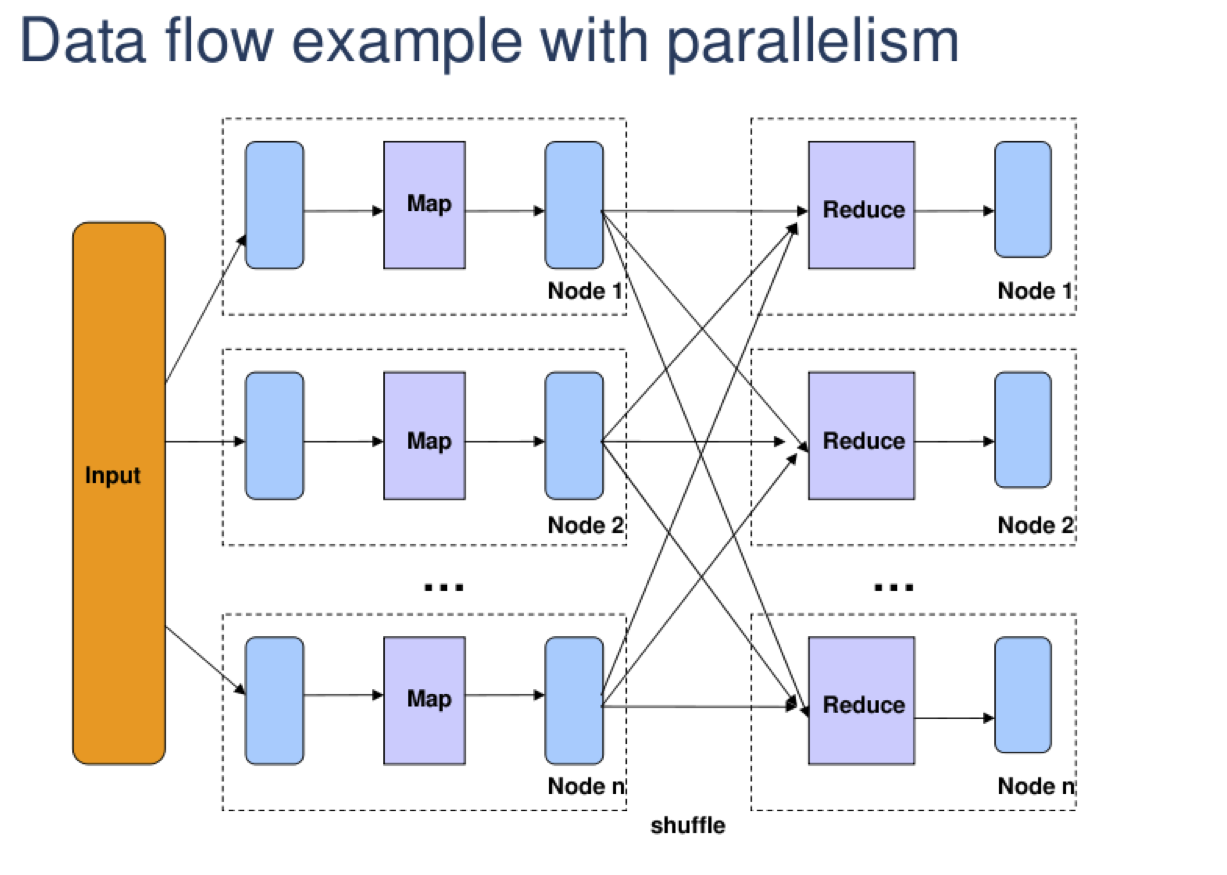
Data Parallelism
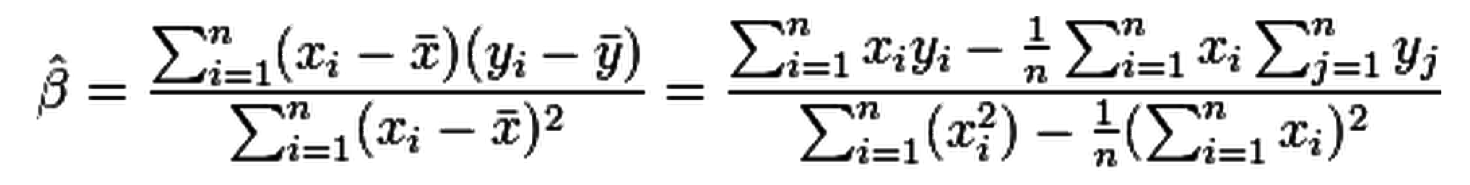

Why use so much data?
The Unreasonable Effectiveness of Data¹: "sometimes it's not who has the best algorithm that wins; it's who has the most data."
¹http://www.csee.wvu.edu/~gidoretto/courses/2011-fall-cp/reading/TheUnreasonable%20EffectivenessofData_IEEE_IS2009.pdf
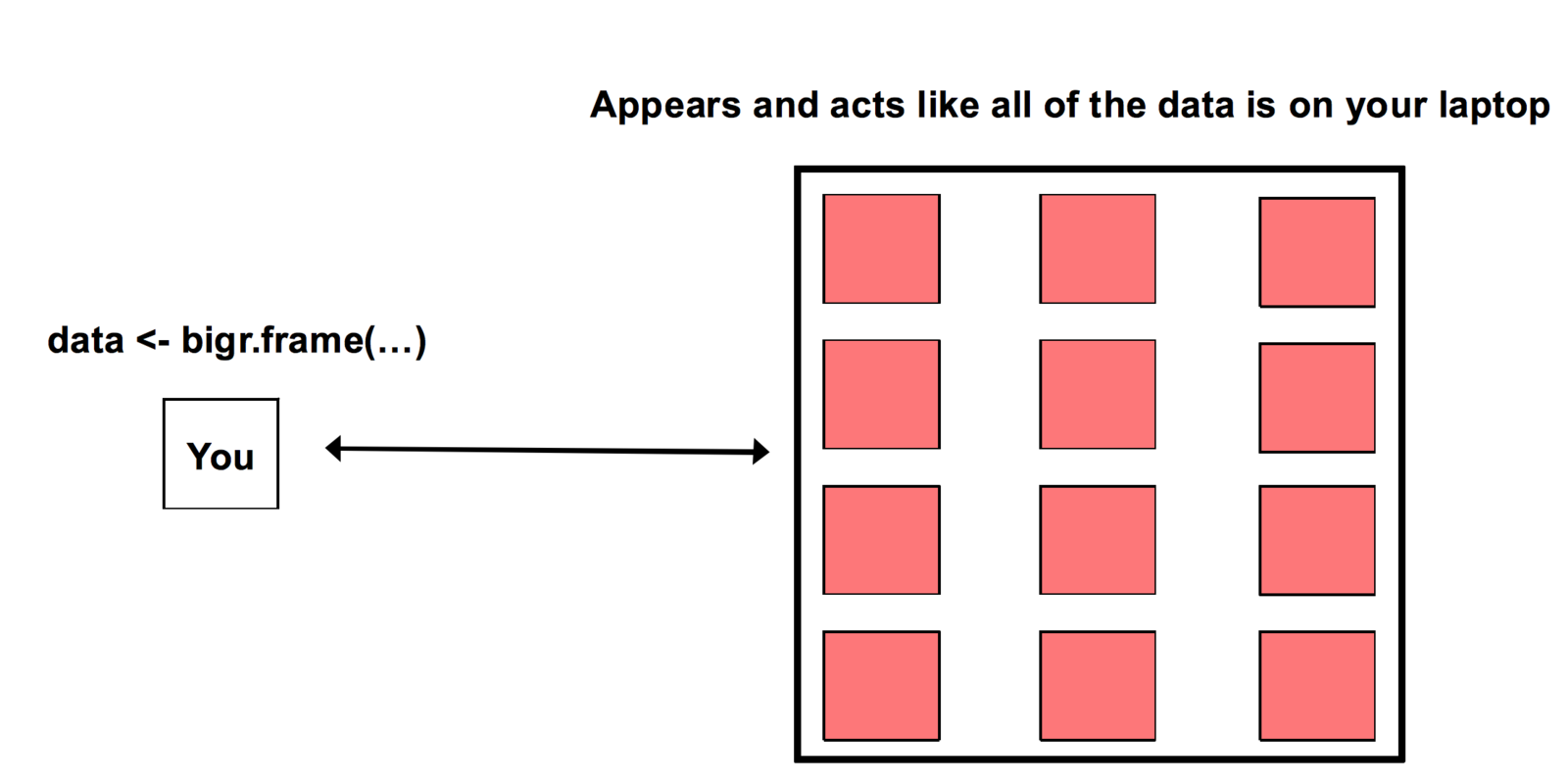
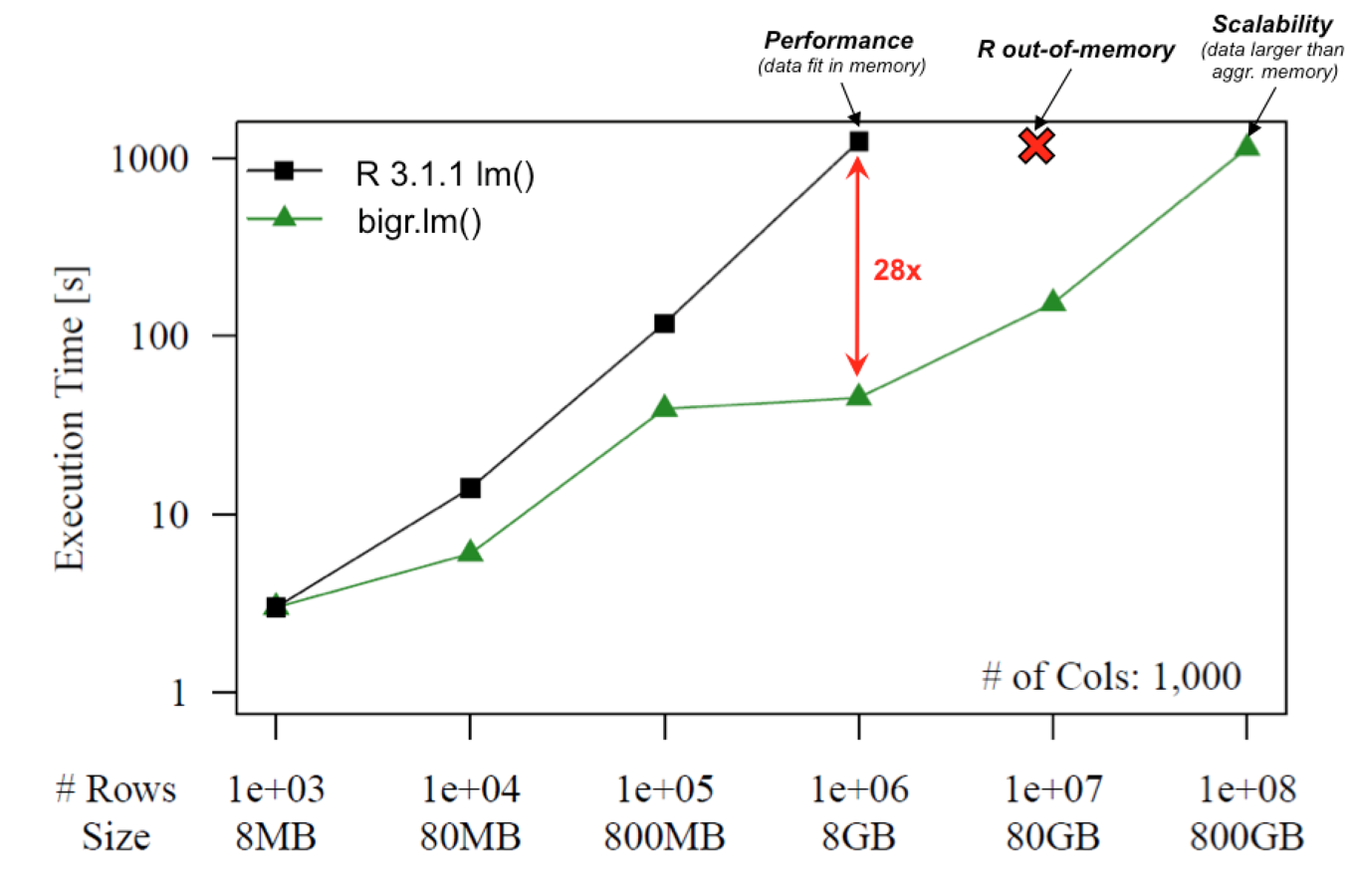
How to store so much data?
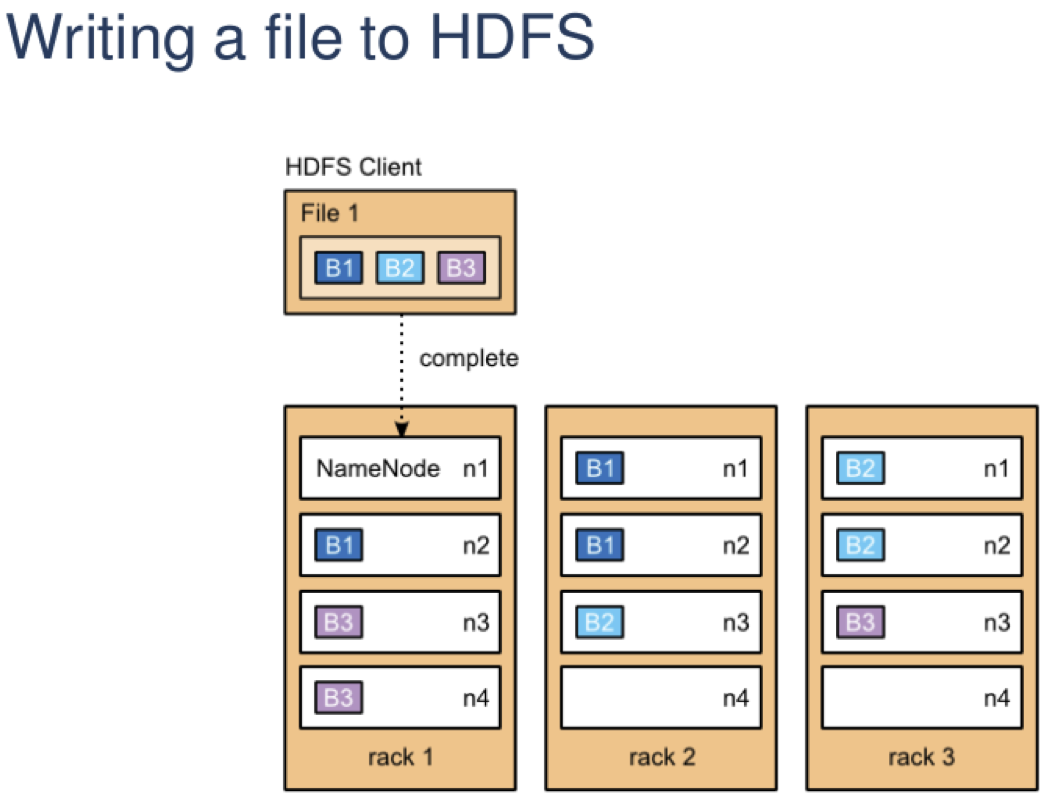
"Imagine a Filesystem with unlimited capacity, scalability and fault tolerance"
BigR
BigR
Spark

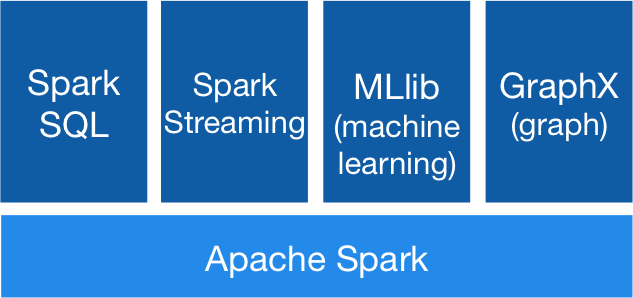
Spark
Life Science
Hadoop - Genomics
Crossbow
- 1st tool on Hadoop
- based on Bowtie + soapSNP
ADAM
- genomics analysis platform
- runs on top of Spark
Hadoop - BAM
- on top of the Picard SAM JDK
Hadoop - Genomics
...some more examples...
- Contrail
- PeakRanger
- Quake
- BlastReduce
- CloudBLAST
- MrsRF
Downstream Analytics
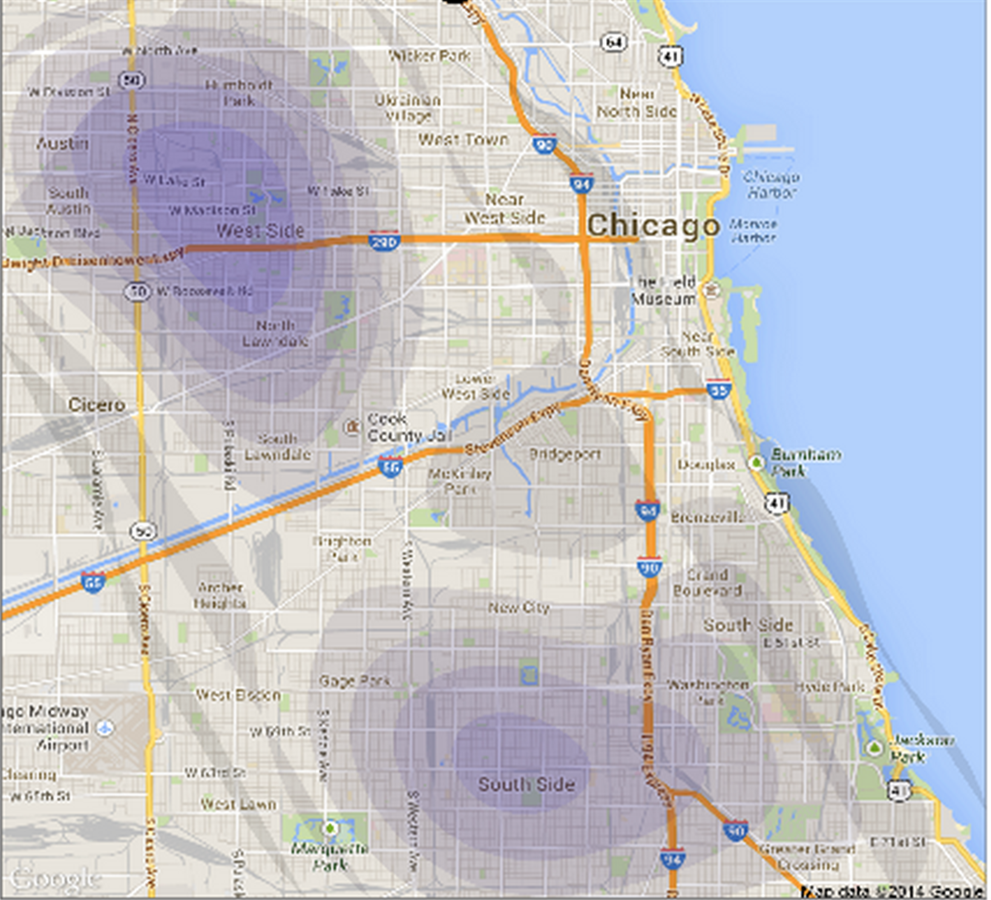
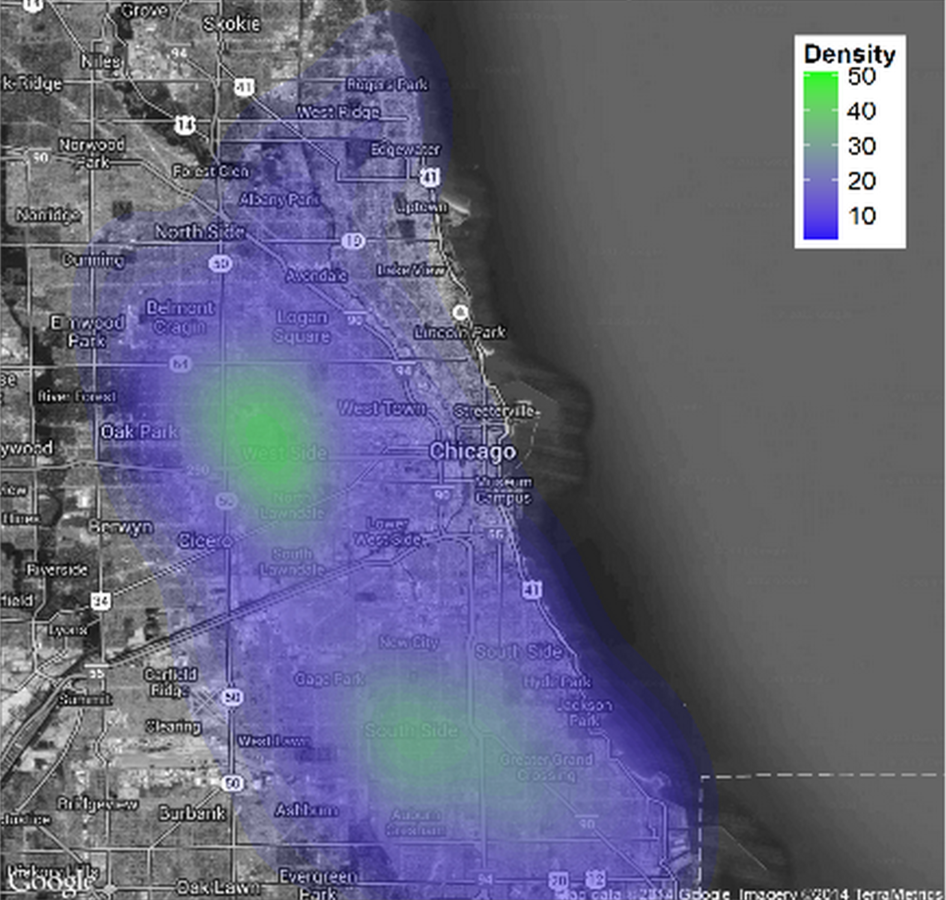
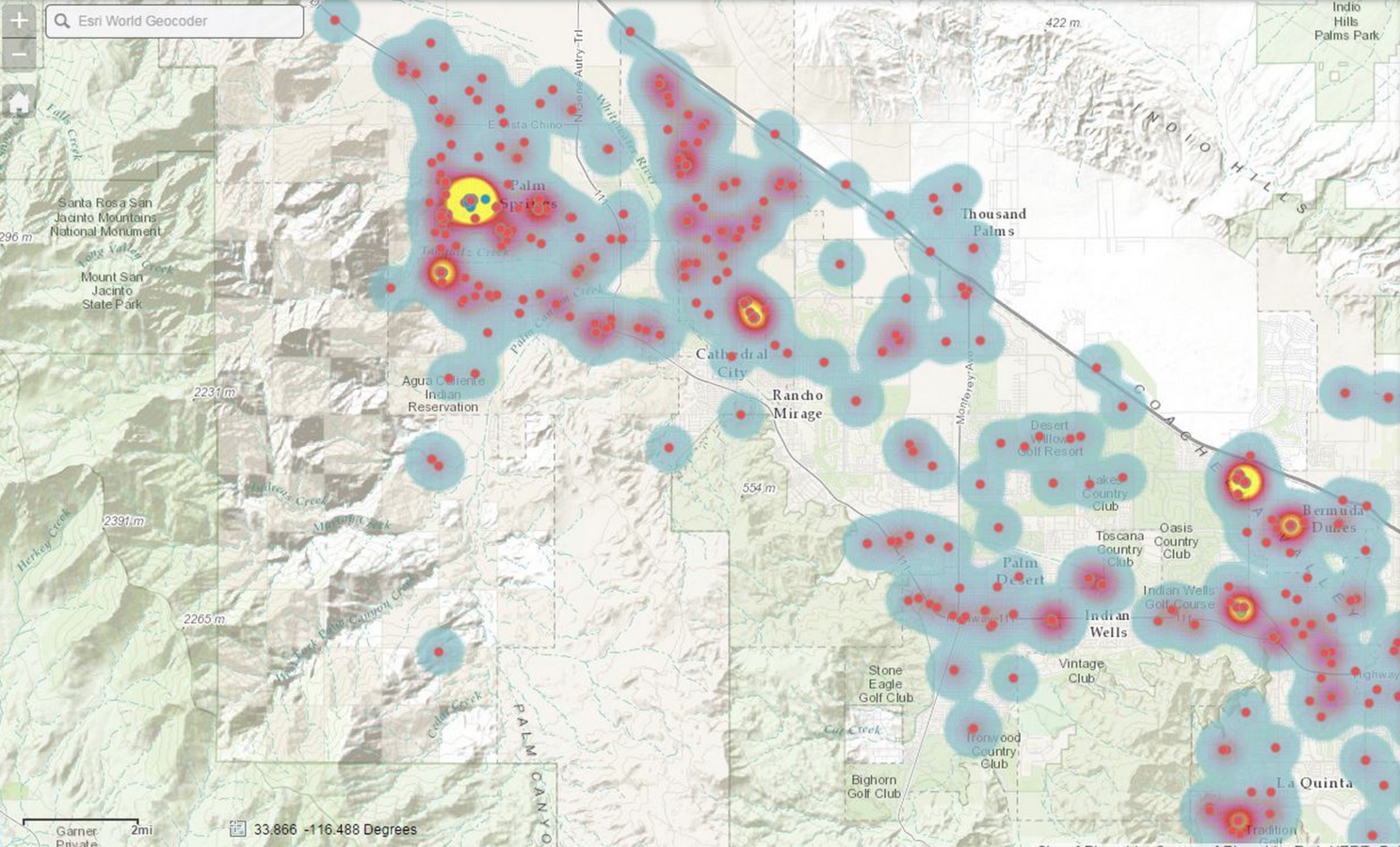
...downstream analytics...
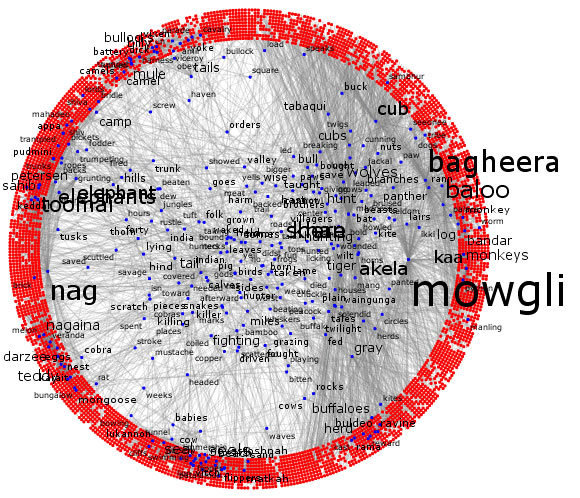
Downstream Analytics
Image/Video Processing

On Hadoop
Fiji/ImageJ
- 3D Image Processing library
- runs also on Hadoop / Spark
OpenCV
- Video Processing library
- runs also on Hadoop / Spark or IBM InfoSphere Streams
IBM BigData
By Romeo Kienzler
IBM BigData
A short overview on IBM BigData




