Intro to MongoDB

By Ronak Raithatha
Gun to the head by Alex.
What we'll cover:
- Introduction
- CRUD
- Aggregation Framework
- Replication
- Sharding (note: look for 12 yr olds)
Introduction
MongoDB :
- is a no-SQL database
- uses JSON documents which are represented in the DB as BSON.
- can be scaled horizontally through sharding
Most Importantly:

MongoDB is Web Scale
JSON
- JavaScript Object Notation
- Not always related
- Easier to read
- Lightweight compared to XML
- Stored as BSON internally
- Binary JSON
- bsonspec.org
RDBMS -> MongoDB
| Table | Collection |
| Row | Document |
| Column | Field |
| Joins | Embedded documents/Linking |
| Database | Database |
CRUD
Creating a document
INSERT INTO seeker (fn, ln)
VALUES ('John', 'Doe')db.seeker.insertOne({
fn: 'John',
ln: 'Doe'
}){
"_id":ObjectId("5a5d957671775ae0f046e3e6"),
"fn":"John",
"ln":"Doe"
}Result:
To insert multiple documents, use:
.insertMany(<document>,<document>,...)SQL:
MongoDB:
CRUD
_id
- Primary key for all collections
- Is of type ObjectID (a BSON type)
- Allows for auto-indexing
- Has auto_increment if needed
- Can be set explicitly :
db.seeker.insert({_id:'Stephane',country:'US'})ObjectID
12 byte long:
- 4-byte: seconds since Unix epoch
- 3-byte:
machine identifier - 2-byte: process id
- 3-byte: counter, starting with a random value
CRUD
Updating a document
SQL:
UPDATE SEEKER SET ln='Smith' WHERE ln='Doe'MongoDB:
db.seeker.update(
{ln: 'Doe'},
{$set:
{ln: 'Smith'}
}
)Replace a full document with:
.replaceOne(<filter>,<replacement>)db.seeker.update(
{ln: 'Doe'},
{$set:
{age: 23}
}
)Adding new field
Update multiple documents with:
.updateMany(<filter>,<update>)CRUD
Deleting a document
SQL:
DELETE FROM seeker WHERE fn='John'MongoDB:
db.seeker.deleteOne({fn:'John'})Or a collection
SQL:
DROP TABLE seekerMongoDB:
db.seeker.drop()To delete many, use:
.deleteMany(<filter>)CRUD
Reading a document
SQL:
SELECT *
FROM seekerMongoDB:
db.seeker.find()SELECT id,
fn,
ln
FROM seekerdb.people.find(
{ },
{ fn: 1, ln: 1 }
)SELECT fn, ln
FROM seeker
WHERE ln = "Doe"db.seeker.find(
{ ln: "Doe" },
{ fn: 1, ln: 1, _id: 0 }
)SELECT *
FROM seeker
WHERE age > 25
AND age <= 50db.seeker.find(
{ age: { $gt: 25, $lte: 50 } }
)CRUD
Reading a document
SQL:
SELECT *
FROM seeker
WHERE age < 30
ORDER BY age ASCMongoDB:
db.seeker.find( { age: { $lt: 30 } } )
.sort( { age: 1 } )SELECT *
FROM seeker
WHERE ln like "%Do%"db.people.find( { user_id: /bc/ } )SELECT COUNT(*)
FROM seekerdb.people.count()
or
db.people.find().count()SELECT *
FROM seeker
LIMIT 5
SKIP 10db.people.find().limit(5).skip(10)CRUD
Reading a document
There are a couple other combined methods to work on single reads:
- db.collection.findOneAndReplace()
- db.collection.findOneAndModify()
- db.collection.findAndModify()
Aggregation Framework
Provides a way to process and return data from multiple results and perform various operations on the return data.
i.e. GROUP BY, SORT, HAVING, etc.
Two most prominent ways to use the aggregation framework are:
- Aggregation Pipeline: works much like pipes (|) in the terminal where data is sent through one stage at a time.
- Map-Reduce: a Mongo operation but uses JS map-reduce in the background. Generally slower than the pipeline.
Aggregation Pipeline

Map-Reduce Operation

Aggregation Framework
SQL:
SELECT seeker_id,
SUM(applications) AS total
FROM seeker
GROUP BY seeker_id
ORDER BY totalMongoDB:
db.seeker.aggregate( [
{
$group: {
_id: "$seeker_id",
total: { $sum: "$applications" }
}
},
{ $sort: { total: 1 } }
] )SELECT seeker_id,
count(*)
FROM seeker
GROUP BY seeker_id
HAVING count(*) > 1db.seeker.aggregate( [
{
$group: {
_id: "$seeker_id",
count: { $sum: 1 }
}
},
{ $match: { count: { $gt: 1 } } }
] )Aggregation Framework
SQL:
MongoDB:
SELECT seeker_id,
app_date,
SUM(applications) AS total
FROM orders
GROUP BY seeker_id,
app_date
HAVING total > 3db.seeker.aggregate( [
{
$group: {
_id: {
cust_id: "$seeker_id",
app_date: {
month: { $month: "$app_date" },
day: { $dayOfMonth: "$app_date" },
year: { $year: "$app_date"}
}
},
total: { $sum: "$applications" }
}
},
{ $match: { total: { $gt: 3 } } }
] )Aggregation Framework
SQL:
MongoDB:
SELECT seeker_id,
app_date,
SUM(applications) AS total
FROM orders
GROUP BY seeker_id,
app_date
HAVING total > 3db.seeker.aggregate( [
{
$group: {
_id: {
cust_id: "$seeker_id",
app_date: {
month: { $month: "$app_date" },
day: { $dayOfMonth: "$app_date" },
year: { $year: "$app_date"}
}
},
total: { $sum: "$applications" }
}
},
{ $match: { total: { $gt: 3 } } }
] )Aggregation Framework
SQL:
MongoDB:
SELECT *, applications
FROM seeker
WHERE ethnicity_id IN (SELECT *
FROM ethnicity
WHERE id= seeker.ethnicity_id);db.seeker.aggregate([
{
$lookup:
{
from: "ethnicity",
localField: "ethnicity_id",
foreignField: "id",
as: "ethnicity_id"
}
}
])Replication
MongoDB provides built-in asynchronous replication by reading oplog to the master.
Maintains a heartbeat connection between the replica sets in case primary goes down.
If primary does go down, mongo determines the next primary either by priority set to each set, or hosting an election if the priority is the same.
Replication

Replication
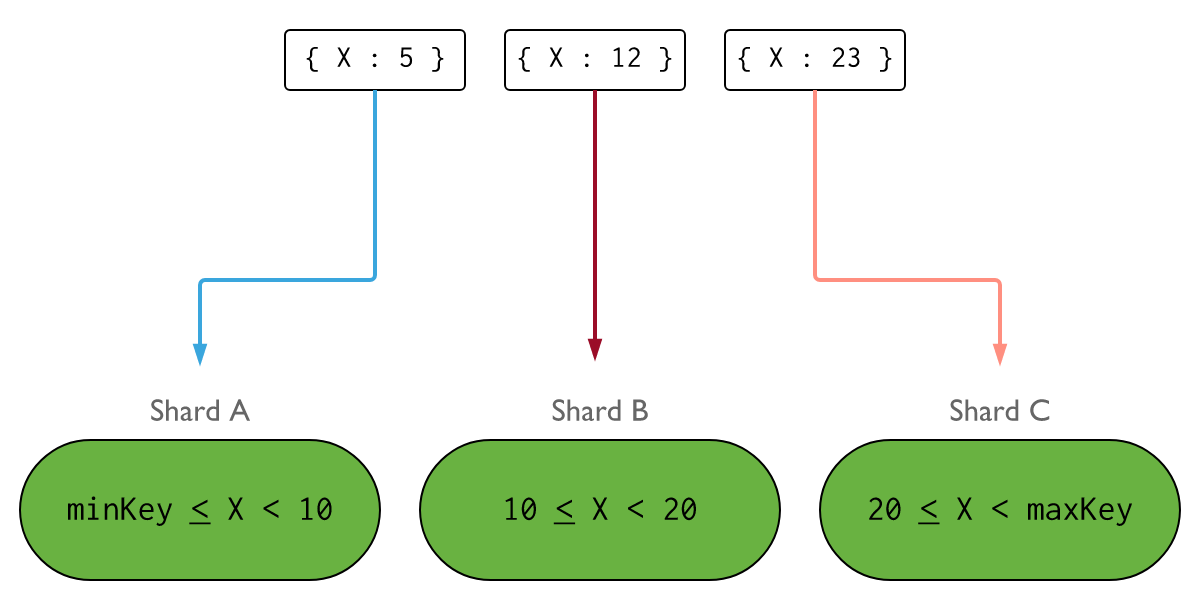
Sharding
Provides a way to horizontally scale data across multiple machines by adding a subset of the overall data to each machine.

Sharding
Shard Keys
The shard key consists of an immutable field of fields that exist in every document in a target collection
Going forward
With enough interest, we can spend a hack-day working on two datasets that are similar between SQL and Mongo.
Divide up into teams and try to replicate one team's SQL query to Mongo.
Questions...
Mongo DB
By Ronak Raithatha



