Deep Reinforcement Learning and Efficient exploration
Reinforcement Learning
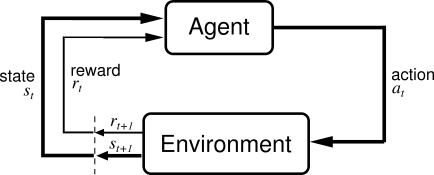
Agent POV
An agent follows policy
Policy: strategy to pick action from current state
The optimal policy maximizes the sum of future rewards
returns sum of rewards from state s wrt policy
\pi
\pi^*
V^\pi(s)
\pi
computable if given
\pi^*
V^{\pi^*}(s)
Neural Network

Deep Reinforcement Learning

Policy iteration
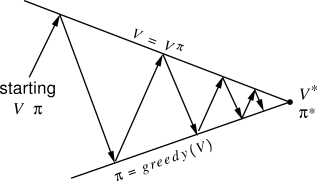
Update rule
SARSA
TD-LAMBDA
Q-LEARNING
Different exploration
EPSILON GREEDY
EFFICIENT EXPLORATION
Results
Conclusion
deck
By Ruben Fiszel


