
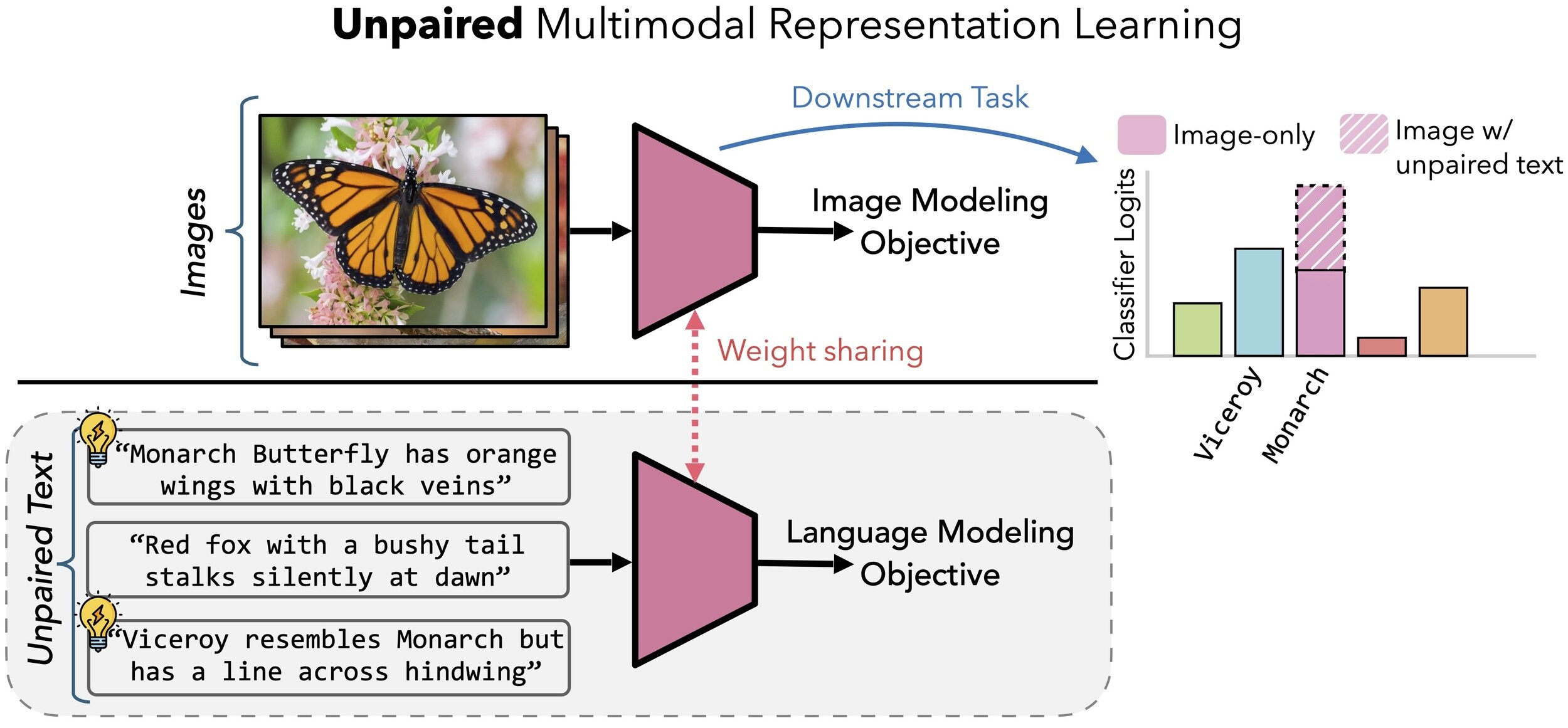
- Can another modality help without exact pairs?
Pairing Bottleneck
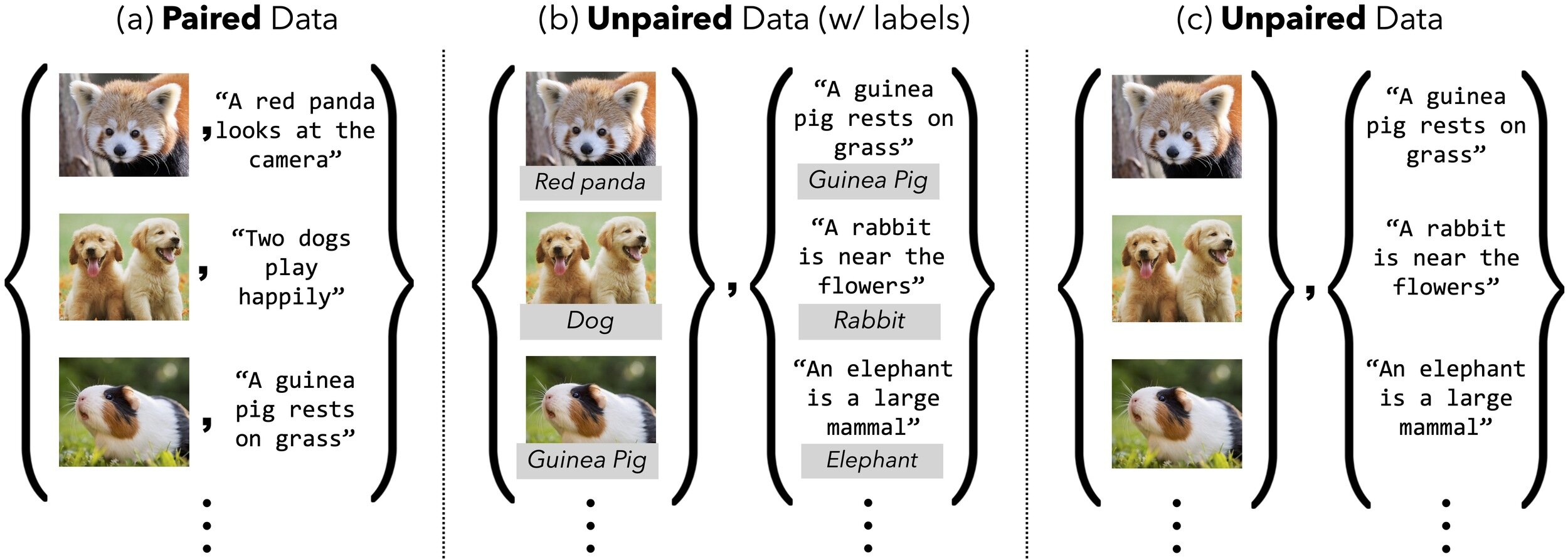
- Most multimodal methods assume matched pairs
- Real clinical data are often unmatched
- Question: can "extra but unpaired" data still help?
- Modality-specific encoders + one shared backbone
- No pair mining
- Keep the improved target-modality representation at inference

Unpaired Multimodal Learner (UML)
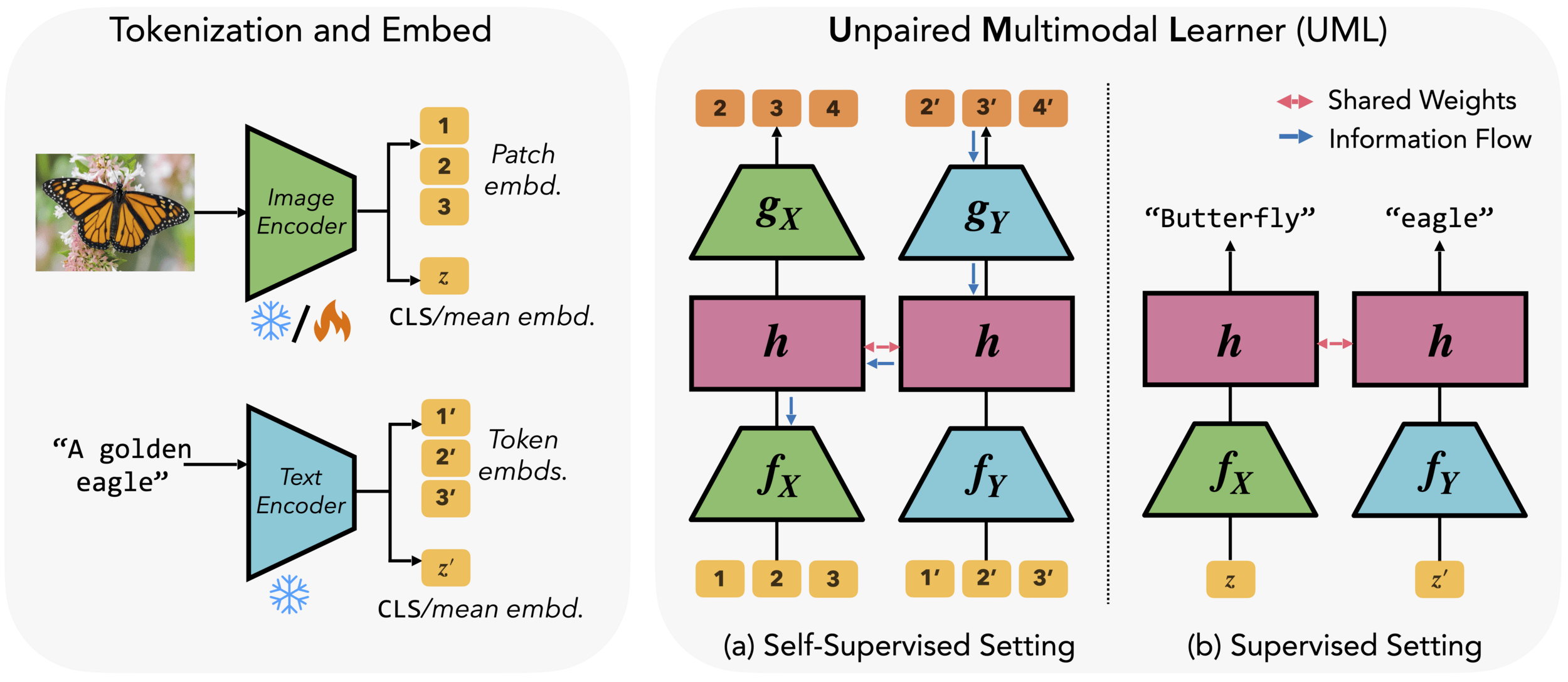
- Different modalities = different views of the same world
- Shared weights push toward concept-level features
- Related modalities transfer useful structure
- Modalities describing the similar structure, one can help the others
UML - Could this work?
Benchmarks
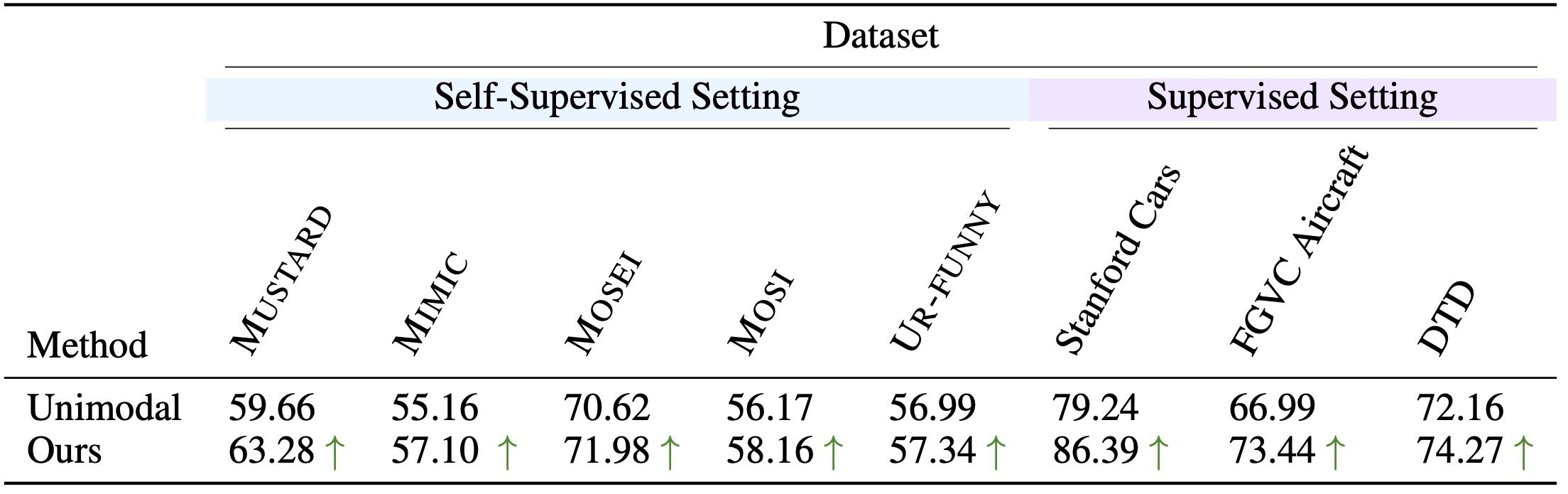
- Self-supervised setting: UML beats unimodal across reported tasks
Benchmarks
- Self-supervised setting: UML beats unimodal across reported tasks
?
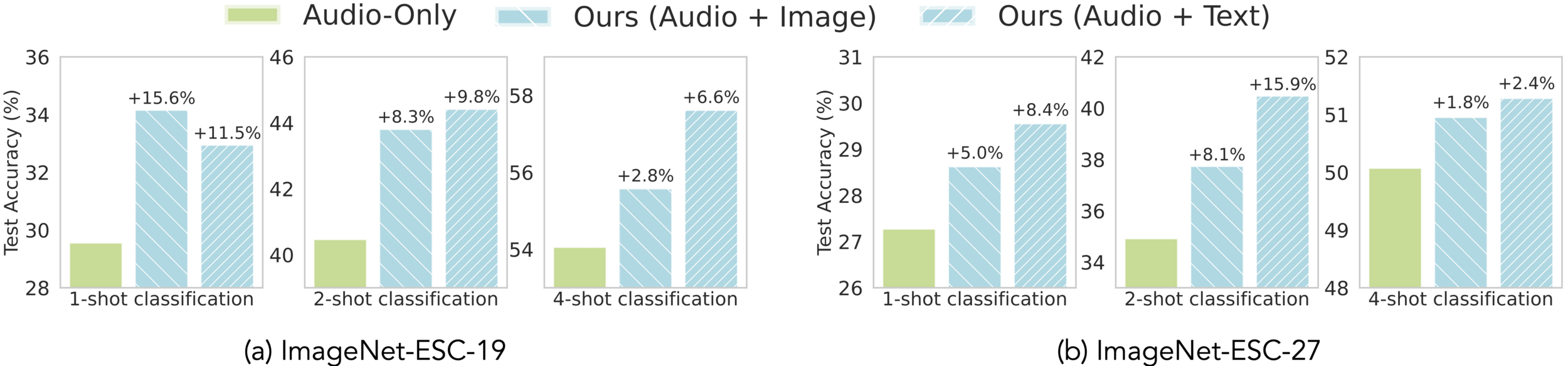
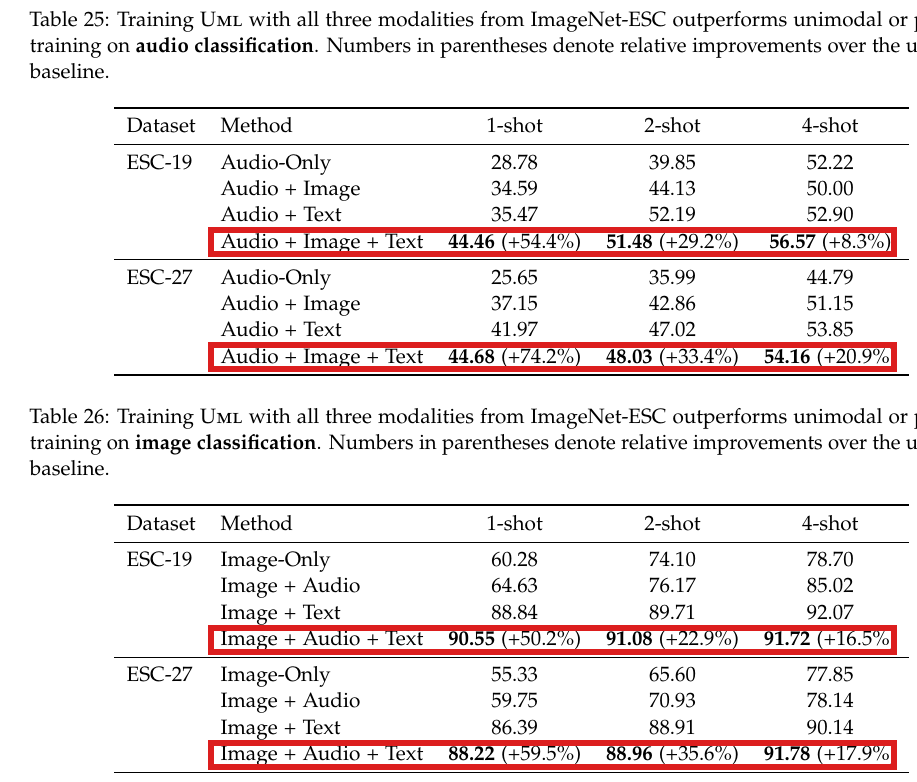
- Extends to audio + vision + text
- Image help audio
- Text help audio
- Best results with all three?
- Clinical analogy: waveform + EHR + notes, or retinal imaging + outcomes + text
Beyond Image + Text: Three Modalities
- Extends to audio + vision + text
- Image + text help audio
- Audio + text help image
- Best results with all three
- Clinical analogy: waveform + EHR + notes, or retinal imaging + outcomes + text
Beyond Image + Text: Three Modalities
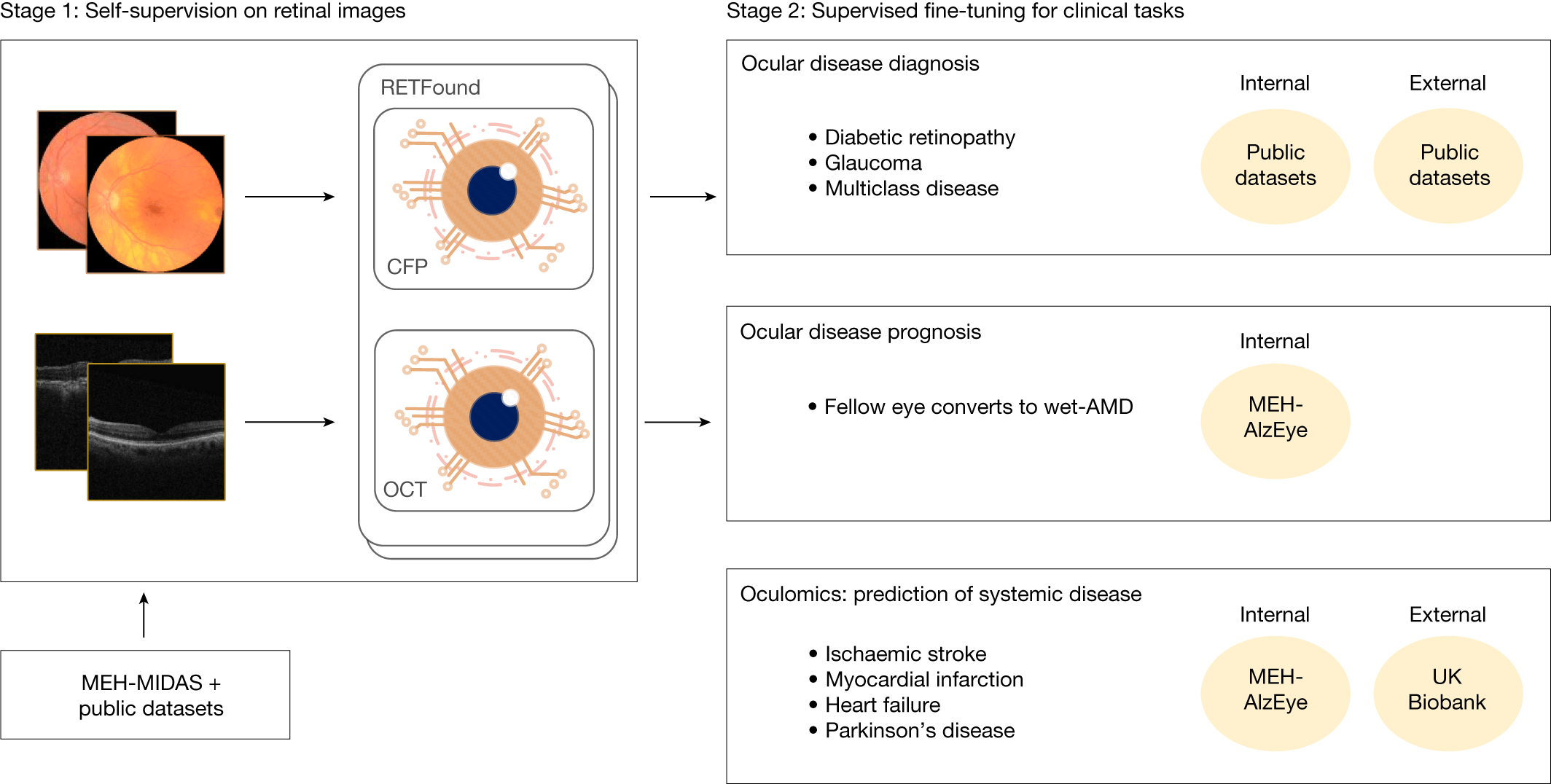
- Scale: ~900K fundus + ~700K OCT
- CFP and OCT carry complementary signal
- RETFound limitation: CFP-OCT fusion not investigated
Fundus + OCT After RETFound
Can we learn from fundus + OCT jointly, even with imperfect pairs?
Summary
- Perfect pairing is not required
- Shared weights are a strong simple baseline
- Key caveat: modalities must be semantically related
- Use retinal data to explore unpaired fundus-OCT learning
Can we learn from fundus + OCT jointly, even with imperfect pairs?
uml-presentation
By Safa Andac




