No relational Databases
Central question
What database or combination of databases best resolves your problem?
Can I use this database to store and refine this data?
Should I?
The question you must always ask yourself
- Relational (PostgreSQL)
- Key-Value (Voldemort, Riak, Redis)
- Columnar (HBase, Cassandra, Hypertable)
- Document (MongoDB, CouchDB)
- Graph (Neo4J)
Types
Key-Value
The key-value (KV) store is the simplest model we cover. KV store pairs keys to values in much the same way that a map
Minuses:
-
doesn't support complex query and aggregation
Pluses:
-
incredibly performant fault-tolerant
Riak

Doesn't have foreign key.
curl -v -X PUT http://localhost:8091/riak/favs/db \
-H "Content-Type: text/html" \
-d "<html><body><h1>My new favorite DB is RIAK</h1></body></html>"PUT something
If you navigate to http://localhost:8091/riak/favs/db in a browser, you’ll get a nice message from yourself.
http://SERVER:PORT/riak/BUCKET/KEY$ curl -v -X PUT http://localhost:8091/riak/animals/ace \
-H "Content-Type: application/json" \
-d '{"nickname" : "The Wonder Dog", "breed" : "German Shepherd"}'First released in 2009, Redis (REmote DIctionary Service) is a simple-to-use key-value store with a sophisticated set of commands. And when it comes to speed, Redis is hard to beat. Reads are fast, and writes are even faster,
Redis

Redis
$ redis-server$ redis-cli
redis 127.0.0.1:6379> PING
PONGredis 127.0.0.1:6379> SET 7wks http://www.sevenweeks.org/
OK
redis 127.0.0.1:6379> GET 7wks
"http://www.sevenweeks.org/"Columnar
Columnar, or column-oriented, databases are so named because the important aspect of their design is that data from a given column (in the two-dimensional table sense) is stored together. By contrast, a row-oriented database (like an RDBMS) keeps information about a row together.
In column- oriented databases, adding columns is quite inexpensive and is done on a row-by-row basis. Each row can have a different set of columns, or none at all, allowing tables to remain sparse without incurring a storage cost for null values. With respect to structure,
| Salary | ||||
|---|---|---|---|---|
| 001 | 10 | Smith | Joe | 40000 |
| 002 | 12 | Jones | Mary | 50000 |
| 003 | 11 | Johnson | Cathy | 44000 |
| 004 | 22 | Jones | Bob | 55000 |
Row-oriented
001:10,Smith,Joe,40000;
002:12,Jones,Mary,50000;
003:11,Johnson,Cathy,44000;
004:22,Jones,Bob,55000;Column-oriented
10:001,12:002,11:003,22:004;
Smith:001,Jones:002,Johnson:003,Jones:004;
Joe:001,Mary:002,Cathy:003,Bob:004;
40000:001,50000:002,44000:003,55000:004;HBase

Document-oriented
A document is like a hash, with a unique ID field and values that may be any of a variety of types, including more hashes.
Documents can contain nested structures, and so they exhibit a high degree of flexibility, allowing for variable domains.
MongoDB

$ mongo book> db.towns.insert({
name: "New York",
population: 22200000,
last_census: ISODate("2009-07-31"), famous_for: [ "statue of liberty", "food" ], mayor : {
name : "Michael Bloomberg",
party : "I" }
})> db.towns.find()
{
"_id" : ObjectId("4d0ad975bb30773266f39fe3"),
"name" : "New York",
"population": 22200000,
"last_census": "Fri Jul 31 2009 00:00:00 GMT-0700 (PDT)",
"famous_for" : [ "statue of liberty", "food" ],
"mayor" : { "name" : "Michael Bloomberg", "party" : "I" }
}db.towns.find({ "_id" : ObjectId("4d0ada1fbb30773266f39fe4") })
{
"_id" : ObjectId("4d0ada1fbb30773266f39fe4"),
"name" : "Punxsutawney",
"population" : 6200,
"last_census" : "Thu Jan 31 2008 00:00:00 GMT-0800 (PST)",
"famous_for" : [ "phil the groundhog" ],
"mayor" : { "name" : "Jim Wehrle" }
}
CouchDB
CouchDB targets a wide variety of deployment scenarios, from the datacenter to the desktop, on down to the smartphone. Written in Erlang, CouchDB has a distinct ruggedness largely lacking in other databases. With nearly incorruptible data files, CouchDB remains highly available even in the face of intermittent connectivity loss or hardware failure.

$ curl http://localhost:5984/music/74c7a8d2a8548c8b97da748f43000ac4 {
"_id":"74c7a8d2a8548c8b97da748f43000ac4",
"_rev":"4-93a101178ba65f61ed39e60d70c9fd97",
"name":"The Beatles",
"albums": [
{
"title":"Help!",
"year":1965
},{
"title":"Sgt. Pepper's Lonely Hearts Club Band",
"year":1967
},{
"title":"Abbey Road",
"year":1969
} ]
}
Graph
One of the less commonly used database styles, graph
Neo4J
One operation where other databases often fall flat is crawling through self-referential or otherwise intricately linked data. This is exactly where Neo4J shines. The benefit of using a graph database is the ability to quickly traverse nodes and relationships to find relevant data. Often found in social networking applications, graph databases are gaining traction for their flexibility, with Neo4j as a pinnacle implementation.

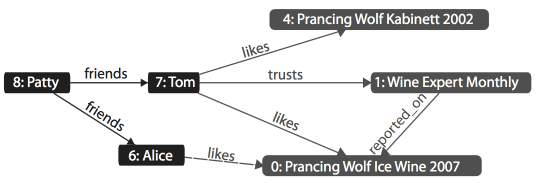
Alice has a bit of a sweet tooth and so is a big ice wine fan.
alice = g.addVertex([name:'Alice'])
ice_wine = g.V.filter{it.name=='Prancing Wolf Ice Wine 2007'}.next()
g.addEdge(alice, ice_wine, 'likes')Tom loves Kabinett and ice wine and trusts anything written by Wine Expert Monthly.
tom = g.addVertex([name:'Tom'])
kabinett = g.V.filter{it.name=='Prancing Wolf Kabinett 2002'}.next()
g.addEdge(tom, kabinett, 'likes')
g.addEdge(tom, ice_wine, 'likes')
g.addEdge(tom, g.V.filter{it.name=='Wine Expert Monthly'}.next(), 'trusts')Patty is friends with both Tom and Alice but is new to wine and has yet to choose any favorites.
patty = g.addVertex([name:'Patty'])
g.addEdge(patty, tom, 'friends')
g.addEdge(patty, alice, 'friends')
Without changing any fundamental structure of our existing graph, we were able to superimpose behavior beyond our original intent. The new nodes are related, as visualized in the following:
NoSQL Databases
By Sania Sutula


