






























Sarah Dean PRO
asst prof in CS at Cornell
SYSID, July 2024
\(\to\)
historical interactions
probability of new interaction
1. Modern Finite-Sample Perspectives
2. Towards SysId for Personalization
inputs
outputs
time
1. Modern Finite-Sample Perspectives
inputs
outputs
time
Statistical Learning Theory for Control: A Finite Sample Perspective
Anastasios Tsiamis, Ingvar Ziemann, Nikolai Matni, George J. Pappas IEEE Control Systems Magazine
Sample Complexity: How much data is necessary to learn a system?
Work with Horia Mania, Nikolai Matni, Ben Recht, and Stephen Tu in 2017
Motivation: foundation for understanding RL & ML-enabled control
building on the adaptive perspective by Abbasi-Yadkori & Szepesvári (2011)
Classic RL setting: discrete problems and inspired by games
RL techniques applied to continuous systems interacting with the physical world
Simplest problem: linear dynamics, quadratic cost, Gaussian process noise
minimize \(\mathbb{E}\left[ \displaystyle\lim_{T\to\infty}\frac{1}{T}\sum_{t=0}^T x_t^\top Q x_t + u_t^\top R u_t\right]\)
s.t. \(x_{t+1} = Ax_t+Bu_t+w_t\)
\(u_t = \underbrace{-(R+B^\top P B)^{-1} B^\top P A}_{K_\star}x_t\)
where \(P=\text{DARE}(A,B,Q,R)\) also defines the value function \(V(x) = x^\top P x\)
Static feedback controller is optimal and can be computed in closed-form:
How many observations are necessary to control unknown system?
As long as \(N\) is large enough, then with probability at least \(1-\delta\),
\(\mathrm{rel.~error~of}~\widehat{\mathbf K}\lesssim \frac{\mathrm{size~of~noise}}{\mathrm{size~of~excitation}} \sqrt{\frac{\mathrm{dimension}}{N} \log(1/\delta)} \cdot\mathrm{robustness~of~}K_\star\)
excitation
\((A_\star, B_\star)\)
\(N\) observations
1. Collect \(N\) observations and estimate \(\widehat A,\widehat B\) and confidence intervals
2. Use estimates to synthesize robust controller \(\widehat{\mathbf{K}}\)
\((A_\star, B_\star)\)
\(\widehat{\mathbf{K}}\)
\((A_\star, B_\star)\)
\(\|\hat A-A_\star\|\leq \epsilon_A\)
\(\|\hat B-B_\star\|\leq \epsilon_B\)
Main Control Result (Informal):
rel. error of \(\widehat{\mathbf K}\lesssim (\epsilon_A+\epsilon_B\|K_\star\|) \|\mathscr{R}_{A_\star+B_\star K_\star}\|_{\mathcal H_\infty}\)
robustness of \(K_\star\)
Least squares estimate: \((\widehat A, \widehat B) \in \arg\min \sum_{\ell=1}^N \|Ax_{T}^{(\ell)} +B u_{T}^{(\ell)} - x_{T+1}^{(\ell)}\|^2 \)
As long as \(N\gtrsim n+p+\log(1/\delta)\), then with probability at least \(1-\delta\),
\(\|\widehat A - A_\star\| \lesssim \frac{\sigma_w}{\sqrt{\lambda_{\min}(\sigma_u^2 G_T G_T^\top + \sigma_w^2 F_T F_T^\top )}} \sqrt{\frac{n+p }{N} \log(1/\delta)} \), \(\|\widehat B - B_\star\| \lesssim \frac{\sigma_w}{\sigma_u} \sqrt{\frac{n+p }{N} \log(1/\delta)} \)
with controllability Grammians defined as
\(G_T = \begin{bmatrix}A_\star^{T-1}B_\star&A_\star^{T-2}B_\star&\dots&B_\star\end{bmatrix} \qquad F_T = \begin{bmatrix}A_\star^{T-1}&A_\star^{T-2}&\dots&I\end{bmatrix}\)
\((A_\star, B_\star)\)
Excitation
\(u_t^{(\ell)} \sim \mathcal{N}(0, \sigma_u^2)\)
Observe states \(\{x_t^{(\ell)}\}\)
have independent Gaussian entries
\(\begin{bmatrix} x_{T}^{(\ell)} \\u_{T}^{(\ell)} \end{bmatrix} \sim \mathcal{N}\left(0, \begin{bmatrix}\sigma_u^2 G_TG_T^\top + \sigma_w^2 F_TF_T^\top &\\ & \sigma_u^2 I\end{bmatrix}\right)\)
\(w_t^{(\ell)} \sim \mathcal{N}\left(0, \sigma_w^2\right)\)
The least-squares estimate is
\(\arg \min \|Z_N \begin{bmatrix} A & B\end{bmatrix} ^\top - X_N\|^2_F = (Z_N^\top Z_N)^\dagger Z_N^\top X_N\)
\(= \begin{bmatrix} A_\star & B_\star \end{bmatrix} ^\top + (Z_N^\top Z_N)^\dagger Z_N^\top W_N\)
Data and noise matrices
\(X_N = \begin{bmatrix} x_{T+1}^{(1)} & \dots & x_{T+1}^{(N)} \end{bmatrix}^\top\)
\(Z_N = \begin{bmatrix} x_{T}^{(1)} & \dots & x_{T}^{(N)} \\u_{T}^{(1)} & \dots & u_{T}^{(N)} \end{bmatrix}^\top\)
\(W_N = \begin{bmatrix} w_{T}^{(1)} & \dots & w_{T}^{(N)} \end{bmatrix}^\top \)
lower bound minimum singular value,
or compute data-dependent bound
upper bound inner products
\((A_\star, B_\star)\)
1. Excite system for \(N\) steps and estimate \(\widehat A,\widehat B\)
2. Run controller \(\widehat{\mathbf{K}}\) for remaining time \(T-N\)
\((A_\star, B_\star)\)
\(\widehat{\mathbf{K}}\)
\((A_\star, B_\star)\)
1. Modern Finite-Sample Perspectives
2. Towards SysId for Personalization
inputs
outputs
time
2. Towards SysId for Personalization
\(u_t\)
\(y_t\)
Classically studied as an online decision problem (e.g. multi-armed bandits)
unknown preference
expressed preferences
recommended content
recommender policy
\(u_t\)
unknown preference \(x\)
expressed preferences
recommended content
recommender policy
\(\mathbb E[y_t] = x^\top C u_t \)
goal: identify \(C^\top x\) sufficiently well to make good recommendations
Classically studied as an online decision problem (e.g. multi-armed bandits)
Algorithms: Expore-then-Commit, \(\varepsilon\)-Greedy, Upper Confidence Bound
\(u_t\)
However, interests may be impacted by recommended content
preference state \(x_t\)
expressed preferences
recommended content
recommender policy
\(\mathbb E[y_t] = x_t^\top C u_t \)
updates to \(x_{t+1}\)
Implications for personalization [DM22]
It is not necessary to estimate preferences to make "good" recommendations
Preferences "collapse" towards whatever users are often recommended
Non-manipulation (and other goals) can be achieved through randomization
Even if harmful content is never recommended, can cause harm through preference shifts [CDEIKW24]
initial preference
resulting preference
recommendation
e.g. playlist attributes
e.g. listen time
inputs \(u_t\)
\( \)
outputs \(y_t\)
Input: data \((u_0,y_0,...,u_T,y_T)\), history length \(L\), state dim \(n\)
Step 1: Regression
$$\hat G = \arg\min_{G\in\mathbb R^{p\times pL}} \sum_{t=L}^T \big( y_t - u_t^\top \textstyle \sum_{k=1}^L G[k] u_{t-k} \big)^2 $$
Step 2: Decomposition \(\hat A,\hat B,\hat C = \mathrm{HoKalman}(\hat G, n)\)
\(t\)
\(L\)
\(\underbrace{\qquad\qquad}\)
inputs
outputs
time
Yahya Sattar
\(~\)
$$\hat G = \arg\min_{G\in\mathbb R^{p\times pL}} \sum_{t=L}^T \big( y_t - u_t^\top \textstyle \sum_{k=1}^L G[k] u_{t-k} \big)^2 $$
\(t\)
\(L\)
\(\underbrace{\qquad\qquad}\)
\(\bar u_{t-1}^\top \otimes u_t^\top \mathrm{vec}(G) \)
inputs
outputs
time
\(*\)
\(=\)
\(\underbrace{\qquad\qquad}\)
\(\underbrace{\qquad\qquad}\)
\(\underbrace{\qquad\qquad}\)
\(\underbrace{\qquad\qquad\qquad}\)
$$Z = \begin{bmatrix}\bar u_{L-1}^\top \otimes u_L^\top \\ \vdots \\ \bar u_{T-1}^\top \otimes u_T^\top\end{bmatrix} $$
Assumptions:
With probability at least \(1-\delta\), $$\|G-\hat G\|_{Z^\top Z} \lesssim \sqrt{ \frac{p^2 L}{\delta} \cdot c_{\mathrm{stability,noise}} }+ \rho(A)^L\sqrt{T} c_{\mathrm{stability}}$$
Assumptions:
With high probabilty, $$\mathrm{est.~errors} \lesssim \sqrt{ \frac{\mathsf{poly}(\mathrm{dimension})}{\sigma_{\min}(Z^\top Z)}}$$
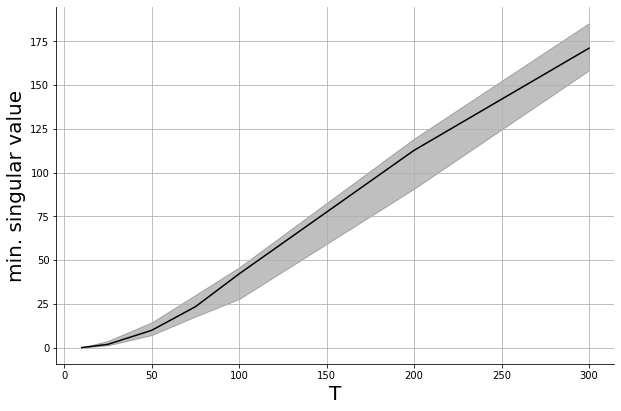
When \(u_t\) are chosen i.i.d. and sub-Gaussian and \(T\) is large enough, whp $$\sigma_{\min}({Z^\top Z} )\gtrsim T$$
For i.i.d. and sub-Gaussian inputs, whp $$\mathrm{est.~errors} \lesssim \sqrt{ \frac{\mathsf{poly}(\mathrm{dim.})}{T}}$$
How large does \(T\) need to be to guarantee bounded estimation error?
\(*\)
\(=\)
formal analysis involves the structured random matrix \(Z\)
$$ = \begin{bmatrix}\bar u_{L-1}^\top \otimes u_L^\top \\ \vdots \\ \bar u_{T-1}^\top \otimes u_T^\top\end{bmatrix} $$
1. Modern Finite-Sample Perspectives
2. Towards SysId for Personalization
Questions about decision-making from the learning theory perspective motivate new system identification results
inputs
outputs
time
Dean, Matni, Recht, Ya. "Robust Guarantees for Perception-Based Control." L4DC, 2020.
Dean, Tu, Matni, Recht. "Safely learning to control the constrained linear quadratic regulator." ACC, 2019
Gaitonde, Kleinberg, Tardos, 2021. Polarization in geometric opinion dynamics. EC.
Hązła, Jin, Mossel, Ramnarayan, 2019. A geometric model of opinion polarization. Mathematics of Operations Research.
Mania, Tu, Recht. "Certainty Equivalence is Efficient for Linear Quadratic Control." NeuRIPS, 2019.
Omyak & Ozay, 2019. Non-asymptotic Identification of LTI Systems from a Single Trajectory. ACC.
Simchowitz, Mania, Tu, Jordan, Recht. "Learning without mixing: Towards a sharp analysis of linear system identification." COLT, 2018.
As long as \(N\gtrsim (n+p)\sigma_w^2\|\mathscr R_{A_\star+B_\star K_\star}\|_{\mathcal H_\infty}(1/\lambda_G + \|K_\star\|^2/\sigma_u^2)\log(1/\delta)\), then for robustly synthesized \(\widehat{\mathbf{K}}\), with probability at least \(1-\delta\),
rel. error of \(\widehat{\mathbf K}\) \(\lesssim \sigma_w (\frac{1}{\sqrt{\lambda_G}} + \frac{\|K_\star\|}{\sigma_u}) \|\mathscr{R}_{A_\star+B_\star K_\star}\|_{\mathcal H_\infty} \sqrt{\frac{n+p }{T} \log(1/\delta)}\)
robustness of optimal closed-loop
excitability of system
optimal controller gain
vs.
more details on affinity maximization, preference stationarity, and mode collapse
$$\hat G = \arg\min_{G\in\mathbb R^{p\times pL}} \sum_{t=L}^T \big( y_t - \bar u_{t-1}^\top \otimes u_t^\top \mathrm{vec}(G) \big)^2 $$
Assumptions:
Suppose \(L\) is sufficiently large. Then, there exists a nonsingular matrix \(S\) (i.e. a similarity transform) such that
\(\|A-S\hat AS^{-1}\|_{Z^\top Z}\)
\(\| B-S\hat B\|_{Z^\top Z}\)
\(\| C-\hat CS^{-1}\|_{Z^\top Z} \)
$$\lesssim c_{\mathrm{contr,obs,dim}} \|G-\hat G\|_{Z^\top Z} $$
\(\underbrace{\qquad\qquad}\)
By Sarah Dean




