RAG and Agents
in 2024
with LlamaIndex

2024-08-15 AWS Loft
What are we talking about?
- What is LlamaIndex
- What is RAG
- Building RAG in LlamaIndex
- Limitations of RAG
- Building Agentic RAG
- Building Workflows in LlamaIndex
What is LlamaIndex?
Python: docs.llamaindex.ai
TypeScript: ts.llamaindex.ai
LlamaCloud

LlamaHub
- Data loaders
- Embedding models
- Vector stores
- LLMs
- Agent tools
- Pre-built strategies
- More!
Why LlamaIndex?
- Build faster
- Skip the boilerplate
- Avoid early pitfalls
- Get into production
- Deliver real value
What can LlamaIndex
do for me?
Why RAG
is necessary
How RAG works

The RAG pipeline

Loading
RAG, step 1:
documents = SimpleDirectoryReader("data").load_data()Parsing
RAG, step 2:
(LlamaParse: it's really good. Really!)
# must have a LLAMA_CLOUD_API_KEY
# bring in deps
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
# set up parser
parser = LlamaParse(
result_type="markdown" # "text" also available
)
# use SimpleDirectoryReader to parse our file
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(
input_files=['data/canada.pdf'],
file_extractor=file_extractor
).load_data()
print(documents)Embedding
RAG, step 3:
Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-en-v1.5")Storing
RAG, step 4:
index = VectorStoreIndex.from_documents(documents)Retrieving
RAG, step 5:
retriever = index.as_retriever()
nodes = retriever.retrieve("Who is Paul Graham?")Querying
RAG, step 6:
query_engine = index.as_query_engine()
response = query_engine.query("Who is Paul Graham?")Multi-modal
npx create-llama

Limitations of RAG
Summarization
Naive RAG failure modes:
Comparison
Naive RAG failure modes:
Multi-part questions
Naive RAG failure modes:
RAG is necessary
but not sufficient
Two ways
to improve RAG:
- Improve your data
- Improve your querying

RAG pipeline

⚠️ Single-shot
⚠️ No query understanding/planning
⚠️ No tool use
⚠️ No reflection, error correction
⚠️ No memory (stateless)
Agentic RAG

✅ Multi-turn
✅ Query / task planning layer
✅ Tool interface for external environment
✅ Reflection
✅ Memory for personalization
From simple to advanced agents

Routing
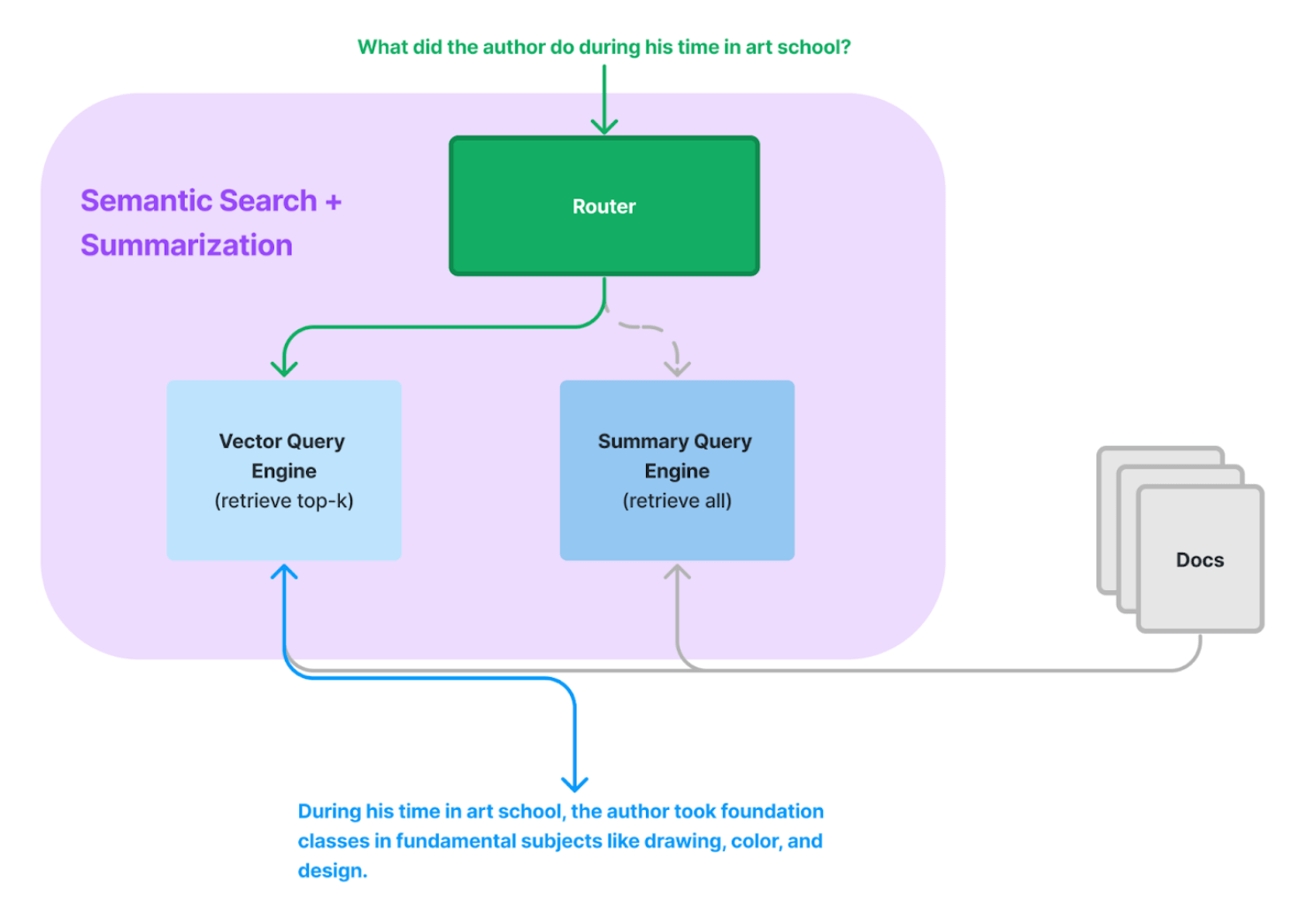
RouterQueryEngine
list_tool = QueryEngineTool.from_defaults(
query_engine=list_query_engine,
description=(
"Useful for summarization questions related to Paul Graham eassy on"
" What I Worked On."
),
)
vector_tool = QueryEngineTool.from_defaults(
query_engine=vector_query_engine,
description=(
"Useful for retrieving specific context from Paul Graham essay on What"
" I Worked On."
),
)
query_engine = RouterQueryEngine(
selector=LLMSingleSelector.from_defaults(),
query_engine_tools=[
list_tool,
vector_tool,
],
)Conversation memory
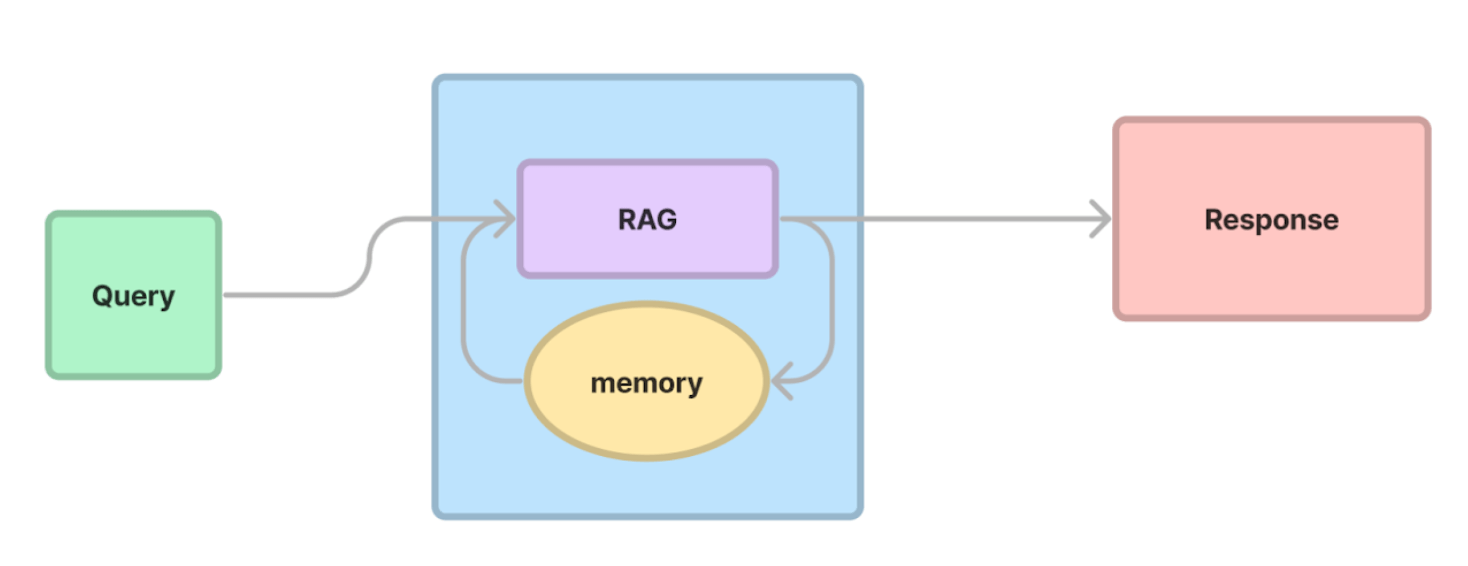
Chat Engine
# load and parse
documents = SimpleDirectoryReader("data").load_data()
# embed and index
index = VectorStoreIndex.from_documents(documents)
# generate chat engine
chat_engine = index.as_chat_engine()
# start chatting
response = query_engine.chat("What did the author do growing up?")
print(response)Query planning

Sub Question Query Engine
# set up list of tools
query_engine_tools = [
QueryEngineTool(
query_engine=vector_query_engine,
metadata=ToolMetadata(
name="pg_essay",
description="Paul Graham essay on What I Worked On",
),
),
# more query engine tools here
]
# create engine from tools
query_engine = SubQuestionQueryEngine.from_defaults(
query_engine_tools=query_engine_tools,
use_async=True,
)Tool use

Tools unleash the power of LLMs
Basic ReAct agent
# define sample Tool
def multiply(a: int, b: int) -> int:
"""Multiply two integers and returns the result integer"""
return a * b
multiply_tool = FunctionTool.from_defaults(fn=multiply)
# initialize ReAct agent
agent = ReActAgent.from_tools(
[
multiply_tool
# other tools here
],
verbose=True
)Combine agentic strategies
and then go further
- Routing
- Memory
- Planning
- Tool use
Agentic strategies
- Multi-turn
- Reasoning
- Reflection
Full agent
3 agent
reasoning loops
- Sequential
- DAG-based
- Tree-based
Sequential reasoning

ReAct in action
Thought: I need to use a tool to help me answer the question.
Action: multiply
Action Input: {"a": 2, "b": 4}
Observation: 8
Thought: I need to use a tool to help me answer the question.
Action: add
Action Input: {"a": 20, "b": 8}
Observation: 28
Thought: I can answer without using any more tools.
Answer: 28DAG-based reasoning

Self reflection

Structured Planning Agent
# create the function calling worker for reasoning
worker = FunctionCallingAgentWorker.from_tools(
[lyft_tool, uber_tool], verbose=True
)
# wrap the worker in the top-level planner
agent = StructuredPlannerAgent(
worker, tools=[lyft_tool, uber_tool], verbose=True
)
response = agent.chat(
"Summarize the key risk factors for Lyft and Uber in their 2021 10-K filings."
)The Plan
=== Initial plan ===
Extract Lyft Risk Factors:
Summarize the key risk factors from Lyft's 2021 10-K filing. -> A summary of the key risk factors for Lyft as outlined in their 2021 10-K filing.
deps: []
Extract Uber Risk Factors:
Summarize the key risk factors from Uber's 2021 10-K filing. -> A summary of the key risk factors for Uber as outlined in their 2021 10-K filing.
deps: []
Combine Risk Factors Summaries:
Combine the summaries of key risk factors for Lyft and Uber from their 2021 10-K filings into a comprehensive overview. -> A comprehensive summary of the key risk factors for both Lyft and Uber as outlined in their respective 2021 10-K filings.
deps: ['Extract Lyft Risk Factors', 'Extract Uber Risk Factors']Tree-based reasoning

Exploration vs exploitation
Language Agent Tree Search
agent_worker = LATSAgentWorker.from_tools(
query_engine_tools,
llm=llm,
num_expansions=2,
max_rollouts=3,
verbose=True,
)
agent = agent.as_worker()
task = agent.create_task(
"Given the risk factors of Uber and Lyft described in their 10K files, "
"which company is performing better? Please use concrete numbers to inform your decision."
)Workflows
Why Workflows?
Workflows primer
from llama_index.llms.openai import OpenAI
class OpenAIGenerator(Workflow):
@step()
async def generate(self, ev: StartEvent) -> StopEvent:
query = ev.get("query")
llm = OpenAI()
response = await llm.acomplete(query)
return StopEvent(result=str(response))
w = OpenAIGenerator(timeout=10, verbose=False)
result = await w.run(query="What's LlamaIndex?")
print(result)Looping
class LoopExampleFlow(Workflow):
@step()
async def answer_query(self, ev: StartEvent | QueryEvent ) -> FailedEvent | StopEvent:
query = ev.query
# try to answer the query
random_number = random.randint(0, 1)
if (random_number == 0):
return FailedEvent(error="Failed to answer the query.")
else:
return StopEvent(result="The answer to your query")
@step()
async def improve_query(self, ev: FailedEvent) -> QueryEvent | StopEvent:
# improve the query or decide it can't be fixed
random_number = random.randint(0, 1)
if (random_number == 0):
return QueryEvent(query="Here's a better query.")
else:
return StopEvent(result="Your query can't be fixed.")
l = LoopExampleFlow(timeout=10, verbose=True)
result = await l.run(query="What's LlamaIndex?")
print(result)Visualization

draw_all_possible_flows()Keeping state
class RAGWorkflow(Workflow):
@step(pass_context=True)
async def ingest(self, ctx: Context, ev: StartEvent) -> Optional[StopEvent]:
dataset_name = ev.dataset
documents = SimpleDirectoryReader("data").load_data()
ctx.data["INDEX"] = VectorStoreIndex.from_documents(documents=documents)
return StopEvent(result=f"Indexed {len(documents)} documents.")
...Workflows enable arbitrarily complex applications
Customizability
class MyWorkflow(RAGWorkflow):
@step(pass_context=True)
def rerank(
self, ctx: Context, ev: Union[RetrieverEvent, StartEvent]
) -> Optional[QueryResult]:
# my custom reranking logic here
w = MyWorkflow(timeout=60, verbose=True)
result = await w.run(query="Who is Paul Graham?")Observability
Evaluation
Recap
- What is LlamaIndex
- LlamaCloud, LlamaHub, create-llama
- Why RAG is necessary
- How to build RAG
- Loading, parsing, embedding
- Storing, retrieving, querying
- Limitations of RAG
- Summarization, comparison, multi-part questions
- Agentic RAG
- Routing, memory, planning, tool use
- Reasoning patterns
- Sequential, DAG based, tree based
- Workflows
- Loops, state, customizability
What's next?
We can't wait to see
what you build!

Thanks!
All resources:
Follow me on Twitter:
@seldo
Please don't add me on LinkedIn.

RAG and Agents in 2024 (AWS SF)
By Laurie Voss



