
RAG in 2024:
Advancing to Agents

2024-10-30 ODSC West
What are we talking about?
- What is LlamaIndex
- Why you should use it
- What can it do
- Retrieval augmented generation
- World class parsing
- Agents and multi-agent systems
What is LlamaIndex?
Python: docs.llamaindex.ai
TypeScript: ts.llamaindex.ai
LlamaParse
World's best parser of complex documents
Free for 1000 pages/day!
cloud.llamaindex.ai
LlamaCloud
Turn-key RAG API for Enterprises
Available as SaaS or private cloud deployment

LlamaHub
- Data loaders
- Embedding models
- Vector stores
- LLMs
- Agent tools
- Pre-built strategies
- More!
Why LlamaIndex?
- Build faster
- Skip the boilerplate
- Avoid early pitfalls
- Get best practices for free
- Go from prototype to production
What can LlamaIndex
do for me?
Why RAG
is necessary
How RAG works

Basic RAG pipeline

5 line starter
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)npx create-llama

Limitations of RAG
- Summarization
- Comparison
- Multi-part questions
Naive RAG failure points:
RAG is necessary
but not sufficient
Two ways
to improve RAG:
- Improve your data
- Improve your querying

What is an agent anyway?
- Semi-autonomous software
- Accepts a goal
- Uses tools to achieve that goal
- Exact steps to resolution not specified
RAG pipeline

⚠️ Single-shot
⚠️ No query understanding/planning
⚠️ No tool use
⚠️ No reflection, error correction
⚠️ No memory (stateless)
Agentic RAG

✅ Multi-turn
✅ Query / task planning layer
✅ Tool interface for external environment
✅ Reflection
✅ Memory for personalization
From simple to advanced agents

Routing
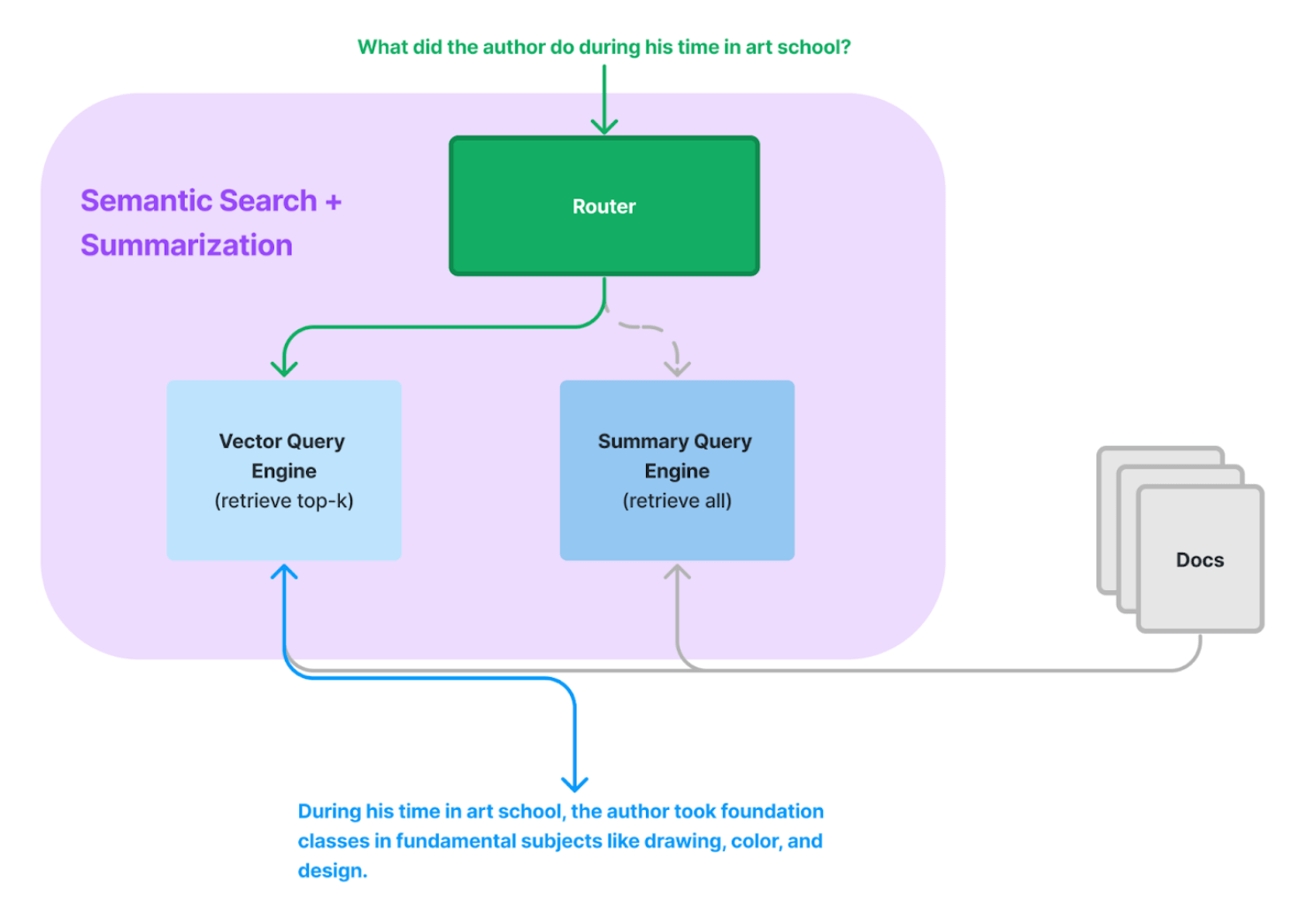
Conversation memory
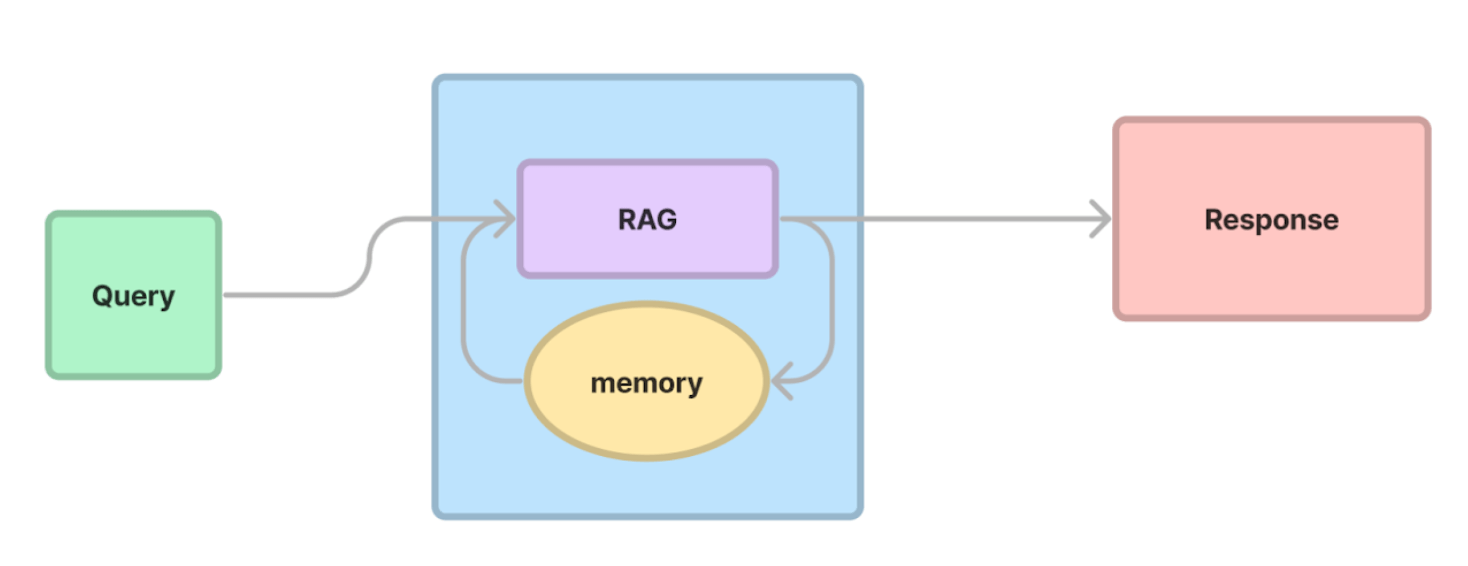
Query planning

Tool use

Tools unleash the power of LLMs
Combine agentic strategies
and then go further
- Routing
- Memory
- Planning
- Tool use
Agentic strategies
- Multi-turn
- Reasoning
- Reflection
Full agent
3 agent
reasoning loops
- Sequential
- DAG-based
- Tree-based
Sequential reasoning

DAG-based reasoning

Self reflection

Tree-based reasoning

Exploration vs exploitation
Workflows
Why workflows?
Workflows primer
from llama_index.llms.openai import OpenAI
class OpenAIGenerator(Workflow):
@step()
async def generate(self, ev: StartEvent) -> StopEvent:
query = ev.get("query")
llm = OpenAI()
response = await llm.acomplete(query)
return StopEvent(result=str(response))
w = OpenAIGenerator(timeout=10, verbose=False)
result = await w.run(query="What's LlamaIndex?")
print(result)Visualization

draw_all_possible_flows()Workflows enable arbitrarily complex applications
Multi-agent concierge
Deploying agents
to production
pip install llama-deploy
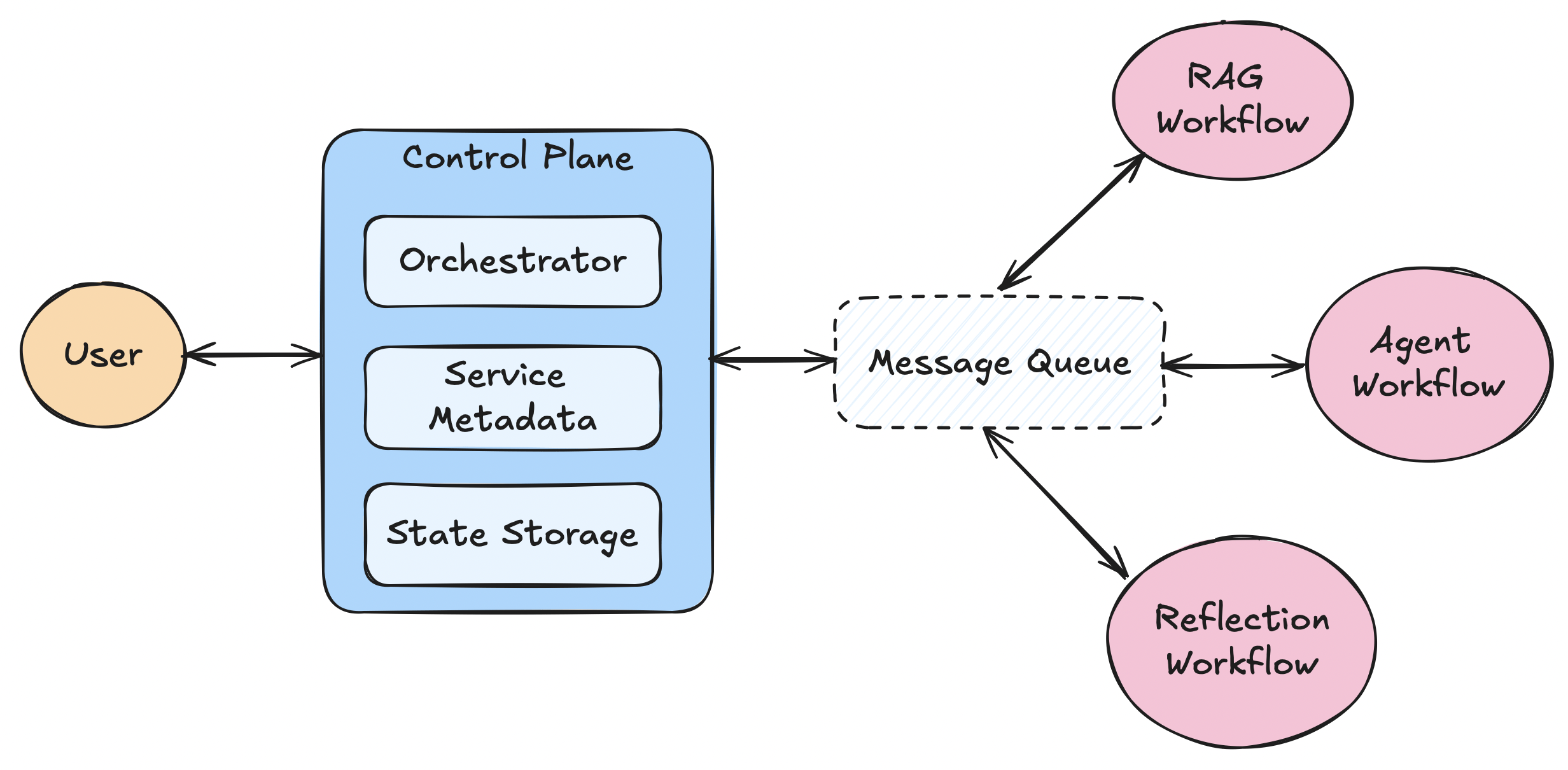
Agents as microservices
Try out llama-deploy
Recap
- What is LlamaIndex
- LlamaCloud, LlamaHub, create-llama
- Why RAG is necessary
- How to build RAG in LlamaIndex
- Limitations of RAG
- Agentic RAG
- Routing, memory, planning, tool use
- Reasoning patterns
- Sequential, DAG-based, tree-based
- Workflows
- Loops, state, customizability
- Deploying workflows
What's next?

Thanks!
Follow me on BlueSky:
@seldo.com

RAG in 2024: Advancing to Agents (ODSC West)
By Laurie Voss



