Exploring the relationship between intonation and the lexicon:
Evidence for lexicalised storage of intonation
Katrin Schweitzer, Michael Walsh, Sasha Calhoun, Hinrich Schutze, Bernd Mobius, Antje Schweitzer, Grzegorz Dogil
Speech Communication (2015)
Sheng-Fu @2014/12/18
Introduction
The question
Are the choice of intonation contour and the form of the contour independent of the words used?
The Autosegmental-Metric Theory
-
The assignment of intonation is autonomous from the segmental level
-
The separation of the lexical and the tonal level
-
Realization of pitch contours is determined by phonetic rules
-
(refering to tonal sequences and metrical organization)
-
-
At odds with the idea of storing acoustic details with lexical items
-
The Exemplar Theory
-
Detailed episodic storage
-
Frequent units lead to many exemplars
-
Frequent units display less variation
- “entrenchment” (Lee et al., 1999; Pierrehumber, 2001)
- Present study: lexical and word+accent frequency
Exemplar models and prosody/intonation
-
Current exemplar models do not take account of intonation
-
Frequency effects on prosody
-
acquisition of the prosodic word (Vigario et al., 2006)
-
word stress assignment (Daelemans et al., 1994)
-
predictability of syllable duration (Schiweitzer & Mobius, 2004)
-
-
Present study: frequency effect on PA variability
-
Evidence for supporting an exemplar view on word+intonation
-
Corpus Analysis
Overview
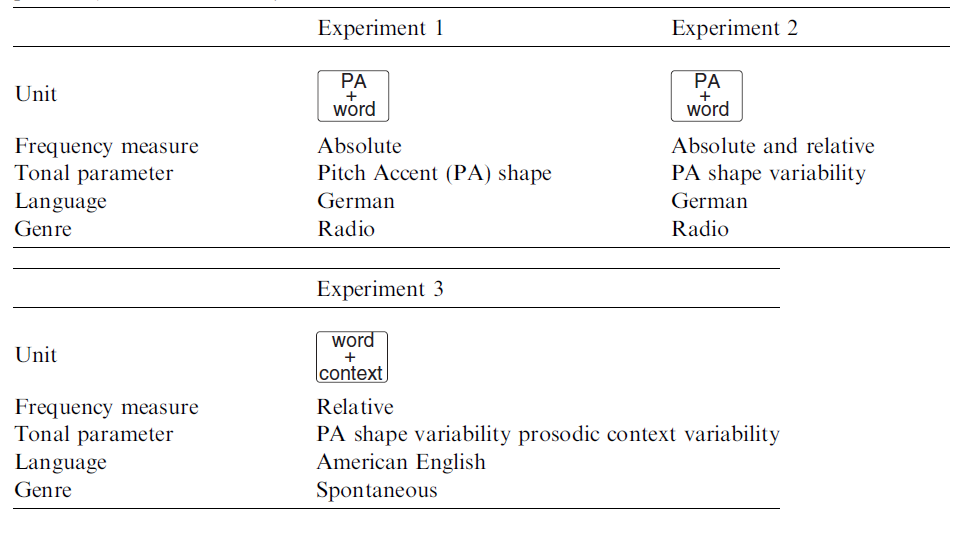
Parametrisation of pitch accent shape
(The PaIntE model)
a1 and a2: steepness of rise and fall
- b: alignment of the peak
- c1 and c2: amplitude of the falling and rising sigmoid
- It is also possible to use one sigmoid only (c)
- d: height of the peak
Experiment 1
absolute frequency of pitch accent + word
Data
-
Annotated part of the DIRNDL-Corpus, German radio news broadcasts (5 hours and 16 min)
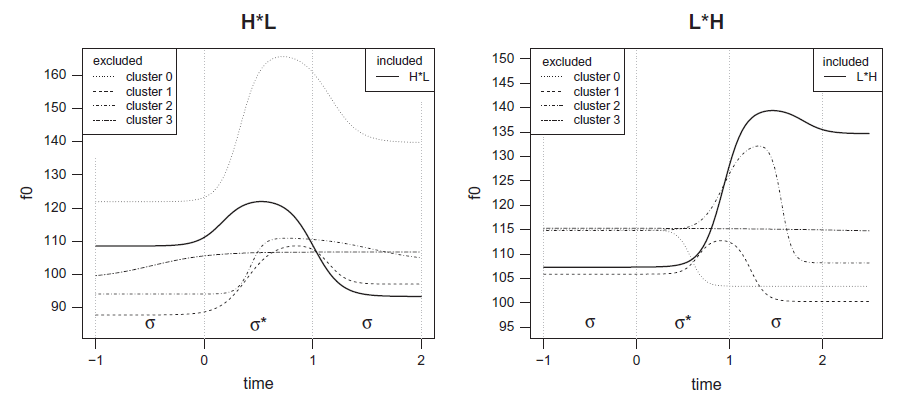
- 7871 L*H and 6118 H*L tokens
- For each word type, frequencies of combination with L*H and H*L were calculated
- outliners for any PaIntE parameters were removed
- patterns that are not "clear" were removed
Results of Plausibility checks
Methods
- Dependent variable: accent range (c1 and c2)
- Fixed Factors:
- frequency of word+accent pairs (logged)
- number of accent to the next IP boundary
- coda size (number of segments)
- onset/coda classification: -V, +S, +V-S
- Random intercepts and slopes for word and speaker
- Linear mixed model with likelihood ratio tests
- add fixed factors separately, only keep the significant ones
Result for H*L

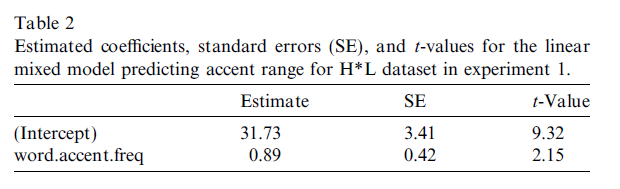
The range is increased by approx. 0.89 Hz for each unit increase in logged frequency of occurrence
Result for L*H

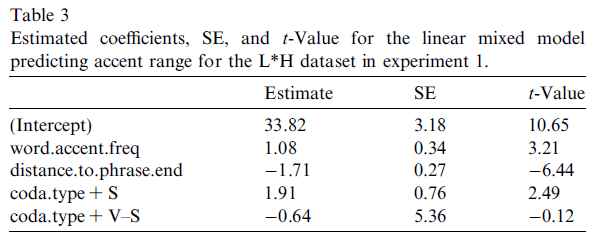
- higher word+PA frequency, bigger range
- sonorant coda, bigger range
- closer to the boundary, bigger range
Experiment 2
relative frequency of pitch accent + word
Methods: Accent variability
- Statistical tests: as in Exp 1
- New fixed factor: relative frequency: "how often is does the word type bear the accent?"
- Calculating the variability of realization
- z-scoring the PaIntE parameters for speakers and accent types
- The vector for each token = {a1, a2, b, c1, c2, d}
- For each token, the vector's distance with other tokens of the same type (word+PA) was calculated
- Average distance = variability
Methods: Accent variability
- For example, for a token "Porsche"+H*L
- Variability (DV) = it's average distance with all other tokens for "Porsche"+H*L
- Absolute frequency (IV) = type frequency of "Porsche"+H*L
- Relative frequency (IV) =
\frac{``Porsche"+H*L}{``Porsche"}
‘‘Porsche"‘‘Porsche"+H∗L
Result for H*L
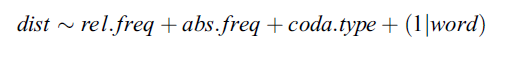
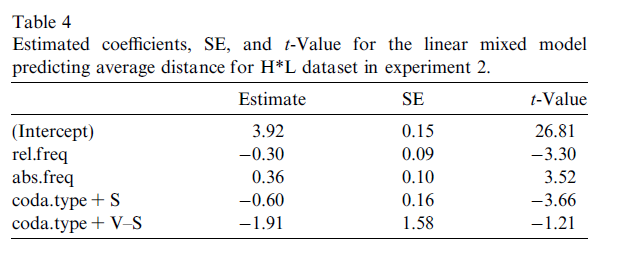
higher rel.freq, lower variability
higher abs.freq, higher variability
sonorant coda, lower variability
Result for L*H
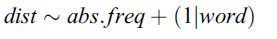
- Result: higher abs.freq, higher variability
Experiment 3
relative frequency of word in lexical context
Data
-
A subset of the Switchboard corpus (6 hours)
-
PA location and boundary location were labeled.
-
- Two datasets were extracted
- prosodic pattern dataset
- trigrams with a frequency > 4
- pitch accent variability dataset
- trigrams with a PA on the middle word
- prosodic pattern dataset
-
Relative frequency:
\frac{trigram frequency}{middle word frequency}
middlewordfrequencytrigramfrequency
Prosodic pattern variability: Methods
- Prosodic pattern: two variables
- NoAcc vs. Acc
- NoBound vs. Bound
- e.g. NoAcc-NoBound—Acc-NoBound—NoAcc-Bound.
-
Variability:
-
Most common pattern for a word in any trigram (e.g., lot)
-
For each trigram with the middle word (lot), determine whether it has that common pattern
-
This is the binary dependent variable
-
-
Prosodic pattern variability: Methods
- For example: for the trigram: "a lot of"
- find the most frequent prosodic pattern for "lot" in all kind of trigrams when it's the middle word
- " NoAcc-NoBound—Acc-NoBound—NoAcc-Bound"
- For each token of "a lot of", determine if it has the pattern (DV)
- Independent variables:
- absolute frequency of "lot"
- relative frequency: "a lot of" divided by "lot"
Prosodic pattern variability: Results
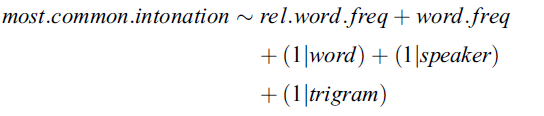
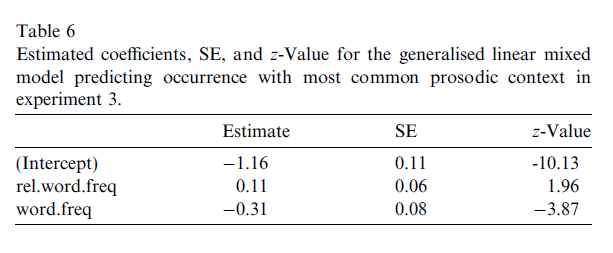
- higher rel.word.freq, higher probability for having the most common prosodic pattern (lower variability)
- higher absolute word.freq, lower probability for having the most common prosodic pattern (higher variability)
Pitch accent variability: Methods
- Calculation: same as Exp. 2
- z-scoring the PaIntE parameters for speakers
- The vector for each token (middle word) = {a1, a2, b, c1, c2, d}
- For each token, the vector's distance with other tokens of the same type was calculated
- Average distance = variability
- For example, for a token of "a lot of"
- Variability (DV) = it's average distance with all other tokens for "lot" in "a lot of"
- Absolute frequency (IV) = type frequency of "lot"
- Relative frequency (IV) = "a lot of" divided by "lot"
Pitch accent variability: Methods
Pitch accent variability: Results
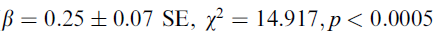
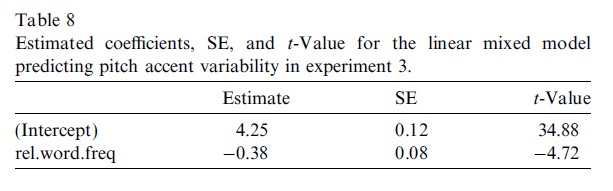
- higher rel.word.freq, lower variability
Discussion
and Conclusion
PA+word freq and Accent range
- PA's F0 range increases as PA+word's frequency increases
- The relationship between tonal and word levels has no obvious explanation in AM theory
-
Theories of episodic storage are able to explain this
-
linguistic units as concrete and highly specified instances, containing properties of the tonal and the lexical
-
- Why greater range with greater frequency?
- choosing the exemplars meeting communication goals
- PA = prominence
PA+word rel.freq and PA variability
-
Less variability with increasing relative frequency (H*L)
- if a word if often realized with a particular accent type (communicative function), then the set of exemplars will be more homogeneous
-
More variability with increasing absolute frequency
-
Greater absolute frequency = greater variability because tokens are coming from all contexts
-
Trigram frequency, prosodic context, PA realization
-
As relative trigram frequency increases...
-
more homogeneous prosodic context (more likely to be the most common pattern)
-
less variability for pitch Accent realization
-
-
Evidence for cohesion between the word and its prosodic realization
-
Explained with the exemplar theory:
-
tonal events are stored with lexical sequences
-
words collocate together will be stored together and acquire particular phonetic characteristics
-
Other Discussions
-
Word and PA tokens separately with co-index?
- Pitch contours and words together?
- This explains the results of entrenched intonation (less variability) better
-
Effects too subtle?
-
intonational information is very uneven across the lexicon, so effects do not show well across words
-
Conclusion
-
This study demonstrates effects on intonation that
should be considered in exemplar-theoretic models.
- Entrenchment should be modelled for tonal parameters.
-
Frequency of occurrence effects are
acknowledged
Evidence for lexicalised storage of intonation
By sftwang0416


