

Shalin Shekhar Mangar
Committer on Apache Lucene/Solr, Engineer at Lucidworks Inc.
The standard for enterprise search.
Truly open source & proven at scale
Fast, scalable, reliable, distributed
NRT indexing and search
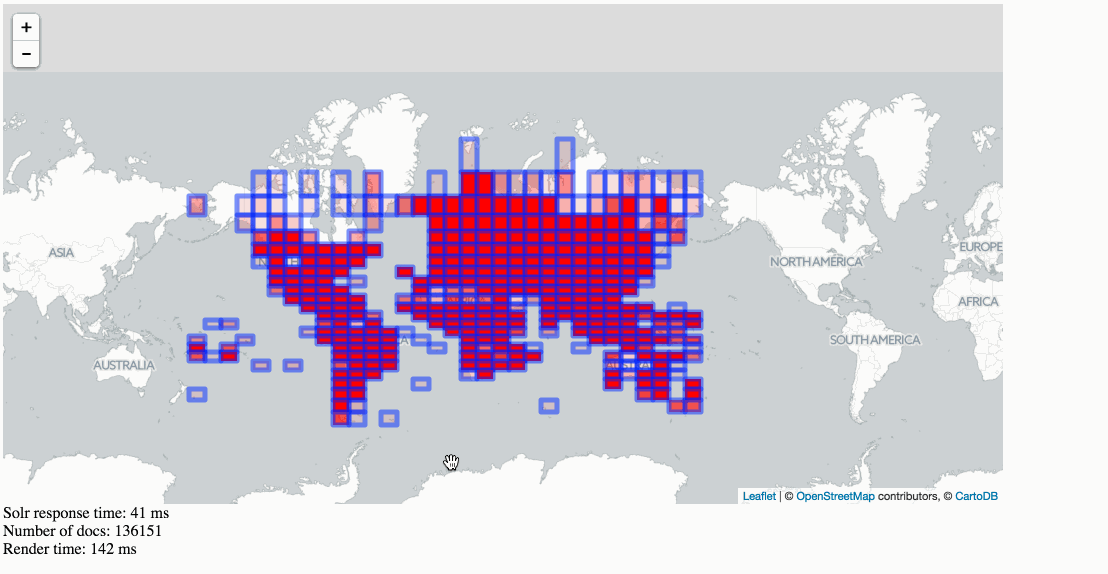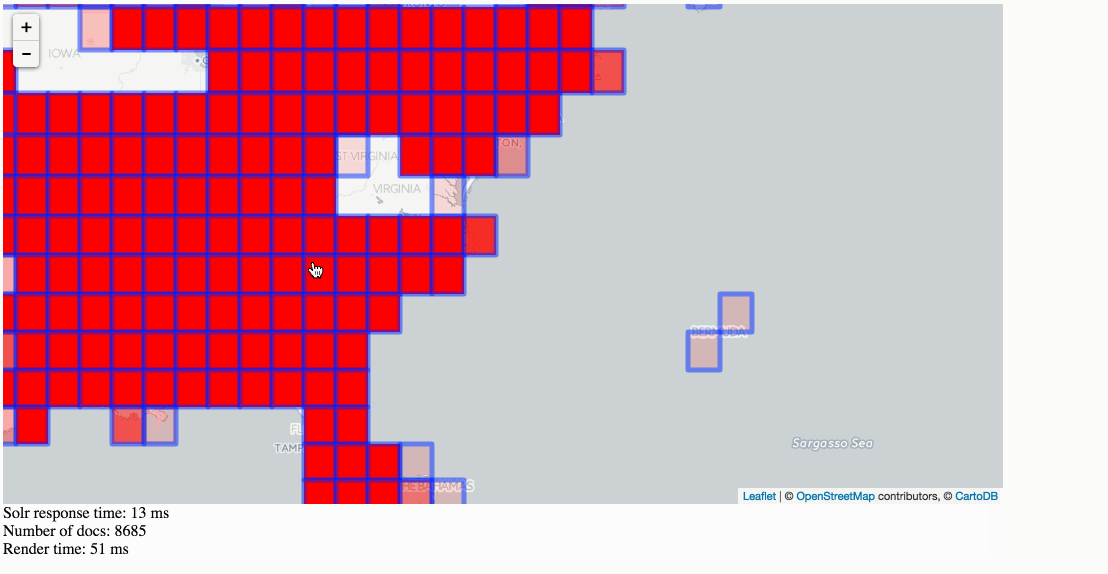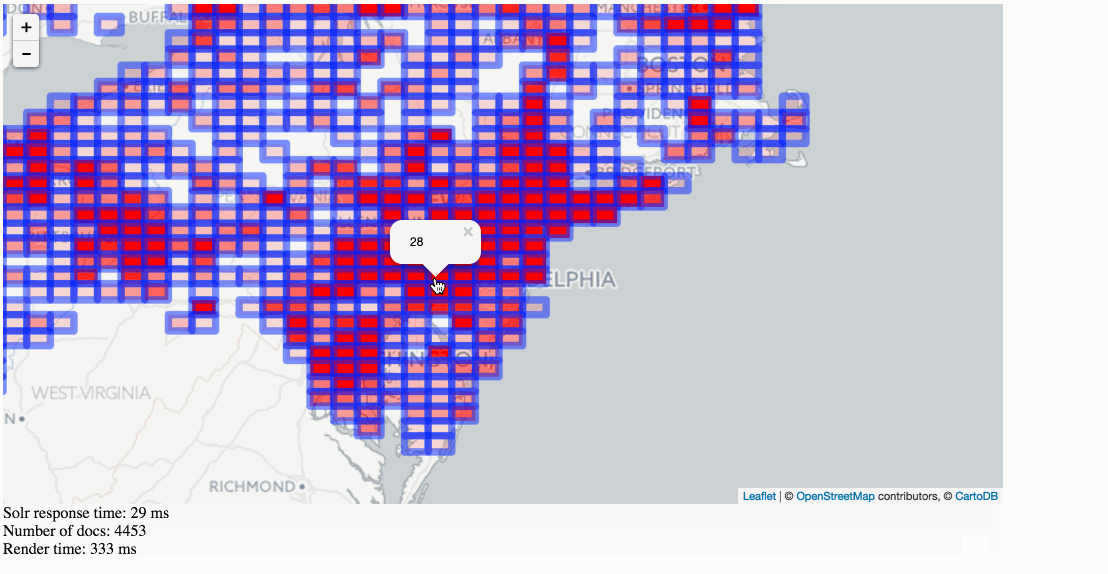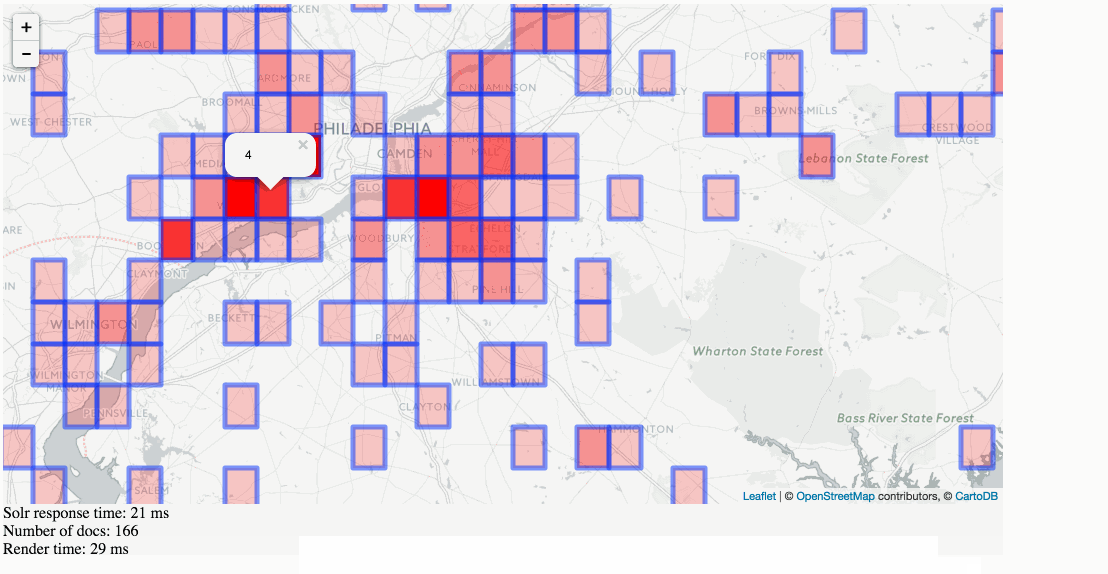
Stats, analytics, geospatial
Extremely pluggable
Extract:
tar xvf solr-6.0.1.tgz (linux/mac)
Run:
./bin/solr start -e schemaless
./bin/solr start -e cloud (interactive cloud setup)
./bin/solr start -e cloud -noprompt (zero effort demo cloud setup)
./bin/solr -help
Index documents:
./bin/post -c gettingstarted /path/to/local/data.extn
./bin/post -help
# Extn = {xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx}
# Extn = {odt, odp, ods, ott, otp, ots, rtf, htm, html, txt, log}
Search:
curl 'http://localhost:8983/solr/gettingstarted/select?q=*:*'
curl 'http://localhost:8983/solr/gettingstarted/select?q=my_query'
Stop:
./bin/solr stop
./bin/solr stop -p 8983
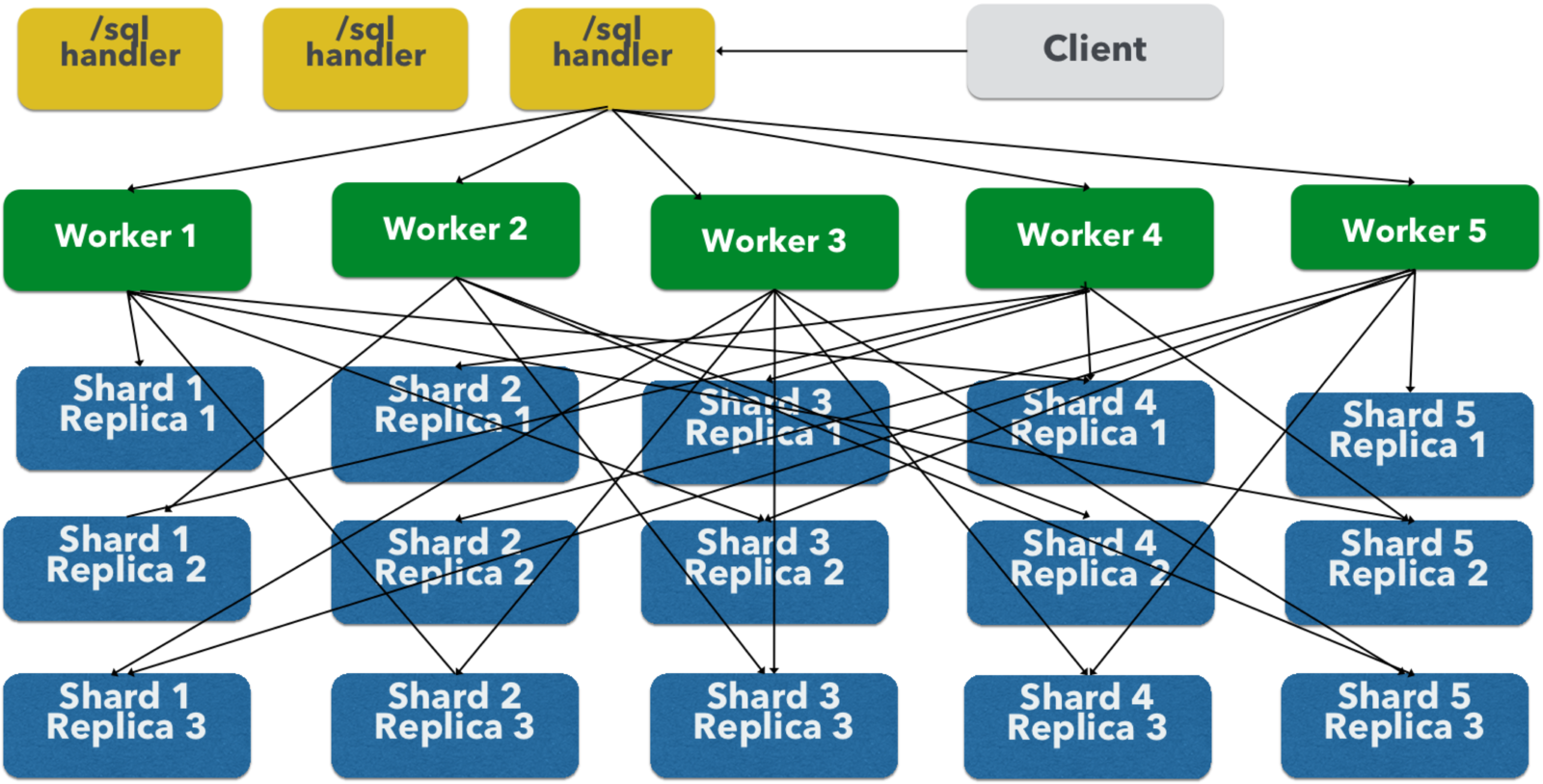
./bin/solr stop -allselect category, count(*), sum(inventory), min(price),
max(price), avg(outstanding)
from mytable
where text='XXXX'
group by category
order by sum(inventory) asc limit 10
select id, category from collection1
where category = 'dvd bluray'
order by category desc limit 100
select fieldA, fieldB, count(*), sum(fieldC), avg(fieldY)
from collection1
where fieldC = 'term1 term2'
group by fieldA, fieldB
having sum(fieldC) > 1000
order by sum(fieldC) asc
limit 100curl "http://localhost:8983/solr/movies/sql" \
--data-binary \
"stmt=select name,rank from movies \
where rank='[0 TO 10]' order by rank desc limit 10"
curl "http://localhost:8983/solr/movies/sql" \
--data-binary \
"stmt=select avg(rating) from movies \
where nb_voters='[10000 TO *]' and director='scor*'"
curl "http://localhost:8983/solr/movies/sql" \
--data-binary \
"stmt=select director, avg(rating), count(*) from movies \
where nb_voters='[10000 TO *]' group by director"// Assuming each document is a person, find Philip and all his ancestors
fq={!graph from=parent_id to=id}id:"Philip J. Fry"
// assume each doc is a tweet
// search for all tweets mentioning java by me or people I follow
q=java&fq={!graph from=following_id to=id maxDepth=1}id:"shalinmangar"curl -XPOST -H 'Content-type:application/hocon' --data-binary '{
operation : {
operation parameters
}
}' http://host:port/v2/endpoint
http://localhost:8983/solr/v2/collections/_introspect?command=create-alias
{"spec":{
"collections.Commands": {
"documentation": "https://cwiki.apache.org/confluence/display/solr/Collections+API#CollectionsAPI-api1",
"methods": ["POST","GET"],
"url": {
"paths": ["/collections"]},
"commands": {
"create-alias":{
"description":"Create an alias for one or more collection",
"documentation":"https://cwiki.apache.org/confluence/display/solr/Collections+API#CollectionsAPI-api4",
"properties": {
"name": {
"type": "string",
"description": "The alias name to be created"},
"collections" :{
"type":"list",
"description":"The list of collections to be aliased"}},
"required" : ["name","collections"]}}}}}// create a collection called 'golf'
curl -XPOST -d '{
create-collection : {
name : golf,
numShards : 2,
configTemplate : data_driven_schema_configs
}
}' http://localhost:8983/v2/collections/golf
// enable auto soft-commit every 2 seconds
curl -XPOST -d '{
set-property : { "updateHandler.autoSoftCommit.maxTime" : 2000 }
}' http://localhost:8983/v2/collections/golf/config
// index data
curl -XPOST -H 'Content-type: application/json' -d '[
{
"course": "fossil trace",
"city": "Golden",
"state": "CO",
"par": 72,
"score": 76,
"gir": 15,
"fairways": 10
}
]' http://localhost:8983/v2/collections/golf/update/json/docs
// query using JSON API
curl -d '{
query : "*:*",
rows: 10,
fields: [course, score, par, gir],
sort: "date desc"
}' http://localhost:8983/v2/collections/golf/query
shalin [at] apache [dot] org
By Shalin Shekhar Mangar
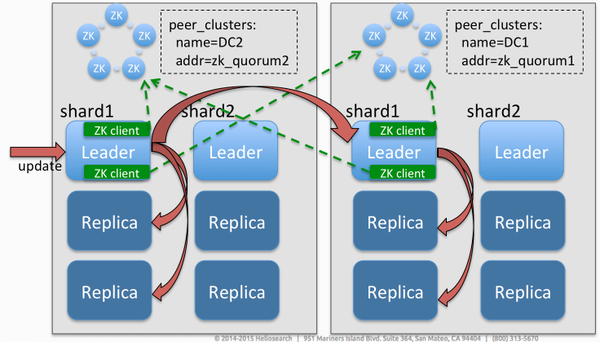
A preview of things to come in Solr 6