自我介紹
暱稱: Hohshen
目前擔任: 肝苦碼農
DB Lock
By Hohshen
目錄
- 這樣做才不會受傷
- 對, 就是在這裡
- 沒有你的世界
- 捆綁上鎖
- 兩位小鎖匠
- 芭比Q惹
- 我們一起去惹
隱藏黑暗力量的鑰匙啊,
在我面前顯示真正的力量吧!
跟擬定下約定的BESG命令你,封印解除!

這樣做才不會受傷
大家都知道鎖要上在c.s.上,
但鎖的對象是誰要特別注意

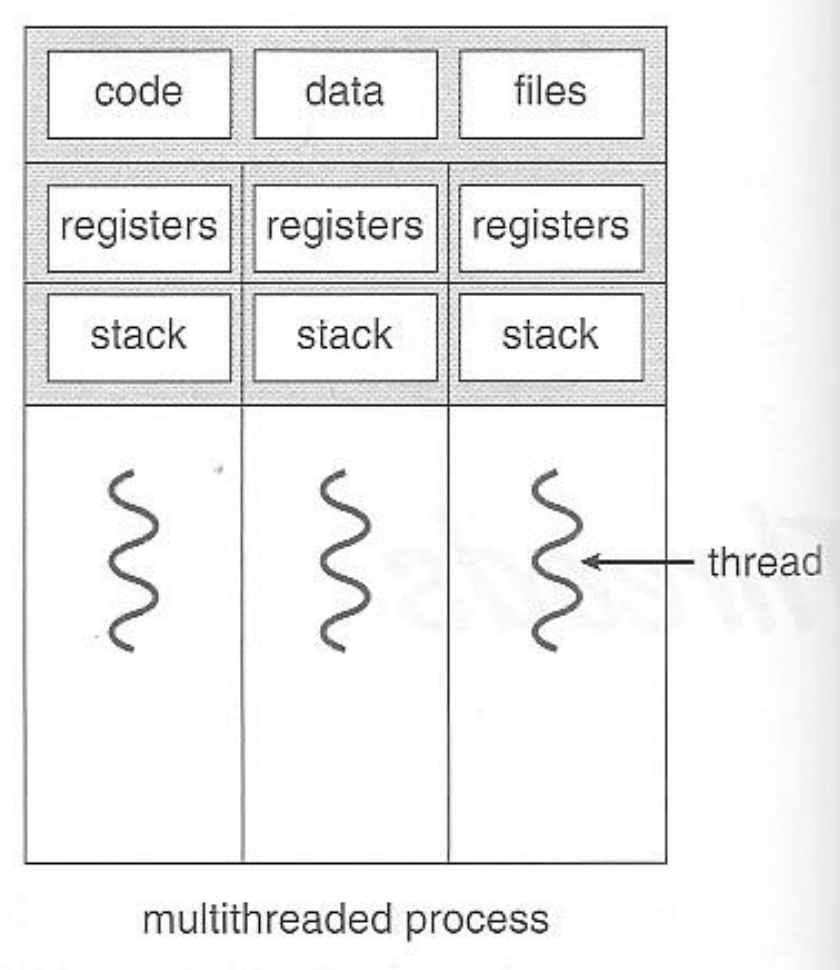
Application Concurrent Access
public class HelloRunnable implements Runnable {
@Override
public void run() {
int c = counter.get();
c++; // c--;
counter.set(c);
}
public static void main(String args[]) {
(new Thread(new HelloRunnable())).start();
(new Thread(new HelloRunnable())).start();
}
}Application Concurrent Access
Application Concurrent Access
| time | thread A | thread B | C |
|---|---|---|---|
| 1 | get c //c=0 | 0 | |
| 2 | get c //c=0 | 0 | |
| 3 | c++ //c=1 | ||
| 4 | c++ //c=1 | ||
| 5 | set c //c=1 | 1 | |
| 6 | set c //c=1 | 1 |
public void run() {
int c = counter.get();
c++; // c--;
counter.set(c);
}class Counter {
private int c = 0;
public void set(int c) { This.c = c; }
public int get() { return c; }
}Synchronization
class Counter {
private int c = 0;
public synchronized void set(int c) {
this.c = c;
}
public synchronized int get() {
return c;
}
}
class Counter {
private int c = 0;
public synchronized void set(int c) {
this.c = c;
}
public synchronized int get() {
return c;
}
}Synchronization
| time | thread A | thread B | C |
|---|---|---|---|
| 1 | get c //c=0 | 0 | |
| 2 | block | ||
| 3 | get c //c=0 | 0 | |
| 4 | c++ //c=1 | ||
| 5 | c++ //c=1 | ||
| 6 | set c //c=1 | 1 | |
| 7 | block | ||
| 8 | set c //c=1 | 1 |
Still Wrong!
A1: callee provides atomic methods
| time | thread A | thread B | C |
|---|---|---|---|
| 1 | get c //c=0 | 0 | |
| 2 | get c //c=0 | 0 | |
| 3 | c++ //c=1 | 1 | |
| 4 | block | ||
| 5 | c++ //c=1 | 2 | |
| 6 | get c //c=2 | ||
| 7 | get c //c=2 |
class Counter {
private int c = 0;
public synchronized increment() {
this.c++;
}
public int get() {
return c;
}
}
class Counter {
private int c = 0;
public synchronized increment() {
this.c++;
}
public int get() {
return c;
}
}A2: callers set c.s.
| time | thread A | thread B | C |
|---|---|---|---|
| 1 | get c //c=0 | 0 | |
| 2 | c++ //c=1 | 0 | |
| 3 | set c //c=1 | 1 | |
| 4 | block | ||
| 5 | get c //c=1 | 1 | |
| 6 | c++ //c=2 | 1 | |
| 7 | set c //c=2 | 2 |
public synchronized void run() {
int c = counter.get();
c++; // c--;
counter.set(c);
}
public synchronized void run() {
int c = counter.get();
c++; // c--;
counter.set(c);
}補充: blocked v.s. waiting
blocked:
outside c.s.
waiting:
in a c.s., stop and enter waiting state
對, 就是這裡
對應到資料庫呢?

先回想一下鎖的功用
wLock.lock();
try {
content += line;
} finally {
wLock.unlock();
}
tx.start()
try {
// some sql instructions
} finally {
tx.commit();
}
剛好對應上了TRANS
其實TX就是一種C.S.
問大家一個選擇題
題目:
我們操作DB時, 大部分都只是單句的CRUD,
單句的CRUD大約佔了80%的使用量,
在資料庫中, 何時會使用到tx
A. 因為是單句CRUD,所以剩下的20%使用tx
B. 100%全部都使用到tx
C. 0%使用tx, 我都直接在應用層上鎖
D. 以上皆非
乾, 完蛋,
我開始意識到生命危險
Skip~
快右滑!
其實在db內是100%使用tx
就算只有一句也是tx
default值是把auto commit=ture
所以丟進來後會自動幫忙加上tx start,tx commit
因為tx才是真正操作單位
default isolation level=Read Committed
Serialized or interleaved operations?
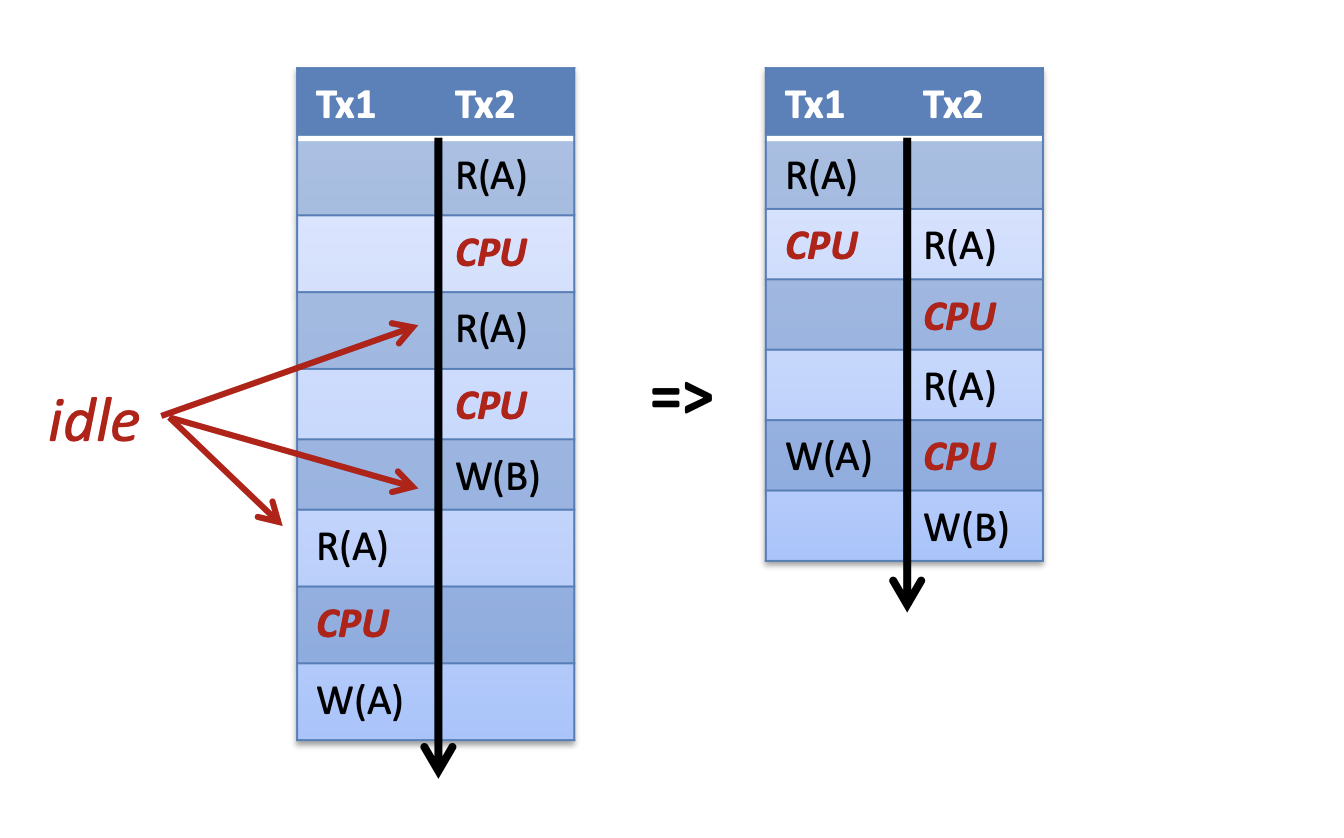
交錯的操作tx可以增加throughput
透過pipelining cpu and io
沒有你的世界
剛剛知道了,
db是multi-thread system,
為了增加throuthput,
但如果在tx內沒處理好鎖呢?


假設沒有在讀寫實作上任何鎖,將會發生甚麼事情
居然可以讀到尚未 commit 的值,
表示在做 update 的過程中,直接改到 db 上
| time | tx1 | tx2 |
|---|---|---|
| 1 | BEGIN | |
| 2 | select * from "persons" where "id"=0; | |
| 3 | BEGIN | |
| 4 | update "persons" set "name"='tx2' where "id"=0; | |
| 5 | select * from "persons" where "id"=0; //name=tx2 | |
| 6 | ROLLBACK |
發生Dirty read
沒關係, 我改!
只可以讀取commit完的資料,
沒commit的不給讀
| time | tx1 | tx2 |
|---|---|---|
| 1 | BEGIN | |
| 2 | select * from "persons" where "id"=0; | |
| 3 | BEGIN | |
| 4 | update "persons" set "name"='tx2' where "id"=0; | |
| 5 | select * from "persons" where "id"=0; //結果同上句 | |
| 6 | ROLLBACK |
But!
告訴大家只可以讀已經commit的資料
確實是只讀commit的資料,
但怎麼會同一個tx讀出的結果居然不同
發生non repeatable read
來! 我讀過後不能改
| time | tx1 | tx2 |
|---|---|---|
| 1 | BEGIN | |
| 2 | select * from "persons" where "id"=0; | |
| 3 | BEGIN | |
| 4 | update "persons" set "name"='tx2' where "id"=0; | |
| 5 | commit | |
| 6 | select * from "persons" where "id"=0; //name=tx2 |
沒關係, 我改!
只可以讀取commit完的資料,
且讀過的上鎖不給改
| time | tx1 | tx2 |
|---|---|---|
| 1 | BEGIN | |
| 2 | select * from "persons" where "id"=0; | |
| 3 | BEGIN | |
| 4 | (blocking)update "persons" set "name"='tx2' where "id"=0; | |
| 5 | select * from "persons" where "id"=0; //結果同上句 |
But!
沒關西,
我插入!
我刪除!
發生Phatom幻讀
來! 我就鎖整張表!
告訴大家只可以讀過後不能改!
| time | tx1 | tx2 |
|---|---|---|
| 1 | BEGIN | |
| 2 | select count(*) from "persons" | |
| 3 | BEGIN | |
| 4 | insert "persons" values ... | |
| 5 | commit | |
| 6 | select count(*) from "persons" |
確實是讀過的不能改,
但怎麼會同一個tx統計出來的不同
沒關係, 我改!
只可以讀取commit完的資料,
且讀過的上鎖不給改
且查詢時鎖整張表
| time | tx1 | tx2 |
|---|---|---|
| 1 | BEGIN | |
| 2 | select count(*) from "persons" | |
| 3 | BEGIN | |
| 4 | (blocking)insert "persons" values ... | |
| 5 | select count(*) from "persons" |
write skew同理(Phantom Read 的一種)
(serializable主要就是解此問題)
由剛剛的問題可以知道
如果要解決上面的問題
必須在資料或表加上鎖
捆綁上鎖
該如何上鎖呢?有哪些鎖可以使用?

IO的操作基本上分為兩類: 讀,寫
不論是對於一筆資料或一個資料表
問題目標
Semphore讀者優先範例
//common
Semphore RWMutex=Semphore(1);//讀寫控制,使讀寫互斥
int RCount=0;//Read數
Semphore RCountMutex=Semphore(1);//Read數控制// Writer
void Writer(){
P(RWMutex)
write()
V(RWMutex)
}
單純寫時上鎖,
寫完解鎖
void Reader(){
P(RCountMutex);
if(RcountMutex==0){
P(RWMutex); //要求讀取權限
}
RCount++;
V(RCountMutex);
read()
P(RCountMutex);
RCount--;
if(RcountMutex==0){
V(RWMutex); //釋放讀取權限
}
V(RCountMutex);
}讀時紀錄有幾個讀,
全部讀完才釋放
類型有三種:
- 讀者優先
- 寫者優先
- 讀寫公平
問題:
讀者優先,
只要一直有讀,
寫就進不來(飢餓)
規則:
- R+R=>OK
- R+W=X
- W+W=X
上鎖的規則
歸納出一個結論
1. 寫寫互斥 - 寫的過程中不給其他tx寫
2. 讀寫互斥 - 讀的過程中不給其他tx寫
3. 讀讀不互斥 - 反正都讀一樣的資料
4. 寫大於讀 - 寫的限制大於讀, 讀鎖可以升級寫鎖, 反之亦然
基本上可以分為兩類鎖:
1. 讀鎖:
讀時可以讓其他tx讀, 但不可以讓其他tx讀寫
2. 寫鎖:
寫時不可以讓其他tx讀寫
這就是鼎鼎大名的
2PL(Two-Phase Locking)
2PL 協議將事務分爲兩部分:
-
擴展階段(獲取鎖,並且不允許釋放鎖)
-
收縮階段(釋放所有鎖,並且無法進一步獲取其他鎖)。
意味著?
Starvation=>
S2PL(Strict Two-Phase Locking)
Lock Table
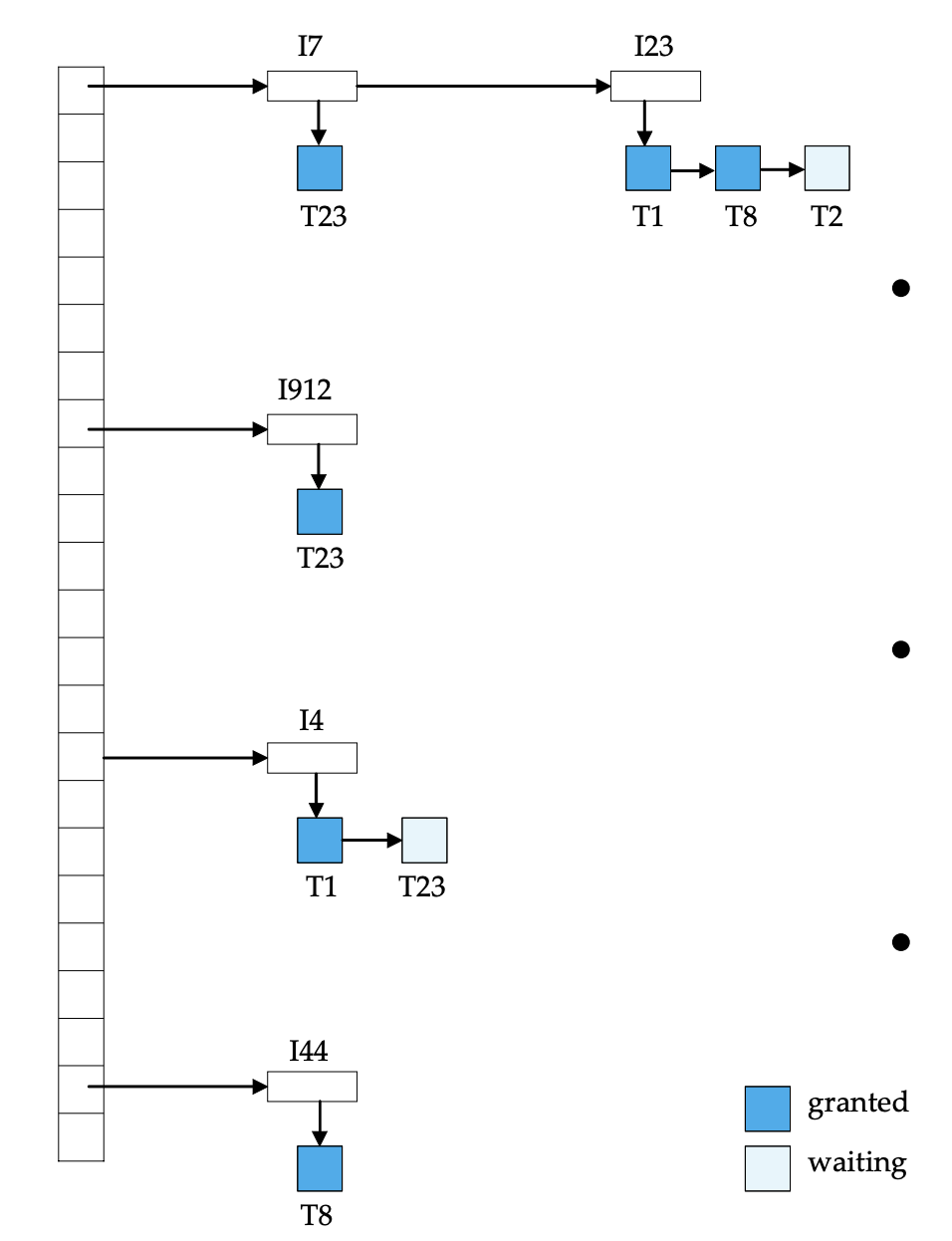
鎖上一筆紀錄
使用讀寫鎖上鎖
讀鎖: S(), Shared (S) lock
寫鎖: X(), Exclusive (X) lock
鎖上一個範圍呢?
鎖上一個範圍呢?
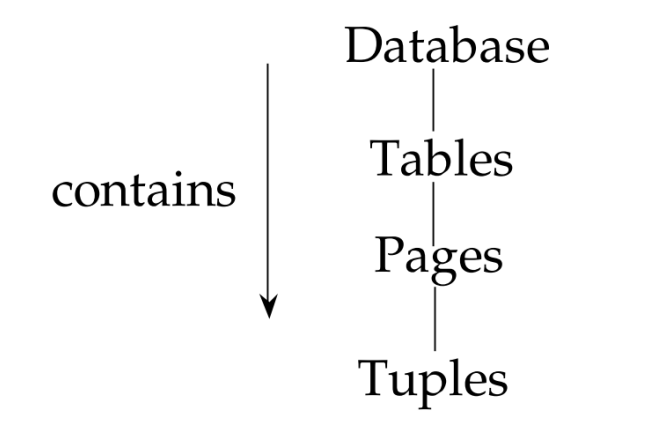
lock granularity (lock 粒度)
multiple granularity locking (MGL)
DB=DB
Table=Table
Pages=records
Tuples=record

先知道鎖一個records
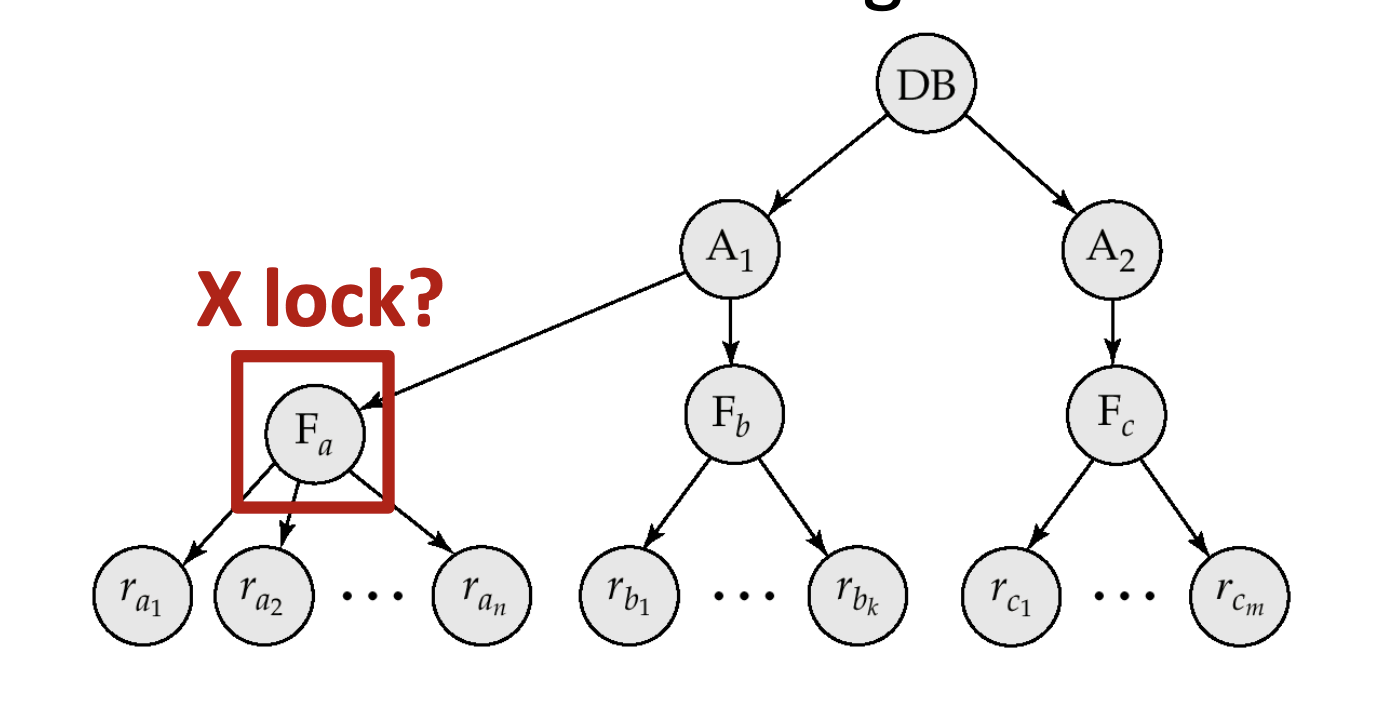
實做一下IS,IX
Tx1(blue): wants to share-lock a record
Tx2(green): wants to exclusive-lock a file
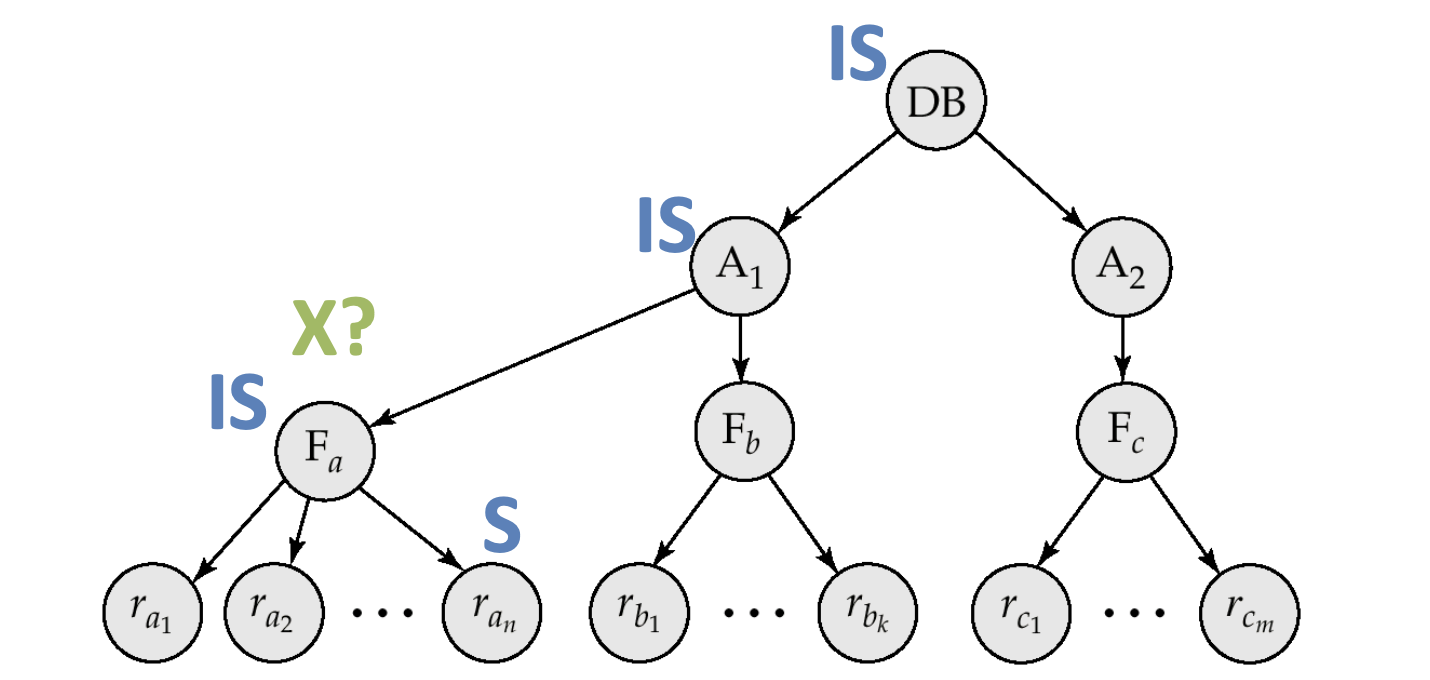
Locks need to be released in leaf-to-root orde
Intention-shared (IS) 意向共享鎖
Intention-exclusive (IX) 意向互斥鎖
隔離層級
透過這些鎖我們就可以時做出隔離層級,
並解決剛剛提出的問題
| level | read | update/delete | insert |
|---|---|---|---|
| Read UnCommit | no | IX File,Block; X Record; |
X File,Block,Record; |
| Read Commit | IS File,Block,Record=>release; S Record=>release |
IX File,Block; X Record; |
X File,Block,Record; |
| Repeatable Read | IS File,Block,Record=>release; S Record | IX File,Block; X Record; |
X File,Block,Record; |
| Serializable | IS File,Block; S Record; |
IX File,Block; X Record; |
X File,Block,Record; |
| level | dirty reads | Unrepeatable read | phantoms |
|---|---|---|---|
| Read UnCommit | T | T | T |
| Read Commit | F | T | T |
| Repeatable Read | F | F | T |
| Serializable | F | F | F |
由該表可知
Read commit: 只讀有commit過的, 解決了dirty read
Repeatable: 讀過的不能改,解決了Nonrepeatable
Serializable: 使用過的地方會標上標記, 解決了Phantom
| level | dirty reads | Unrepeatable read | phantoms |
|---|---|---|---|
| Read UnCommit | T | T | T |
| Read Commit | F | T | T |
| Repeatable Read | F | F | T |
| Serializable | F | F | F |
isolation level並不是避免race condition的出現,
而是對於race condition side effect的最大容忍程度
讓 Race condition 發生後不出現「致命錯誤」,讓系統向不致命的方向發生錯誤
Title Text
Subtitle

分類一下鎖
兩位小鎖匠

這是一個鎖匠的故事, 在很久很久以前......有兩個鎖匠

第一個鎖.......
DB lock
-
悲觀鎖(Pessimistic Lock)
-
隱式鎖
-
顯示鎖
-
什麼是隱式鎖
就是剛剛講的isolation level
db預設幫你加上的
什麼是顯式鎖?
自己加上的鎖
e.g.
select ... for share
select .... for update
為什麼需要顯式鎖-舉個例子1
Conflict promotion:
在read commit level 想要讀過不能改, 即加上s lock
e.g. 購物系統中, 賣太好, 想中途改變價格
1. 前面訂的要算數, 且是原價
2. 正在進行中的交易不能開價到結帳不同
| time | tx1 | tx2 |
|---|---|---|
| 1 | BEGIN TRANSACTION ISOLATION LEVEL READ COMMITTED; | |
| 2 | select * from "product" where "id"=0 for share; | |
| 3 | BEGIN ... READ COMMITTED; | |
| 4 | update inventory set balance = balance-1 | (blocking or not)update "product" set "price"='100' where "id"=0; |
| 5 | commit |
為什麼需要顯式鎖-舉個例子2
Conflict materialization:
在read commit level 想要插入新資料不照成rr problem,
即加上x lock
e.g. 商品系統中, 想中途改加上該商品的更多細節
1. 正在進行中的不能讀兩次都不同
| time | tx1 | tx2 |
|---|---|---|
| 1 | BEGIN TRANSACTION ISOLATION LEVEL READ COMMITTED; | |
| 2 | select * from "product" where "id"=0 for share; | BEGIN ... READ COMMITTED; |
| 3 | (blocking or not) Select * from "product" where "id"=0 for update; | |
| 4 | select * from "product_detail" where "id"=0; | |
| 5 | commit | |
| 6 | insert "product_detail" .... |
為什麼需要顯式鎖
盡量統一隔離層級,如果有特殊需要,自行加上鎖;
大部分的應用都是Read Committed 中使用 Conflict promotion + Conflict materialization
便足夠了,不建議用更高階的 isolation
有悲觀鎖?有樂觀鎖嗎?

悲
觀
鎖
樂
觀
鎖
樂觀鎖( Optimistic Lock)
有多樂觀?
樂觀能解決問題嗎?
| id | name | num |
|---|---|---|
| 1 | iphone | 10 |
一般的表
樂觀鎖- 先看悲觀實例
| id | name | num |
|---|---|---|
| 1 | iphone | 10 |
一般的products表
begin
// 讓其他tx不可讀寫
select num from products where id=1 for update
//更新數量
update products set num=num-1 where id=1
//查詢最後剩餘多少
select num from products
commit
其他tx在select時就會block住了(轉圈圈),
直到第一個tx釋放鎖後開始執行
樂觀鎖- 先看樂觀實例
| id | name | num | version |
|---|---|---|---|
| 1 | iphone | 10 | 0 |
加上version(or timestamp) 的 products表
begin
select num from products where id=1 //version=0
update products set num=num-1, version=version+1 \
where id=1 and version=0
select num from products
commit
其他tx在select時會取得相同version
但更新時where不到version=0
所以就更新0筆記錄
過程中完全沒上
任何顯式鎖
樂觀鎖是好的方案嗎?
對於db演進的發展
先拉回來我們剛剛認識的db
等等...那隱式鎖呢?
等等...那不就是說R會block U?
等等...那不就是說會常常deadlock?
等等...那把commit的時間點拉長不就gg了
完了丸了八比Q了
先拉回來我們剛剛認識的db

Timeout & rollack (deadlock detection)
Wait-die (deadlock prevention)
陪你一起學習學校沒教的知識

好像沒真的被鎖上誒?
-
MVCC 的資料庫的 Record 只有 X lock ,而沒有 S lock 的
-
MVCC 在讀取時,會讀最該 Record 「最新」的 Committed 版本,所以自然地沒有了 Dirty Read
-
因為讀不會被阻擋, 所以只有write-werit confliet
類似剛剛的樂觀鎖,在資料表上加上version欄位,
每次的insert/update都會額外增加版本
當前讀
MVCC 實作- postgres 為例0
其實Pg每個表中都有一些隱藏欄位
(如要顯示,要在create table時with oids)
| 欄位 | 代表意思 |
|---|---|
| oid | resourceId(table,index, view,record....都有的id) |
| ctid | (ItemPointer), 在表中的物理位置 |
| xmin | born 建立record時, 當前tx的id |
| xmax | die 刪除record時, 當前tx的id, default=0 |
| cmin | 當前tx最早的txid, 從0開始 |
| cmax | 下個tx進來取的號碼牌 |
MVCC 實作- postgres 為例1-insert
| ctid | xmin | xmax | cmin | cmax | oid | id | clog | ||
|---|---|---|---|---|---|---|---|---|---|
| (0,1) | 80853357 | 0 | 0 | 0 | 17569 | 1 | 0x01 | 已提交 | |
| (0,2) | 80853358 | 0 | 0 | 0 | 17570 | 2 | 0x01 | 已提交 | |
| (0,3) | 80853359 | 0 | 0 | 0 | 17571 | 3 | 0x01 | 已提交 |
insert 3筆記錄
那該如何判斷該record有效呢?
pg把tx的狀態記錄到clog (commit log)中,
每讀一行就會到該文件檢查tx的狀態, 狀態如下
- #define TRANSACTION_STATUS_IN_PROGRESS=0x00 正在进行中
- #define TRANSACTION_STATUS_COMMITTED=0x01 已提交
- #define TRANSACTION_STATUS_COMMITTED=0x02 已回滚
- #define TRANSACTION_STATUS_SUB_COMMITTED=0x03 子事务已提交
MVCC 實作- postgres 為例2-update
begin
select txid_current() //80853360
update t1 set id=4 where id=1
| ctid | xmin | xmax | cmin | cmax | oid | id | clog | ||
|---|---|---|---|---|---|---|---|---|---|
| (0,1) | 80853357 | 80853360 | 0 | 0 | 17569 | 1 | 0x00 | 進行中 | |
| (0,2) | 80853358 | 0 | 0 | 0 | 17570 | 2 | 0x01 | 已提交 | |
| (0,3) | 80853359 | 0 | 0 | 0 | 17571 | 3 | 0x01 | 已提交 | |
| (0,4) | 80853360 | 0 | 0 | 0 | 17569 | 4 | 0x00 | 進行中 |
tx2=80853361
tx1= 80853360
MVCC 實作- postgres 為例3-delete
delete from t1 where id=2
| ctid | xmin | xmax | cmin | cmax | oid | id |
|---|---|---|---|---|---|---|
| (0,1) | 80853357 | 80853360 | 0 | 0 | 17569 | 1 |
| (0,2) | 80853358 | 80853360 | 1 | 1 | 17570 | 2 |
| (0,3) | 80853359 | 0 | 0 | 0 | 17571 | 3 |
tx2=80853361
tx1= 80853360
由此可知: PG在做delete,udpate時,並不會真的刪除,更新.
更新: 而是插入新的tuple(record)後, 把原紀錄標記刪除
刪除: 把原紀錄標記刪除
由tx2可以看到之前版本的信息(都是用標記的),
不同tx擁有各自的數據空間 ,
不會對彼此產生干擾, 保證事務的隔離性
| ctid | xmin | xmax | cmin | cmax | oid | id | clog | ||
|---|---|---|---|---|---|---|---|---|---|
| (0,1) | 80853357 | 80853360 | 0 | 0 | 17569 | 1 | 0x00 | 進行中 | |
| (0,2) | 80853358 | 80853360 | 1 | 1 | 17570 | 2 | 0x00 | 進行中 | |
| (0,3) | 80853359 | 0 | 0 | 0 | 17571 | 3 | 0x01 | 已提交 | |
| (0,4) | 80853360 | 0 | 0 | 0 | 17569 | 4 | 0x00 | 進行中 |
MVCC 實作- postgres為例4-tx1 commit後
commit
tx1= 80853360
commit後,寫入in memory 內的東西
有xmax的刪除掉,
新增的ctdi存起來
| ctid | xmin | xmax | cmin | cmax | oid | id | clog | ||
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | ||||||||
| (0,3) | 80853359 | 0 | 0 | 0 | 17571 | 3 | 0x01 | 已提交 | |
| (0,4) | 80853360 | 0 | 0 | 0 | 17569 | 4 | 0x01 | 已提交 |
MVCC 實作- postgres為例4-tx1 rollback後
rollback
tx1= 80853360
rollback後,把in memory內的東西drop掉
但, xmax居然沒還原回去
| ctid | xmin | xmax | cmin | cmax | oid | id |
|---|---|---|---|---|---|---|
| (0,1) | 80853357 | 80853360 | 0 | 0 | 17569 | 1 |
| (0,2) | 80853358 | 80853360 | 1 | 1 | 17570 | 2 |
| (0,3) | 80853359 | 0 | 0 | 0 | 17571 | 3 |
基於效率的原因, 如果rollback也清除標記,
就變成要找到該列, 更新,(非整個record的操作)降低了效能
| ctid | xmin | xmax | cmin | cmax | oid | id | clog | ||
|---|---|---|---|---|---|---|---|---|---|
| (0,1) | 80853357 | 80853360 | 0 | 0 | 17569 | 1 | 0x02 | 已回滚 | |
| (0,2) | 80853358 | 80853360 | 1 | 1 | 17570 | 2 | 0x02 | 已回滚 | |
| (0,3) | 80853359 | 0 | 0 | 0 | 17571 | 3 | 0x01 | 已提交 | |
| 0 | 0 | 0 | 0x00 | 已回滚 |
MVCC 實作- postgres為例4-tx1 rollback後
| ctid | xmin | xmax | cmin | cmax | oid | id |
|---|---|---|---|---|---|---|
| (0,1) | 80853357 | 80853360 | 0 | 0 | 17569 | 1 |
| (0,2) | 80853358 | 80853360 | 1 | 1 | 17570 | 2 |
| (0,3) | 80853359 | 0 | 0 | 0 | 17571 | 3 |
基於效率的原因, 如果rollback也清除標記,
就變成要找到該列, 更新,(非整個record的操作)降低了效能
MVCC 實作- postgres為例5-
rollback垃圾問題

MVCC 實作- postgres為例5-
rollback垃圾問題
| ctid | xmin | xmax | cmin | cmax | oid | id |
|---|---|---|---|---|---|---|
| (0,1) | 80853357 | 80853360 | 0 | 0 | 17569 | 1 |
| (0,2) | 80853358 | 80853360 | 1 | 1 | 17570 | 2 |
| (0,3) | 80853359 | 0 | 0 | 0 | 17571 | 3 |
可以看到
ctid(0,1)更新操作下遺留的標記
ctid(0,2)刪除操作下留下的標記
頻繁操作的表會累積大量標記, 佔用硬碟空間
PG的解決方法是提供vacuum命令來清理過期的數據(下集待續)
兩種 isolation 流派
SX lock 和 MVCC 都能逹到 Isolation 目的,
MVCC: PostgreSQL, Oracle
SX lock: MySQL, MSSQL
因為其底層機制不同,所以雖然大家都說自己支持 ACID ,
支持 4個 isolation level ,其 isolation 的行為卻有所不同
MySQL 和 MSSQL 近年試圖在其 SX lock 架構上再加上 MVCC (😱
SX lock 還是 MVCC?
在高流量環境, MVCC 比較高效能。
因為 MVCC 的 READ 永遠不被阻擋,
同一時間資料庫能處理更多的 TX
MVCC 只有 X lock 而沒有 S lock ,
其 Deadlock detector 要管理的 lock 的數目一定更少,
所以一定比較快
只考慮一個 TX , MVCC 使用比較多的 IO 還有 CPU ,所以比 較花時間
1. 決定那個版本才是「最新」 2. 管理舊的版本的刪除
MVCC is type of Optimistic Lock?
Yes!
Two widely known algorithms of
optimistic concurrency control are:
begin~commit的時間很長
SX lock:
更新某資料後就卡死,無法讀取,且容易deadlock
MVCC :
更新某資料後, 仍然可讀,
但如加上顯式鎖仍然如同SX lock
Mysql RR problem
Mysql RR problem
(5.7,8.0可重現)
RR本來就不防幻讀,
如果有人跟你說mysql RR發生幻讀,
你要跟他說每個db的RR都會發生幻讀
RR是防止同一列讀第二次數值不同.
理想上read/write會抓到同一個版本的值,而非最新commit點. mysql只符合read version相同.
MVCC 實作- Mysql為例0
Mysql 會在每筆紀錄的最後加上trx_id,
來紀錄最後一次修改該row的交易ID
| id | name | num | (trx_id) |
|---|---|---|---|
| 1 | iphone | 10 | 0 |
假設此筆資料為建立table時隨之建立的,
所以trx_id=0 (不是重點)
當下select指令時, 會產生一個叫ReadView(snapshot)的表
| 欄位 | 代表意思 |
|---|---|
| m_ids | 當前還沒commit/rollback的tx_ids |
| min_trx_id | 最小的m_ids(最早的tx) |
| max_trx_id | 下一個tx_id的號碼牌 |
| creator_trx_id | 創建此ReadView的txId |
MVCC 實作- Mysql為例0-ReadView
| 欄位 | 代表意思 |
|---|---|
| m_ids | 當前還沒commit/rollback的tx_ids |
| min_trx_id | 最小的m_ids(最早的tx) |
| max_trx_id | 下一個tx_id的號碼牌 |
| creator_trx_id | 創建此ReadView的txId |
會透過以下四個if來決定該record是否該被當前tx看到
| 判斷 | 代表意思 | 可否讀 |
|---|---|---|
| trx_id=creator_trx_id | 該readview是自己建立的 | 可 |
| trx_id<min_trx_id | 已經commit過的tx | 可 |
| trx_id>max_trx_id | 該row是此readView出生後才建立的 | 不可 |
| min_trx_id< trx_id<max_trx_id |
看trx_id是否在m_ids中 存在: 尚未commit=>不可讀 不存在: 已經commit=>可讀 |
存在: 不可 不存在: 可 |
該row的
MVCC 實作- Mysql為例0-ReadView
看到問題了嗎?
只有對read做mvvc
MVCC 實作- Mysql為例-RR problem
| time | tx1 | tx2 |
|---|---|---|
| 1 | tx(RR) | |
| 2 | select num from products where id=1 | |
| 3 | tx(RR) | |
| 4 | select num from products where id=1 | |
| 5 | Update products set num=num-10 where id=1 //10-10=0 |
|
| 6 | commit | |
| 7 | Update products set num=num-5 where id=1 //理應10-5=5, 但發生了0-5=-5 |
這裡pg會throw error |
| 8 | commit |
快照讀, 當前寫
Q: why time 5 is ok? mvvc即為不加鎖的讀
解法: for update or DIY Optimistic Lock
MVCC 實作- 此範例如果在pg呢?
| time | tx1 | tx2 |
|---|---|---|
| 1 | tx(RR) | |
| 2 | select num from products where id=1 | |
| 3 | tx(RR) | |
| 4 | select num from products where id=1 | |
| 5 | Update products set num=num-10 where id=1 | |
| 6 | commit | |
| 7 | Update products set num=num-5 where id=1 | |
| 8 | commit |
| ctid | xmin | xmax | cmin | cmax | oid | id | num |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | |||||
| (0,2) | 753 | 0 | 0 | 0 | 17569 | 1 | 0 |
tx2=753
throw error
| ctid | xmin | xmax | cmin | cmax | oid | id | num |
|---|---|---|---|---|---|---|---|
|
|
0 | 0 | 1 | ||||
| x | 0 | 0 | 1 |
tx1=754

任何本質上是SX lock
但又自稱支援MVCC的RDBMS,
抱持欣賞的態度.
請自求多福了......
我們一起去惹
分散式鎖

CAP定理

C-onsistency: (Strong Consistency): 強一致性(每次讀到都最新)
A-vailability: 系統不會返回錯誤(不保證都最新 e.g. 斷路器模式(Circuit Breaker))
P-artition Tolerance: 就算腦裂(Split-brain)可正常運作可復原 e.g. 斷線
note: A這裡的錯誤是系統錯誤(網路,溝通), 其他沒錯的情況下
CAP定理
"在分散式系統中,
不可能同時滿足上面三個性質,最多只能同時滿足兩個。"
C3取2=3 所以有三種選擇
CAP定理
C-onsistency: (Strong Consistency): 強一致性(每次讀到都最新)
A-vailability: 系統不會返回錯誤(不保證都最新 e.g. 斷路器模式(Circuit Breaker))
P-artition Tolerance: 就算腦裂(Split-brain)可正常運作可復原 e.g. 斷線
CA:
求: 強一致性且不返回錯誤=>只有單機可符合
CP:
求: 強一致性且腦裂可正常運作=>常常會傳掉線
AP:
求: 系統不會返回錯誤且腦裂可正常運作=>結果可能不是最新的
NoSQL Database,強調的就是Availablity,也就是系統保證運作,但是可能返回的結果不是最新的
BASE 介紹
B-asically A-vailable:
服務基本上保持可用( CAP 的A-vailable一樣的概念)
S-oft State:
Hard-State, 同等於Strong Consistency,反之Soft-State就是非大家都統一
E-ventual consistency:
偏向CAP的Consistency, 最終一致性
BASE原則是根據CAP的AP原則演變而來,
NoSql通常遵守BASE, 而非ACID 強項不同

一開始覺得很奇怪,
後面覺得還不錯?
這個感覺就對了
BASE 介紹
ACID 介紹
1. Atomicity:
* 一次全成功或全失敗
2. Consistency: 非CAP的C(Strong Consistency)
- 每次commit後都符合db Constraint
- E.g., posts.authorId must be a valid users.id
3. Isolation:
- Concurrent txs = serial txs (in some order)
4.Durability:
- commit後就不會在遺失(就算事後發生crashs)
2PC
(2 Phase Commitment)
分布式交易強一致性 CP
Strong Consistency
P-artition Tolerance
這是一個拜占庭將軍的故事

我們稱拜占庭將軍問題
(Byzantine Generals Problem)

大家開始進攻!
大家開始進攻!
我還沒準備好Q
rollback
大家開始進攻!
大家開始進攻!
大家開始進攻!
prepare
殺阿!commit
殺阿!commit
殺阿!commit
commit
請給我木頭
準備就緒
請給我石頭
end
準備就緒
準備就緒
準備就緒
begin
叛徒?
2PC介紹
原本的tx
2pc的tx
begin
...
commit
-- rollbackbegin
...
end
...
prepare TRANSACTION 'T1'
...
commit prepared 'T1'
-- rollback prepared 'T1'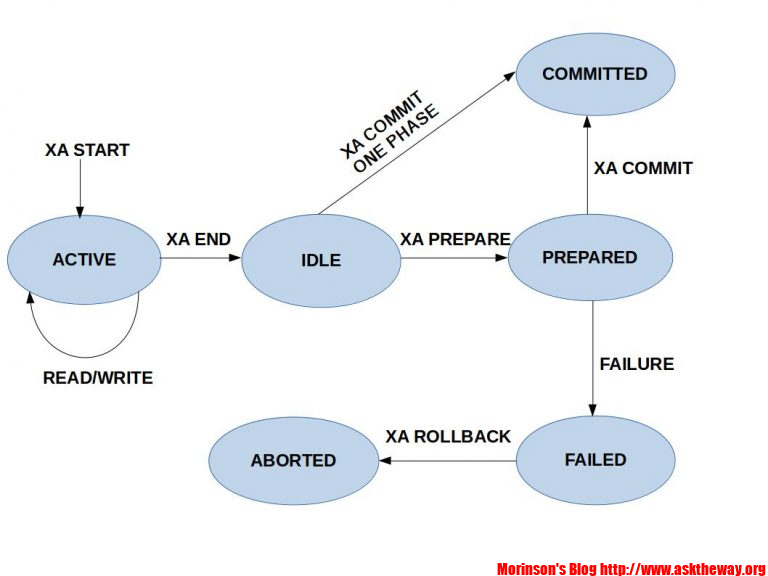
2PC介紹-範例
假設有兩個db,
一個國泰世華(cathaybk),
一個中國信託(ctbc)
兩個db都有一張cash_account的table,
今天想要從國泰世華轉帳1000元到中國信託
cathaybk.cash_account =>ctbc.cash_account
-- DB cathaybk
-- Table cash_account
+--------+---------+
| name | balance |
+--------+---------+
| Mike | 1000 |
| Error | 9999999 |
+--------+---------+-- DB ctbc
-- Table cash_account
+--------+---------+
| name | balance |
+--------+---------+
| Mike | 0 |
| Error | 9999999 |
+--------+---------+2PC介紹-範例
-- DB cathaybk
-- Table cash_account
+--------+---------+
| name | balance |
+--------+---------+
| Mike | 1000 |
| Error | 9999999 |
+--------+---------+-- DB ctbc
-- Table cash_account
+--------+---------+
| name | balance |
+--------+---------+
| Mike | 0 |
| Error | 9999999 |
+--------+---------+begin
update cash_account set balance=balance-1000 where name=Mike
end
prepare TRANSACTION 'T1'begin
update cash_account set balance=balance+1000 where name=Mike
end
prepare TRANSACTION 'T1'
commit prepared 'T1'commit prepared 'T1'如果兩tx其中一個再進入prepare前發生錯誤, 就可以rollback
世上只有一種一致性算法Paxos,
所有其他一致性算法都是Paxos算法的不完整版。
ACD of Sagas
下次講分散式系統時再補充XD
謝謝大家
Q&A+工商時間
DDIA放在後面呦~
歷史不是讓我們記住仇恨,而是學會各個環境下的人性
DB不單讓我們學會操控DB,而是學會設計App的精隨


DB Lock v2
By Shen Hoh




