编译原理基础
陈景辉


为什么要学习编译原理
-
编译原理是一门基础理论学科,学习了编译原理,可以知道编译器是如何工作的。
-
当下的开发流程基本都要有编译的过程,编译原理已经成为Babel, Eslint, Pug, Vue等技术的理论基石之一。




大致流程
-
词法解析
-
语法解析
-
代码优化
-
目标代码生成
&&
错误处理
小目标
const str = `texto ~
<div Class="wrapper" id='root'>
<h1>I'm h1 tag</h1>
<input />
</div>
`
let lexer = new Lexer()
const tokens = lexer.lex(str)
const ast = new Parser().parse(tokens)
const code = codeGenerate(ast)分别实现简单的Lexer,Parser和codeGenerate。
词法分析
词法分析(lexical analysis)是将字符序列(源码)转换为词法单元(token)序列的过程。进行词法分析的函数叫作词法分析器(简称lexer)。词法分析器的输出是一个token队列,供语法分析器调用。
词法分析通常基于有限状态自动机。词法分析器能够识别其所能处理的标记中可能包含的所有字符序列。例如“整数”标记可以包含所有数字字符序列。
词法单元,模式,词素
- 词法单元:由词法单元名和可选的属性值组成。词法单元名将影响语法分析过程中的决定,而属性值将影响语法分析之后对这个词法单元的翻译(具体翻译成哪一个词素)。
- 模式:描述一个词法单元的词素可能具有的形式,通常使用正则表达式进行定义。
- 词素:是一个字符串,它和某个词法单元的模式匹配,并被词法分析器识别为该词法单元的一个实例。
// 模式,描述了词素所有可能情况,一般是正则表达式
const TAG_OPEN = /^<([a-zA-Z][\w\-\.]*)\s*/
const TAG_ATTRIBUTE = /^([-0-9a-zA-Z]+)(=('([^']*)'|"([^"]*)"))?\s*/
const TAG_END = /^(\/?)>/
const TAG_CLOSE = /^<\/([a-zA-Z][\w\-\.]*)>/
const TEXT = /^[^\x00]|</
const WHITE_SPACE = /^\s+/
// 词法单元,由词法单元类型和可选的属性值组成
{
type: 'TAG_OPEN',
value: 'div'
}
// 同是TAG_OPEN,但可以通过value区分
{
type: 'TAG_OPEN',
value: 'p'
}
{
type: 'EOF'
}
// 词素,和TAG_OPEN的模式匹配
<div <p 有限状态机
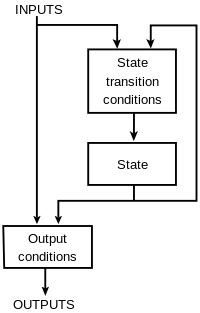
有限状态机,简称状态机,是表示有限个状态以及在这些状态之间的转移和动作等行为的数学模型。
有限状态机有三个特点:
- 状态总数(state)是有限的。
- 任一时刻,只处在一种状态之中。
- 某种条件下,会从一种状态转变(transition)到另一种状态。
状态转换表
| 当前状态→ 条件↓ |
start | tagOpen |
|---|---|---|
| whitespace | - | - |
| tagOpen | tagOpen | - |
| tagEnd | - | start |
| attribute | - | - |
| tagClose | - | - |
| text | - | - |
- start是初始状态,tagOpen状态表示当前正在解析html标签。
- 这里的条件指下一个token的类型。
class Lexer {
tagOpen(){
const matched = this.match('TAG_OPEN')
if(matched){
this.state.enter('tagOpen')
this.input = this.input.slice(matched[0].length)
return new Token('TAG_OPEN', matched[1])
}
}
attribute(){
// 非tagOpen状态不匹配attribute
if(!this.state.is('tagOpen')) return
}
tagEnd(){
if(!this.state.is('tagOpen')) return
const matched = this.match('TAG_END')
if(matched){
// 离开 tagOpen状态
this.state.leave('tagOpen')
}
}
text(){
// tagOpen 不匹配 text
if(this.state.is('tagOpen')) return
// ...
}
}Lexer根据状态正确生成token
ReGEpx.exec
const TAG_OPEN = /^<([a-zA-Z][\w\-\.]*)\s*/
const TAG_END = /^(\/?)>/
class Lexer{
match(type){
if(!pattern[type]) return
return pattern[type].exec(this.input)
}
}
// TAG_OPEN.exec('<div')
// ["<div", "div", index: 0, input: "<div", groups: undefined]
// TAG_END.exec('/>')
// ["/>", "/", index: 0, input: "/>", groups: undefined]
class Lexer {
constructor(){
this.tokens = []
this.index = 0
this.state = new State()
this.state.enter('start')
}
// 启动状态机的方法
lex(input){
this.input = input
let token = this.advance()
while(token && token.type !== 'EOF'){
this.tokens.push(token)
token = this.advance()
}
this.tokens.push(new Token('EOF'))
return this.tokens
}
// 将当前字符串尝试解析成任意一种可能的token
advance(){
const token =
this.eof() ||
this.whitespace() ||
this.tagOpen() ||
this.attribute() ||
this.tagEnd() ||
this.tagClose() ||
this.text()
return token
}
}
module.exports = Lexer通过lex方法启动状态机
[ Token { type: 'TEXT', value: 'texto ~\n' },
Token { type: 'TAG_OPEN', value: 'div' },
Token {
type: 'TAG_ATTRIBUTE',
value: { name: 'Class', value: 'wrapper' } },
Token { type: 'TAG_ATTRIBUTE', value: { name: 'id', value: 'root' } },
Token { type: 'TAG_END', value: { isSelfClosed: false } },
Token { type: 'WHITE_SPACE', value: '\n ' },
Token { type: 'TAG_OPEN', value: 'h1' },
Token { type: 'TAG_END', value: { isSelfClosed: false } },
Token { type: 'TEXT', value: 'I\'m h1 tag' },
Token { type: 'TAG_CLOSE', value: 'h1' },
Token { type: 'WHITE_SPACE', value: '\n ' },
Token { type: 'TAG_OPEN', value: 'input' },
Token { type: 'TAG_END', value: { isSelfClosed: true } },
Token { type: 'WHITE_SPACE', value: '\n' },
Token { type: 'TAG_CLOSE', value: 'div' },
Token { type: 'WHITE_SPACE', value: '\n' },
Token { type: 'EOF' } ]Lexer的输出
const str = `texto ~
<div Class="wrapper" id='root'>
<h1>I'm h1 tag</h1>
<input />
</div>
`语法分析
形式文法
形式文法G是下述元素构成的一个四元组(N, Σ, P, S):
- “非终结符号”集合N。
- “终结符号”集合Σ,Σ与N无交。
- 一组“产生式规则” P,(Σ ∪ N)*中的字符串→ (Σ ∪ N)* 中的字符串,并且产生式左侧的字符串中必须至少包括一个非终结符号。
- “起始符号”S,S属于N。
例子
考虑如下的文法G,其中N = {S, B}, Σ = {a, b, c}, P包含下述规则
1. S -> aBSc
2. S -> abc
3. Ba -> aB
4. Bb -> bb
非终结符号S作为初始符号。下面给出字串推导的例子:(推导使用的产生式规则用括号标出,替换的字串用黑体标出)
- S -> (2) abc
- S -> (1) aBSc -> (2) aBabcc -> (3) aaBbcc -> (4) aabbcc
- S -> (1) aBSc -> (1) aBaBScc -> (2) aBaBabccc -> (3) aaBBabccc -> (3) aaBaBbccc -> (3) aaaBBbccc -> (4) aaaBbbccc -> (4) aaabbbccc
很清楚这个文法定义了语言{ anbncn | n > 0 },这里an表示n个a 串连所得的字串。
对应的形式文法
PROGRAM → STATEMENTS
STATEMENTS → STATEMENT*
STATEMENT → TAG | TEXT
ATTRIBUTE → attribut*
TAG → tagOpen ATTRIBUTE? tagEnd (STATEMENTS tagClose)?
TEXT → (text | whitespace)*
PROGRAM是起始符号,属于非终结符。
N={PROGRAM, STATEMENTS, STATEMENT, TAG, TEXT, ATTRIBUTE}
Σ = {tagOpen, tagEnd, tagClose, text, whitespace, attribute}
P包含如下规则:
class Parser {
constructor(){
this.index = 0
}
statements(){
let root = []
while(this.peek().type !== 'EOF'
&& this.peek().type !== 'TAG_CLOSE'
){
const statement = this.statement()
if(statement){
root.push(statement)
}
}
return root
}
statement(){
const token = this.peek()
switch(token.type){
case 'TAG_OPEN':
return this.tag()
case 'TEXT':
case 'WHITE_SPACE':
return this.text()
default:
console.error(`Unexpected token: ${token.type}`)
return
}
}
tag(){
const token = this.peek()
function Tag(name){
return {
type: 'Tag',
name: name,
attributes: {}
}
}
let node = Tag(token.value)
this.consume()
// handle attributes
while ( this.peek().type === 'TAG_ATTRIBUTE') {
node.attributes[ this.peek().value.name ] = this.peek().value.value
this.consume()
}
if(this.peek().type !== 'TAG_END'){
console.error(`Parser Error. Expect token 'TAG_END', got ${this.peek().type}`)
}
// consume tagEnd
if(this.peek().value.isSelfClosed){
node.isSelfClosed = true
this.consume()
return node
}
node.isSelfClosed = false
this.consume()
node.children = this.statements() || []
if(this.peek().value !== node.name){
console.error(`Unexpected close tag ${this.peek().value}, expected ${node.name}`)
}
this.consume()
return node
}
text(){
let text = ''
while(this.peek().type === 'TEXT' || this.peek().type === 'WHITE_SPACE'){
text += this.peek().value
this.consume()
}
const node = {
type: 'Text',
value: text
}
return node
}
}
module.exports = ParserParser.js中部分生成AST节点的方法
class Parser {
peek(){
return this.tokens[this.index]
}
}递归下降的解析(TOP-DOWN PARSER)
每个生成AST节点的方法都会先调用peek方法获取将要解析的token,根据token的类型决定生成哪种AST节点。因为这种Parser 在运行时每次都要至少向前看一个符号才能决定用哪个生产式,因此也可以叫做预测解析器(Predict parser)。
同时因为它总是把左边先看到的符合产生式的一串符号构建成一个语法树,所以也叫LL(k) Parsing,其中第二个L就是最左推导的意思,而k 是指最多向前看几个符号。比如我们的Parser就是一个LL(1) Parser。
{
"type": "Program",
"body": [
{
"type": "Text",
"value": "texto ~\n"
},
{
"type": "Tag",
"name": "div",
"attributes": {
"Class": "wrapper",
"id": "root"
},
"isSelfClosed": false,
"children": [
{
"type": "Text",
"value": "\n "
},
{
"type": "Tag",
"name": "h1",
"attributes": {},
"isSelfClosed": false,
"children": [
{
"type": "Text",
"value": "I'm h1 tag"
}
]
},
{
"type": "Text",
"value": "\n "
},
{
"type": "Tag",
"name": "input",
"attributes": {},
"isSelfClosed": true
},
{
"type": "Text",
"value": "\n"
}
]
},
{
"type": "Text",
"value": "\n"
}
]
}Parser输出的AST
代码优化
代码优化是指对程序代码进行等价变换。在不改变程序运行效果的前提下,使之能生成更加高效的目标代码。
<div>
<header>
<h1>I'm a template!</h1>
</header>
<p v-if="message">
{{ message }}
</p>
</div>// render
function anonymous(
) {
with(this){return _c('div',[_m(0),(message)?_c('p',[_v(_s(message))]):_e()])}
}
// staticRenderFns:
_m(0): function anonymous(
) {
with(this){return _c('header',[_c('h1',[_v("I'm a template!")])])}
}// vue/src/compiler/optimizer.js
export function optimize (root: ?ASTElement, options: CompilerOptions) {
if (!root) return
markStatic(root)
markStaticRoots(root, false)
}目标代码生成
目标代码生成是遍历AST并生成最终代码的过程,因为在经过语法分析后生成的AST树是符合我们之前设计的文法的,所以代码生成函数也针对文法去输出对应的代码字符串就可以了。
let res = ''
const codeGenerate = ast => {
if(ast.type === 'Program'){
ast.body.forEach(child => {
codeGenerate(child)
})
}
if(ast.type === 'Text'){
res += ast.value
}
if(ast.type === 'Tag'){
res += `<${ast.name} `
Object.keys(ast.attributes).forEach(key => {
// code transformer
res += ` ${key.toLowerCase()}`
res += ast.attributes[key] ? `="${ast.attributes[key]}"` : ''
})
if(ast.isSelfClosed){
res += '/>'
}else{
res += '>'
ast.children.forEach(child => {
codeGenerate(child)
})
res += `</${ast.name}>`
}
}
return res
}codeGen.js
错误处理
对于词法分析,语法分析,都有可能出现一些错误。比如在词法分析阶段,在某个状态下出现了不该出现的token。语法分析是根据形式文法进行的,可能会出现解析到不该出现对应token的错误。捕获这些错误可以让我们更容易发现我们写出的模板出现了哪些类型的错误。
与Vue.js结合
现在我们让之前的解析器支持表达式,并用它替换掉Vue.js的 Parser,目标效果如下:
const app = new Vue({
template: `
<div>
{#if num % 2 === 0}
<span>
{{num}}是偶数
</span>
{/if}
{#if num % 2 !== 0}
<span>
{{num}}是奇数
</span>
{/if}
</div>
`,
// app initial state
data: {
num: 1
}
})
setInterval(() => {
app.num += 1
}, 1000)状态转换表修改
| 当前状态→ 条件↓ |
start | tagOpen | expressionOpen |
|---|---|---|---|
| whitespace | - | - | - |
| tagOpen | tagOpen | - | - |
| tagEnd | - | start | - |
| attribute | - | - | - |
| tagClose | - | - | - |
| text | - | - | - |
| expressionOpen | expressionOpen | - | - |
| exporessionEnd | - | - | start |
Lexer中的改动
// new pattern
const EXPRESSION_OPEN = /^\{#(\w+)\s+(.*)\}/
const EXPRESSION_END = /^\{\/(\w+)\s*\}/
export default class Lexer {
// expression logic
expressionOpen () {
const matched = this.match('EXPRESSION_OPEN');
if (matched) {
this.state.enter('exprOpen')
this.input = this.input.slice(matched[0].length)
return new Token('EXPRESSION_OPEN', {
type: matched[1],
expr: matched[2]
});
}
}
expressionEnd () {
if (!this.state.is('exprOpen')) return
const matched = this.match('EXPRESSION_END');
if (matched) {
this.input = this.input.slice(matched[0].length)
return new Token('EXPRESSION_END', {
type: matched[1]
});
}
}
}文法改动
PROGRAM → STATEMENTS
STATEMENTS → STATEMENT*
STATEMENT → TAG | TEXT | EXPRESSION
ATTRIBUTE → attribut*
TAG → tagOpen ATTRIBUTE? tagEnd (STATEMENTS tagClose)?
TEXT → (text | whitespace)*
EXPRESSION -> expressionOpen STATEMENTS expressionEnd
N={PROGRAM, STATEMENTS, STATEMENT, TAG, TEXT, ATTRIBUTE, EXPRESSION}
Σ = {tagOpen, tagEnd, tagClose, text, whitespace, attribute, expressionOpen, expressionEnd}
Parser改动
/* eslint-disable */
export default class Parser {
statement () {
const token = this.peek()
switch (token.type) {
case 'TAG_OPEN':
return this.tag()
case 'TEXT':
case 'WHITE_SPACE':
return this.text()
// new type
case 'EXPRESSION_OPEN':
return this.expression()
default:
console.error(`Unexpected token: ${token.type}`)
}
}
expression () {
const token = this.peek();
let node = {
type: 'Expression',
exprType: token.value.type,
expr: token.value.expr,
body: ''
};
this.consume()
const statements = this.statements()
if (statements) {
node.body = statements
}
if (this.peek().value.type !== node.exprType) {
return new Error(`no matched expr ${node.exprType} end `)
}
this.consume()
return node
}
}AST转换
现在我们的Parser已经支持了表达式语法,想要让我们的模板可以被Vue使用,就需要让我们的AST兼容Vue的codeGenerate。

export const createCompiler = createCompilerCreator(function baseCompile (
template: string,
options: CompilerOptions
): CompiledResult {
// const ast = parse(template.trim(), options)
// if (options.optimize !== false) {
// optimize(ast, options)
// }
// const code = generate(ast, options)
const lexer = new Lexer()
const parser = new Parser()
const tokens = lexer.lex(template)
const ast = parser.parse(tokens)
console.log('[SOURCE AST]:', ast)
// ast转换是关键
const distAst = transformAst(ast)
console.log('[TARGET AST]:', distAst)
// 这里的generate依旧是Vue的generate
const code = generate(distAst, options)
return {
ast,
render: code.render,
staticRenderFns: code.staticRenderFns
}
})
创建新的compiler-entry
export function transformAst(ast){
let root
// transform children
if(Array.isArray(ast)){
return ast.map(item => transformAst(item))
}
// transform root
if(ast.type === 'Program'){
root = createASTElement('div', [])
root.children = transformAst(ast.body)
}
// transform text
if(ast.type === 'Text'){
let res
let text = ast.value
if (res = parseText(text, delimiters)) {
return {
type: 2,
expression: res.expression,
tokens: res.tokens,
text
}
} else if (text !== ' ') {
return {
type: 3,
text
}
}
}
if(ast.type === 'Tag'){
let node = createASTElement(ast.name, transAttrs(ast.attributes))
if(ast.children && ast.children.length){
node.children = transformAst(ast.children)
}
return node
}
// 把{#if } 转成一个带 v-if 属性的 div
if(ast.type ==='Expression' && ast.exprType === 'if'){
let node = createASTElement('div', [{name: 'v-if', value: ast.expr}])
node.children = ast.body.map(child => transformAst(child))
// vue 处理if属性的方法,这里为了方便直接拿来用
processIf(node)
return node
}
function transAttrs(attrMap){
return Object.keys(attrMap).map(key => ({name: key, value: attrMap[key]}))
}
function addIfAttrs(ifBody, expr){
if(Array.isArray(ifBody)){
return ifBody.forEach(bodyItem => {
if(bodyItem.children){
addIfAttrs(bodyItem.children, expr)
}
})
}
if(!ifBody.attrsList){
ifBody.attrsList = []
}
ifBody.attrsList.push({
name: 'v-if',
value: expr
})
}
return root
}transformAst方法
Q&A
编译原理基础
By showonne



