Scene Text Detection and Recognition
By:
Shubham Patel, CS17M051
Indian Institute of Technology, Madras
MTech, CSE
Under Guidance of:
Dr. Mitesh Khapra
Introduction

Scene

Scene Text

Scene Text Detection








STATE
BANK
ATM
स्टेट
बैंक
ए
टी
एम
Scene Text Recognition

Script Identification
English
Tamil
Hindi
Challenges

Distortion

Rotation, Languages, Lighting

Blurred Text, Handwritten

Dark

Glossy

Obstruction

Colored Background
Noisy Text
Till Now...
Synthetic Dataset Generation for Hindi




Problems
Not Connected Text
Uneven Distance
Reason
भू
त
ना
थ
Placing character one by one so that complex character bounding box can be captured.
This result in inconsistency of the space.
Solution : Discard complex character level bounding boxes since we are using methods which does not required character level segmentation.
1. Normal Text.
Reason
2. Rotated Text
भू
त
ना
थ
Solution: Replace it with.
\[ y = c \times x^2 \]


c can range from 0.001 to -0.001
0,0
Improvements.
Earlier.
Now.



Recently it has come to our notice that ICDAR 2019 has released synthtic dataset for Hindi as part of MLT, 2019 competition.




Our's
There's
Extending the Generation to Multiple Language.




Malayalam
Punjabi
Extending the Generation to Multiple Language.




Tamil
Telugu
We have generated 400K images each for all five languages.
Detection
Feature Extractor
Detection
Framework
Box Prediction
and Classification
Feature Extractor
Mostly CNN Based Imagenet Architecture Pre-initialize with Imagenet weight
We used MobileNetV2
Motivation: No. of parameter 3.4 Million.
300 Millions MAdds operation.
Depthwise Seperable Convolution
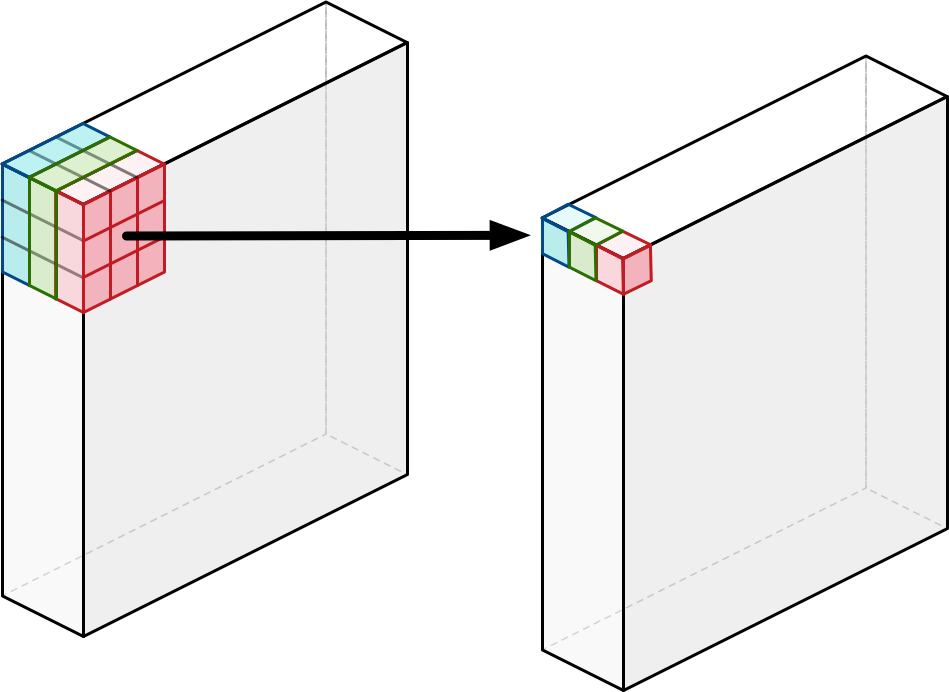
Regular Convolution
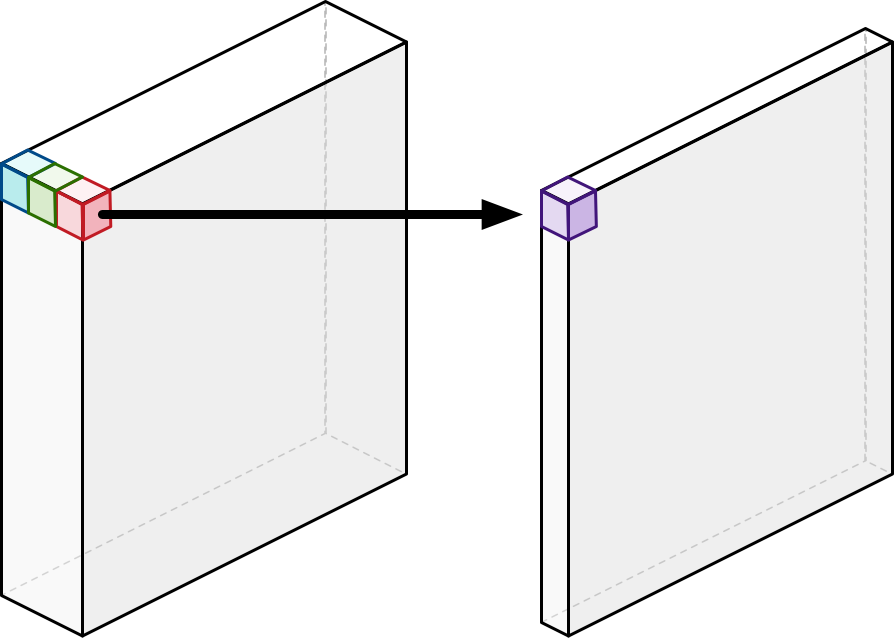
Depthwise Convolution
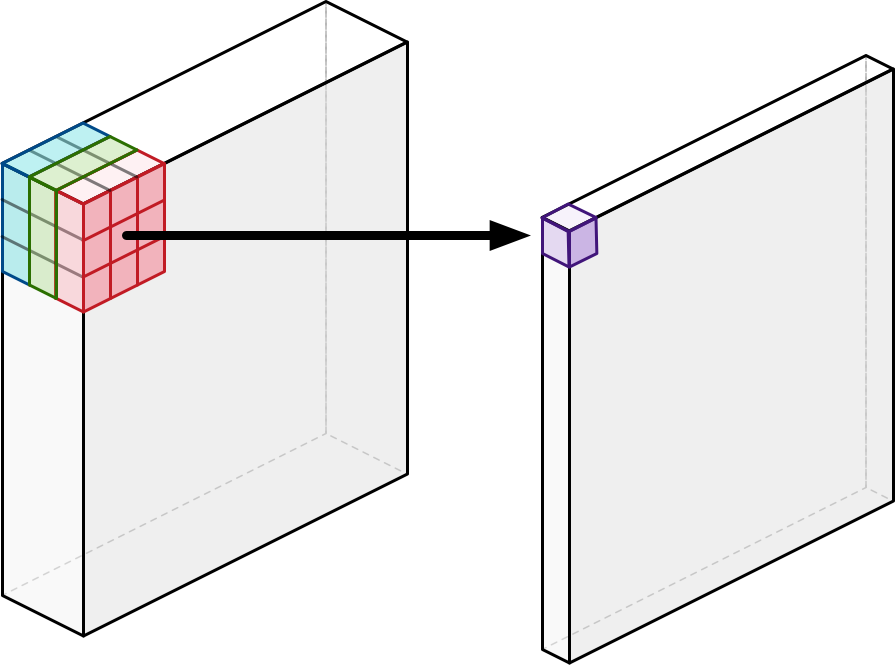
Depthwise Convolution
Follow By
1 X 1 Convolution
If K kernels, there will be k such 1X1 operation.
Depthwise Seperable Convolution
Bottleneck Residual Block
Expansion Layer
Depthwise Conv Layer
Projection Layer
1x1 conv2d, relu6
1x1 conv2d, linear
3x3 dwise s=s, relu6
h x w x k
h x w x (tk)
(h/s) x (w/s) x (tk)
(h/s) x (w/s) x (k')
add
MobileNetV2
conv2d_0, 32, s=2
bottleneck0,16, s=1,t=1
bottleneck1, 24, s=2,t=6
bottleneck2, 24, s=2,t=6
bottleneck3, 32, s=2,t=6
bottleneck4, 32, s=2,t=6
bottleneck5, 32, s=2,t=6
bottleneck6, 64, s=2,t=6
bottleneck7, 64, s=2,t=6
bottleneck9, 64, s=2,t=6
bottleneck10, 96, s=1,t=6
bottleneck11, 96, s=1,t=6
bottleneck12, 96, s=1,t=6
bottleneck13, 160, s=2,t=6
bottleneck14, 160, s=2,t=6
bottleneck15, 160, s=2,t=6
bottleneck16, 320, s=1,t=6
conv2d_1, 1x1, 1280, s=1
avgpool 7x7
bottleneck8, 64, s=2,t=6
conv2d, 1x1, k
SSDLite
SSDLite is similar is SSD, with the difference that all of the normal convolution operations replace by depthwise separable convolution.
SSD do the prediction of bounding boxes at multiple layers, for multiple boxes of different aspect ratio and scale.
In present architecture, the prediction has been at 6 different layers.
SSDLite Architecture.
conv2d_0, 32, s=2
bottleneck13
conv2d, 1x1, 576
predict
dwise, 3x3, 576
conv2d, 1x1, 160
conv2d_1, 1280, s=1
predict
MobileNetV2
conv2d, 3x3, 512
conv2d, 1x1, 256
dwise, 3x3, 512
conv2d, 3x3, 256
conv2d, 1x1, 128
dwise, 3x3, 256
conv2d, 3x3, 128
conv2d, 1x1, 64
dwise, 3x3, 128
predict
predict
predict
predict
conv2d, 3x3, 256
conv2d, 1x1, 128
dwise, 3x3, 256
19x19x576
10x10x1280
300x300x3
10x10x1280
5x5x512
3x3x256
2x2x256
1x1x128
Predict
dwise, 3x3
conv2d, 1x1, k*4
dwise, 3x3
conv2d, 1x1, k*class
m x n x c
m x n x (k*4)
m x n x (k*c)
Objective Function.
\[x^p_{ij} = \{1, 0\}\] is an indicator for matching the i-th default box to the j-th ground truth box of category p.
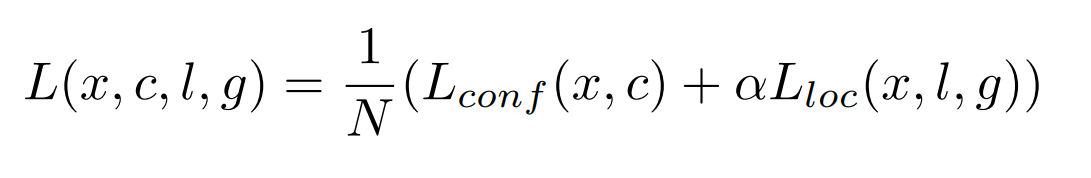
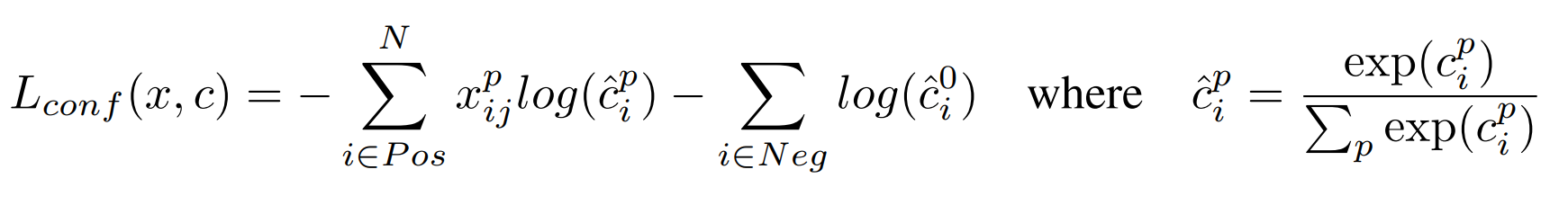
Classification Loss
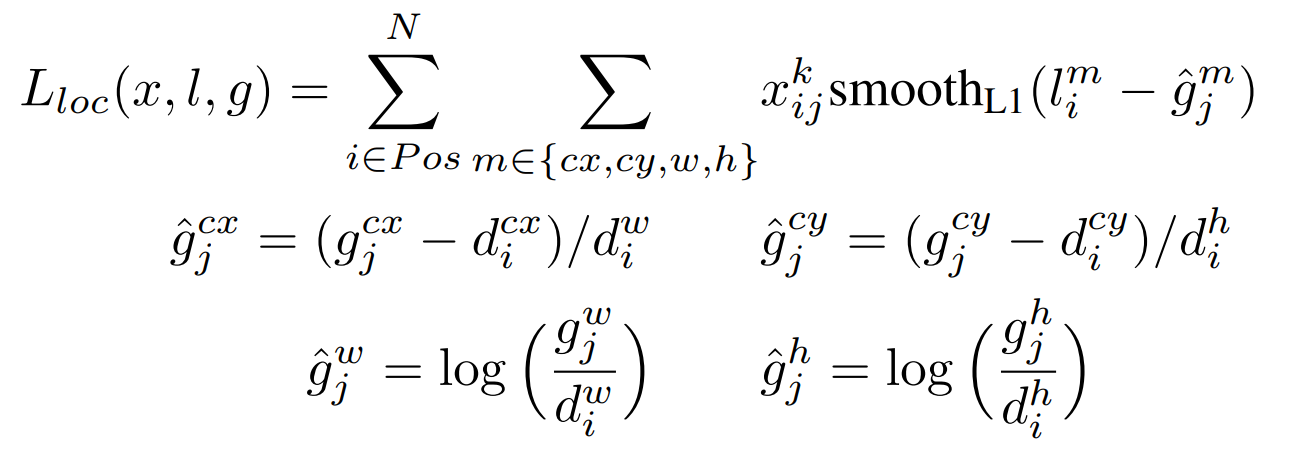
Localization Loss
g: denotes ground truth boxes.
d: denotes default bounding boxes.
l: denotes predicted bounding boxes.
Training.
We have used the MS-coco pretrained model.
Train it on synthetic dataset of size 400k for 200k iteration for 1 day with batch size of 24 on single Nvidia 1080 gpu.
Further finetune it on 300 real images to get the best results.
We have choosen more wider aspect ratio for training 1, 3, 6, 8, 5 respectively.
Results
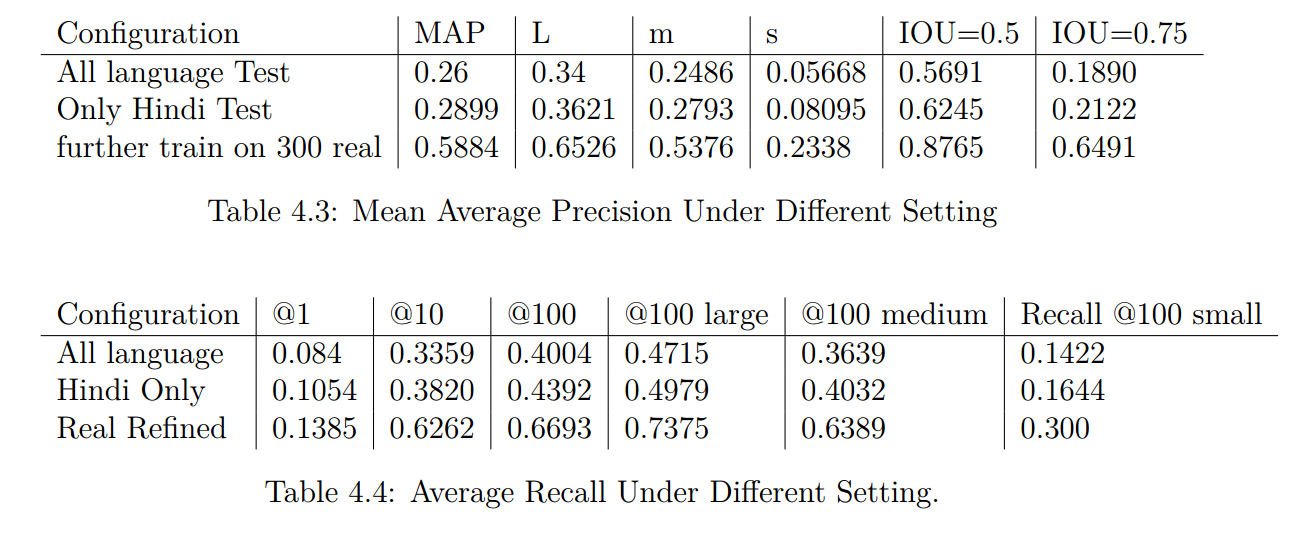
Results.
Before fine tuning on real images.


Left Prediction : Right Ground Truth


Results.
After fine tuning on real images.
Left Prediction : Right Ground Truth






Recognition
Feature Extractor
Encoder
Decoder
बैंक
Feature Extractor
1x1 conv, k
3x3 conv, k, s
+
bottleneck
3x3, conv2d, s = 1x1
bottleneck, k=32, s=1x1
bottleneck, k=32, s=1x1
bottleneck, k=32, s=2x2
bottleneck, k=64, s=1x1
bottleneck, k=64, s=1x1
bottleneck, k=64, s=1x1
bottleneck, k=64, s=2x2
bottleneck, k=128, s=1x1
bottleneck, k=128, s=1x1
bottleneck, k=128, s=1x1
bottleneck, k=128, s=1x1
bottleneck, k=128, s=1x1
bottleneck, k=128, s=2x1
bottleneck, k=512, s=2x1
bottleneck, k=512, s=1x1
bottleneck, k=512, s=1x1
bottleneck, k=256, s=2x1
bottleneck, k=256, s=1x1
bottleneck, k=256, s=1x1
bottleneck, k=256, s=1x1
bottleneck, k=256, s=1x1
bottleneck, k=256, s=1x1
Image: 32x100x3
Features: 1x25x512
Encoder-Decoder
Features
0
24
1
Bi-Directional LSTM
x
\[h\]
Attend
\[ \alpha_t \]
LSTM
\[g_t \]
LSTM
LSTM
LSTM
LSTM
\[ s_{t-1} \]
<EOS>
ब
ै
ं
क
Attention
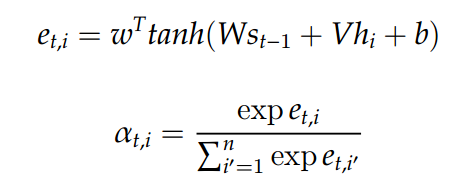


Input to the Decoder
Bothway Decoder
Encoder
Left-To-Right
Decoder
Right-To-Left
Decoder
Reverse
कंैब
बैंक
बैंक
Higher_confidence
बैंक
Objective Function
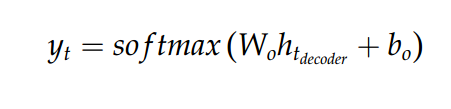
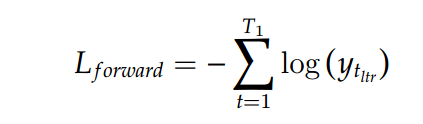
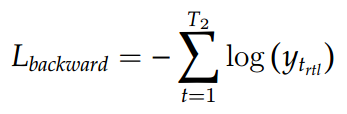
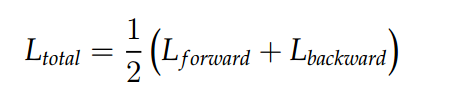
Training
- Batch size 32 is chosen.
- Model is trained on cropped word synthetic data of size 3 million refer to Jaya's work.
- For first 600k iteration learning rate of 0.1 is used.
- For 600k to 800k learning rate of 0.01 is used.
- For 800k to 1.2m learning rate of 0.001 is used.
- ADADELTA is used as the optimizer.
- Training took 2.5 days using 1 nvidia 1080.
Results.

On looking to the prediction, it has come under observation that certain Hindi characters such as अ, न, ई, क, ज, ग were never predicted which have further affected the results of our predictions.
In many of the cases, model is not able to predict the first character properly.

It has been observed that the model has seen confusion in predicting character such as द -> ट, भ -> म .
Correct predictions example
More...

Some Incorrect Examples.

Conclusion and Future Work
It has been a long tradition in OCR to break Hindi character into three regions one above connecting line one below the bottom and one in the center. Though this is directly not possible to incorporate directly into scene text recognition, there is a possibility to incorporate this information in an end to end manner.
The conclusion of our work in regards to scene text detection is that standard object detection methods work well for the text detection also given that we have tuned the aspect ratio and scale appropriately.
Also, in the context of recognition state of the art, the method which is doing well on English perform subtle on Hindi, but they do have learned, since they aster the one we have tried able to predict 26% words correctly, moreover also 62% of the characters properly.
The next step when scene text recognizer is working well with all of the single languages is to focus on multi-lingual recognizer. Which still a hot area of research in scene text domain.
References
-
Q. Ye and D. Doermann, “Text detection and recognition in imagery: A survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 37, pp. 1480–1500, July 2015.
-
A. Gupta, A. Vedaldi, and A. Zisserman, “Synthetic data for text localisation in natural images,” in IEEE Conference on Computer Vision and Pattern Recognition, 2016.
-
F. Liu, C. Shen, and G. Lin. Deep convolutional neural fields for depth estimation from a single image. In Proc. CVPR, 2015.
-
Baoguang Shi and Xiang Bai and Cong Yao, An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition, CORR.
-
Baoguang Shi ; Mingkun Yang ; Xinggang Wang ; Pengyuan Lyu ; Cong Yao ; Xiang Bai, ASTER: An Attentional Scene Text Recognizer with Flexible Rectification, Transaction on Pattern Recognition and Machine Learning.
M Tech Presentation
By Shubham Patel


