Neural Actors:
The intersection between
machine learning, hardware,
and the actor model
@Smerity
My history is a mix of
linguistics
and
computing
Leveraging more compute
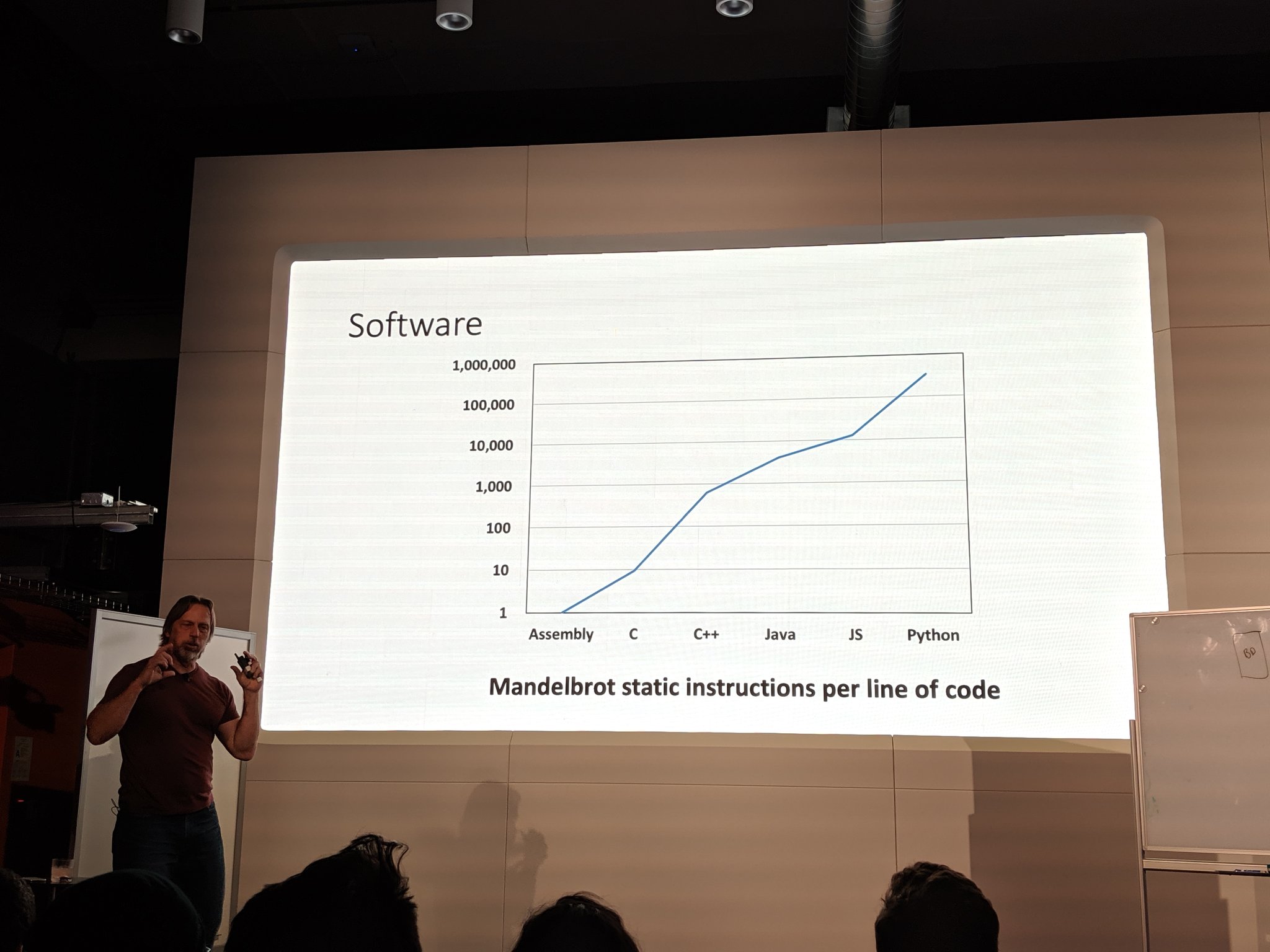
Actors
ML
Will Wright's "Dynamics for Designers"
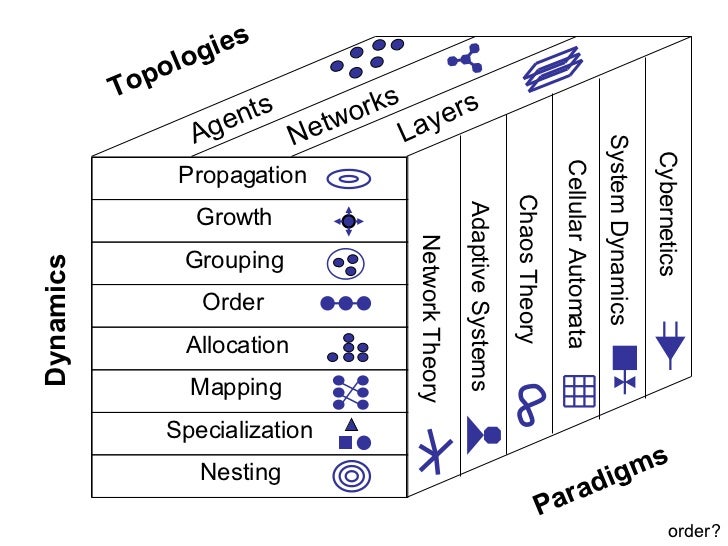
Rich interactions for systems we don't yet know / can't explicitly specify we're developing
An actor can:
- Send a finite number of messages to other actors
- Actors have a mailbox with an address and bounded / unbounded capacity
- Create a finite number of new actors
The last point minimizes the need for orchestration systems
The actor model
The actor model helps solve:
- Concurrency (no shared state, many cores)
- Scalability (spawn new actors as needed, potentially on nodes across the network)
- Reliability (actors supervising other actors)
- Flexibility: "Actor creation plus addresses in messages means variable topology"
The actor model
Erlang / Elixir:
- Actors as a language primitive
- Erlang/OTP used for reliable telecoms
Rust's "fearless concurrency":
- Mutable with single owner
- Immutable with many references
The actor model in Software 1.0
Actor model enabling Amazon's two pizza rule
WhatsApp: "35 engineers and reached more than 450 million users" (pre Facebook acquisition)
Discord: "scaling to over a 100 million messages per day with only 4 backend engineers in 2017 and serving 250+ million users with less than 50 engineers in 2020"
Team and software scaling
Actors and the web at scale
Lone engineer at CommonCrawl
(2.5 petabytes and 35 billion webpages)
Extensive use of MapReduce
(simplified actor model if you squint)
The web as an actor ecosystem
(concurrency, scalability, reliability, flexibility, interoperability, ...)
Frank McSherry's COST

Graph processing (single threaded laptop) w/ Rust
Actors and ML
ML frameworks act as message passing++
(fwd + bwd are sync / async msgs)
Actors are explicit operations learning and performing implicit tasks via obj functions
ML components can be seen as actors but:
- High parallelism, minimal concurrency (SPMD)
- Inability to spawn (except limited by the above)
The limitations of hardware
SPMD means "one (hammer) program"
The result? All problems made equivalent nails
Multi-tenancy would provide different primitives
(at least CPUs are ~good at time sharing)
At present any "spawning" is manually specified
Remember: "Actor creation plus addresses in messages means variable topology"
What does MPMD look like atm?
- NVIDIA: High end cards at best 7 MPMD (MIG)
(max theoretical is 108 as 108 SMs)
...
The best you can do is run many nodes with many cards and send messages about
This gives you the horrors of both worlds: neural networks and container orchestration!
Mixture of Experts (MoE)

Tenstorrent 🤔
- Many small independent cores (RISC + SIMD)
- Cores communicate via network packets
- Cores agnostic to same node / cross network
- Conditional / variable computation
- High parallelism, high concurrency
The dream: XPUs
Small + many enables a future of:
"This programs requires 8 XPU cores"
Why? I desperately want to be able to write a program featuring ML that doesn't rely on them having internet access or a $1k card (with the right drivers installed ...)
- Programs that don't rely on foreign API
- Doesn't require a local $1k card (with right drivers)
- Edge models don't need as much conversion
Neural actors
A neural actor can:
- Send a finite number of messages to other actors
(Explicit addr or implicit addr via attention)
- Actors have a mailbox with an address and bounded / unbounded capacity
- Create a finite number of new neural actors
Neural actor possibilities
Scale up/down network and compute
- Proxy actors for messaging (filter out at source, predict missing packets, ...)
- LM actors spawned between components for shared compressed language / comms
- TEMPEST actors: "ephemeral arbitrator between AIs w/o knowledge exposed"
- Spare capacity for expansion / distillation
- Treat msgs over network like RNN BPTT
Example: Expert Choice MoE

Ancient history: n-grams
Past decades: search engine's inverted index
(past: "Actor" appears on pages A, B, C, ...)
Recent:
word2vec("Actor") => 1024 dim f32 vector
"Actor" + context => 1024 dim vector
The word connecting to its own meaning
Know a word by the company it keeps
Data actors
An actor expanding / better understanding a specific piece of data (implicit program)
- Naive: inverted index (i.e. search)
- Implicit: language models / embeddings
- Explicit: data actors continuously shifting about an actor ecosystem
"Actor" node has high entropy .: mitosis spawns: "Actor (programming)", "Actor (arts)"
Traveling Linguist Problem
Data actors shifting about an actor ecosystem
=>
A data ecosystem groups, sorts, and removes redundancies within itself such that you have the minimal surprise learning a language
Will Wright's "Dynamics for Designers"
Rich interactions for systems we don't yet know / can't explicitly specify we're developing
Actors Everywhere
By smerity




