Spanner: Google’s Globally-Distributed Database
Fernanda Mora
Luis Román
Corbett, James C., et al. "Spanner: Google’s globally distributed database." ACM Transactions on Computer Systems (TOCS) 31.3 (2013): 8.
Content
- Introduction
- Key ideas
- Implementation
- Concurrency control
- Evaluation
- Future work & Conclusions
Introduction
Storage now has multiple
requirements
- Scalability
- Responsiveness
- Durability and consistency
- Fault tolerant
- Easy to use
Previous attempts
-
Relational DBMS: MySQL, MS SQL, Oracle RDB
- Rich features (ACID)
- Difficult to scale
-
NoSQL: BigTable, Dynamo, Cassandra
- Highly scalable
- Limited API
Motivation
Spanner: Time will never be the same again
-Gustavo Fring
To build a transactional storage system replicated globally
¿What is the main idea behind Spanner?

How?
- Main enabler is introducing a global "proper" notion of time

Key ideas
Key ideas
- Relational data model with SQL and general purpose transactions
- External consistency: transactions can be ordered by their commit time, and commit times correspond to real world notions of time
- Paxos-based replication, with number of replicas and distance to replicas controllable
- Data partitioned across thousands of servers
Basic Diagram
Data center 1
Data center 2
Data center 3

Spanservers
s_{1,1}
s_{1,2}
s_{1,n}
...
Spanservers
Spanservers
...
s_{2,2}
s_{3,2}
s_{2,n}
s_{3,n}
s_{2,1}
s_{3,1}
...
Replication
Replication
Millions of nodes, hundreds of datacenters, trillions of database rows
Implementation
Server organization

Storage data model: tablets
- Each spanserver has 100-1000 tablets
- Optimized data structure to track data by row/column and location (stored in Colossus)
- Table mapping:
- Tablet's state is tracked and stored
(key:string, timestamp:int64) -> stringStorage data model

- Each tablet has a Paxos state machine that mantains its log and state
- Paxos has long-lived leaders
- Paxos is used to maintain consistency among replicas: writes must initiate at the leader, reads from any recent replica
Paxos Group
Storage data model
- Each leader has a lock table with state for two phase locking, mapping range of keys to lock states
- Transaction manager supports distributed transactions and selects participant leader, which coordinates Paxos between participant groups
Data movement
- Directories: smallest units of data placement
- Looking for similarity or closeness

External consistency
- All writes in a transaction are globally ordered by timestamp
- If the start of a transaction T2 occurs after the commit of a transaction T1, then
- We need sinchronized clocks to determine the most recent write to each objects
T_{2,c} > T_{1,c}
More difficulties!
-
Sinchronization algorithms
-
Implementation
-
Practical use
-
Global scale

First option: Lamport timestamps
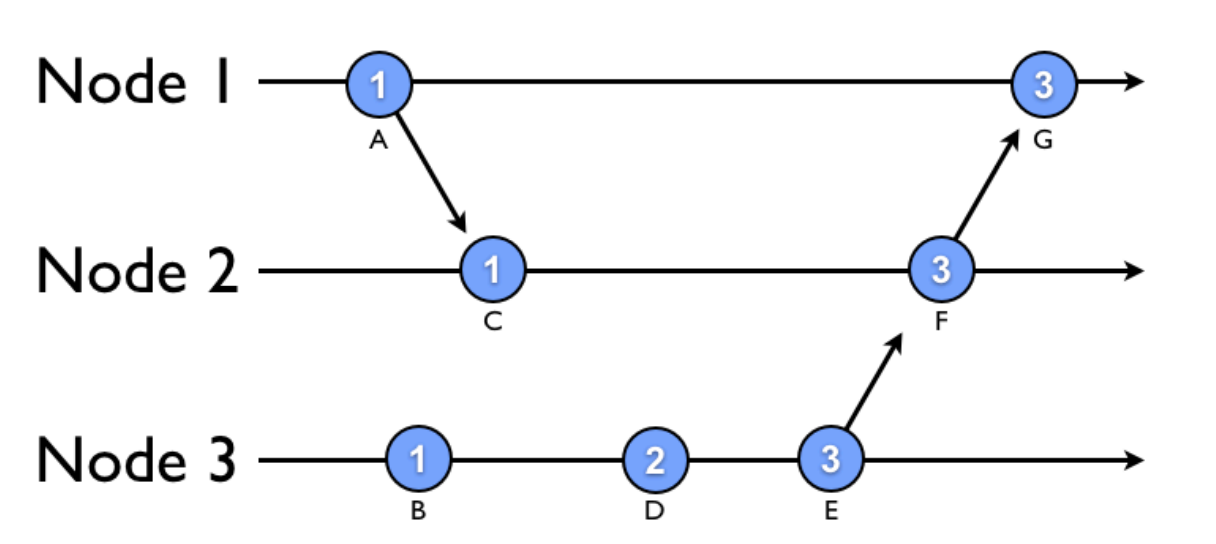
-
But we can't distinguish concurrent events!
Another option: Vector clocks
-
Only partial order: what about concurrent events?!

How do we ensure that all nodes have consistent clock values?
- Use time synchronization (GPS + atomic clocks on some nodes)
- Plus network time synchronization protocols (where nodes exchange times with each other and adjust their clocks accordingly)
Can't there still be small differences between clocks on nodes?
- Yes: API TrueTime is able to estimate the accuracy of a node's clock, guaranteeing that
=> tt.earliest\leq t_{abs} \leq tt.latest
tt=TT.now()
How is TrueTime implemented?
- Set of time master machines per data center
- Timeslave daemon per machine
GPS receivers
Atomic clocks
Daemons
Data Center
Concurrency control
Concurrency Control
How to use TrueTime to guarantee:
- Externally consistent transactions
- Lock-free read-only transactions
- Non-blocking reads in the past
Concurrency Control
Timestamp Managment
| Operation | Concurrency Control | Replica Required |
|---|---|---|
| Read-write | pessimistic | leader |
| Read-only | lock-free | leader for timestamp |
| Snapshot read | lock-free | any |
Concurrency Control
Timestamp Managment
Spanner's Paxos implementation uses timed leases to make leadership long-lived
Discovers has a quorum of lease votes
No longer has a quorum of lease votes
Spanner depends on the following invariant: for each Paxos group, each Paxos leader's lease interval is disjoint from every other leader's
Concurrency Control
Timestamp Managment
Transactional reads and writes use two-phase locking. As a result, timestamps can be assigned at any time after the locks have been acquired but before they've been released.
Monotonicity Invariant: Spanner assigns timestamps to Paxos writes in monotonically increasing order, even across leaders.
Concurrency Control
Timestamp Managment
Spanner also enforces the following external consistency invariant: Define the start and commit events for transaction Ti by:
e_i^{start}
e_i^{commit}
and the commit timestamp as
s_i
t_{abs}(e_1^{commit})< t_{abs}(e_2^{start})\Rightarrow s_1 < s_2
Timestamp Managment
Enforced by two rules:
1.- The coordinator assigns a commit timestamp no less than the value of computed after
TT.now().latest
e_i^{server}
Timestamp Managment
Enforced by two rules:
2.- The coordinator leader ensures that clients cannot see any data commited until after TT.after(si) is true
Concurrency Control
Timestamp Managment
Enforced by two rules:
s_1 < t_{abs}(e_1^{commit})
t_{abs}(e_1^{commit}) < t_{abs}(e_2^{start})
t_{abs}(e_2^{start}) \leq t_{abs}(e_2^{server})
t_{abs}(e_2^{server})\leq s_2
Concurrency Control
Timestamp Managment
Serving reads at a timestamp:
Every replica tracks a value called safe time which is the maximum timestamp at which replica is up-to-date. A replica can satisfy a read at timestamp t if t<=
t_{safe}
t_{safe}
t_{safe}=min(t_{safe}^{Paxos},t_{safe}^{TM})
Concurrency Control
Timestamp Managment
Serving reads at a timestamp:
: timestamp of the highest-applied Paxos write.
Is the prepare timestamp assigned by the participant leader Ti in a group g.
t_{safe}^{TM}=min_i(s_{i,g}^{prepare})-1
t_{safe}^{Paxos}
s_{i,g}^{prepare}
Concurrency Control
Timestamp Managment
Read only transactions:
read-only transactions executes intwo phases:
1.- assign a timestamp
2.- execute the transaction's read at
s_{read}
s_{read}
Concurrency Control
Timestamp Managment
Read only transactions:
read-only transactions executes intwo phases:
1.- assign a timestamp
2.- execute the transaction's read at
s_{read}
s_{read}
Concurrency Control
Details
- Writes are buffered at the client until commit
- Reads within read-write transactions use wound-wait to avoid deadlocks.
- When a client has completed all reads and buffered all writes, it begins two phase commit.
Concurrency Control
Details
Aquired locks
Aquired locks
Aquired locks
T_c
T_{p1}
T_{p2}
Compute ts
Start logging
Done logging
Prepared + ts
Commit overall ts
Commit wait done
Release locks
Release locks
Release locks
Evaluation
Microbenchmarks
Distribution of TrueTime values, sampled right after timeslave daemon polls the time masters. 90th, 99th and 99.9th percentiles

Scalability

2PC scalability. Mean and sd over 10 runs
Avalability
Effect of killing servers on throughput

TrueTime
Distribution of TrueTime values (percentiles), sampled right after timeslave daemon polls the time masters.

Future Work & Conclusions
Future work
- Doing reads in parallel: non-trivial
- Support direct changes on Paxos configurations
- Reduce TrueTime < 1 ms
- Poor single-node performance
- Automatically movement of client-application processes
Summary
- Replica consistency: using Paxos
- Concurrency control: using two-phase locking
- Transaction coordinator: using 2PC
- Timestamps for transactions and data items
Global scale database with strict transactional guarantees
Conclusions
Easy-to-use
Semi-relational interface
SQL-based query language
Scalability
Automatic sharding
Fault tolerance
Consistent replication
External consistency
Wide-area distribution

Distribuidos_Presentación_final
By Sophie Germain
Distribuidos_Presentación_final
Presentación para la clase de Algoritmos




