SQuAD: The Stanford Question Answering Dataset
Update #4: CNN results and answer extraction methodology
August 11th, 2016

Overview
- Week's outcomes
- Results for CNN methodology for sentence ranking
- Methodology proposal and preliminary results for answer extraction baseline
- Next steps
Week's outcomes
CNN methodology for sentence ranking
Results
First Run:
- 30% of SQUAD's training data
- 80% training, 10% dev, 10% test
- Exact match as labels for training
MAP = 0.2503
MRR = 0.2503
CNN methodology for sentence ranking
Results
MAP = 0.2394
MRR = 0.2394
- Jaccard similarity as labels for training
Second Run:
- 30% of SQUAD's training data
- 80% training, 10% dev, 10% test
Answer extraction baseline
General Metodologies
- Treat sentence ranking and answer extraction as two separate tasks - Assume the sentence ranker is right and get an estimate of the error of the exact answer extraction.
- Treat sentence ranking and answer extraction as a unified process - Pass the score of the sentence ranker as a feature for the answer extractor
Answer extraction baseline
Metodology 1.1 (almost question "agnostic")
Idea: Use features that extract lexical, syntactical and semantical structure of sentence, question and answer to train a classifier.
For each word in answers:
- Indicator as part of the answer (True/False)
- Lemma (for each of its l-r neighbors)
- POS (for each of its l-r neighbors)
- NER (for each of its l-r neighbors)
- Type of question (W's)
- Animacy, number, gender and emotion
Answer extraction baseline
Metodology 1.1 (almost question "agnostic")
Idea: Use features that extract lexical, syntactical and semantical structure of sentence, question and answer to train a classifier.
Example: "it"
(False, u'It', u'PRP', u'O', 'whom', '', '', '', u'is', u'VBZ', u'O', u'INANIMATE', u'SINGULAR', u'NEUTRAL', u'PRONOMINAL')Answer extraction baseline
Metodology 1.1 (almost question "agnostic")
Random forest classifier
- 10 trees
- Uses bootstrap sampling
- Criterion Gini
Parameters:
Results:
- F1 0.1392
- Confusion matrix
| 502,419 | 5,853 |
| 60,095 | 5,335 |
True
Pred
0
1
0
1
Answer extraction baseline
Metodology 1.1 (almost question "agnostic")
Random forest classifier
- 100 trees
- Uses bootstrap sampling
- Criterion Gini
Parameters:
Results:
- F1 0.1393
- Confusion matrix
| 502,671 | 5,644 |
| 60,352 | 5,345 |
True
Pred
0
1
0
1
Answer extraction baseline
Metodology 1.2 (question sensitive)
Idea: Use features that extract lexical, syntactical and semantical structure of sentence, question and answer to train a classifier.
For each word in answers:
- Indicator as part of the answer (for each of its l-r-d neighbors)
- Indicator as part of the question (for each of its l-r-d neighbors)
- Lemma (for each of its l-r-d neighbors)
- POS (for each of its l-r-d neighbors)
- NER (for each of its l-r-d neighbors)
- Type of question
- Animacy, number, gender and emotion
- Type of dependency
Answer extraction baseline
Metodology 1.2 (question sensitive)
Idea: Use features that extract lexical, syntactical and semantical structure of sentence, question and answer to train a classifier.
Example: "it"
(False, u'It', u'PRP', u'O', False, 'whom', '', '', '', '', '', u'is', u'VBZ', u'O', False, False, u'replica', u'NN', u'O', u'nsubj', False, False, u'INANIMATE', u'SINGULAR', u'NEUTRAL', u'PRONOMINAL')Comparison with Stanford
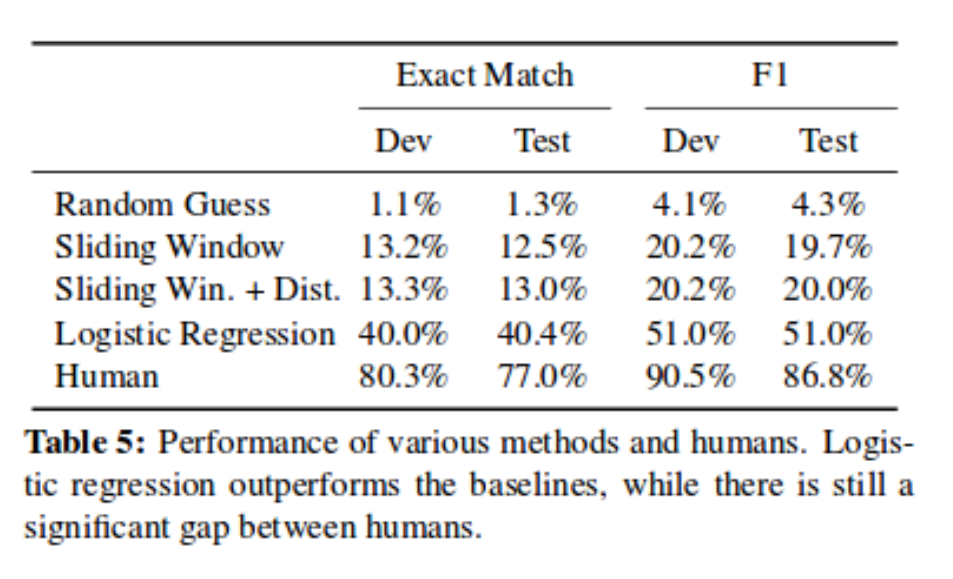
Next steps
- Adapt CNN code to run efficiently on server
- Integrate CNN with BM25
- Add topicality to CNN feature array
- Mix different embeddings
- Extract and add more question knowledge to classifier (e.g. TED, question class)
- Integrate two tasks in on single pipeline
- Explore other methodologies: attention-based
What's next?
Update 4
By Sophie Germain
Update 4
LTI-CMU




