Lær at spille Atarispil med AI

Hvem er Søren?
- Udvikler siden år 2000
- I Topdanmark fra 2012
- IT-Skade
- Machine Learning
- Innovation Lab
Hvem er Kåre?
- Statistiker fra Københavns Universitet
- Arbejdet i Topdanmarks statistikafdeling siden 2008
- Arbejdet med Machine Learning / Artificial Intelligence siden januar 2017
Machine Learning teamet
- Kåre - Statistiker
- Christian - Statistiker
- Nicolai- Statistiker
- Mads Tvede - AAA
- Søren - Udvikler
- Esben - Studerende
- Stig - Projektleder
- Mathias - Udvikler
High level introduktion til Atarispil med Reinforcement Learning
"Programming a computer to do the right thing when you don't know for sure, what the right thing is"
Peter Norvig, Director of research, Google
Hvad er AI?
Elementer i AI
- En maskine der kan opføre sig og forstå som et menneske
- Læse og forstå tekst
- Forstå billeder
- Forstå tale
- Machine Learning
- Deep Learning
Hvad er Machine Learning?
- Statistiske algoritmer og metoder
- Lær fra data ved træning
- Koden er generel, dvs. den kan bruges til forskellige problemer men trænes specifikt med data for hvert problem
Hvad er Deep Learning?
- Neurale netværk i flere lag
- Neurale netværk er software i en computer, der regner på data efter samme princip som en biologisk hjerne
- Billedgenkendelse
- Tekstanalyse
Hvad er intelligens?



Lidt historie

Alan Turing, 1912 - 1954
Turingtesten
I 1950-1970 var AI det vi kender som software i dag
- Baseret på logik
- Regler nedskrevet i logik
- Baseret på Sandt/Falsk
1980+ blev AI baseret på sandsynlighed
- Først i 1980'erne kom algoritmer frem, der kunne håndtere sandsynlighed
- Lære om regler fra data
- Baseret på sandsynlighed
- Kombiner med logik
Hvor kommer intelligensen fra?
"The intelligence in Artificial Intelligence lies within the team"
Danny Lange (som jeg husker det) ved Nordic AI 2017

Komplekse beslutninger er ... komplekse!!!
Udfordringer med AI
- Fokuseret på enkelt problem
- Kode er specifik på domænet der arbejdes med
- Mister viden når der skal trænes om
- Nye regler kræver ny træning
- Meget følsomt overfor ændringer i regler
Atarispil
3 eksempler på Atarispil


Space invaders
Breakout
Pong
Hvordan spiller man et Atarispil?
Der kan laves et ryk for hver "frame" som vises med en hastighed på 60Hz. Hver gang skærmen tegnes skal der besluttes hvad man vil gøre.
- Observer skærmen
- Forudse hvad det bedste træk vil være (højre, venstre, skyd)
- Udfør bedste træk
- Observer resultatet
- Gentag 1-4 indtil man er død
Måder at spille Atarispil med et program
- Spil ET spil, f.eks. Space Invaders, ud fra regler i spillet og lav en algoritme specifikt til det
- Spil ET spil ved kun at se på pixels og belønning. Koden er generel, men stadig er der valg der vil være bundet til spillet (vurdering af hvilket træk der giver flest point etc)
- Spil samtlige spil med samme kode ved kun at se på pixels og hvad man får i belønning
Spil samtlige spil med samme kode
Mål vi vil opnå:
- Opnå "Super Human Performance"
- Samme kode benyttes på tværs af spil
- Uafhængig af hvilke handlinger der giver flest point (f.eks. "Blå giver 100, rød giver kun 10")
Målet er ikke at spille perfekt, men at spille bedre end mennesker
"Super human performance"
I denne præsentation spiller vi "Breakout"
Men... hvorfor????
Hvorfor betalte Google +500 million $ for Deepmind?
Vejen til Artificial General Intelligence (AGI)
- A.K.A "Strong AI" eller "true AI"
Hvad er AGI?
Intelligens der matcher eller overgår menneskelig intelligens
-
Samme netværksarkitektur for alle spil
-
Hyperparametrene er de samme for alle spil
-
Bliv bedre mens netværket træner
-
En model per spil
Målsætning for at spille Atarispil
Først løst i 2013 til at spille 7 forskellige spil. Forbedret i 2015 til at spille 49 spil
Terminologi
-
Neuralt netværk (eller bare netværk)
- Software i en computer, der regner på data efter samme princip som en biologisk hjerne
-
Træning
- Processen hvor man træner det neurale netværk
-
Prediktion
- Svaret fra et neuralt netværk på det spørgsmål det er trænet til
Kort forklaring om Deep Learning
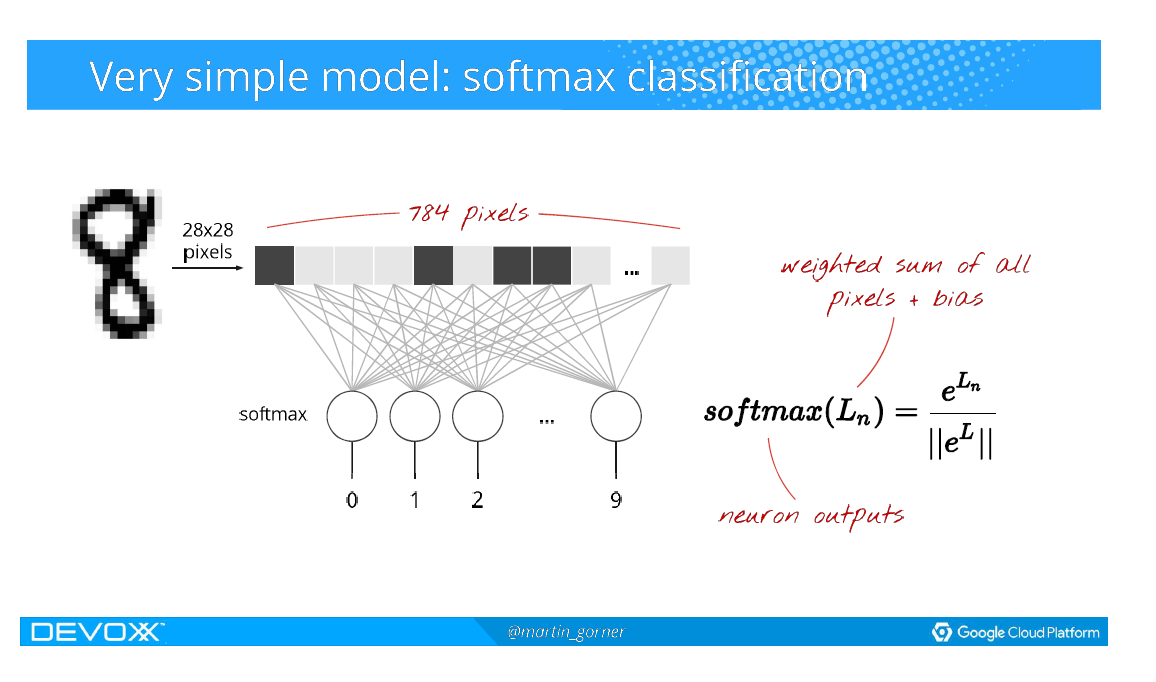

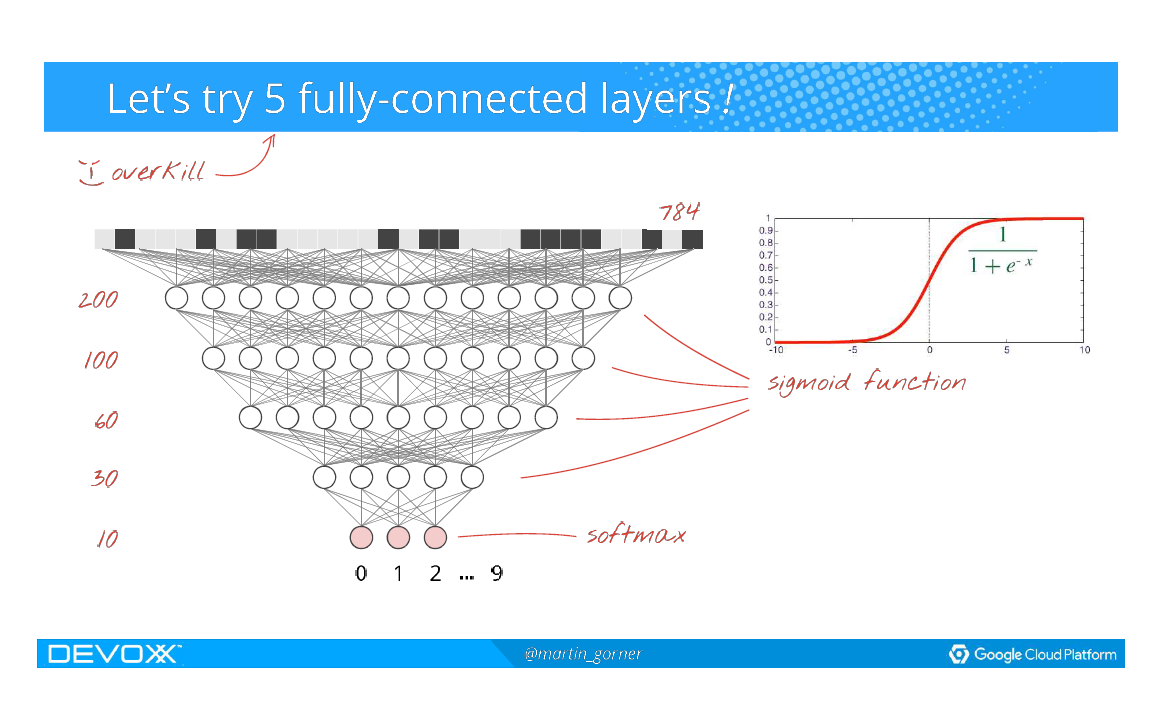
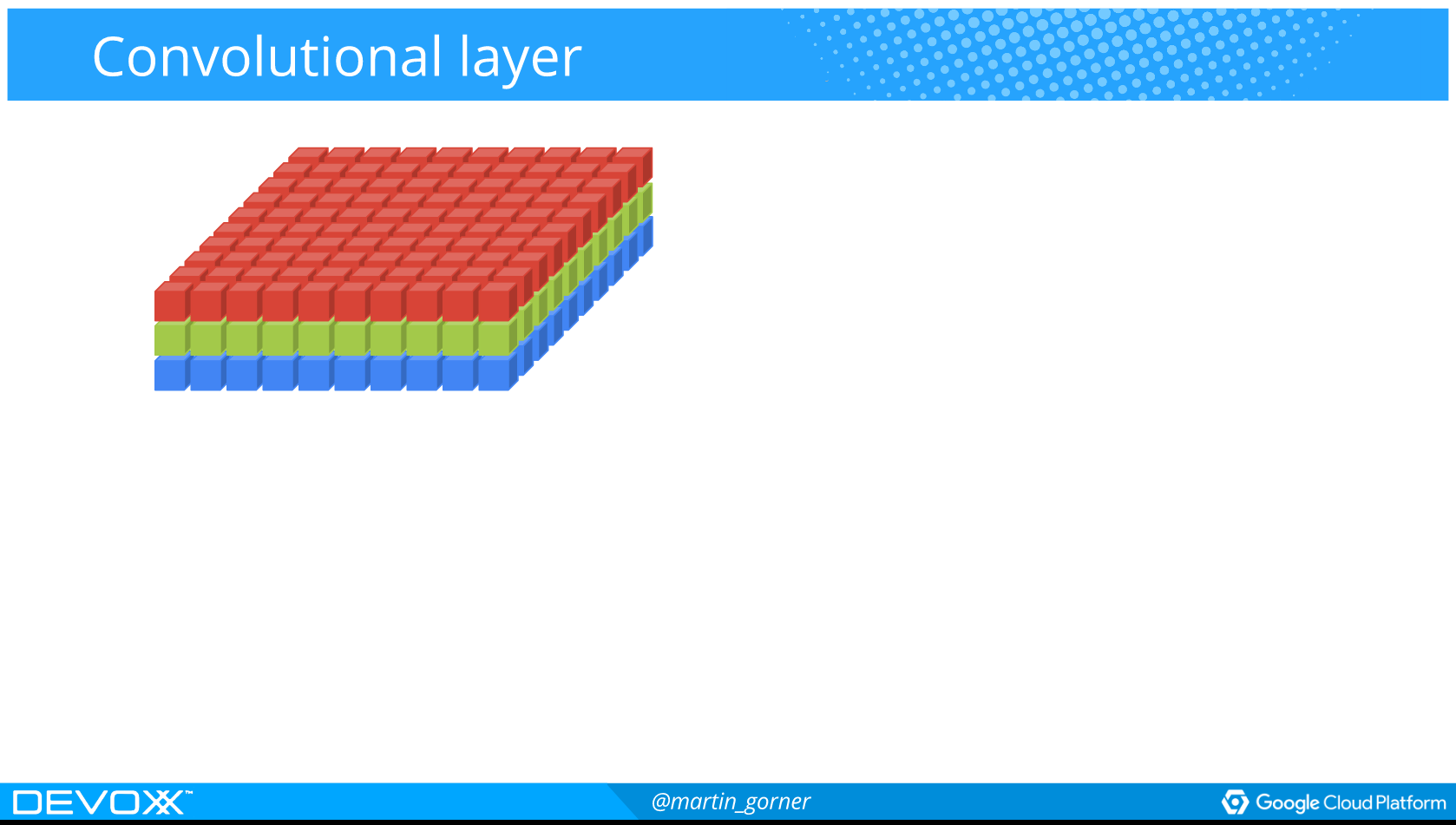
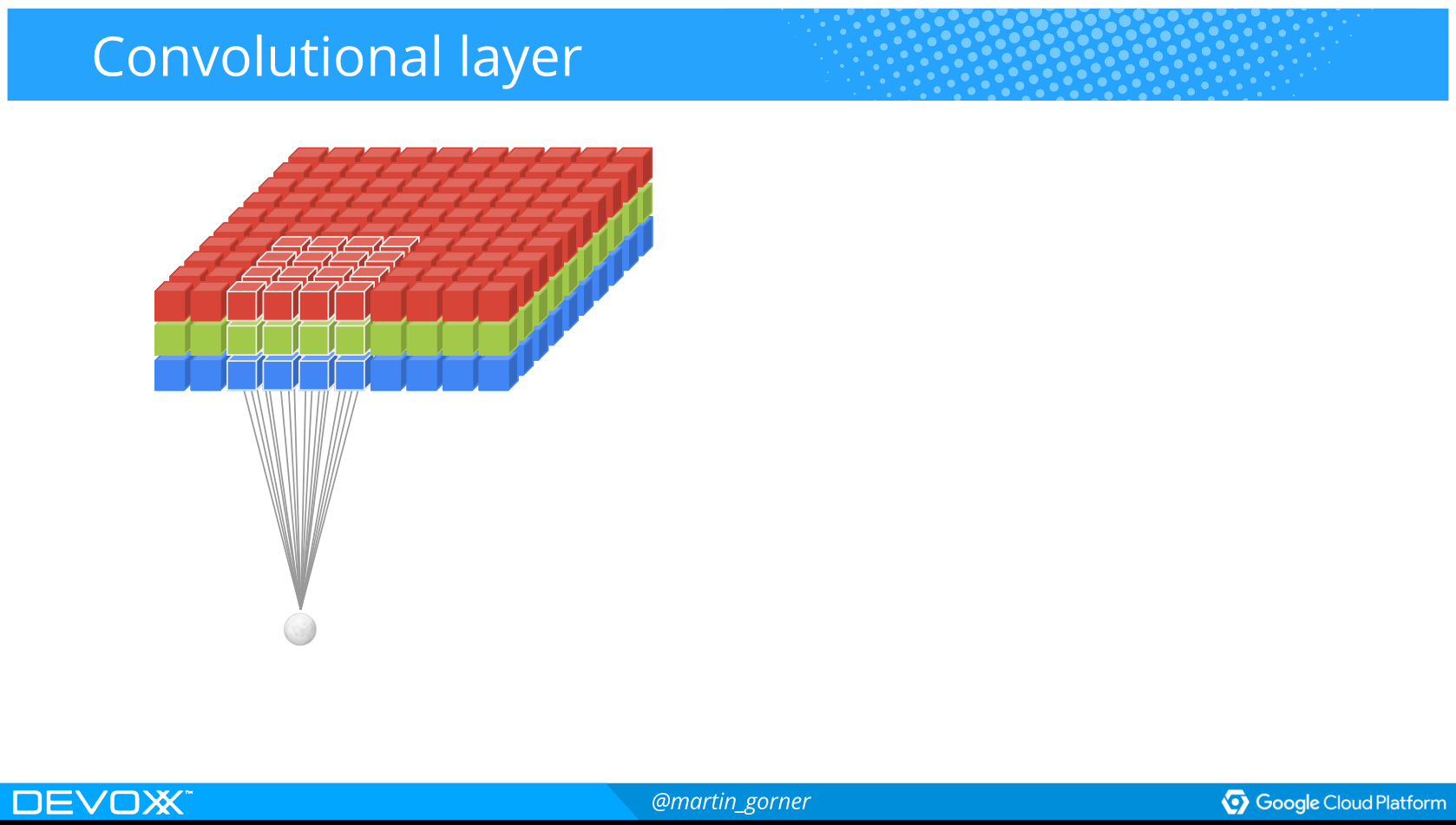
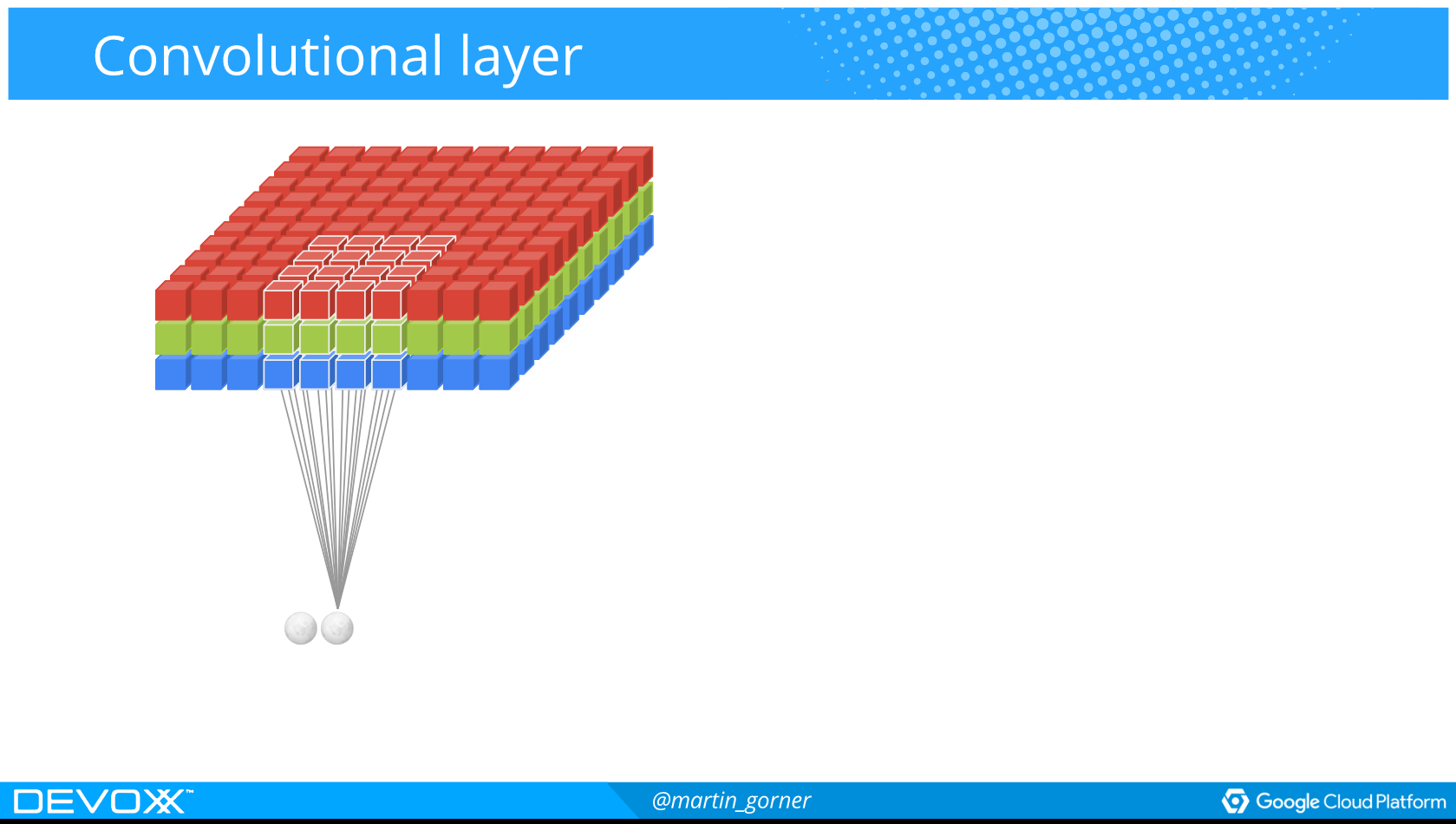
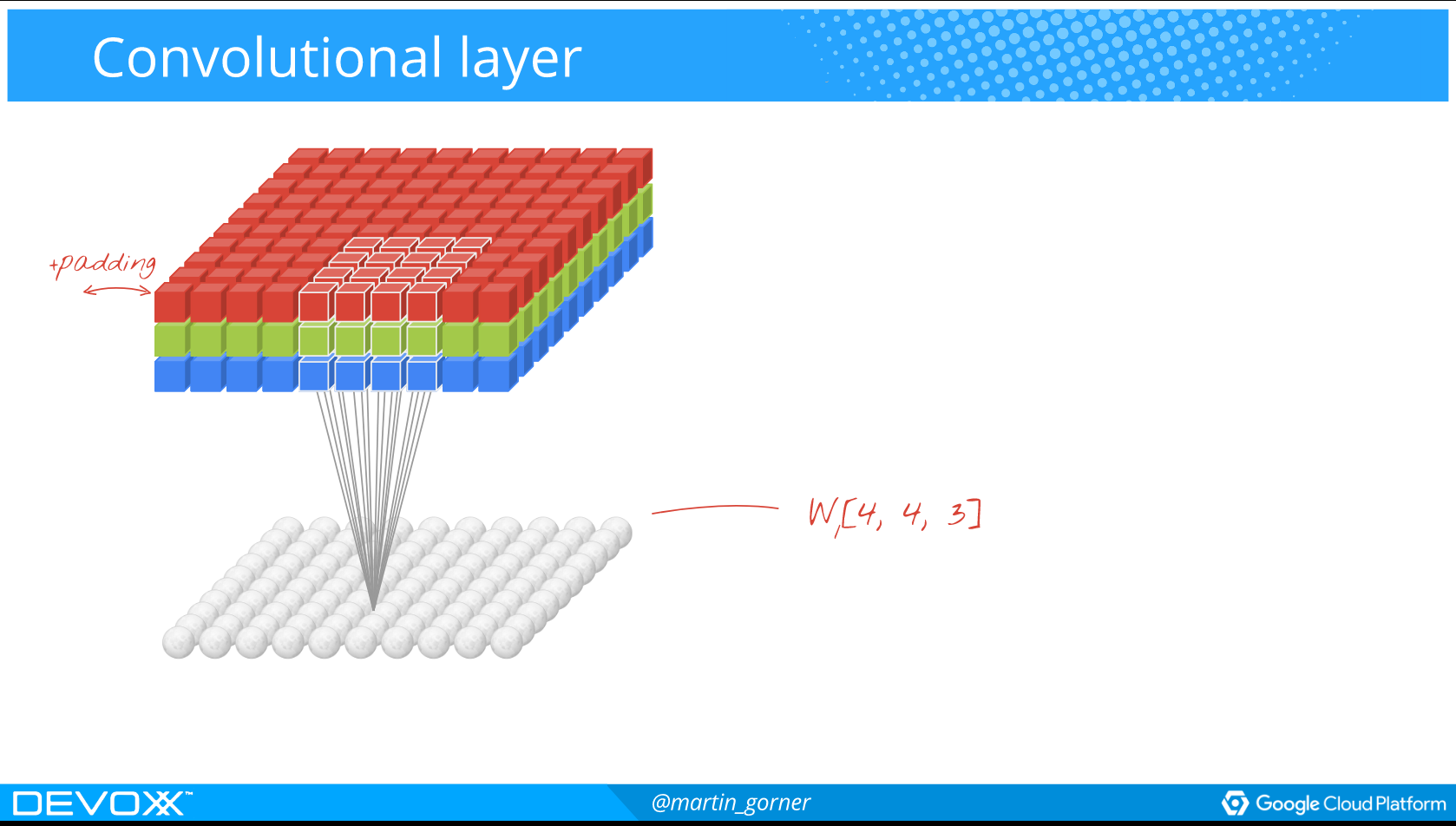
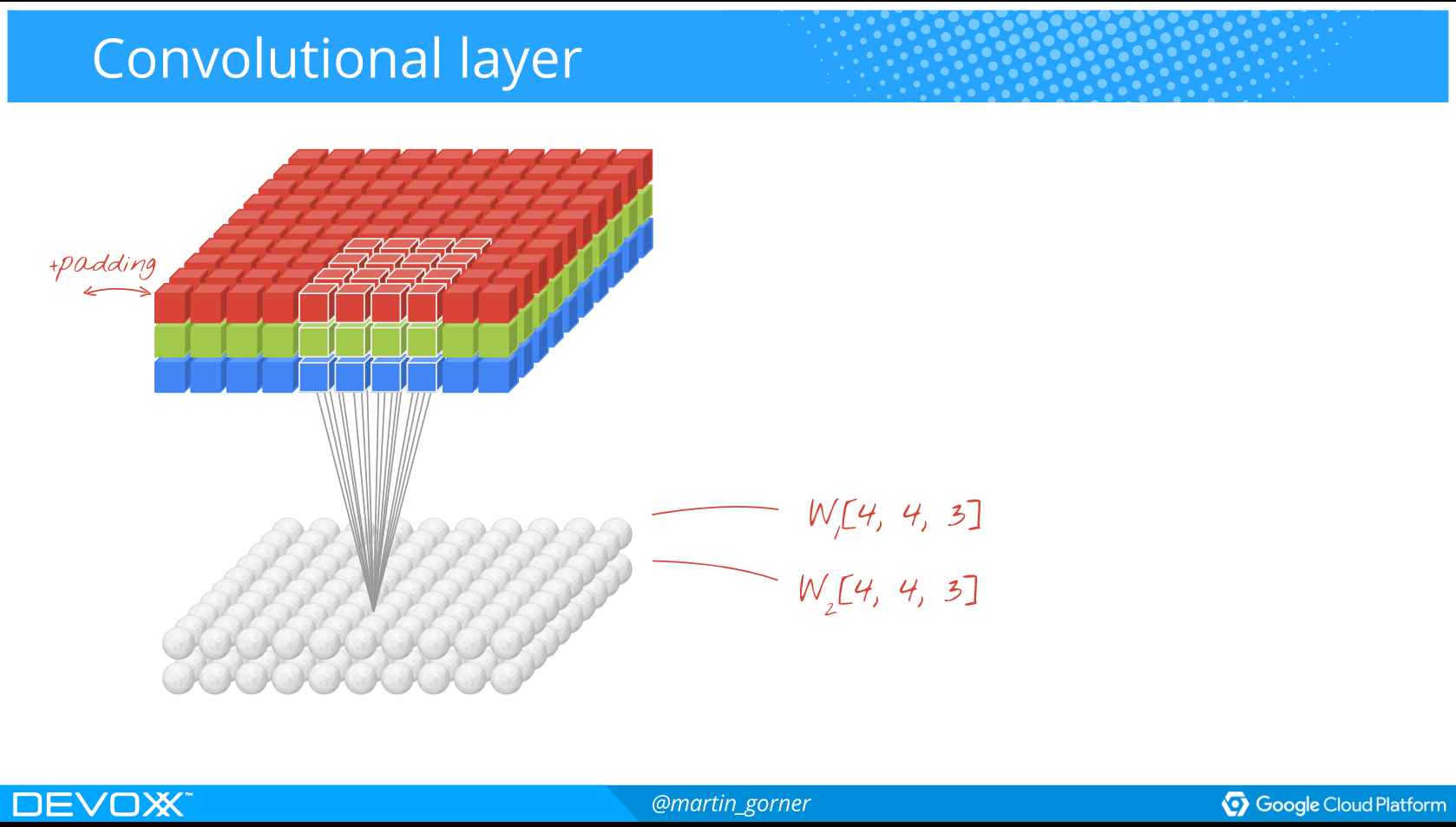
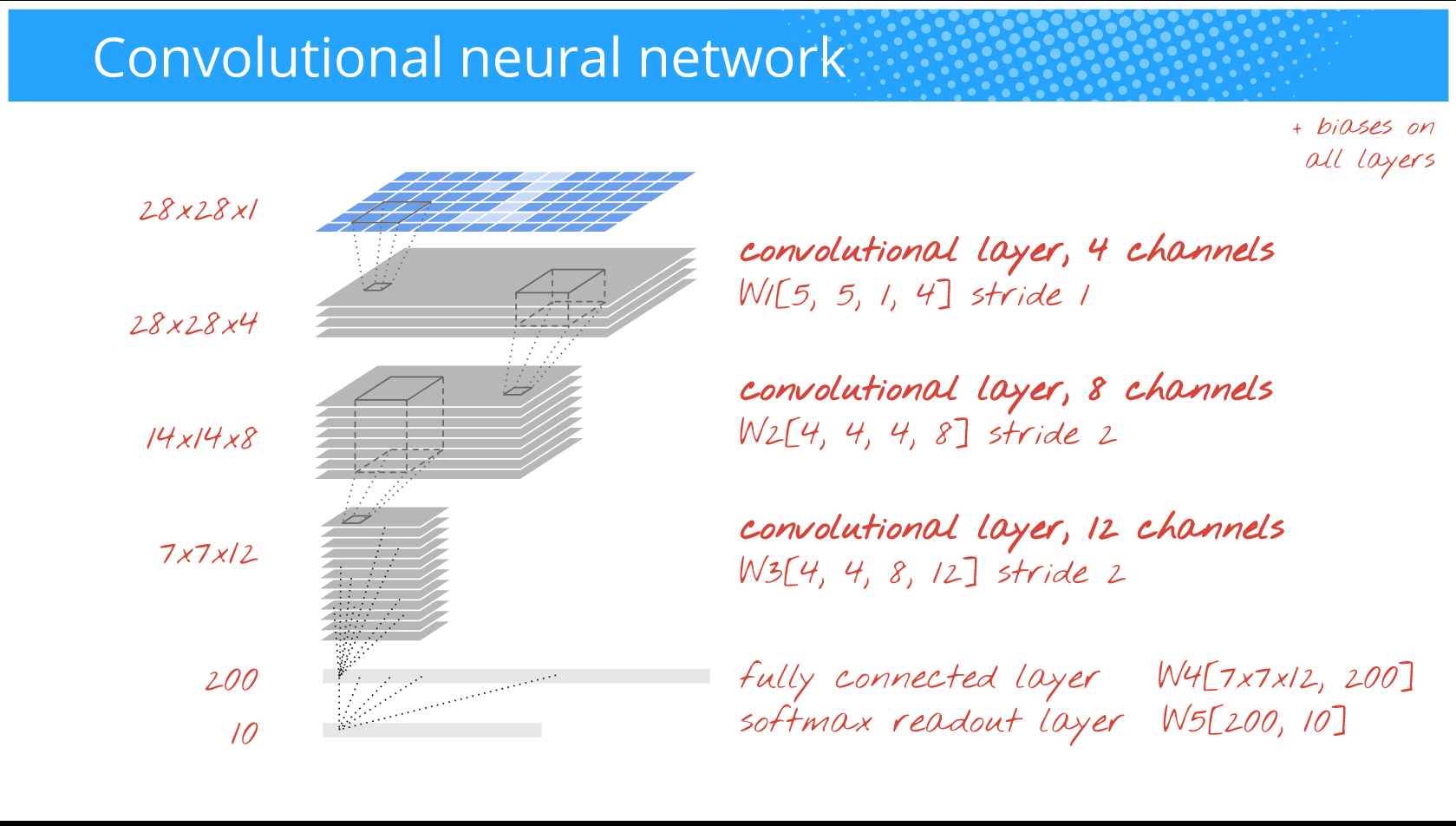
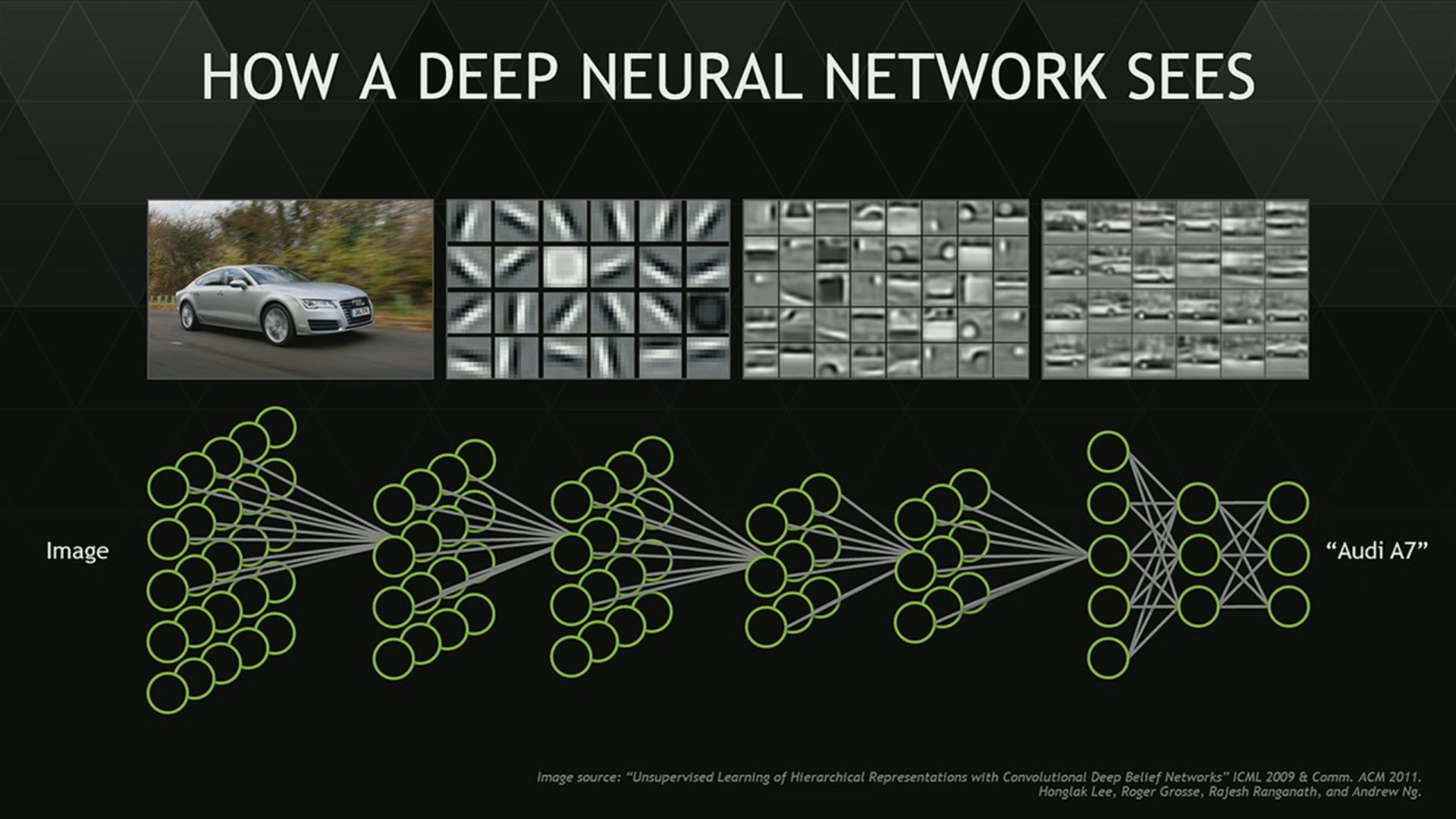
Hvordan spiller man Atarispil?
- Observer skærmen
- Forudse hvad det bedste træk vil være (højre, venstre, skyd)
- Udfør bedste træk
- Observer resultatet
- Gentag 1-4 indtil man er død
state = game.start()
while(isNotDead(state)):
pixels = state.getPixels()
rewards = gameExperience.predict(pixels)
bestAction = getBestActionFromRewards(rewards)
state = game.move(bestAction)
updateGameExperience()
Algoritmen i den simpleste form
Første problem:
Finde ud af, hvordan man kan spille "Breakout" via et program
Atari Learning Environment + OpenAI Gym
env = aleGym.make('BreakoutDeterministic-v0')
env.start()
while True:
env.render()
# Random action
action = env.getRandomAction()
next_state, reward, is_dead, info = env.doAction(action)
if is_dead:
env.start()En Atari agent der spiller for evigt, med random actions
Reinforcement Learning (RL)
- Neuralt netværk der løbende forbedres under træning
- Baseret på princippet om fremtidig belønning
Deep Q-network (DQN)
Går ud på at forudse det bedste træk, baseret på den beregnede Q værdi for forskellige mulige træk
Q(s,a)
Givet tilstand (s) og aktion (a), beregn Q
Forestil dig at du har den optimale funktion der kan beregne den fremtidige værdi af et træk




En tilstand består af 4 gråskalerede billeder
En aktion kan være enten:
- 0 - gør ingenting
- 1- skyd
- 2 - højre
- 3 - venstre
Q(s,a) beregner den estimerede fremtidige belønning, givet en tilstand og en aktion
- Q værdien bruges til at træne netværket ud fra en tilstand
Spørgsmålet vi ønsker at stille er:
Hvis jeg er i denne tilstand:
Hvad er så det bedste træk jeg kan lave?
Svar: [[0.3][0.1][1.665][0.6]]
Hvordan gør vi så?
Træning
- Input af start tilstand bestående af 4 gråskalerede og resized billeder, hver på 84 x 84 pixels
- Antal point for aktion
- Hvilken aktion (0, 1, 2, 3)
- Næste tilstand bestående af 4 gråskalerede og resized billeder, hver på 84 x 84 pixels
- Spørg hvad det eksisterende netværk ville prediktere som output på næste tilstand
- Output er en tabel med den beregnede Q værdi for den valgte aktion
- Nu trænes DQN med det beregnede output og starttilstanden
initialise Q(numstates,numactions) arbitrarily
observe initial state s
repeat
select and carry out an action a
observe reward r and new state s'
Q(s,a) = r + γ(max(Q(s',a')))
s = s'
until terminatedQ learning algoritme
Q(s,a) = r + \gamma(max(Q(s',a')))
- r = belønning
- \(\gamma\) = reduktion
- Q(s', a') = prediktion fra model for næste tilstand
DQN
1 point
Højre
Tilstand:
Næste tilstand:
Beregn Q
0.3
0.1
1.665
0.6
Træn
Prediktion
- Input af en tilstand bestående af 4 gråskalerede og resized billeder, hver på 84 x 84 pixels
- Output er en tabel med et element for hver mulig aktion
- Hvert felt i tabellen indeholder en Q værdi
- Det felt der har den højeste Q værdi vælges og den aktion der er knyttet til feltet, udføres
DQN
Tilstand
0.3
0.1
1.665
0.6
Hvorfor reducerer vi det maximale udfald af Q(s',a') ?
Det er svært at spå - især om fremtiden...
Robert Storm Petersen
Forudsige fremtiden i et stokastisk miljø:
Stokastisk = Når noget påvirkes af tilfældigheder
- Atari er for det meste stokastisk. F.eks. starter hvert spil med en tilfældig bold, så vi kan aldrig forvente at være nøjagtig ens, baseret på samme aktioner
- Pga. dette skal vi reducere estimerede belønninger - prisen for usikkerhed
- Jo længere ind i fremtiden vi forsøger at estimere, jo større afvigelse og jo mindre kan vi regne med det
\(\gamma\)
Gamma:
Sat til 0.95 fordi det giver det bedste resultat, når vi ser 4 skridt ind i fremtiden
Eksempel:
- max(Q(s',a')) af næste tilstand er 0.7
- Belønning for den aktuelle aktion er 1
- Reduktion (gamma) er 0.95
- Aktion er 2 (højre)
1 + (0.95 x 0.7) = 1.665
Netværket trænes med 1.665 der lægges ind på pladsen for "højre" for den aktuelle tilstand
[0.45][0.23][1.665][0.7664]
Q(s,a) = r + \gamma(max(Q(s',a')))
Implementering af DQN
Deep Q-network algoritme
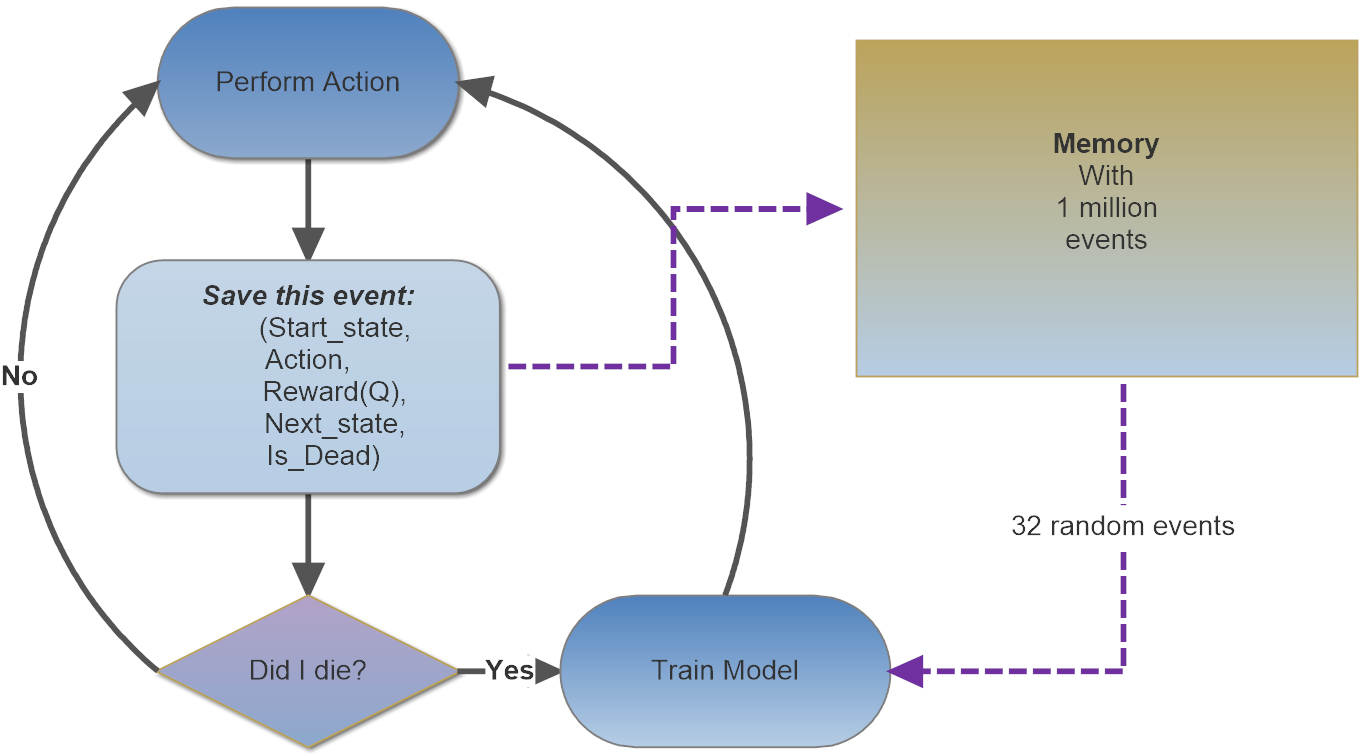
initialize replay memory D
initialize action-value function Q with random weights
observe initial state s
repeat
select an action a
with probability ε select a random action
otherwise select a = argmaxa’Q(s,a’)
carry out action a
observe reward r and new state s’
store experience <s, a, r, s’> in replay memory D
sample 32 random transitions <ss, aa, rr, ss’> from replay memory D
calculate target for each minibatch transition
if ss’ is terminal state then tt = rr
otherwise tt = rr + γ (max(Q(ss’, aa’)))
train the Q network
s = s'
until terminatedOptimeringer for DQN
DQN skal have nogle specifikke optimeringer
- Experience replay
- Target network
- Exploration-Exploitation
Experience replay
- Optag hver tilstand og det træk der blevet lavet, samt resultatet
- Når et bestemt antal træk er nået, så træn netværket med resultaterne
- Gem alle træk i hukommelsen - max 1.000.000
Target network
- Opret et netværk der kan spørges (target)
- Opret et netværk der kan trænes på
Formålet er at stabilisere træningen fordi target netværket ikke hele tiden opdateres
Exploration-exploitation
Bruges til at prøve forskellige træk af under træning og over tid opnå viden, så vi kan mindske eksperimenterne, men aldrig helt stoppe med dem
- Benyttes for at prøve alle muligheder
- I starten vil vi altid vælge en random aktion
- \(\epsilon\) styrer hvor meget random faktoren er
- Mindskes over tid med faktor 0.0025 (learning rate)
- Styrer om man spørger modellen eller vælger random
- Der vil altid være en smule random for at kunne udfordre kendt viden
Det faktiske neurale netværk er 3 x convolutional network med et fully connected layer med 512 neuroner
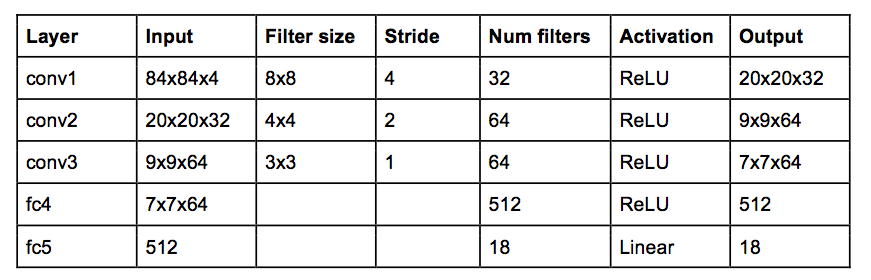
Koden ser såleds ud:
_model = Sequential()
_model.add(Permute((2, 3, 1), input_shape=(4,)))
_model.add(Convolution2D(32, 8, 8, subsample=(4, 4), input_shape=(84, 84, 4)))
_model.add(Activation('relu'))
_model.add(Convolution2D(64, 4, 4, subsample=(2, 2)))
_model.add(Activation('relu'))
_model.add(Convolution2D(64, 3, 3, subsample=(1, 1)))
_model.add(Activation('relu'))
_model.add(Flatten())
_model.add(Dense(512))
_model.add(Activation('relu'))
_model.add(Dense(action_size))
_model.add(Activation('linear'))Eneste problem er at ...
DET VIRKER IKKE!!!
Der benyttes mange tricks for at få det til at virke:
- Error clipping
- Reward clipping
- Gradient clipping
- og andre småtricks...
Alle tricks har til formål at stabilisere træningen af netværket!
Demo
Hvad så nu?
"First, do the simple thing then apply intelligence",
Thad Starner, Georgia Institute of Technology
Uncle Bob siger at en dag vil en software bug dræbe 10.000 mennesker

Problemet med AI er gennemskueligheden i hvorfor den når frem til et resultat
Human/Machine teams
- Mennesker og maskiner finder løsninger i fællesskab
Sources:
Terminology:
- Prediction: Ask the model for a result from data
- Network: The construct that calculates the model and is used to make predictions on data
- Model: The trained knowledge of how to make predictions for this specific problem
- Training: Feed categorised data into the network and ask it to produce a model that can map the input data to the expected result
- Error: How far the calculation was from the expected result is called the "error"
- Hyper parameters: Parameters used to calibrate the network for a specific problem
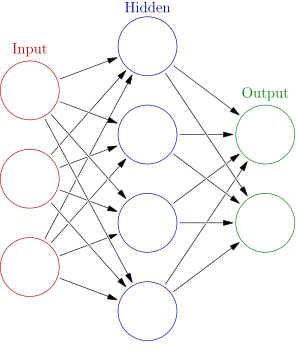
Artificial Neural Network
Originally an idea from late in the 1940's
Neural network
Deep Learning
Multilayered neural networks
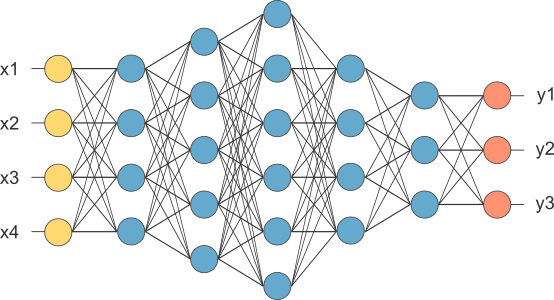
Universal approximation algorithm
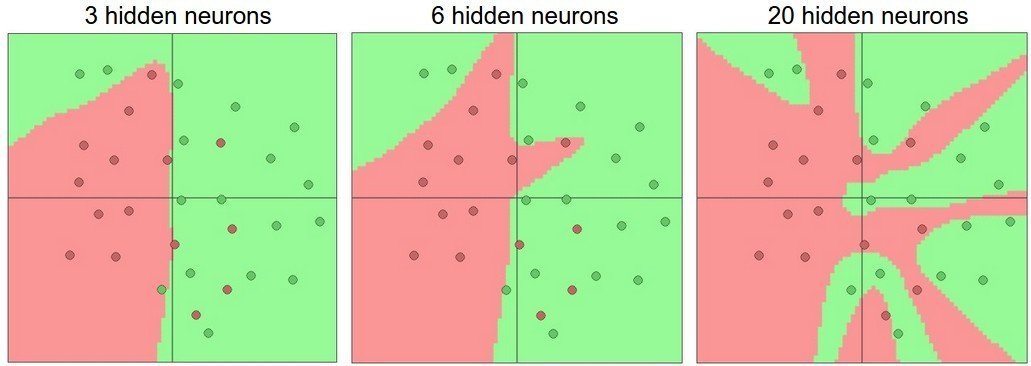
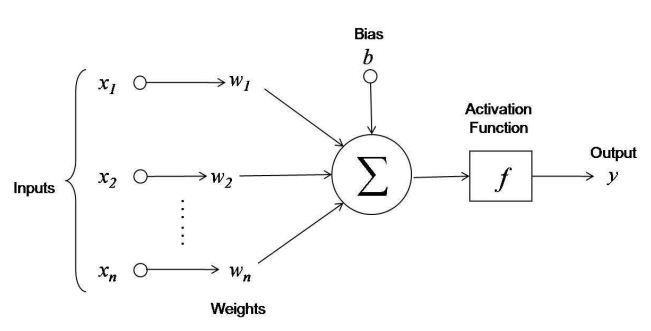
Neurons is the building blocks
Great for image recognition and complex categorisation with large datasets
Is all good then???
Need LOTS of data!
Training takes long time
No defined approach for calibrating hyper parameters
Basically: Trial/Error
Goal is to minimise the error for a prediction
Convolutional networks
Used for image recognition
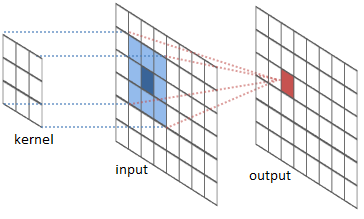
Used to extract specific "features" from an image
Lær at spille Atarispil med AI
By Søren Pedersen


