資訊期末報告
27 鄭向晴、33 簡千皓、34 簡伯寰
目錄
選定題目
挑選適當的資料
能夠做研究
讀出資料 & 繪製圖表
把大量數據
變成可視化圖表
問題與思考
中途遇到的問題
與解決方式
總結
關於資料
未來展望
Q & A
任何指教
選定主題
初始想法
我們一開始是先選定了幾個有興趣的題目再去老師提供的網站找資料集
大概有:
- 台灣發生交通事故的數量與種類
- 搜尋關鍵字的統計
- 大學生畢業的學歷與薪資關係
不過,我們發現亂想題目的化根本不會有對應的資料集
所以就先去看看有哪些資料集再決定要什麼主題
新冠肺炎數據
紐約時報有提供每天美國新冠肺炎確診案例的數據
新冠肺炎數據
紐約時報有提供每天美國新冠肺炎確診案例的數據
就決定是你了
主題:分析美國各州在各時期疫情的數據
讀出資料 & 繪製圖表
資料結構
date, county, state, fips, cases, deaths該資料表有以下欄位:
然後總共大約有 \(1.18 \times 10^6\) 個資料
Debug 超難!
裸的程式碼
import os
import dotenv
dotenv.load_dotenv()
import pandas as pd
import matplotlib.pyplot as plt
# Load your dataset
# Replace 'your_dataset.csv' with the actual filename or path to your dataset
df = pd.read_csv(os.getenv("SOURCE_URL"))
# Ensure 'date' column is in datetime format
df['date'] = pd.to_datetime(df['date'])
# Sort the DataFrame by date
df = df.sort_values(by=['state', 'date'])
# Aggregate the data to handle duplicates
# (summing daily cases for the same date and state )
df_agg = df\
.groupby(['date', 'state'], as_index=False)['cases']\
.sum().reset_index()
# Pivot the DataFrame to have 'date' as the index and columns for each state
pivot_df = df_agg.pivot(index='date', columns='state', values='cases')
# Plot the stacked bar chart
ax = pivot_df.plot(kind='bar', stacked=True, figsize=(12, 8))
# Set x-axis ticks every N days (adjust N as needed)
ax.xaxis.set_major_locator(plt.MaxNLocator(7))
plt.title('Daily Stacked Bar Chart of COVID-19 Cases Over Time by State '
+ 'and Total Cases Across All States')
plt.xlabel('Date')
plt.ylabel('Number of Daily Cases')
plt.legend(title='Location', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.grid(True)
plt.tight_layout()
plt.show()
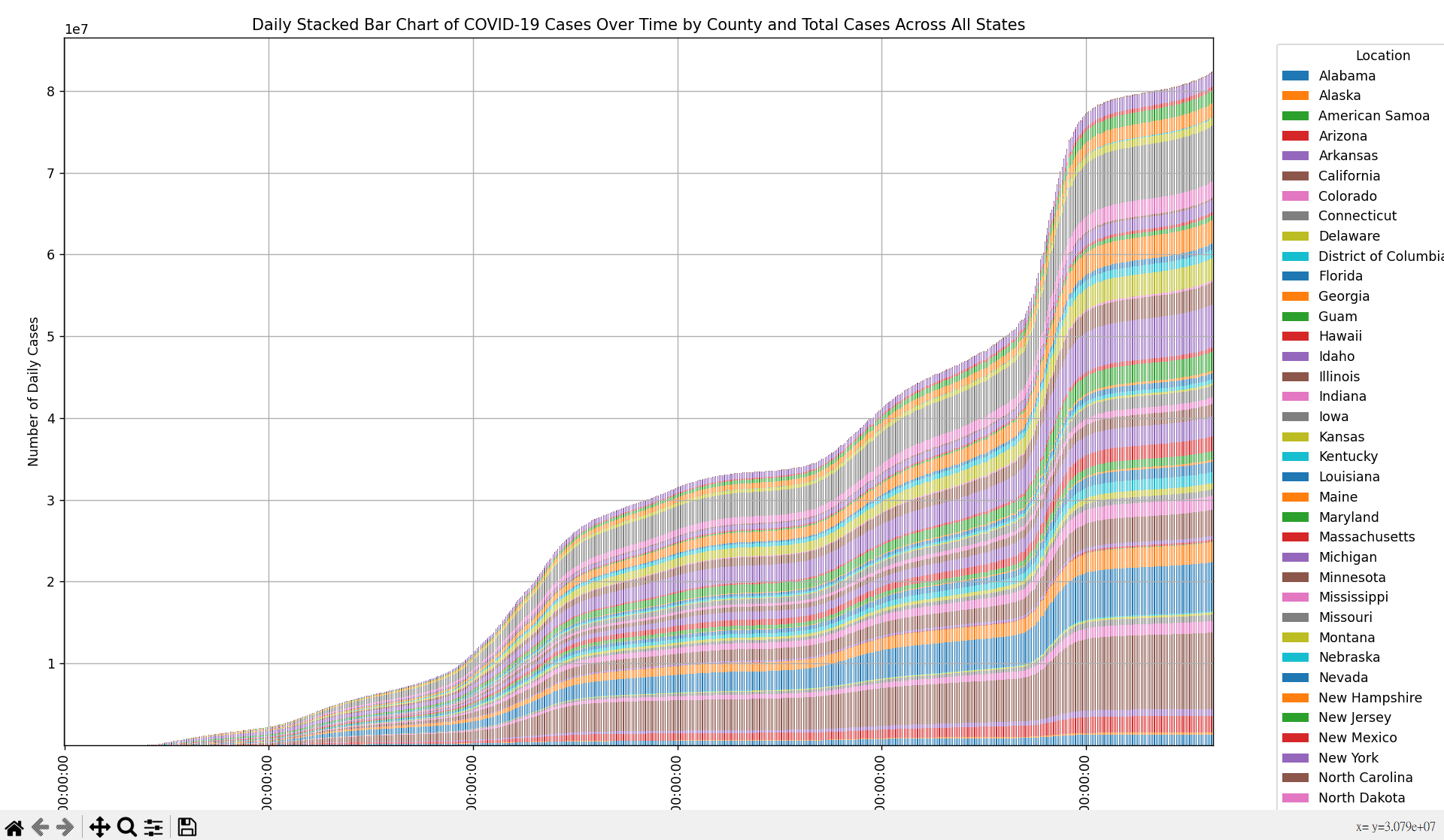
顯示這張圖表大概用掉我 8G 記憶體
然後這個視窗有 10 秒的延遲
問題與思考
問題 1
我發現,每天的確診數長那樣好像不太正確
# Calculate daily cases for each state
df['daily_cases'] = df.groupby('state')['cases'].diff().fillna(df['cases'])他看起來像是累計的
所以我多做了處理:
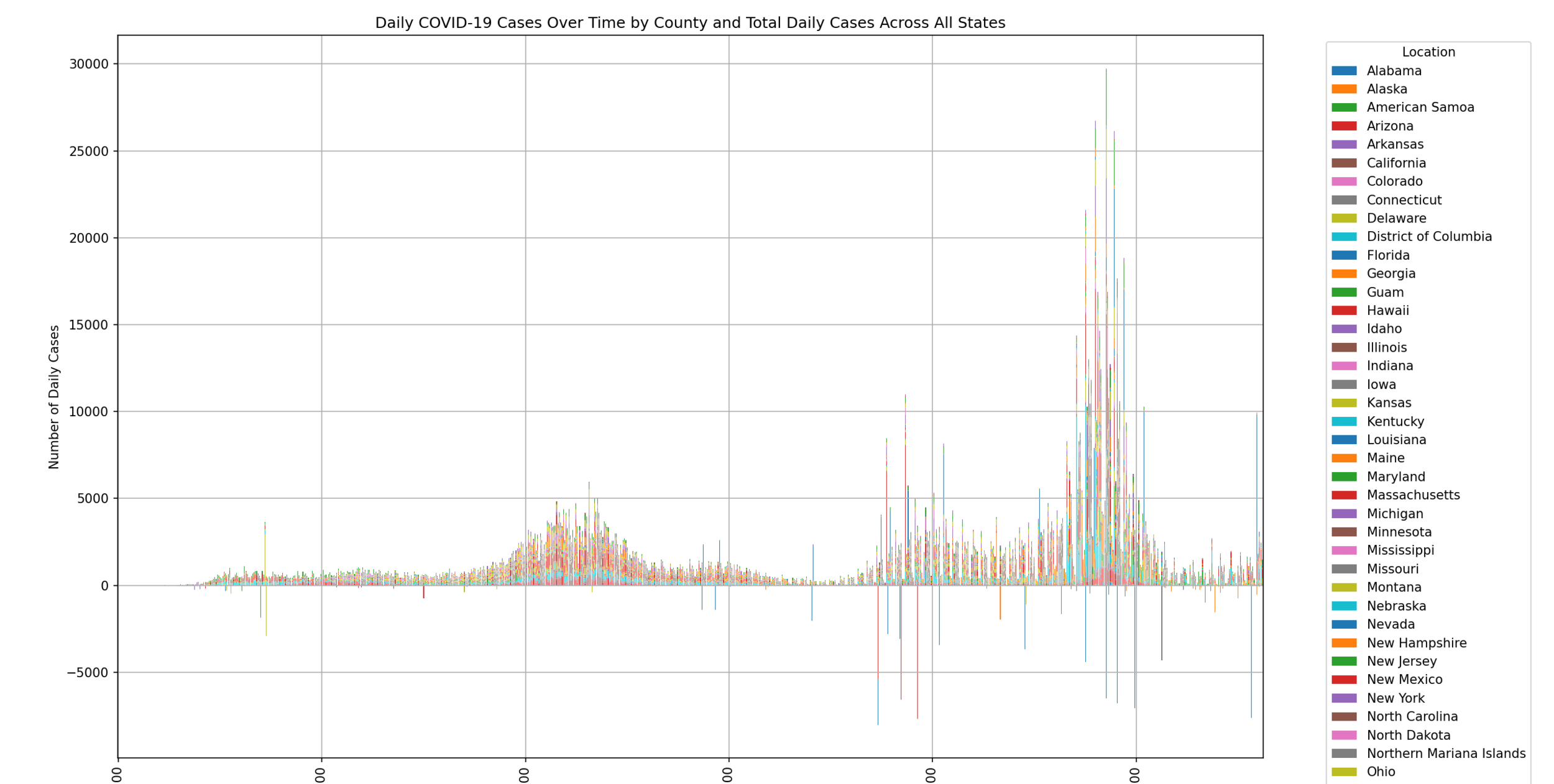
問題 2
我的每日確診數處理後就出現了負的值
那我也不知道為什麼 可能他在校正回歸
# Replace negative daily_cases values with the previous day's value
df['daily_cases'] = df.groupby('state')['daily_cases']\
.apply(lambda x: x.where(x >= 0, x.shift()))# Replace negative daily_cases values with the previous day's value
df[df['daily_cases'] < 0] = np.nan
df['daily_cases'] = df['daily_cases'].ffill()這個問題解決不了 這兩種方法都沒用 :(
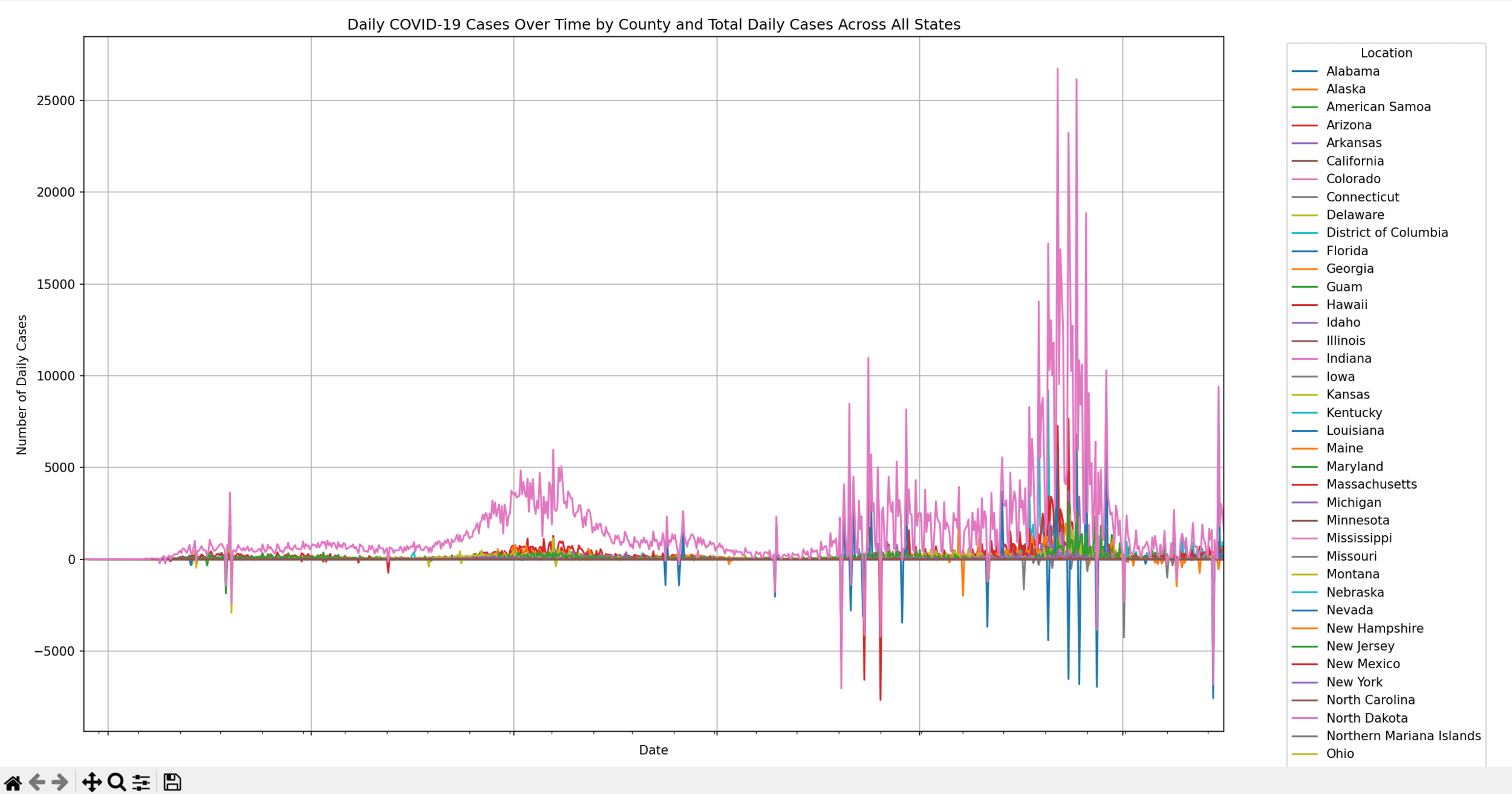
問題 3
不過我發現數值會起伏不定,不連續的狀況
可以透過每天取最近 14 天的平均值,讓他更滑順一點
# Calculate the 14-day rolling average for each county
df_agg['14day_avg'] = df_agg.groupby('state')['daily_cases']\
.transform(lambda x: x.rolling(window=14).mean())
# Pivot the DataFrame to have 'date' as the index and columns for each state
pivot_df = df_agg.pivot(index='date', columns='state', values="14day_avg")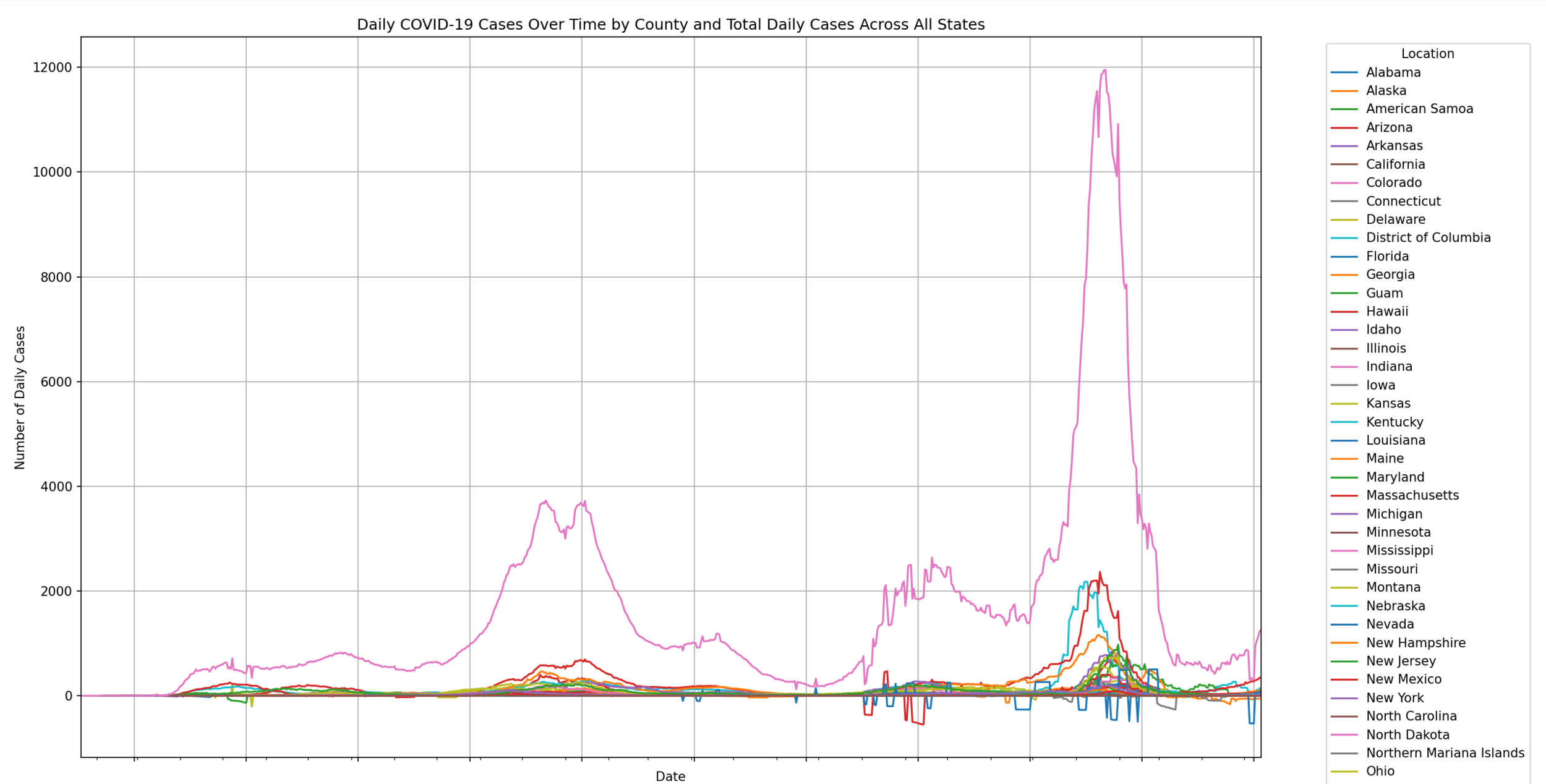
import os
import dotenv
dotenv.load_dotenv()
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Load your dataset
# Replace 'your_dataset.csv' with the actual filename or path to your dataset
df = pd.read_csv(os.getenv("SOURCE_URL"))
# Ensure 'date' column is in datetime format
df['date'] = pd.to_datetime(df['date'])
# Sort the DataFrame by date
df = df.sort_values(by=['state', 'date'])
# Calculate daily cases for each state
df['daily_cases'] = df.groupby('state')['cases'].diff().fillna(df['cases'])
# Aggregate the data to handle duplicates
# (summing daily cases for the same date and state )
df_agg = df\
.groupby(['date', 'state'], as_index=False)['daily_cases']\
.sum().reset_index()
# Calculate the 14-day rolling average for each county
df_agg['14day_avg'] = df_agg\
.groupby('state')['daily_cases']\
.transform(lambda x: x.rolling(window=14).mean())
# Pivot the DataFrame to have 'date' as the index and columns for each state
pivot_df = df_agg.pivot(index='date', columns='state', values="14day_avg")
# Add a new column for the total daily cases across all states
pivot_df['Total'] = pivot_df.sum(axis=1)
# Plot the line chart
ax = pivot_df.plot(kind='line', y=pivot_df.columns, legend='brief', figsize=(12, 8))
# ax = pivot_df.plot(kind='bar', stacked=True, figsize=(12, 8))
# Set x-axis ticks every N days (adjust N as needed)
N = 14
ax.xaxis.set_major_locator(plt.MaxNLocator(N))
plt.title('Daily COVID-19 Cases Over Time by County and Total Daily Cases Across All States')
plt.xlabel('Date')
plt.ylabel('Number of Daily Cases')
plt.legend(title='Location', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.grid(True)
plt.tight_layout()
plt.show()
未來展望
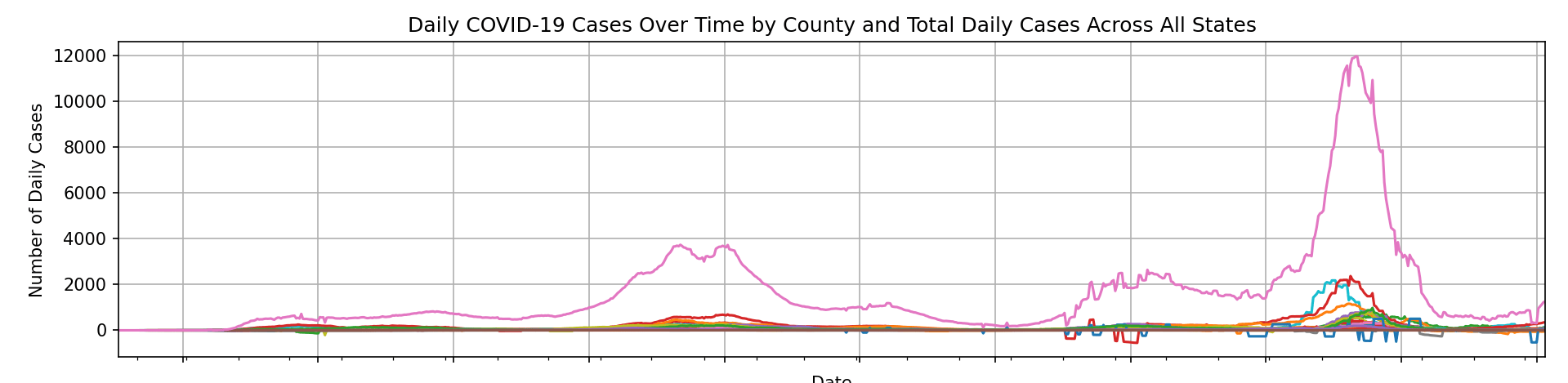
接續研究
因為這次時間緊湊,而且我都在修 Bug
最後只有把圖表畫出來,沒有更深入的研究
如果還有時間,有以下幾點可以參考:
- 分析不同州、地區或大都會區的 COVID-19 病例和趨勢有何不同
- 在高峰或低峰時期發生了什麼事?可以深入研究各種政策對於控制疫情的效果
- 將 COVID-19 數據與其他國家進行比較,以深入了解全球趨勢和應對措施
Q & A
謝謝大家

附上一張 Panda 在處理資料的圖
資訊期末
By 晴☆



