Supervised Knowledge May Hurt Novel Class Discovery Performance
Ben Dai (CUHK)
(Joint work with Li, Otholt, Hu, Meinel, and Yang)
IMS China 2024

NCD Background
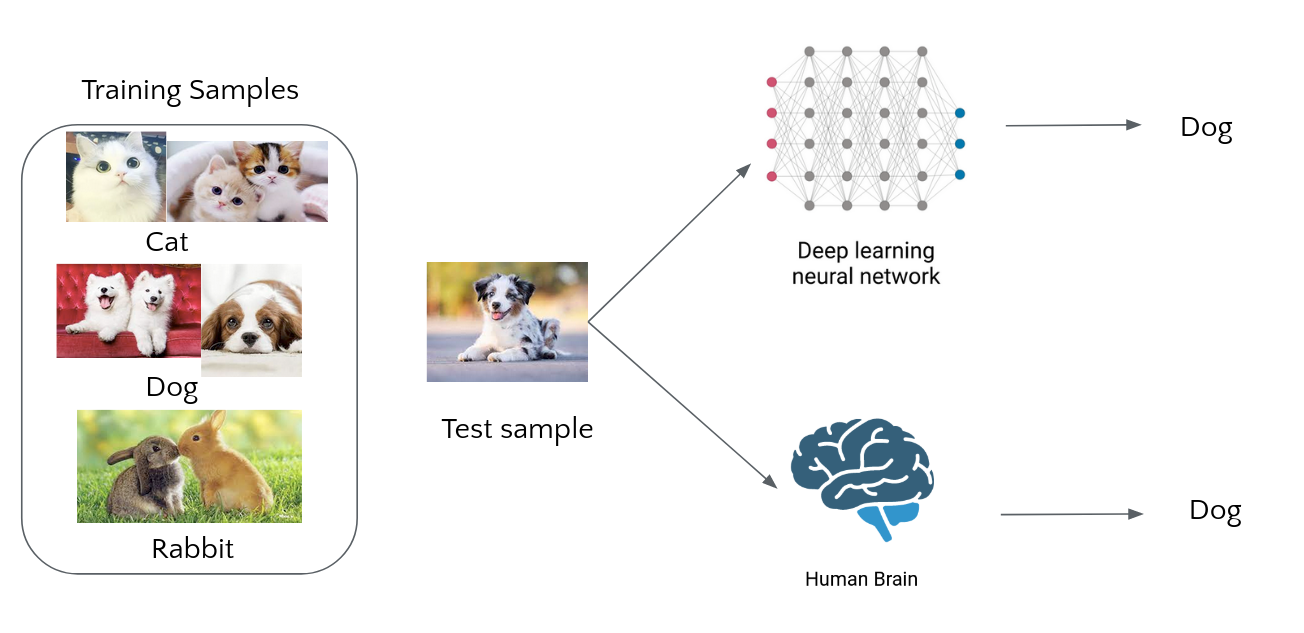
Novel class discovery (NCD) is a machine learning task focused on finding new classes in the data that weren't available during the training period.
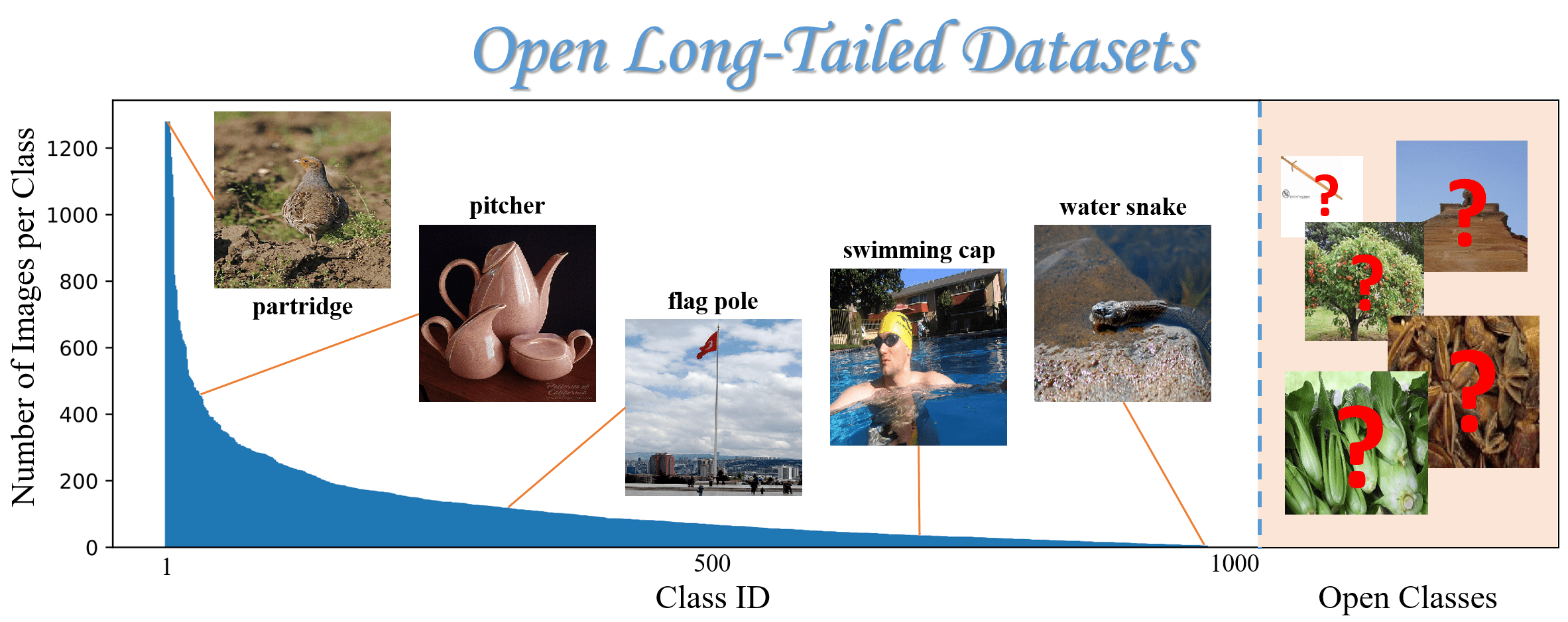
Liu, Ziwei, et al. "Large-scale long-tailed recognition in an open world." CVPR. 2019.
NCD Background
NCD Background
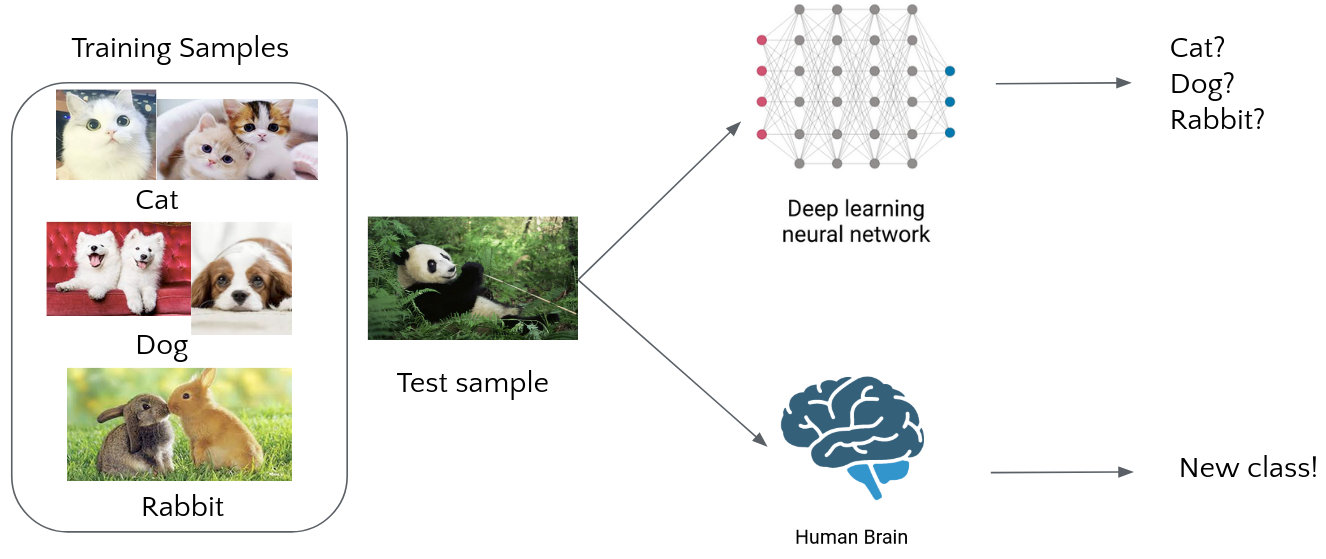
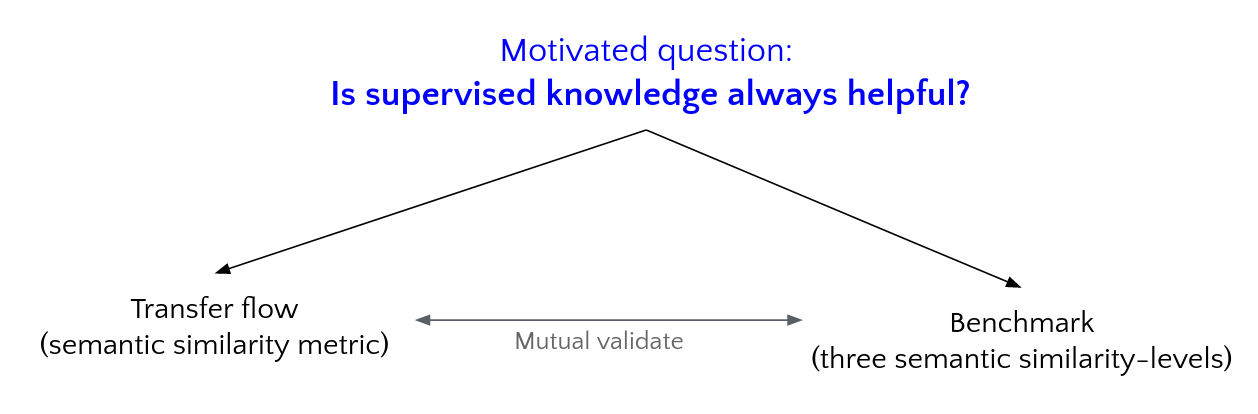
How can we borrow supervised knowledge and break the category constrain?
NCD Background
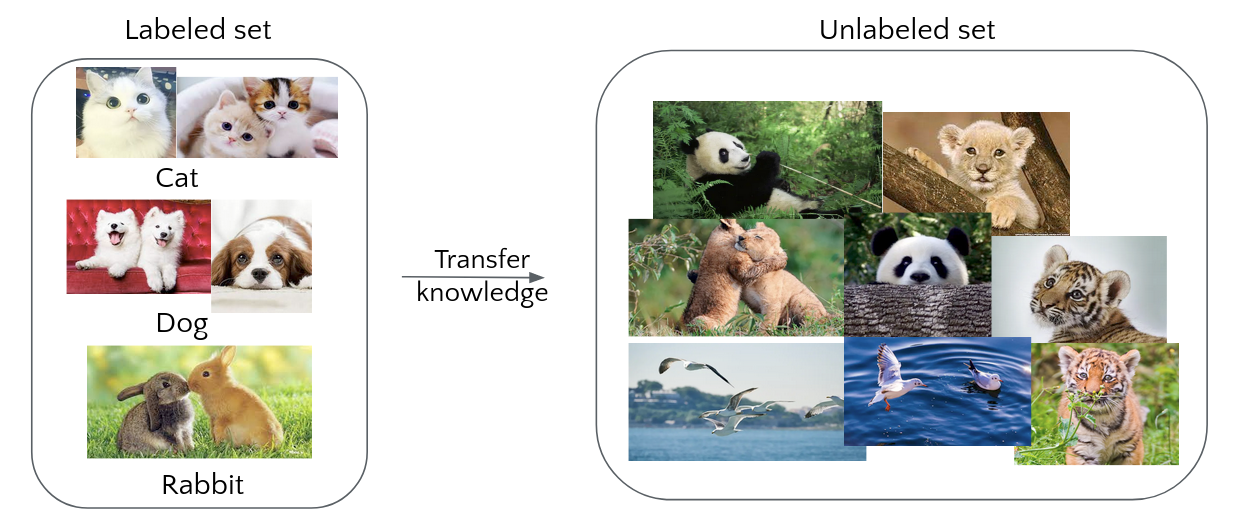
NCD: Existing Methods
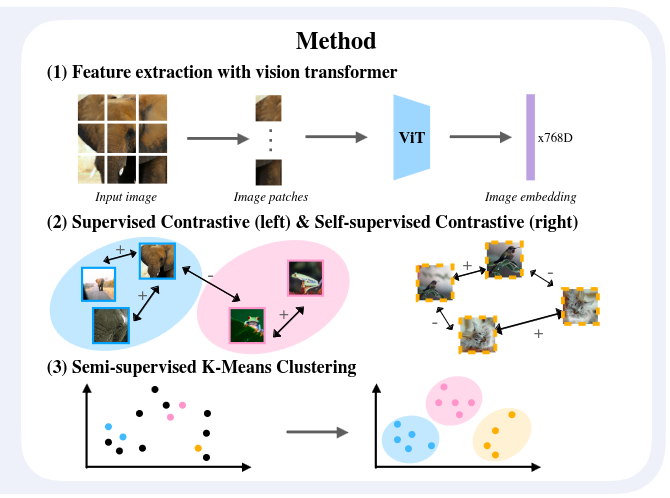
Vaze et al (CVPR 2022) Generalized Category Discovery
NCD: Existing Methods
Fini et al (ICCV 2021) A Unified Objective for Novel Class Discovery
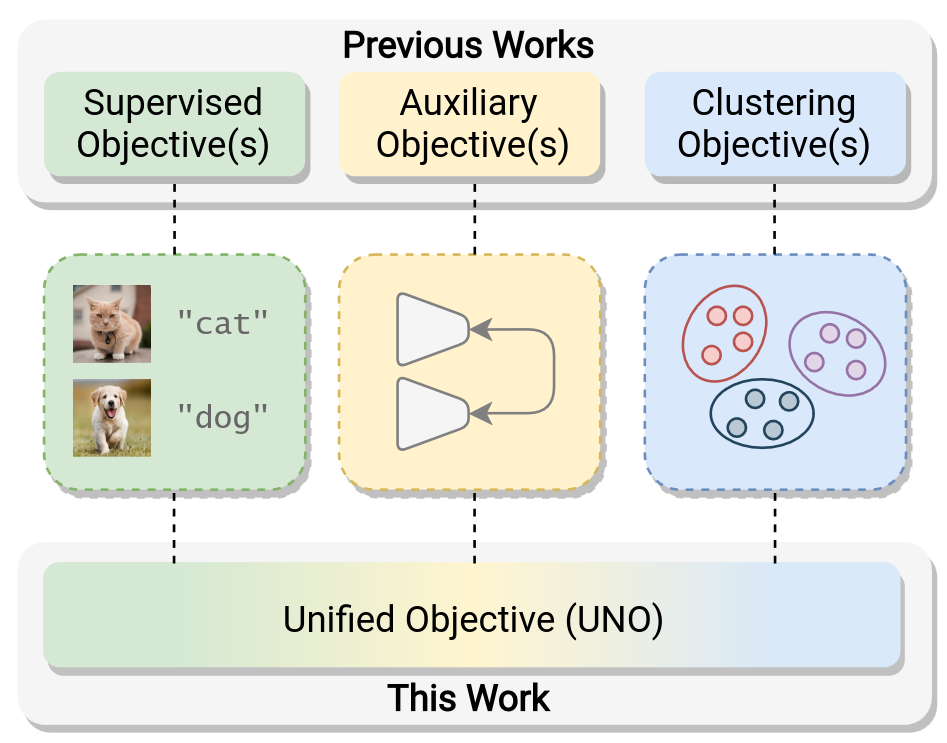
NCD: Existing Methods
Fini et al (ICCV 2021) A Unified Objective for Novel Class Discovery
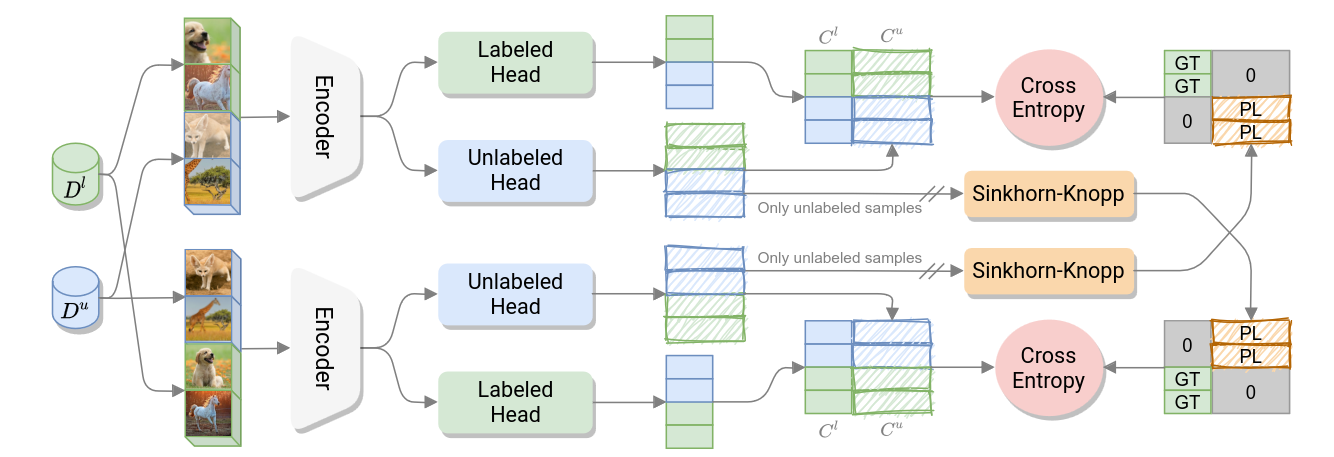
NCD: Existing Methods
What makes the implementation of NCD possible?
NCD: Existing Methods
What makes the implementation of NCD possible?
Supervised info \( \mathbf{X} | Y \)
NCD: Existing Methods
What makes the implementation of NCD possible?
Supervised info \( \mathbf{X} | Y \)
Unsupervised info \( \mathbf{X} \)
NCD: Existing Methods
Vaze et al (CVPR 2022) Generalized Category Discovery
NCD: Existing Methods
Fini et al (ICCV 2021) A Unified Objective for Novel Class Discovery
NCD: Existing Methods
DL:
DL typically assumes that more data is better, and the focus lies in designing different network structures to effectively utilize the available data.
STAT:
Statisticians always strive to clarify when and how to utilize data effectively in various situations/assumptions.
NCD: Existing Methods
DL:
DL typically assumes that more data is better, and the focus lies in designing different network structures to effectively utilize the available data.
STAT:
Statisticians always strive to clarify when and how to utilize data effectively in various situations/assumptions.
An interesting question:
Is more (supervised) data necessarily better?
From a practical perspective, we would like to propose a metric that can serve as a reference to guide us in determining which data to utilize, thereby avoiding the need to train a time-consuming, huge model unnecessarily.
NCD: Outline
DL:
- More data is better...
- design a DL architecture
STAT:
- under this kind of assumption you should ...
Step 1
Step 2
Step 3
NCD: Metric
NCD: Metric
Suppose we learn a mapping \(\mathbf{p}\) from training samples
How to measure the effectiveness of \(\mathbf{p}\)
NCD: Metric
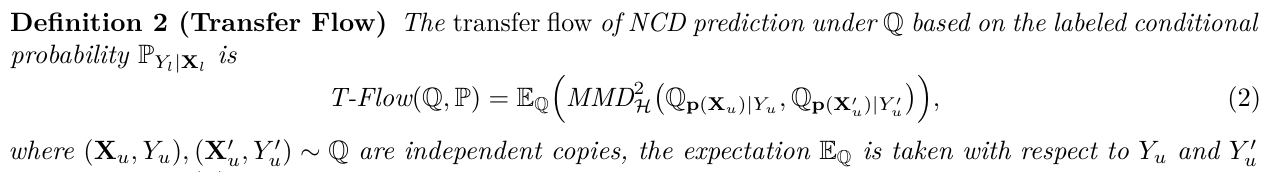
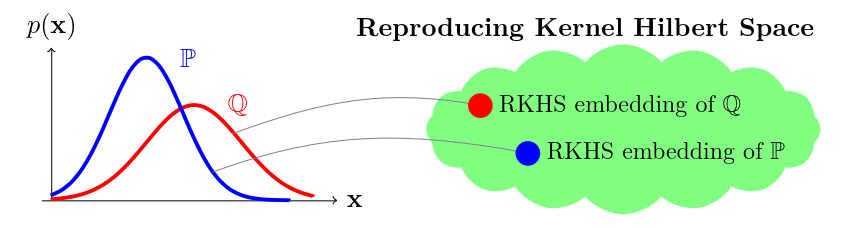
Recall: MMD
Muandet et al (2020) Kernel Mean Embedding of Distributions: A Review and Beyond
NCD: Metric
Recall: MMD
Muandet et al (2020) Kernel Mean Embedding of Distributions: A Review and Beyond
Fini et al (ICCV 2021) A Unified Objective for Novel Class Discovery
NCD: Metric
Yet, in practice, \(Y_u\) is unknown...

NCD: Benchmark
Step 1
Step 2
Step 3
NCD: Benchmark
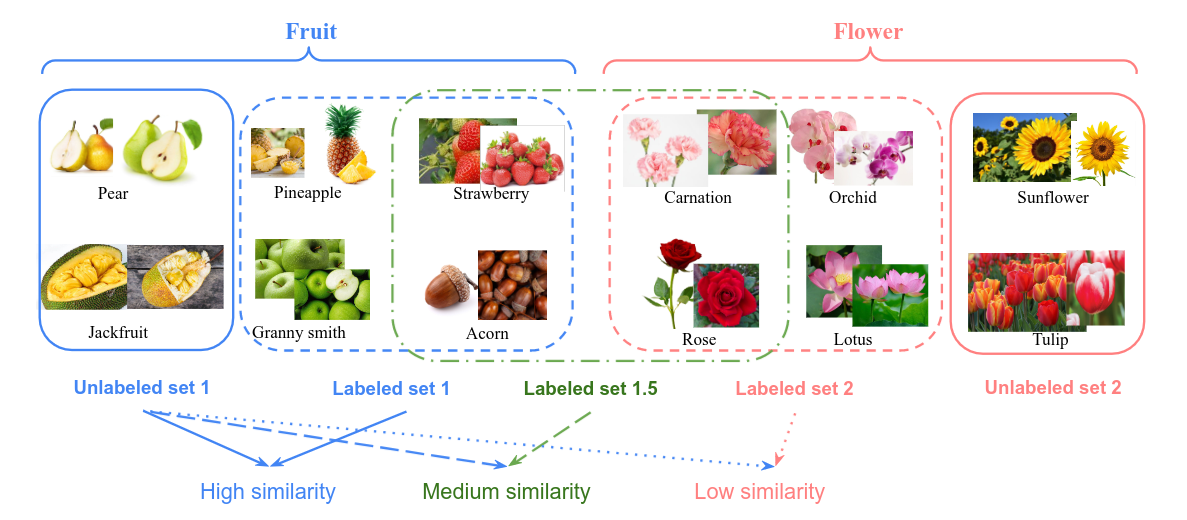
NCD: Benchmark
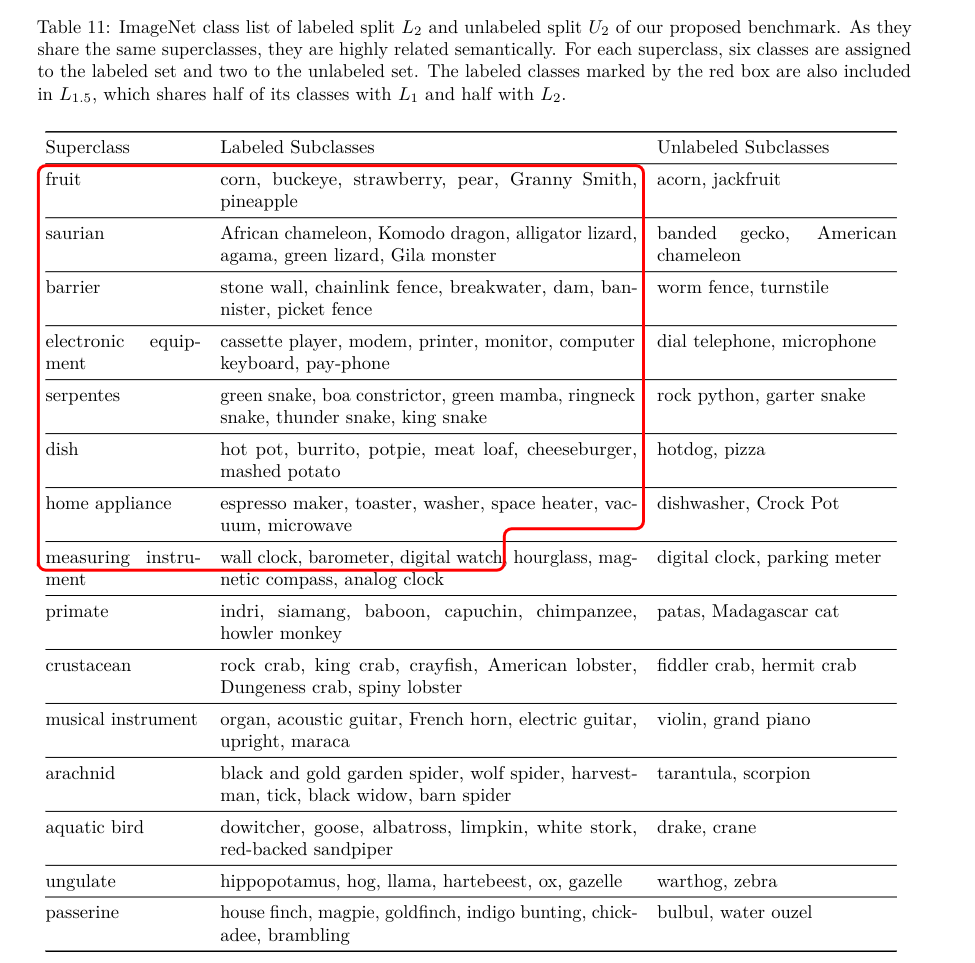
NCD: Benchmark
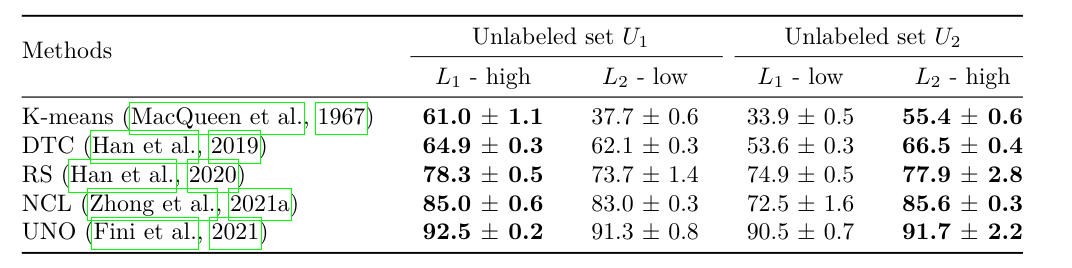
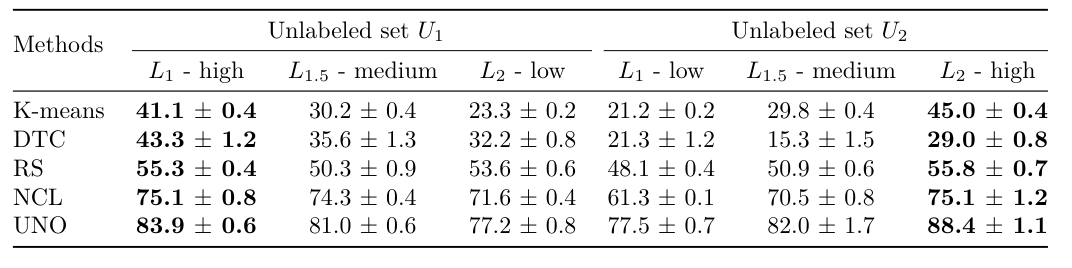
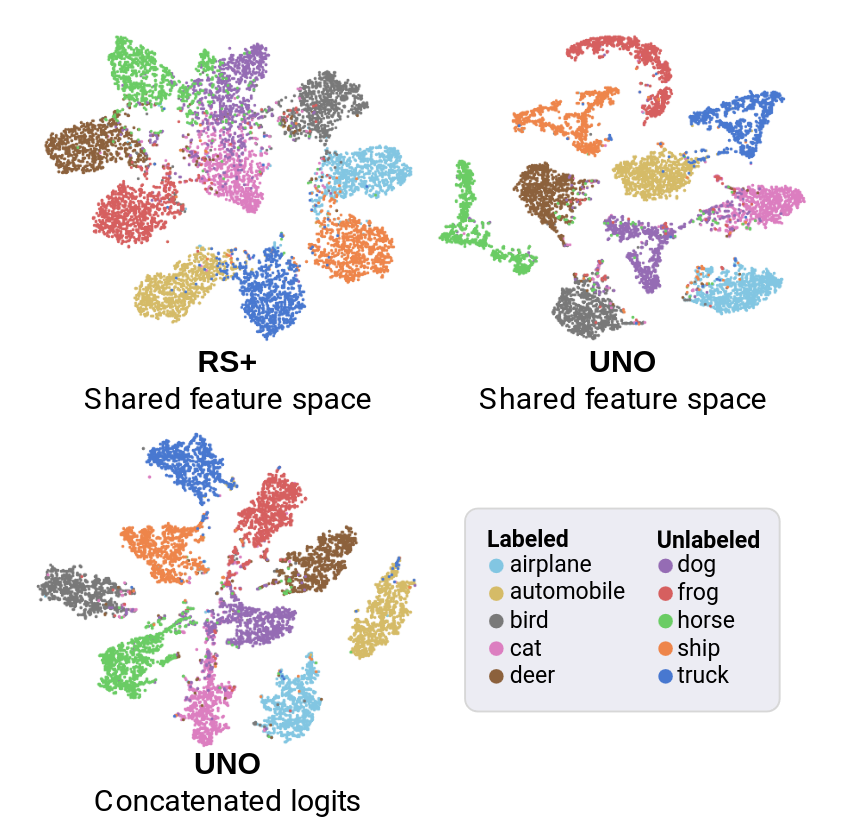
Conclusion: consistency between Semantic Similarity and Accuracy. The proposed benchmark is good...
NCD: Benchmark
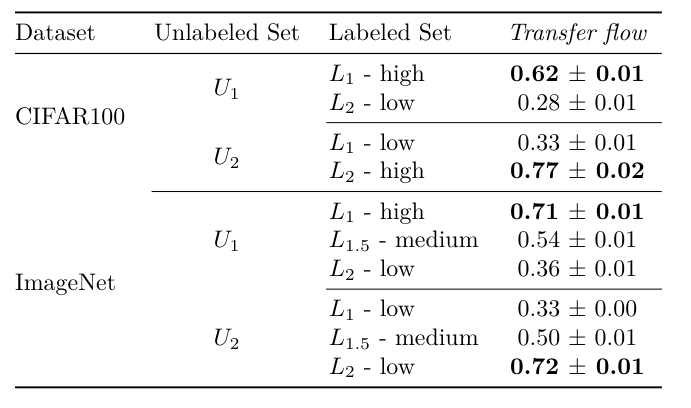

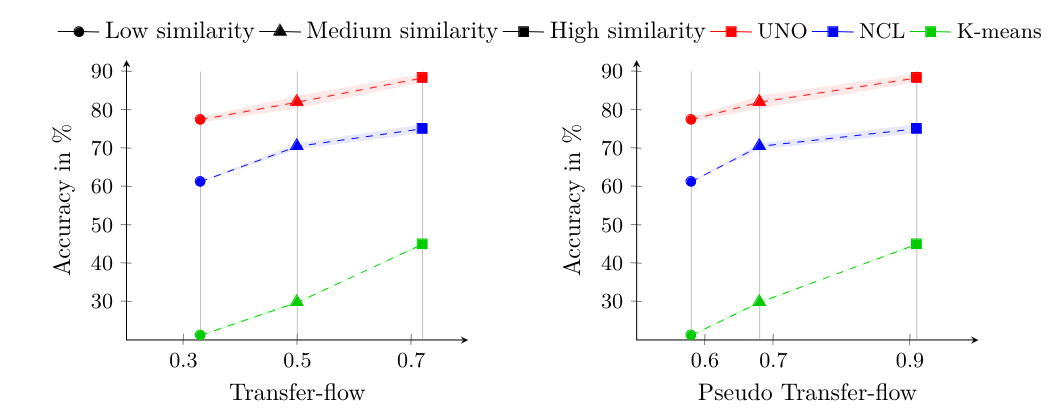
Conclusion: consistency among Semantic Similarity, Accuracy, and (pseudo) transfer flow. The proposed metric is good...
NCD: Supervised Info May Hurt
Step 1
Step 2
Step 3
Step 4
NCD: Supervised Info May Hurt

NCD: Supervised Info May Hurt
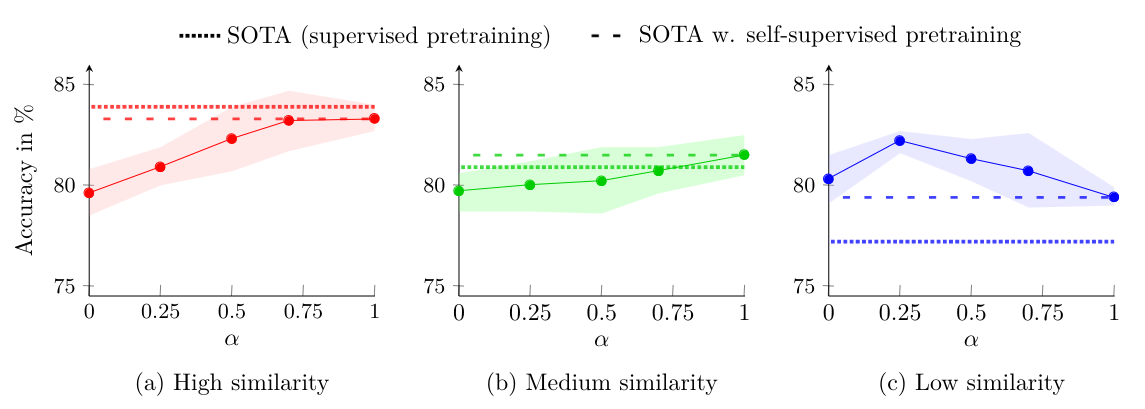
Suboptimal
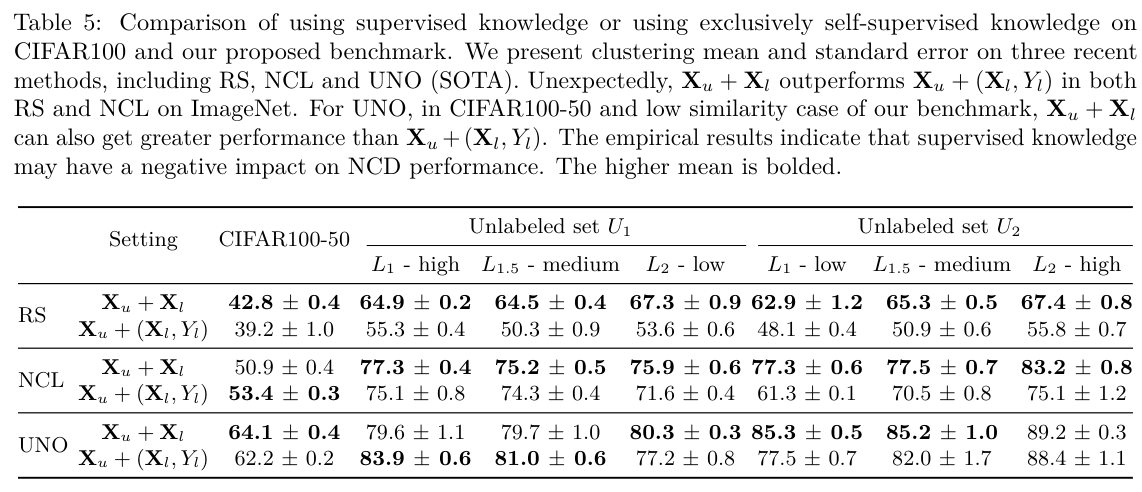
NCD: Supervised Info May Hurt
Conclusion: Supervision information with low semantic relevance may hurt NCD performance.
NCD: Supervised Info May Hurt
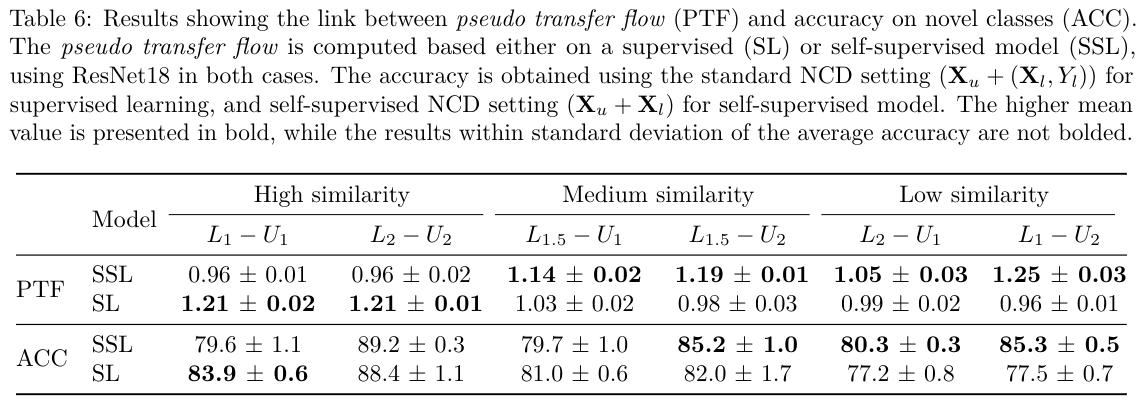
Conclusion: pseudo transfer flow can be used as a practical reference to infer what sort of data we want to use in NCD.
Application: Data selection
NCD: Supervised Info May Hurt
Application: Data Combining
Contribution
- We find that using supervised knowledge from the labeled set may lead to suboptimal performance in low semantic NCD datasets. Based on this finding, we propose two practical methods and achieve ∼3% and ∼5% improvement in both CIFAR100 and ImageNet compared to SOTA.
- We introduce a theoretically reliable metric to measure the semantic similarity between labeled and unlabeled sets. A mutual validation is conducted between the proposed metric and a benchmark, which suggests that the proposed metric strongly agrees with NCD performance.
- We establish a comprehensive benchmark with varying degrees of difficulty based on ImageNet by leveraging its hierarchical semantic similarity.
Thank you!

ncd
By statmlben




