РАЗРАБОТКА МЕТОДА РАНЖИРОВАНИЯ СЕМАНТИЧЕСКИ АННОТИРОВАННЫХ ДОКУМЕНТОВ
Мингазов Никита, гр. 09-107
Постановка задачи
Применить информацию, получаемую из семантических информаций, для улучшения ранжировании поиска

Выделение именованных сущностей
Аналоги
- Компонент Mimir проекта GATE
- Компонент ContentHub проекта Apache Stanbol
Оба:
- Имеют достаточную инфраструктуру
- Не уделяют внимания ранжированию
- В основном для английского языка
Составление коллекции
-
Тестовая коллекция документов - новости о компаниях за 2013-2015 гг.
-
Набор запросов, например:
-
"Total Кристоф де Маржери" -
"Газпром Китай контракт поставки газа" -
"Runa Capital инвестиции"
-
-
Набор оценок релевантности для пар “запрос-документ” - 4 уровня
-
Мера оценки - была выбрана мера NDCG:
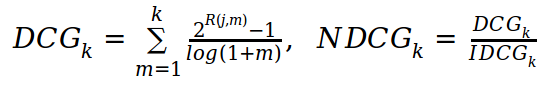
Базовые признаки
TF-IDF:
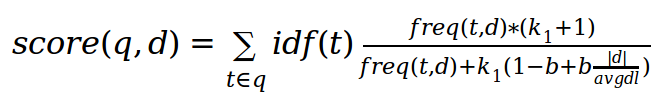
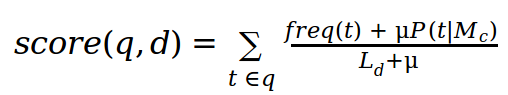
Okapi BM25:
LM Dirichlet:
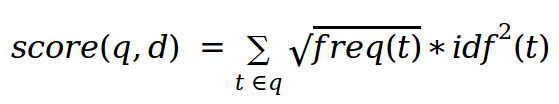
Идея - в качестве запросов выбрать аннотации запроса, в качестве текста документа - текст аннотаций документа
Entity-level признаки
-
Делим документ и запрос на слова.
-
Считаем частоты слов запроса в документе.
-
Суммируем полученные частоты.
-
Делим на количество слов в документе.
Simple Score
-
Разбиваем каждую аннотацию документа и запроса на слова.
-
Для каждого слова из запроса и аннотации считаем его процентную частоту.
-
Усредняем по аннотациям документа и словам запроса.
Moderate Score
-
Считаем количество тех аннотаций документа, которые включают в себя все слова из запроса
-
Делим на общее число аннотаций в документе
Discrete Perfect Match
-
Среднее степенное
-
Среднее степенное, домноженное на быстрорастущую функцию от количества ненулевых встреченных аннотаций
Усреднение по аннотациям запроса
Итоги работы
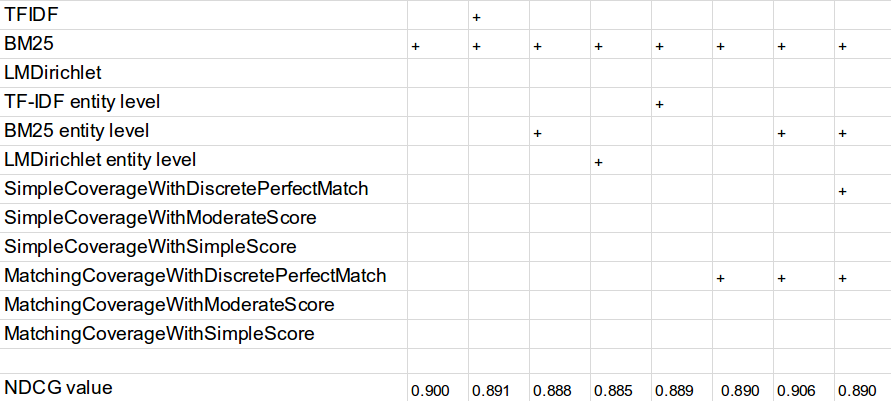
Итоги работы
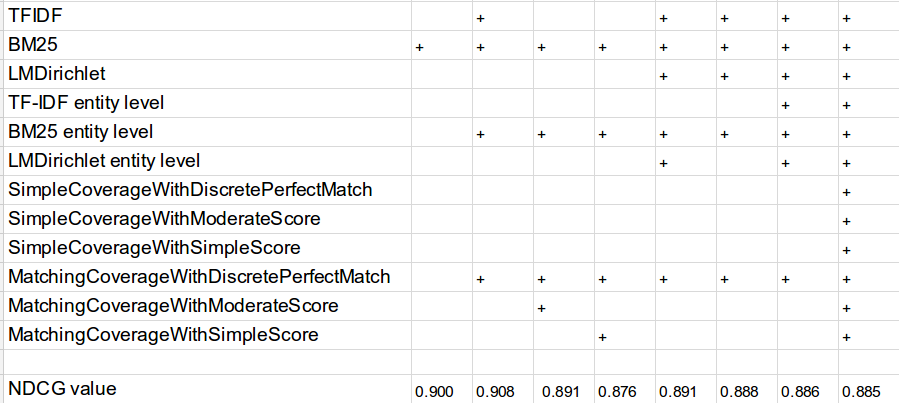
Возможные причины
-
Недостаточное количество размеченных документов в коллекции
-
Недостаточная точность разметки с помощью автоматических средств обработки данных
-
Неподходящий выбор алгоритма обучения ранжированию
-
Недостаточная информативность выбранных признаков
Спасибо за внимание!
Дипломная
By stdfx



