Experiences with a long-running big system migration
Part I – emerging behavior
Stefan Schwetschke

What other parts can I offer?
- Part 1: Emerging behavior
- Part 2: Measuring methods in depth
The USE method, measuring points - Part 3: Sizing, archiving & decommissioning, project setup
About me
- I ❤️ the mountains a lot!
- I studied "Informatik" (basically computer science)
- During my studies, I was one of the founders of 4friendsonly.com
- I worked over ten years as a consultant for Capgemini in various roles
- I work now as a lead-developer over at Check24
We are building the "Kontomanager"

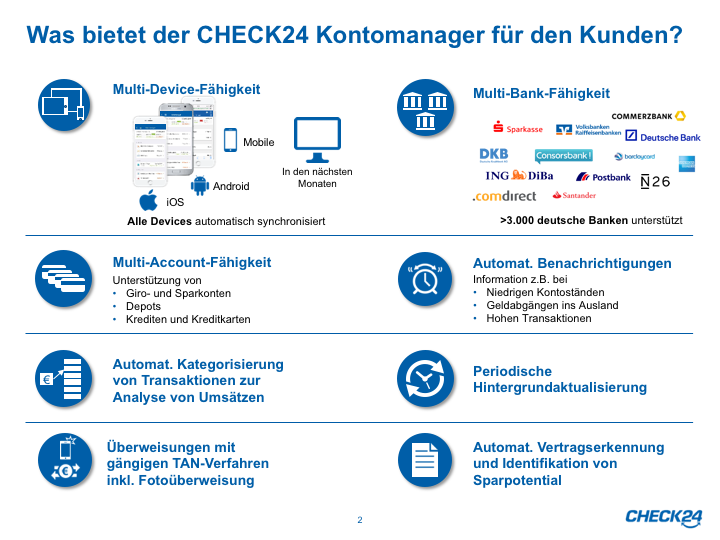

The scenario
- Merging two data centers
- Cleaning up the application stack
- At a mobile phone carrier
- Complex workflow ahead!
Idea
- Migrate during business hours
- Migrate parallel to normal operations
- Pause migration when the system overloads
- Migrate in small batches, correct problems before much damage occurs
Why a complex workflow?
- Lock customer account against changes
- Deactivate on old systems
- Move to new systems
- Propagate in all business applications
- Propagate in all network elements
- Update location in the global lookup
- Un-lock account
Measuring basics:
The USE Method
- Idea from Brandan Gregg: The USE Method
- Three metrics for each ressource
- Utilization
- Saturation
- Errors
Utilization
- Goal: Get this up (70% is a good value)
- Examples:
- CPU usage
- Network throughput
- Used memory
- 100% means: you have a bottle-neck!
Saturation
- Goal: Avoid
- Examples:
- Waiting threads
- Network packets waiting
- Paging: swap-in events
(Swap out is not a problem!)
Errors
- Goal: No measurement while errors are present!
- Examples:
- Throttled core due to overheating
- Lost network packets
- ECC errors
Measuring basics:
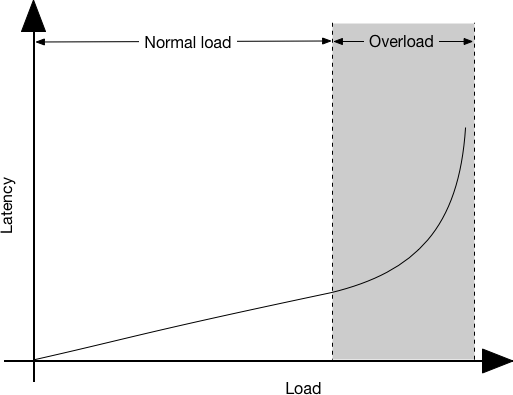
Hockey stick curve
- Term "stolen" from climate science
- Typical curve for systems under load
- Allows to predict the system behavior
- Idea: workload vs resource usage
- Typically: throughput vs latency
- Distinguishes linear from "exponential" behavior
(not really exponential in the mathematical sense)
Hockey stick: Example
What we found
- Throughput of the system less than 50%
- No clear utilization bottleneck
- Saturation all over the system
- No errors
Theory
- The system is oscillating
- The oscillation is too fast for our measurement
- Average utilization is low
- Parts of the system reach maximum saturation periodically
Problems with oscillation
- Hard to measure
- Many overload alerts
- The system stays more time in an inefficient overload state
- Average throughput goes down
- Periodical overload-state misleads local optimizations
Reasons for oscillation
- Internal state
- Reaction time
- Shared resources
- Sudden load changes
- Thermodynamics
Reason: Internal state
- Hysteresis is inherent to some models
- Timeouts
- Queues fill up
- Local optimizations
- Database optimizer
- OS caches
- Java VM heap (Moved to Eden space...)
Reason: reaction time
- Signal latency
- Calculation times
- Re-tries due to Ethernet collisions
- See Nagel-Schreckenberg-model (phantom traffic jam)
Reason: Shared resources
- One component strangles the others
- When they depend on each other, the system oscillates
- See Lotka–Volterra equations / prey-predator-model
- Examples:
- VM host
- Application server
- Network link
- Storage
Reason: Sudden load changes
- Activate latent oscillation potential
- Dirac-pules: Impulse response
- Examples:
- Batching
- Queues flushing
- Input surges
- Huge work packages mixed with small ones
(This also leads to the “Zen Garden Effect")
Reason: Thermodynamics
- Often there is some source of entropy
- When we take a random snapshot
- it is unlikely to get all work packets evenly distributed over time
- it is more likely to get some “clumping”
- it is unlikely to get all work packets evenly distributed over time
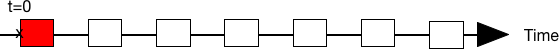
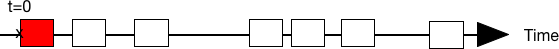
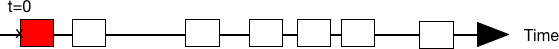
Details: Thermodynamic forces

Potential countermeasures
- Fine-grained monitoring
(especially for saturation) - Isolated or guaranteed resources
- Throttling (at the head of the traffic jam)
- Avoid surges: spread the input
- Traffic control: Global back pressure
- Faster reaction times
- Shorter queues
- Start back pressure when queue fills up
- Handle overspill
Our countermeasures
- Input spreading: Smaller batch sizes
- Throttling at the queues
Let's discuss
- Who has already experienced this?
- Other reasons?
- Other countermeasures?
- Other emerging behavior?
- Deadlock
- Livelock
- ????
Complex migration - part 1: emerging behaviour
By Stefan Schwetschke
Complex migration - part 1: emerging behaviour
This is my talk about my experiences with a very complex migration project. This talk is for the Munich DevOps Meetup in July 2018, hosted at Google in Munich.