Speech Project
Week 15 Report
b02901085 徐瑞陽
b02901054 方為
Task 5:
Aspect Based Sentiment Analysis (ABSA)
We focus on subtask1 first
Subtask 1: Sentence-level ABSA
Given a review text about a target entity (laptop, restaurant, etc.),
identify the following information:
-
Slot 1: Aspect Category
- ex. ''It is extremely portable and easily connects to WIFI at the library and elsewhere''
----->{LAPTOP#PORTABILITY}, {LAPTOP#CONNECTIVITY}
- ex. ''It is extremely portable and easily connects to WIFI at the library and elsewhere''
-
Slot 2: Opinion Target Expression (OTE)
- an expression used in the given text to refer to the reviewed E#A
- ex. ''The fajitas were delicious, but expensive''
----->{FOOD#QUALITY, “fajitas”}, {FOOD#PRICES, “fajitas”}
-
Slot 3: Sentiment Polarity
- label: (positive, negative, or neutral)
Slot1 :
Aspect Detection
Originally , we think this is a simple task...
At first , high input dimension of SVM seems awful : (
Paper Study
Latent Dirichlet Allocation
Topic Modeling
High input dimension seems not work...
We need to reduce it !
Every application category has better feature set to describe
Ex. MFCC <-> audio
Gabor <-> video...etc
For text corpus ... it's keywords !
1000 VS 3000
remove stopwords
stemming
tf-idf
simple word clustering...
not work ... OTL
Find short descriptions of the members of a collection
whlie preserving the essential relationships
Introduction of Topic Modeling
Differ from tf-idf :
tf-idf is is "indexing" (give proper weight to every unigram)
like normalization ... I think
Dimensionality Reduction
-
Latent Semantic Indexing
use SVD to find subpace of tf-idf matrix that
capture most of the variance in the collection
-
probablistic Latent Semantic Indexing
model each word as a sample of a mixture model
p(d,w_n) = p(d) \sum\limits_{z} p(w_n|z) p(z|d)
z
: hidden topic
Drawback of pLSI
- have no natural way to assign for unseen documents
p(z|d)
d is only a dummy label :p
- linear growth in params => overfitting issue
size grows in mixture(corpus)
We don't have generative model for portions of topic given arbitary document
But , I don't figure it totally now , actually :p
Latent Dirichlet Allocation
Assumption : BOW (order of words can be neglected)
exchangeability
de Finetti's Theorem
Any collection of exchangeable RVs
has a representation as a mixture distribution
In our case ,
=> word , topic is a mixture distrubution
And some hidden variable will determine those distribution
multinomial
Latent Dirichlet Allocation
(they are all "distribution over distributions")
Randomly choose corpus-level param
for subsequent document-level param
\alpha , \beta
\theta
decide topic dis.
use to decide word probability conditioned on topic
z , \beta
Dirichlet is multi-nomimal version of beta distribution
Advantage : Avoid over-fitting issue in MLE (ref : CMU)
(conjugate to multinomial dis.)
Experiment in Slot1
After using PCA(SVD) to reduce dimension and get error ...
I found I use sklearn's "fit_transform" incorrectly in previous ...
OTL
Experiment in Slot1 (Cross Validation)
Without LSI :
- With Tf-Idf indexing
restaurant : 61% (12 category)
laptop : 52% (81 category)
- Without Tf-Idf indexing
restaurant : 60% (12 category)
laptop : 50.05% (81 category)
Experiment in Slot1 (Cross Validation)
With LSI : (reduce dimension to 1000)
restaurant : 60% (12 category)
laptop : 52% (81 category)
Need more time...
Seems no improvement ,
but the 1000 dimension seems preserve the essential info
Experiment in Slot1 (Cross Validation)
Bigram
| 9000/? (origin size) |
3000 (unigram size) |
|
|---|---|---|
| restaurant | 61% | 61% |
| laptop | 51% | 51% |
seems high input dimension is not a problem :p
| 15k/17k (origin size) |
3000 (unigram size) |
|
|---|---|---|
| restaurant | 61% | |
| laptop | 51% |
Trigram
Experiment in Slot1 (Visualization of LSI)
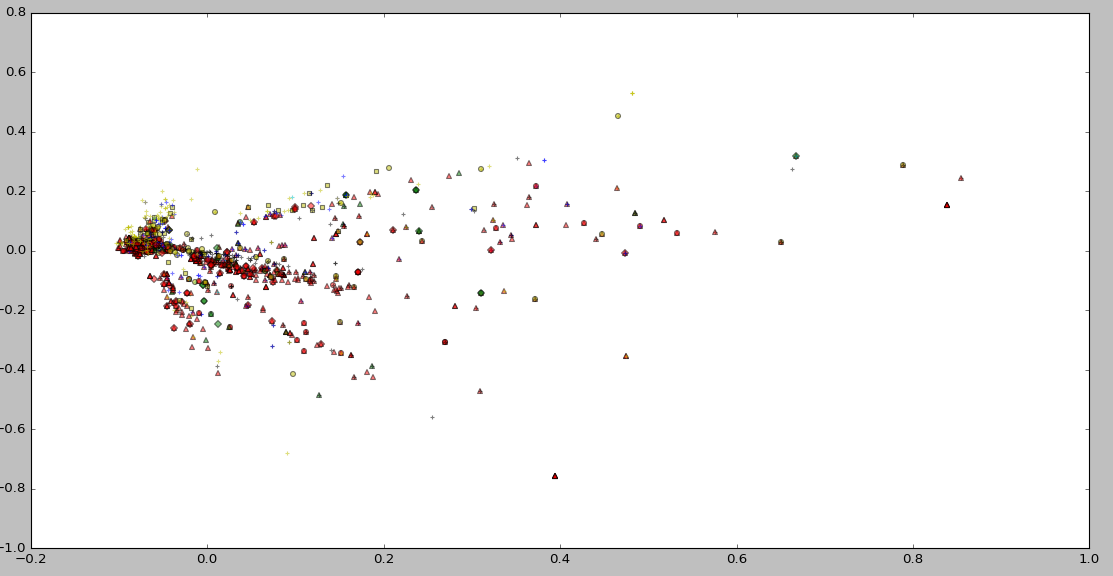
Experiment in Slot1 (Visualization of LSI)
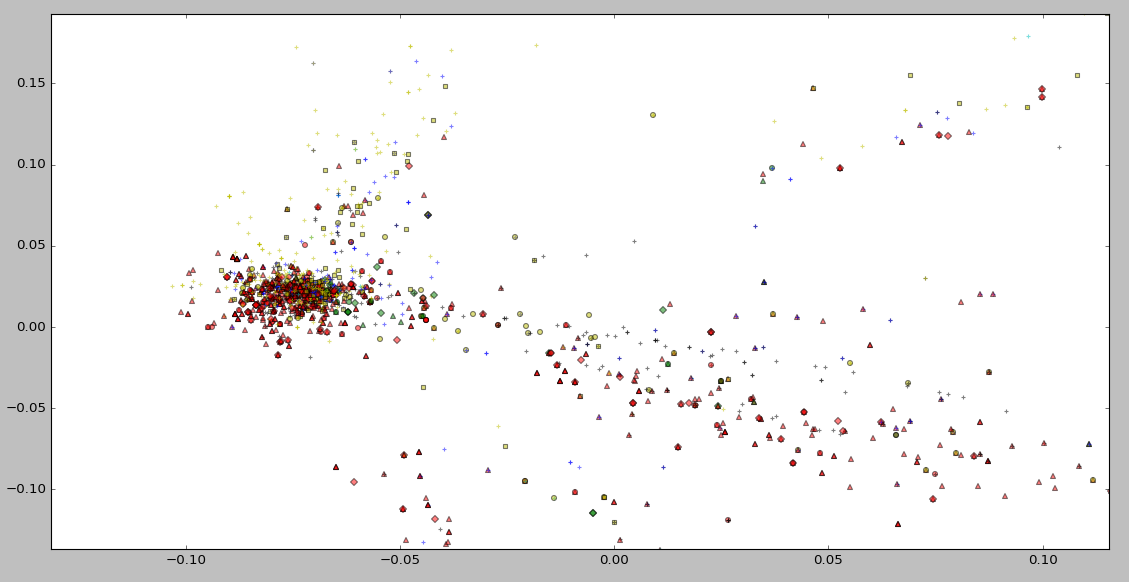
Experiment in Slot1 (Visualization of LSI)
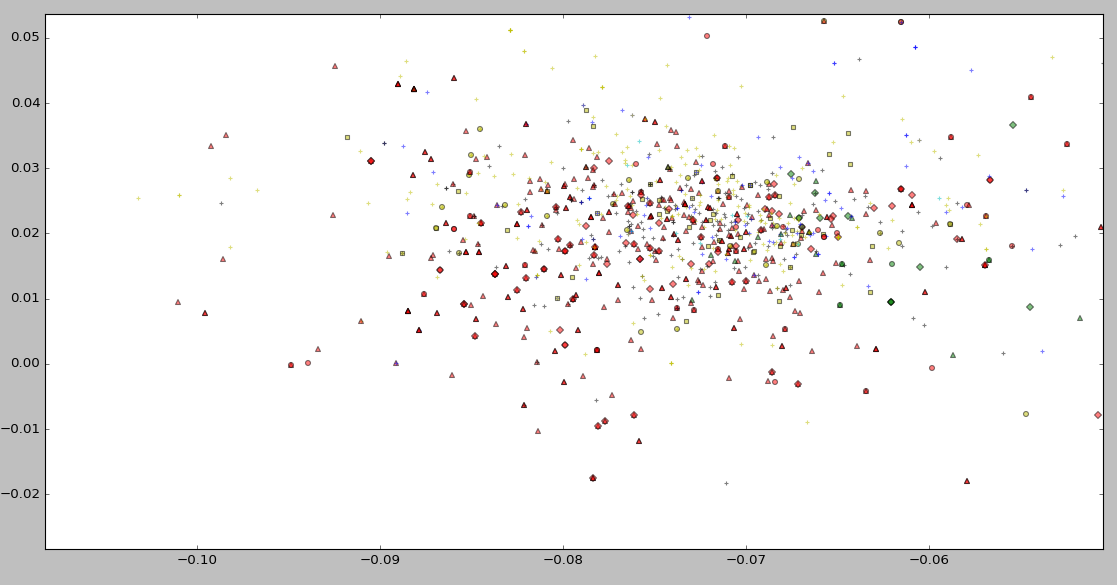
Nothing special :p
Experiment in Slot1 (unsupervised LDA)
Experiment in Slot1 (supervised LDA)
Experiment in Slot1 (Summary)
Two kinds of classifier
- discriminative model :
- generative model :
something like dimensionality reduction
use sample to classify directly
use sample to guess hidden model's param <learn a model>
use these models to predict unseen sample <classify>
Slot3 : Polarity Identification
Framework
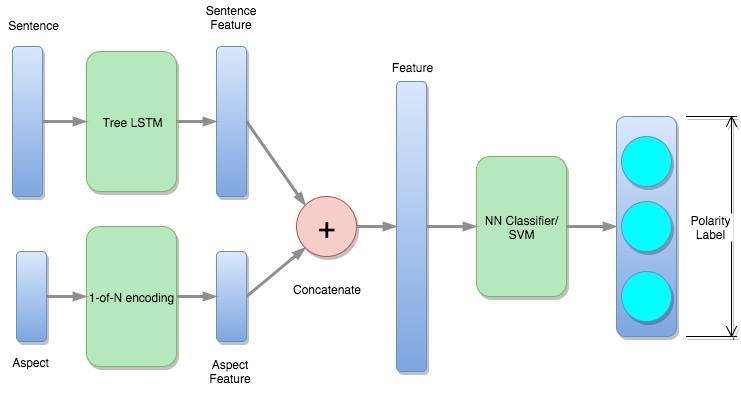
Slot3 :
Polarity Identification
| Domain | 3-class accuracy |
|---|---|
| Restaurant | 71.23% |
| Laptop | 74.93% |
Without using aspect information and removing conflicting polarities
Seems like we're on the right track...we hope so...
Problem we encountered
When modifying TreeLSTM code, the model can be trained on our dataset, but we can only feedforward data in the train and dev set, but not on the test set.
Our guess is that the dictionary was extracted from the train/dev data but not the test data, so some words in the test set cannot be encoded, causing the error
SpeechProject-week15
By sunprinces




