Building user-based recommendation model for Amazon.
- Sunny
DESCRIPTION
-
The dataset provided contains movie reviews given by Amazon customers.
-
Reviews were given between May 1996 and July 2014.
Data Dictionary
| Column | Description |
|---|---|
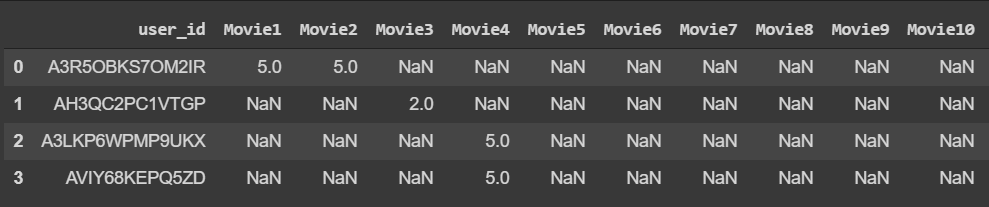
| UserID – | 4848 customers who provided a rating for each movie |
| Movie 1 to Movie 206 | 206 movies for which ratings are provided by 4848 distinct users |
Snapshot
Data Considerations
- All the users have not watched all the movies and therefore, all movies are not rated. These missing values are represented by NA.
- Ratings are on a scale of -1 to 10 where -1 is the least rating and 10 is the best.
ANALYSIS TASK
EDA
- Which movies have maximum views/ratings?
- What is the average rating for each movie? Define the top 5 movies with the maximum ratings.
- Define the top 5 movies with the least audience.
HINTS/Links
Recommendation System
Introducing ...
Surprise Library
!pip install scikit-surprise Recommendation Model
Some of the movies hadn’t been watched and therefore, are not rated by the users. Netflix would like to take this as an opportunity and build a machine learning recommendation algorithm which provides the ratings for each of the users.
- Divide the data into training and test data
- Build a recommendation model on training data
- Make predictions on the test data
Train test split
using surprise
Evaluating RecSys Model
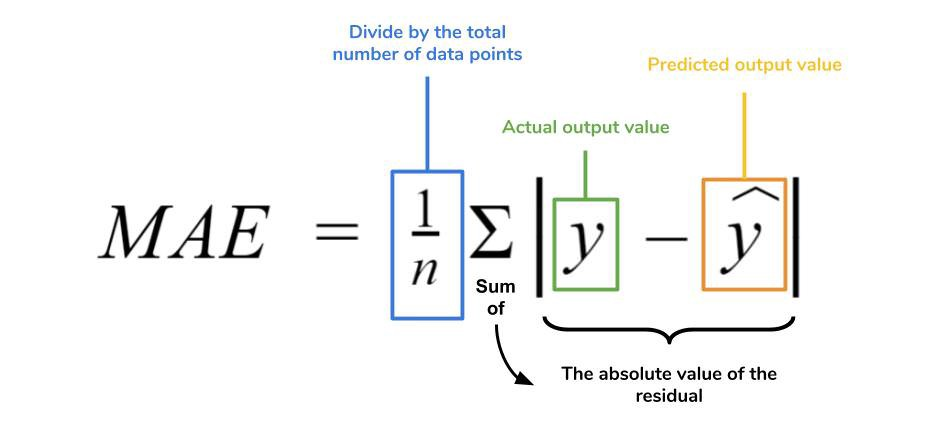
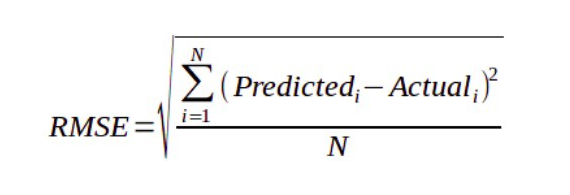
- MAE
- RMSE
MAE
RMSE
To explore further on how to evaluate your RecSys model -
Algos used
- PCA
- SVD
PCA
SVD
Bonus..
Introducing to the world of
and
Reference -
Project mentoring on Recommend-er System
By Sunny



