AI 概覽 之 GPT 篇
小社第一堂 25/09/30
講師 - Suzy
# PRESENTING CODE
- 北資一六學術長
- 二信 離前面最近的位置
但有事先DC找 - 小羊蘇西(?
- PY 及 AI 小社講師

Artificial Intelligence 人工智慧
# PRESENTING CODE
ChatGPT?
Gemini?
掃地機器人?
統治世界(??
Artificial Intelligence 人工智慧
# PRESENTING CODE
ChatGPT?
Gemini?
掃地機器人?
統治世界(??
1950s
- 圖靈:機器可以思考嗎?
- 圖靈測試 (Turing Test)
1956
- 達特茅斯夏季人工智慧研究計畫
- 開了一個月,使 AI 成為一個研究領域
1970
- AI 寒冬
- 沒什麼人研究 AI
- 技術期待過高,落空
Artificial Intelligence 人工智慧
# PRESENTING CODE
1997
- DeepBlue AI 打敗人類西洋棋棋王
1990s-2000s
- 網路普及 -> 大數據資料產生
- 硬體能力升級
2006
- 發明深度學習 (Geoferry Hinton)
2017
- Google Brain 發明「注意力機制」
2018
- OpenAI 發布 GPT-1
Artificial Intelligence 人工智慧
# PRESENTING CODE
1997
- DeepBlue AI 打敗人類西洋棋棋王
1990s-2000s
- 網路普及 -> 大數據資料產生
- 硬體能力升級
2006
- 發明深度學習 (Geoferry Hinton)
2017
- Google Brain 發明「注意力機制」
2018
- OpenAI 發布 GPT-1
AGI (Artifical General Intelligence) - 在各方面能力和人類相似
ASI (Artifical Super Intelligence) - 在各方面能力顯著超越人類
⋯⋯
ANI
(Artificial Narrow Intelligence)
- 能執行特定功能
The Singularity 奇異點
# PRESENTING CODE
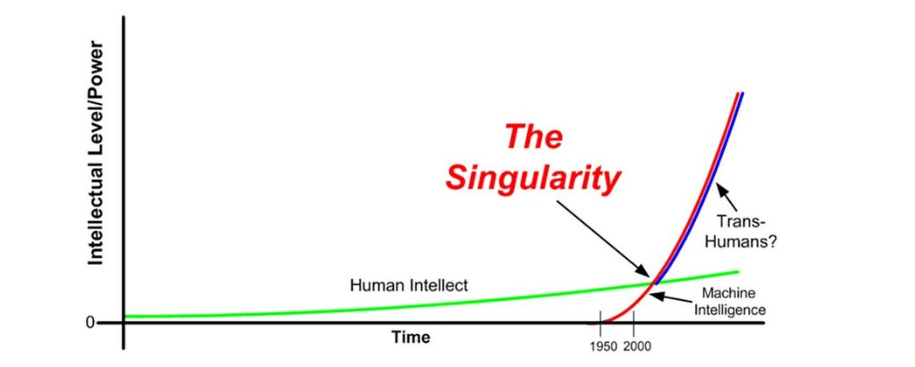
當機器智慧超過人工智慧(?
Machine Learning 機器學習
# PRESENTING CODE
- 傳統的程式碼:一個指令一個動作
- 機器學習:讓機器學習如何把一些資料轉換為另一些資料。
文字
圖片
中文
英文
例:
midjourney, nano banana
例:
google 翻譯
圖片
文字
例:
圖片辨識系統
其實就是讀入一些資料後,輸出一些有意義的資料,即使我們沒有預先明確指定好輸入的資料要對應到哪些輸出。
Machine Learning 機器學習
# PRESENTING CODE
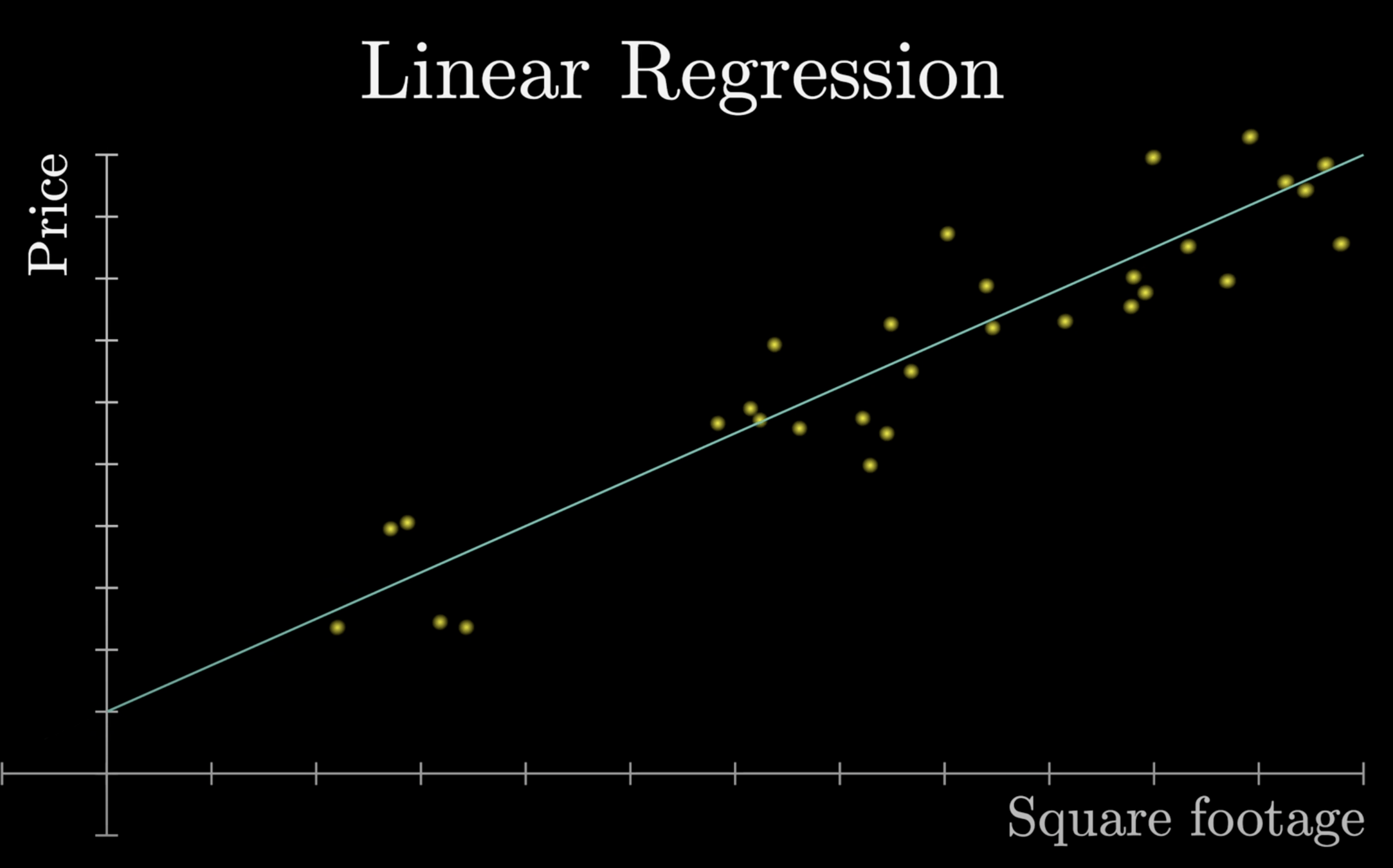
線性迴歸是一個簡單的例子!
利用機器來尋找最合適的那條直線
=尋找斜率及結局
=尋找 x 軸和 y 軸的關聯。
x 軸:房子坪數
y 軸:房價
結果:
可以對該模型輸入一個 x 值(房子坪數),模型會輸出一個預測的y 值(房價)。
Auto-regression (AR):
過去預測未來
Machine Learning 機器學習
# PRESENTING CODE
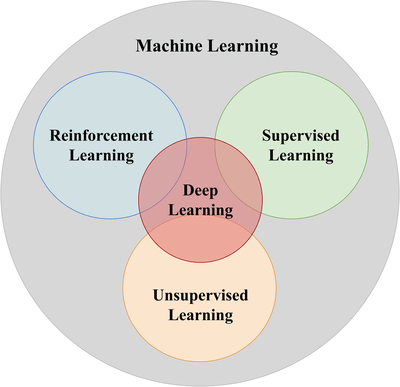
- 監督式學習:所有資料都被「標註」(label),告訴機器相對應的值,以提供機器學習在輸出時判斷誤差使用。
- 非監督式學習:所有資料都沒有標註,機器透過尋找資料的特徵,自己進行分類。
- 強化式學習:我們不標註任何資料,但告訴它所採取的哪一步是正確、那一步是錯誤的,根據反饋的好壞,機器自行逐步修正、最終得到正確的結果。
- 深度學習:神經網絡。(以後會教)
Large Language Models 大型語言模型
# PRESENTING CODE
- 就是那種「可以講話」的 AI !
- 如何把機器學習,套用到語言模型上?
Natural Langauge
Processing (NLP)
自然語言處理
- 一種機器學習技術,讓電腦能夠解譯、操縱及理解人類語言。– Google
Large Language Models 大型語言模型
# PRESENTING CODE
- 套用前面 Auto-Regression (自我迴歸)的概念,
- 「用過去預測未來」
透過前一句話,預測下一個單字有可能是什麼
=> 不斷重複後,得到一個完整的文字段落
Large Language Models 大型語言模型
# PRESENTING CODE
- 套用前面 Auto-Regression (自我迴歸)的概念,
- 「用過去預測未來」
透過前一句話,預測下一個單字有可能是什麼
=> 不斷重複後,得到一個完整的文字段落
例:我是北一女中資訊
研習社
的
社員
N - gram model
# PRESENTING CODE
- 利用機率預測「下一個字可能是什麼」
STEP 1 取得一定量的文本資料(訓練素材)
STEP 2 給模型一段未完成的文字
STEP 3 模型找出,未完成文字的最後幾個字最有可能和哪個字一起出現
把那個字視為下一個字輸出,
並重複此過程直到達成完整文字段落為止。
N - gram model
# PRESENTING CODE
我是北一女中的學生。
我是北一女中資訊研習社社員。
我是北一女中資訊研習社幹部。
我喜歡叫人工智慧幫我寫作業。
你是建國中學電子計算機研習社的幹部。
文本素材
未完成的文字段落
我
P (「我」之後接「是」的機率)
P (「我」之後接「喜歡」的機率)
= \frac {我是(3個)}{我後面接所有字 (4個)}= \frac {3}{4}
= \frac {我是(1個)}{我後面接所有字 (4個)}= \frac {1}{4}
N - gram model
# PRESENTING CODE
我是北一女中的學生。
我是北一女中資訊研習社社員。
我是北一女中資訊研習社幹部。
我喜歡叫人工智慧幫我寫作業。
你是建國中學電子計算機研習社的幹部。
文本素材
未完成的文字段落
我是
P (「是」之後接「北一女中」的機率)
P (「是」之後接「建國中學」的機率)
= \frac {北一女中(3個)}{所有字 (4個)}= \frac {3}{4}
= \frac {建國中學(1個)}{所有字 (4個)}= \frac {1}{4}
N - gram model
# PRESENTING CODE
我是北一女中的學生。
我是北一女中資訊研習社社員。
我是北一女中社團社幹部。
我喜歡叫人工智慧幫我寫作業。
你是建國中學電子計算機研習社幹部。
文本素材
完成的文字段落
我是北一女中資訊研習社幹部
N - gram model
# PRESENTING CODE
- N 代表把幾個字為一單位進行運算
- 本例為 N=1 (monogram)
- 經常使用的還有 N=2 (bigram), N=3 (trigram) 等
N - gram model 優點
N - gram model 缺點
- 通常不會出現文法錯誤、不合語法的句子
- 模型訓練過程簡單
- 創作內容順暢但不知所云
- 無法創作一個有邏輯、意義的文章段落
G
P
T
G
P
T
enerative
re-trained
ransformers
生成式
預先訓練好的
變換器
GPT
把文本切成一個一個的小單位,即 token。一個單位可以是一個詞彙或是一個字根。
1.
2.
把 token 換成數字,方便運算
3.
GPT 的核心技術
運算這些 token 數字
今天可能來不及講
下學期來機器學習小社
# CHAPTER 2
Tokenization
Word
Embedding
Transformer
Tokenization
# PRESENTING CODE

把一段文字切成一個一個的 token
會依照語言而有不同的切割方式
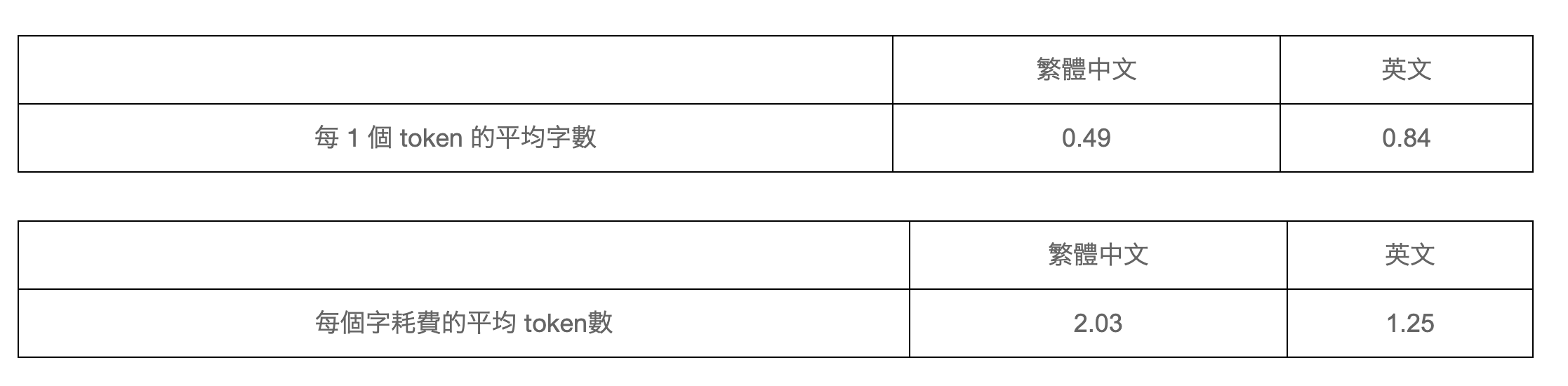
例:「你好嗎」=7 tokens, 「我很好」=6 tokens
Word Embedding
# PRESENTING CODE
把每個 token 配對到一串「向量」
向量簡單來說就是一串數字,可以在幾何空間中作表示
例:(2, 4) 是二維向量,可以視為 x 軸走 2 單位, y 軸走 4 單位
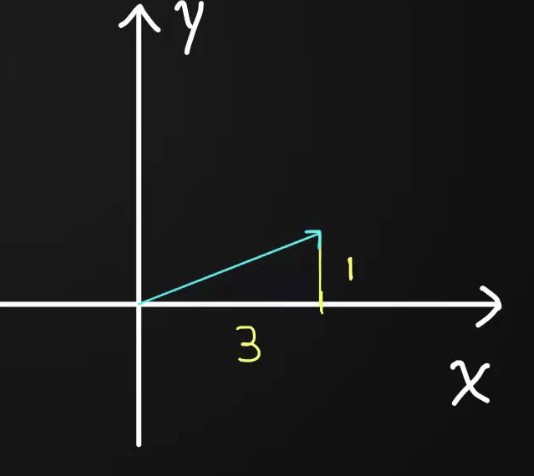
Word Embedding
# PRESENTING CODE
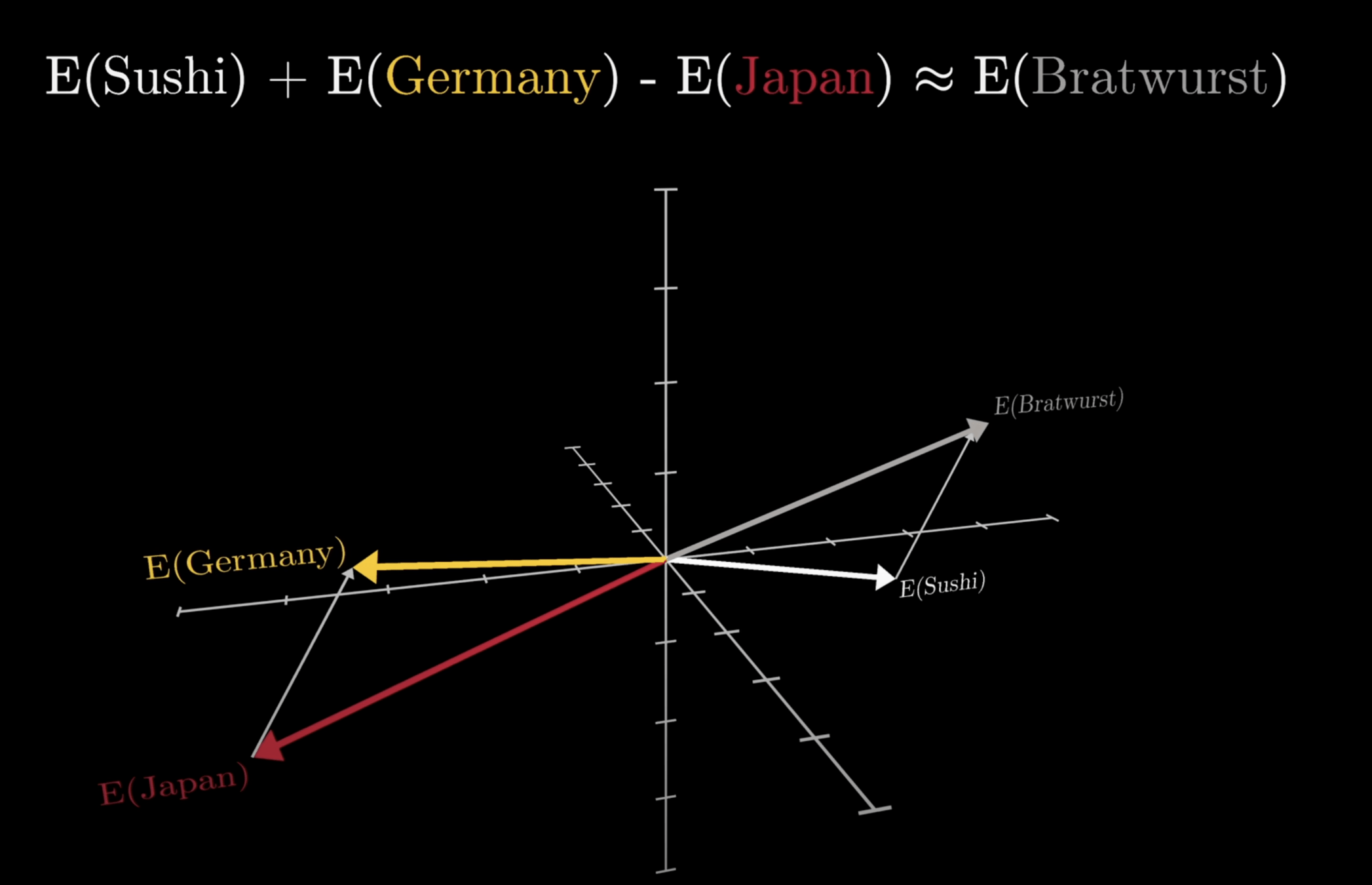
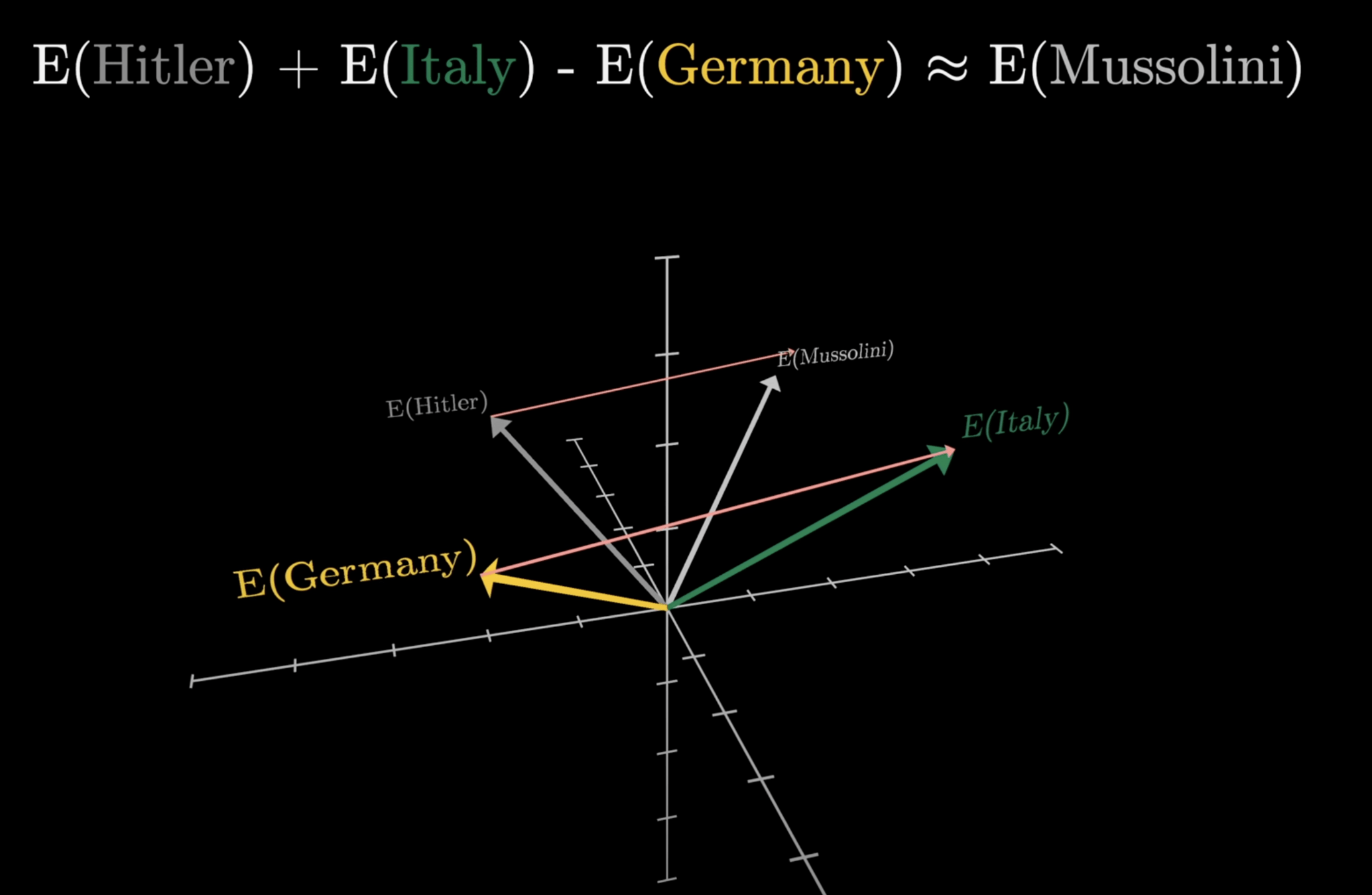
意思相近的詞在幾何空間中會有相關的意義。
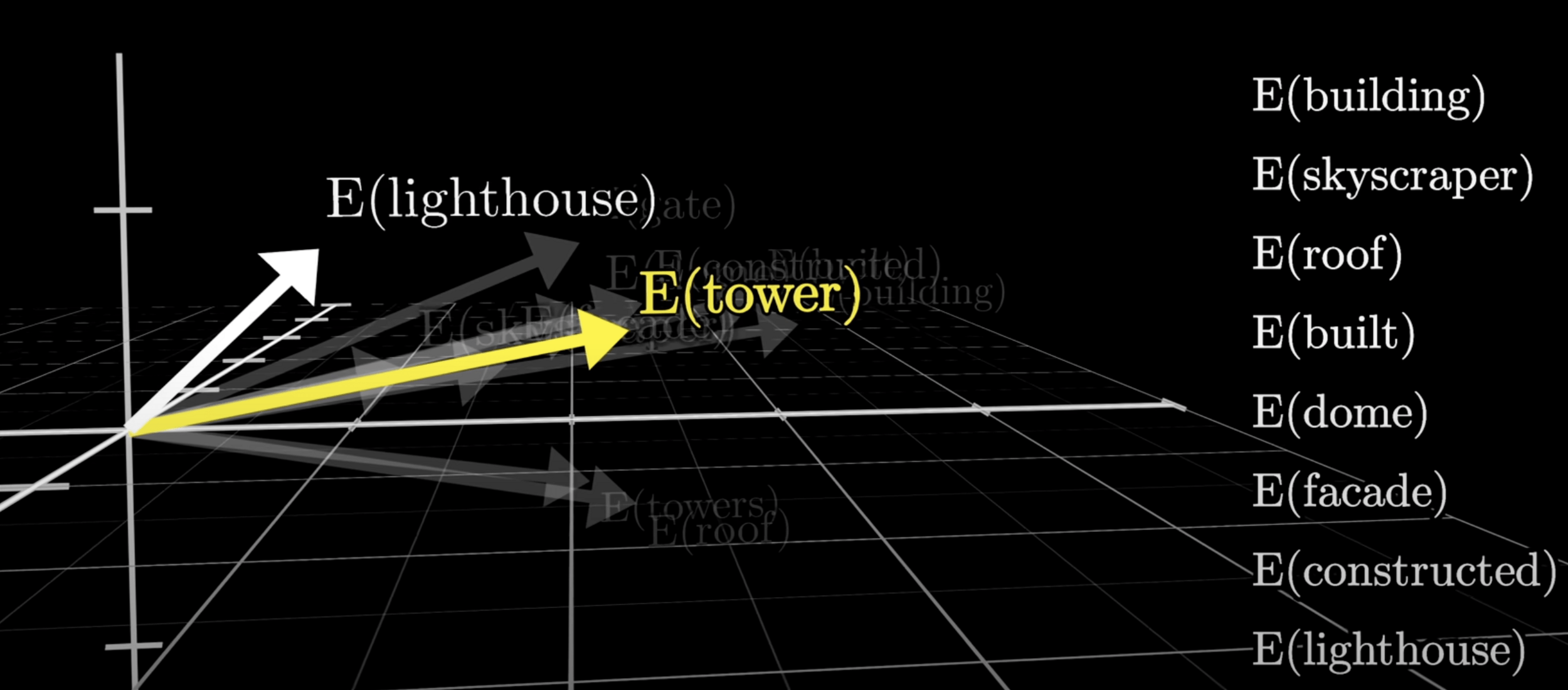
Word Embedding
# PRESENTING CODE
意思相近的詞在幾何空間中會有相關的意義。
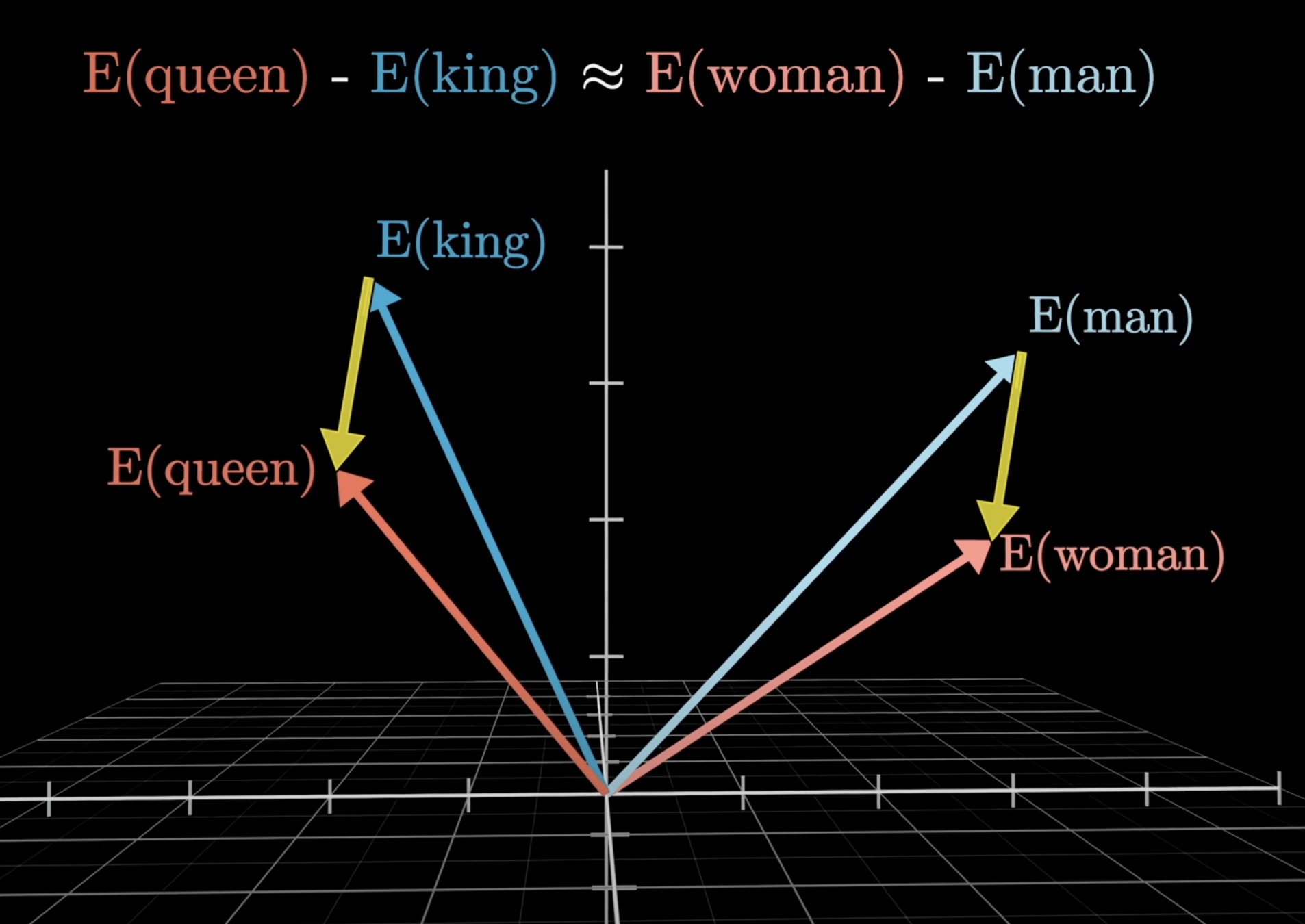
Word Embedding
# PRESENTING CODE
意思相近的詞在幾何空間中會有相關的意義。
Word Embedding
# PRESENTING CODE
意思相近的詞在幾何空間中會有相關的意義。
Transformer
# PRESENTING CODE
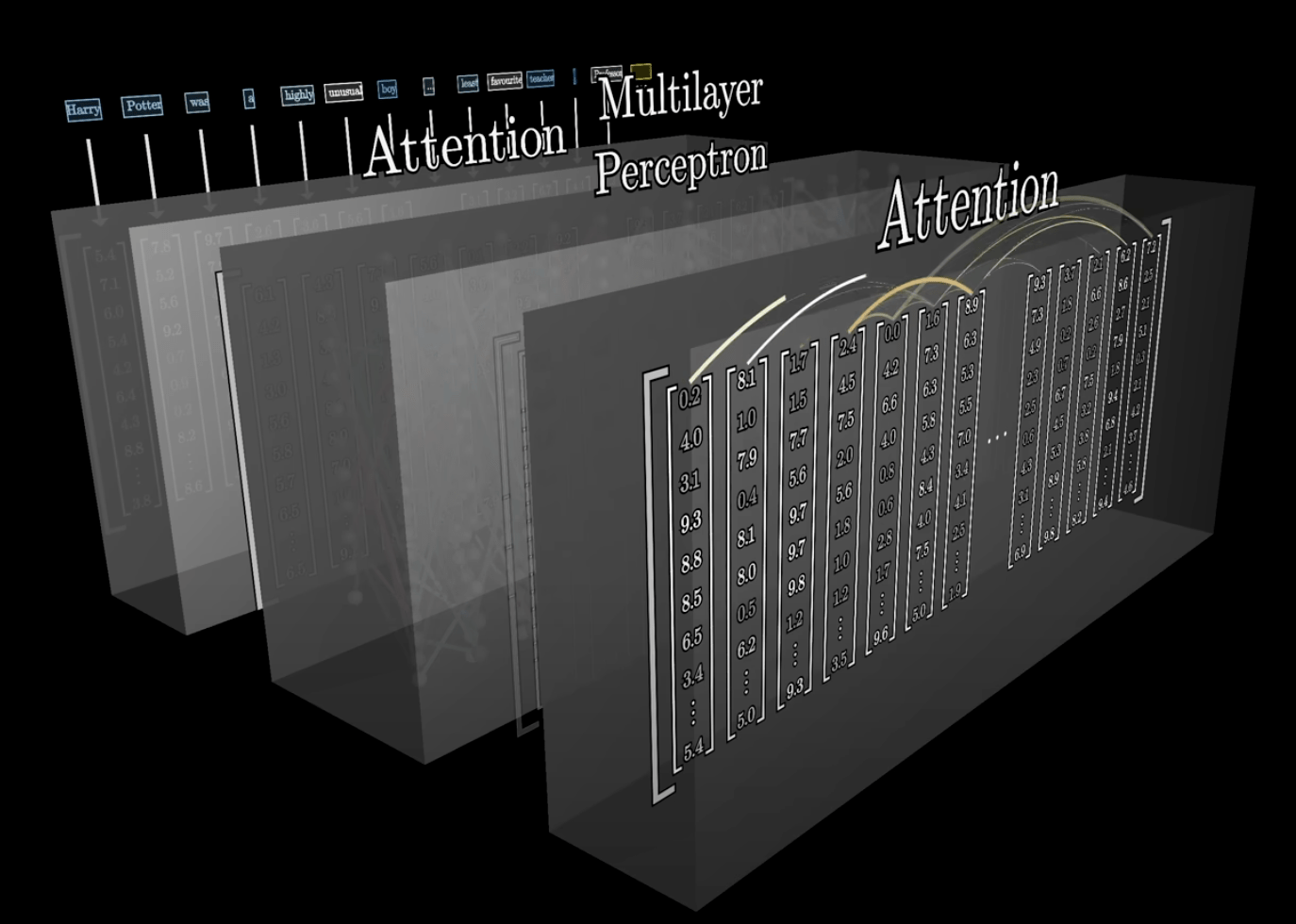
經過一系列複雜的數學運算(其實是矩陣運算),
得出下一個字最有可能是什麼。
Attention (注意力)
是 GPT 成功的關鍵技術,旨在找出個字詞間的關聯,以處理一字多義的現象。
實作嘗試
大神 Andrej Karpathy 自製的迷你莎士比亞GPT
謝謝大家
想解鎖更多,歡迎參與接下來的 AI 小社和下學期的放學機器學習
順便去修一下 Python 的課啦
AI 小社第一堂 GPT篇
By Suzy Huang



