Machine Learning 0
Introduction & Linear regression
目錄
- 機器學習概論與分類
- 線性回歸
- 梯度下降
- 實作
講師 Suzy (蘇西)
- 北資一六 學術長
技能點:
- Python
- 機器學習 (機器在學習講師也在學習)
- C++ 可以說是會跟不會差不多
- 養了兩隻 Labubu

寶寶蘇西

What is Machine Learning?
Artificial Intelligence vs Machine Learning?

ML as a part of AI
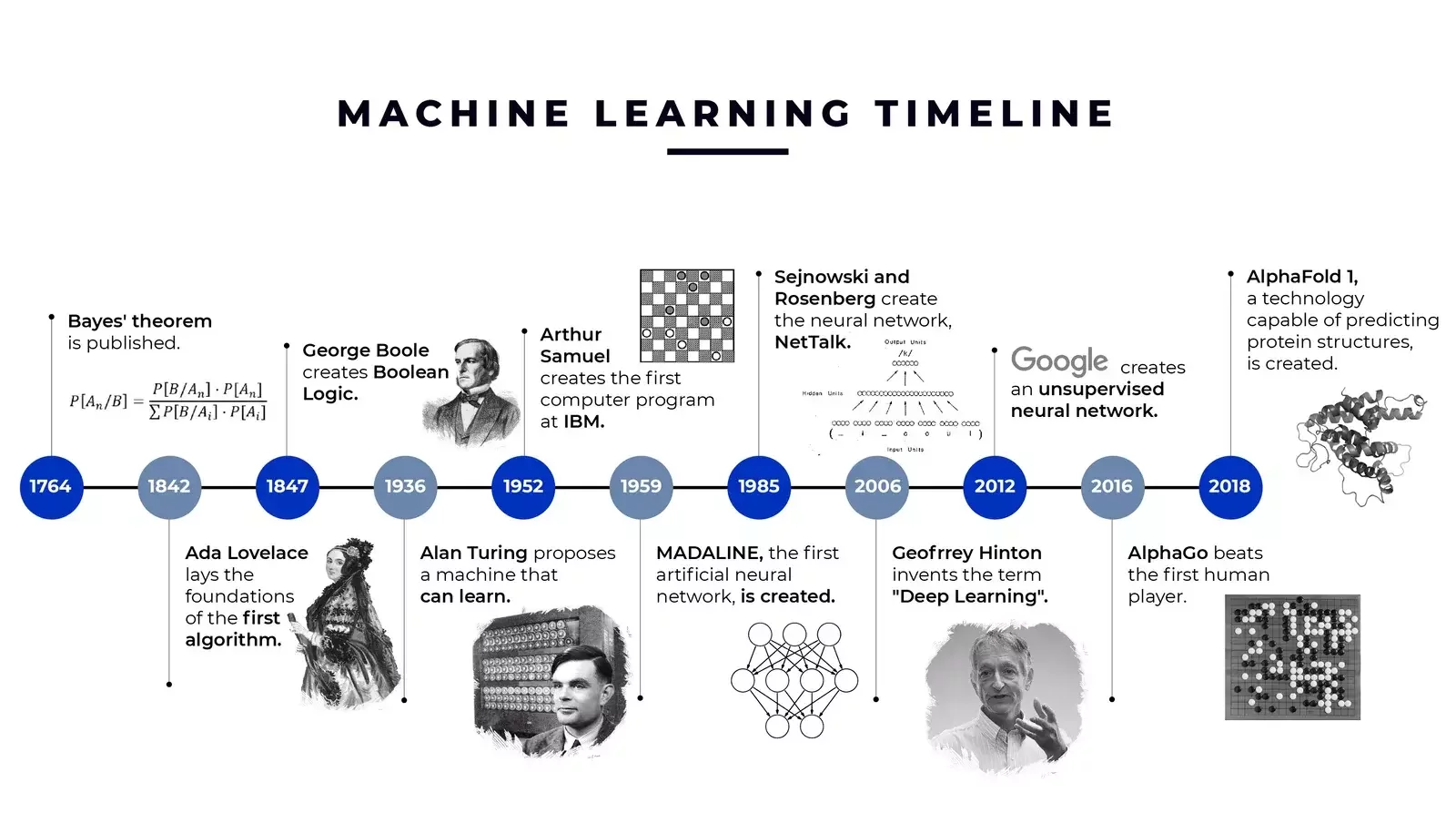
Defining Machine Learning
機器學習是一個研究領域,旨在賦予電腦無需經由明確指令就能具備學習的能力。- Arthur Sameul (1959)


他的電腦跳棋程式是世界上最早能成功進行自我學習的電腦程式之一。
Defining Machine Learning
對於某類任務 T 和 表現 P,如果一個電腦程式在處理任務 T 時的性能(以 P 為量測標準)隨著經驗 E 而改善,則稱該程式從經驗 E 中學習。- Tom Mitchell (1998)
他領導開發了一個非常有名的系統,叫作 NELL (Never-Ending Language Learner)

例:
- E(經驗 / 數據):程式自己和自己玩的遊戲
- P (表現):勝率
Machine Learning
監督式學習
非監督式學習
強化學習
人工智慧
Supervised Learning
監督式學習
監督式學習
【條件】一組數據有 m 個範例
【目標】給定 x 值,預測 y 值?
(x^{(1)}, y^{(1)}), ... (x^{(m)}, y^{(m)})
坪數
房價
x
y
坪數
房間數
房價
(x^{(1)}, y^{(1)}), ... (x^{(n)}, y^{(n)})
x^{(i)} = (x_1^{(i)}, x_2^{(i)})
x_1
x_2
y
x = \begin{bmatrix} x_1 \\ x_2 \\ x_3 \\ \vdots \\ x_d \end{bmatrix}
其實可以弄成很多維度
考量不同特徵
監督式學習
Regression vs Classification
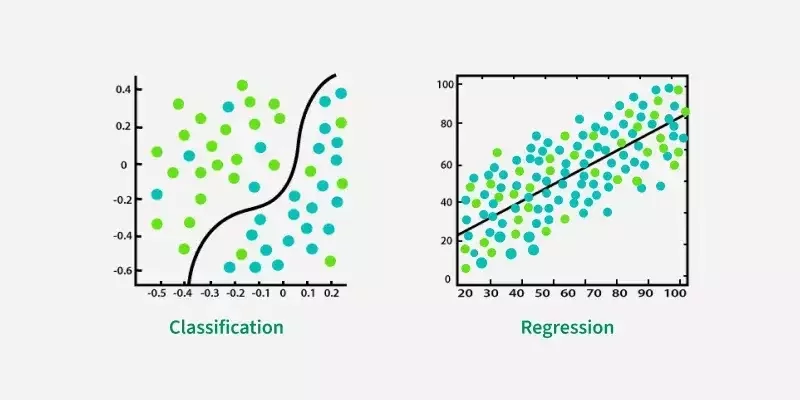
分類
迴歸
監督式學習 & 圖片識別 Image Classification

x = 圖片像素
y = 圖片中的主要物件
監督式學習 & NLP 自然語言處理
機器翻譯
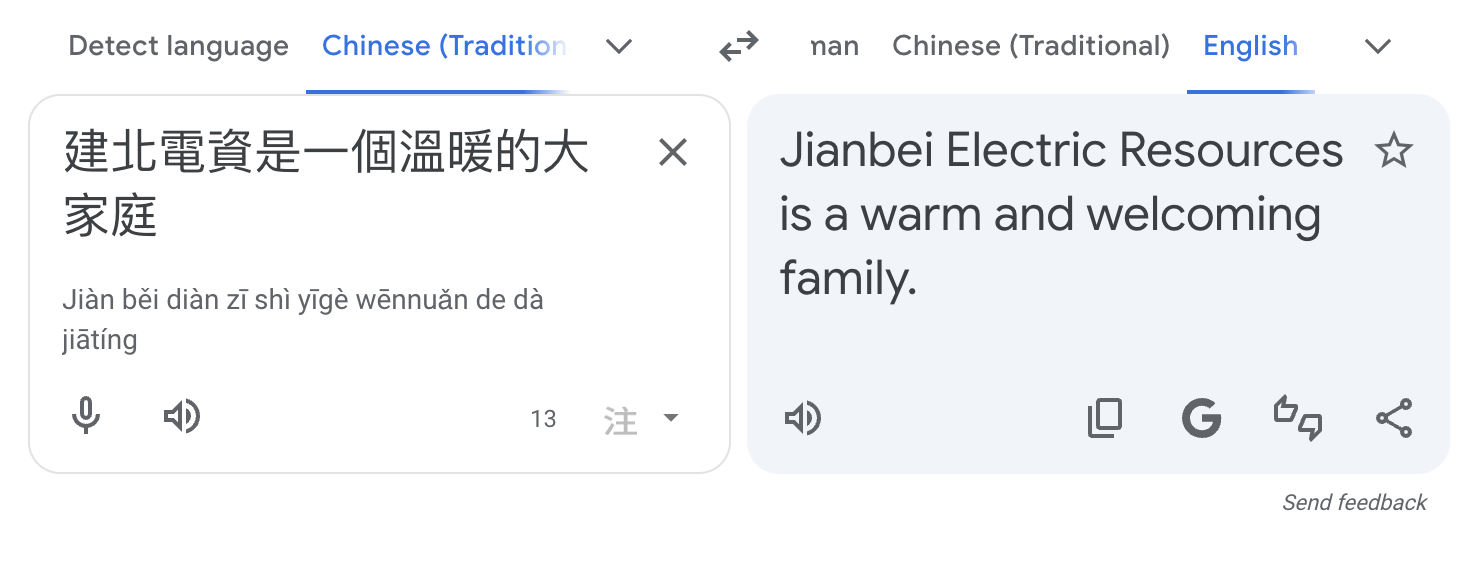
x
y
Unsupervised Learning
非監督式學習
非監督式學習
【條件】一組數據但沒有標記(沒有先給標準答案)
【目標】找看數據點的分佈有沒有什麼有趣的現象
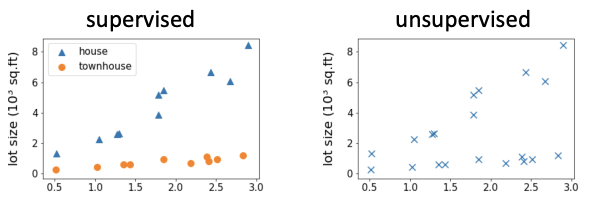
Clustering 分群 / 聚類分析
Clustering 實例:基因
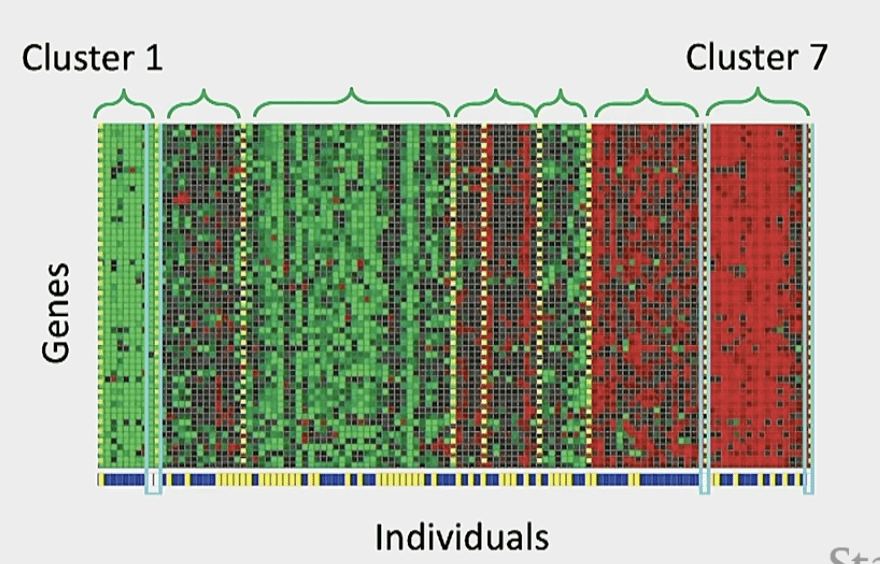
"You shall know a word by the company it keeps."
- John Rupert Firth (1957)
一個詞的意義在於它語其他詞之間的差異與關係。
Reinforcement Learning
強化學習
強化學習
強化學習是機器學習中的一個領域,強調如何基於環境而行動,以取得最大化的預期利益。
其靈感來源於心理學中的行為主義理論,即有機體如何在環境給予的獎勵或懲罰的刺激下,逐步形成對刺激的預期,產生能獲得最大利益的習慣性行為。
- Wikipedia
強化學習
Data
Collection
Training
嘗試策略
蒐集反饋
根據反饋
改良策略
強化學習

Linear Regression 線性迴歸
簡言之,
坪數
房價
x
y
畫線。
坪數
房價
x
y
訓練資料
學習
演算法
假設
函式
h(x) = \text{預測} \space y \space \text{值}
h(x) = ax + k
我們把預測函式
或者是,如果你有多個特徵的話
h(x) = a\cdot x_1 + b\cdot x_2 + k
預測房價
坪數
房間數
h(x)
寫出來吧
h(x) = \sum_{j=0}^{n} \theta_j x_j
h(x) = \theta_0 x_0 + \theta_1 x_1 + ... + \theta_n x_n
(令有
n
筆資料)
(令
x_0 = 1
)
(令
)
h(x) =
\begin{bmatrix} \theta_0 & \theta_1 & \dots & \theta_n \end{bmatrix}
\begin{bmatrix} x_0 \\ x_1 \\ \vdots \\ x_n \end{bmatrix}
聽說也可以寫成這樣
【目標】 最小化
J(\theta) = \frac{1}{2m} \sum_{i=1}^{m} (h_{\theta}(x^{(i)}) - y^{(i)})^2
坪數
x
房價
y
目標就是要找到一條線,
讓點到線的距離總和最小。
預測值 - 實際值
啊找線其實就是在找
\theta_i
J(\theta) = \frac{1}{2m} \sum_{i=1}^{m} (h_{\theta}(x^{(i)}) - y^{(i)})^2
- 什麼是
- 為什麼要除以 m
- 為什麼要平方
- 為什麼不要 4 次方
J(\theta)
它是我們的 損失函數 (loss function)
m 是特徵數,不然特徵數越大損失越大好像怪怪的
因為大減小或小減大都是距離(損失)
好問題,下集待續。
Gradient Descent 梯度下降
所以說到底要怎麼找
\theta_i
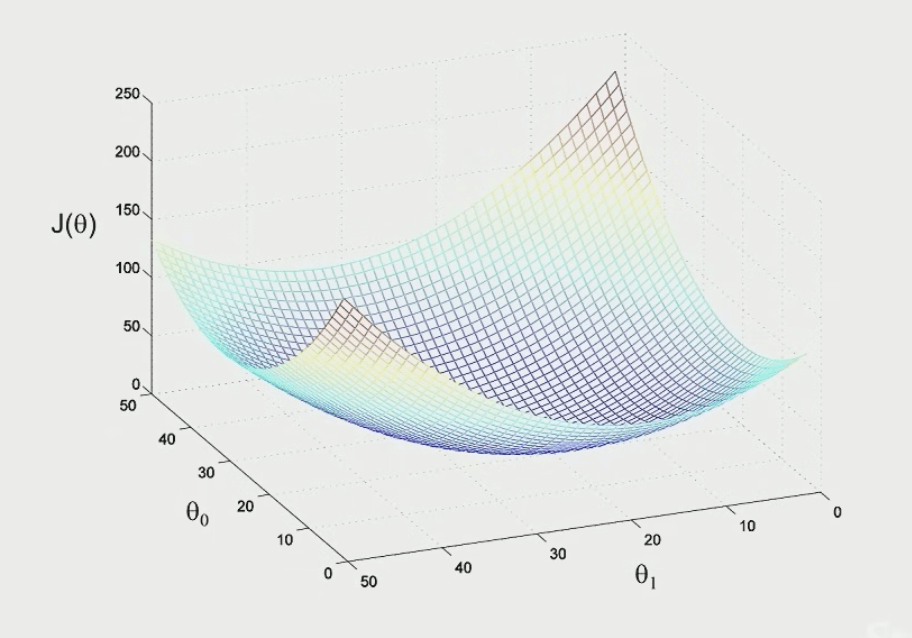
想像我們的
J(\theta)
長這樣
或是這樣
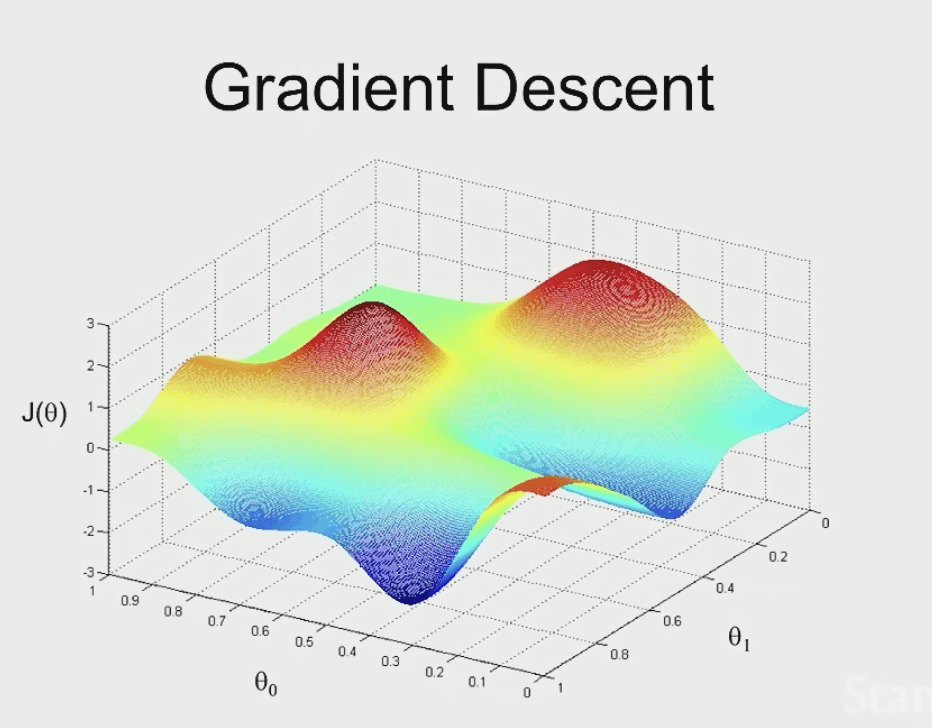
那我們的目標應該是要走到最低點
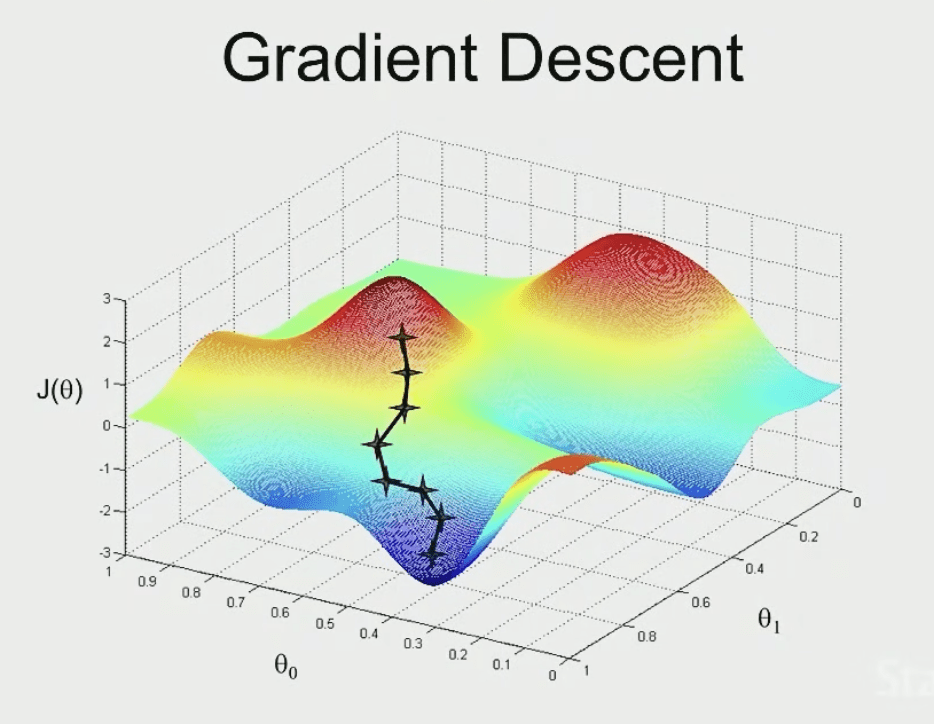
因為這樣可以確保
J(\theta)
達到最小值(損失最少=函數最準)
斜率為正
我們先找個簡單的函式舉例一下
斜率為負
我們先找個簡單的函式舉例一下
斜率為零
我們先找個簡單的函式舉例一下
這就是我們要找的點。
(實作時只要夠接近 0就好)
所以找斜率我們會需要來點
微分
其實不難,我們只需要會兩個東西
\frac{d}{dx} x^n = nx^{n-1}
第一個東西:the power rule (冪次規則)
就是次方項拉到前面(當係數乘上去),然後次方項 -1
\frac{d}{dx} {3x}^2 = 6x
舉例:
微分
\frac{d}{d\theta} f(g(\theta)) = f'(g(\theta)) \cdot g'(\theta)
第二個東西:the chain rule (連鎖律)
\begin{aligned}
\frac{dy}{dx} &= 2(3x + 1)^{2-1} \cdot \frac{d}{dx}(3x + 1) \\
&= 2(3x + 1) \cdot (3) \\
&= 6(3x + 1)
\end{aligned}
舉例:
\frac{dy}{dx}(3x+1)^2
就是一種剝洋蔥,一層一層微進去的概念
\theta_j := \theta_j - \alpha \frac{\partial}{\partial \theta_j} J(\theta)
所以是這樣的:我們要根據斜率,不斷更新
\theta_j
直到
J(\theta)
夠接近其最小值為止
(=它的斜率夠接近 0)
\alpha =
learning rate (學習率,一次調整多少 / 走多遠)
學習率是一個 hyperparameter 「超參數」,是機器學習模型訓練前人工設定的外部配置參數,用於控制學習過程,無法從訓練資料中自動學習得到。
\theta_j := \theta_j - \alpha \frac{\partial}{\partial \theta_j} J(\theta)
\theta_j := \theta_j + \alpha (y^{(i)} - h_{\theta}(x^{(i)})) x_j^{(i)}
(根據冪次法則把 2 乘到前面,然後因為連鎖律所以產生一個 )
我們把它打開,變成
x_j^{(i)}
註 1: 這樣知道為什麼 前面乘一個 1/2 了吧
J(\theta)
註 2: 該特徵值影響越大,則移動越多
Stochastic Gradient Descent 隨機梯度下降法
如果今天訓練資料量很大,
每次移動都要考慮 n 筆資料的話,
會算很久(而且很貴)
隨機梯度下降:每次只考慮一筆資料(由 1 到 n 循環)
所以向各位介紹
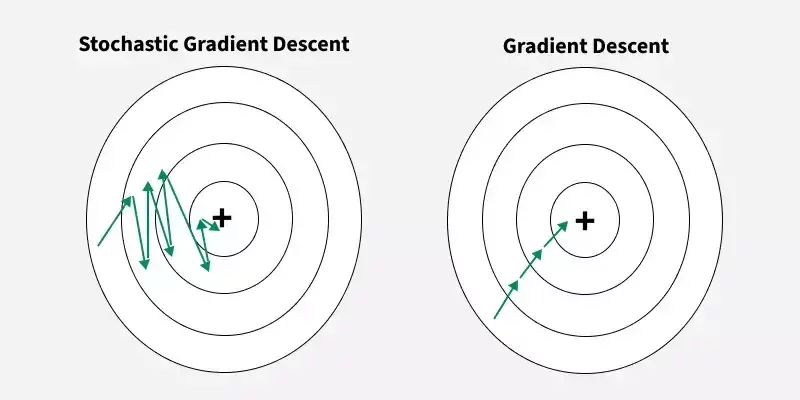
SGD 沒辦法達到真正的 最小值
J(\theta)
但也夠好了(可以透過調整學習率來提升準度)
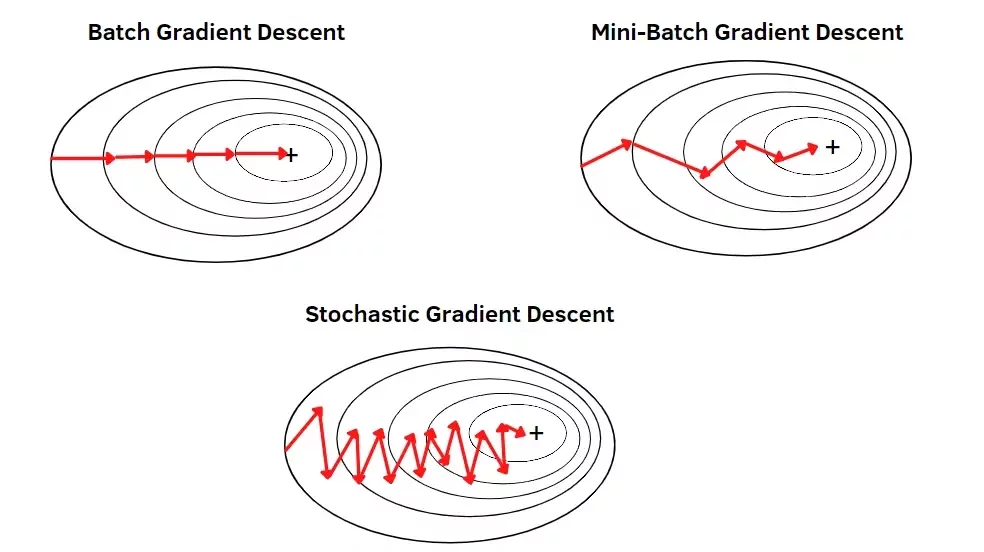
另外還有 mini-batch gradient descent(批次訓練)
每次移動考慮一批資料(例: 100 筆)
實作
import numpy as np
#the training data
x = np.random.randn(50, 1) # 50 筆資料
y = 2*x + np.random.randn(50, 1)
theta_1 = 0.0
theta_0 = 0.0
# hyperparameter
alpha = 0.01 #學習率# 梯度下降
def descend(x, y, theta_1, theta_0, alpha):
dl_theta_1 = 0.0
dl_theta_0 = 0.0
m = x.shape[0]
# loss = (y - (theta_1 * x + theta_0)) **2
for xi, yi in zip(x,y):
dl_theta_1 += -2 * xi * (yi - (theta_1 * xi + theta_0))
dl_theta_0 += -2 * (yi - (theta_1 * xi + theta_0))
theta_1 = theta_1 - (1/m) * dl_theta_1 * alpha
theta_0 = theta_0 - (1/m) * dl_theta_0 * alpha
return theta_1, theta_0
# 執行梯度下降
for epoch in range(800):
theta_1, theta_0 = descend(x, y, theta_1, theta_0, alpha)
hx = theta_1 * x + theta_0
loss = np.mean((y - hx)**2)
print(f'{epoch} loss is {loss}, parameters theta_1 :{theta_1}, theta_0: {theta_0}')
print(theta_1, theta_0)機器學習第 0 堂
By Suzy Huang




