Machine Learning 1
LWR, MLE & Classification
目錄
- Locally Weighted Regression, LWR(局部加權回歸)
- Maximum Likelihood Estimation, MLE(最大概似估計)
- Classification 分類問題
- 二元:Logistic Regression 邏輯斯回歸
- 多元:Softmax 函式 (下集待續)
講師 Suzy (蘇西)
- 北資一六 學術長
技能點:
- Python
- 機器學習 (機器在學習講師也在學習)
- 一些 C++
- 養了兩隻 Labubu

寶寶蘇西

Locally Weighted Regression
局部加權迴歸
Parametric vs Non-parametric
parametric learning algorithm(參數式)
選擇係數 使損失函數最小
\theta
迴歸問題就是要找一條方程式可以適當的擬和training data
y = \theta x_1 + x_0
這我們上次學的線性迴歸,屬於參數學習演算法的一種
\theta_0 + \theta_1 x + \theta_2 x^2
\theta_0 + \theta_1 x + \theta_2 \sqrt{x}
.....
問題:如何知道該用什麼方程式進行學習?
方案一:Parametric + Feature Selection algorithm (特徵篩選)
方案二:Non-parametric learning algorithms (非參數學習演算法)
讓演算法自己判斷方程式該長什麼樣子
Locally Weighted Regression 局部加權迴歸
這是 traning data
Locally Weighted Regression 局部加權迴歸
test data
training data
輸入 x,請預測 y
Locally Weighted Regression 局部加權迴歸
test data
training data
根據和新數據點相近的數據,
判斷輸入的 x 值合理的對應 y 值
data weighted to decide y (test data)
LWR
離 test data 越近則越重要
(權重越大)
較近 = 權重大
較遠 = 權重小
test data
Locally Weighted Regression
Linear Regression
\sum_{i}(y^{(i)} - \theta^{T}x^{(i)})^{2}
\sum_{i}w^{(i)}(y^{(i)} - \theta^{T}x^{(i)})^{2}
找
讓損失函數最小
\theta
w^{(i)} = \exp \left( -\frac{(x^{(i)} - x)^2}{2\tau^2} \right)
其中,權重如下:
w^{(i)} = \exp \left( -\frac{(x^{(i)} - x)^2}{2\tau^2} \right)
每次遇到新的 x 值,就要計算一次,對該 x 值而言,其他每個 traning data 的權重大小。
-(x^{(i)} - x)^2
距離越近,權重越大
\tau
超參數(人工設定的),值越大則考量的鄰近範圍越廣
實作
Maximum Likelihood Estimation
最大概似估計
欸所以為什麼 linear regression 的損失函數是取平方
來了
y^{(i)} = \theta^T x^{(i)} + \epsilon^{(i)}
首先,假設輸入值和輸出值的關聯如下:
其中,
是某種噪音/ 雜訊 /誤差。
\epsilon
在進行 MLE 時,通常假設
的分佈遵守以下兩個規則:
\epsilon
1. IID (Indendently and Identically Distributed)
每筆數據的雜訊獨立,不會互相影響
在進行 MLE 時,通常假設
的分佈遵守以下兩個規則:
\epsilon
2. Normal Distribution / Guassian Distribution
雜訊呈常態/高斯分佈
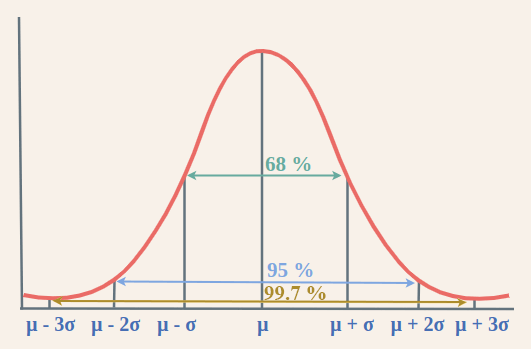
常態分佈的數學式
p(\epsilon^{(i)}) = \frac{1}{\sqrt{2\pi}\sigma} \exp\left( -\frac{(\epsilon^{(i)})^2}{2\sigma^2} \right)
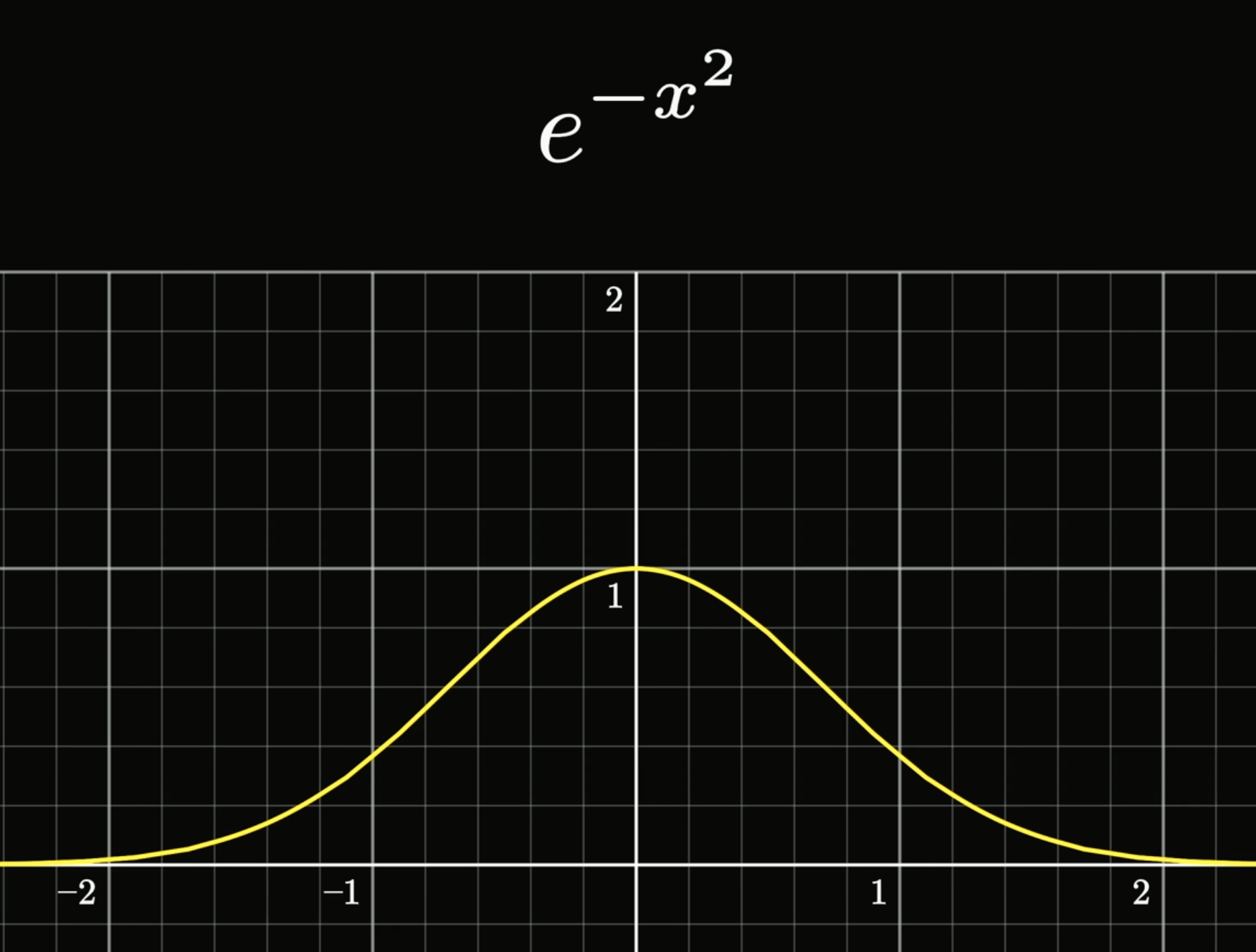
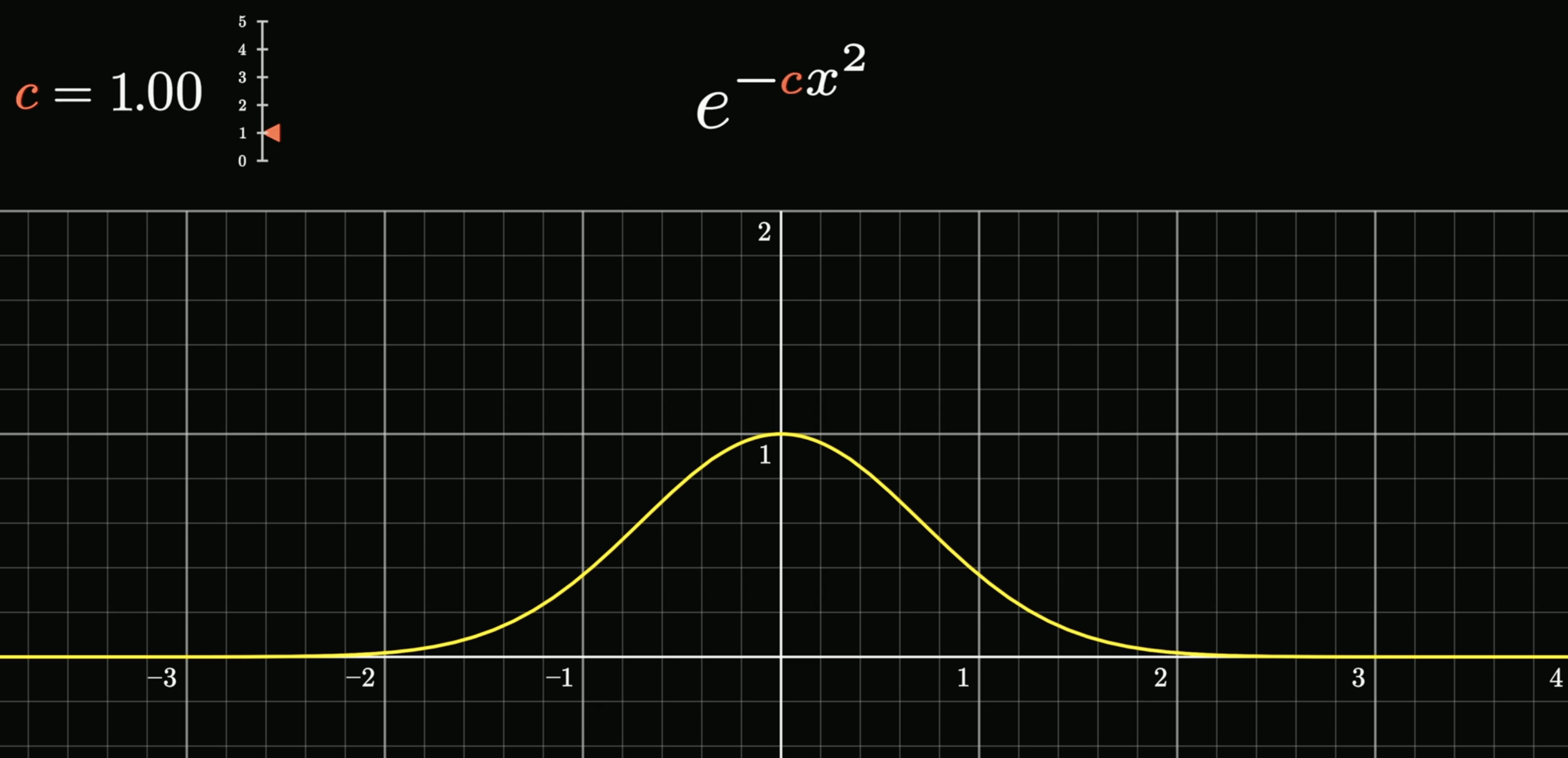
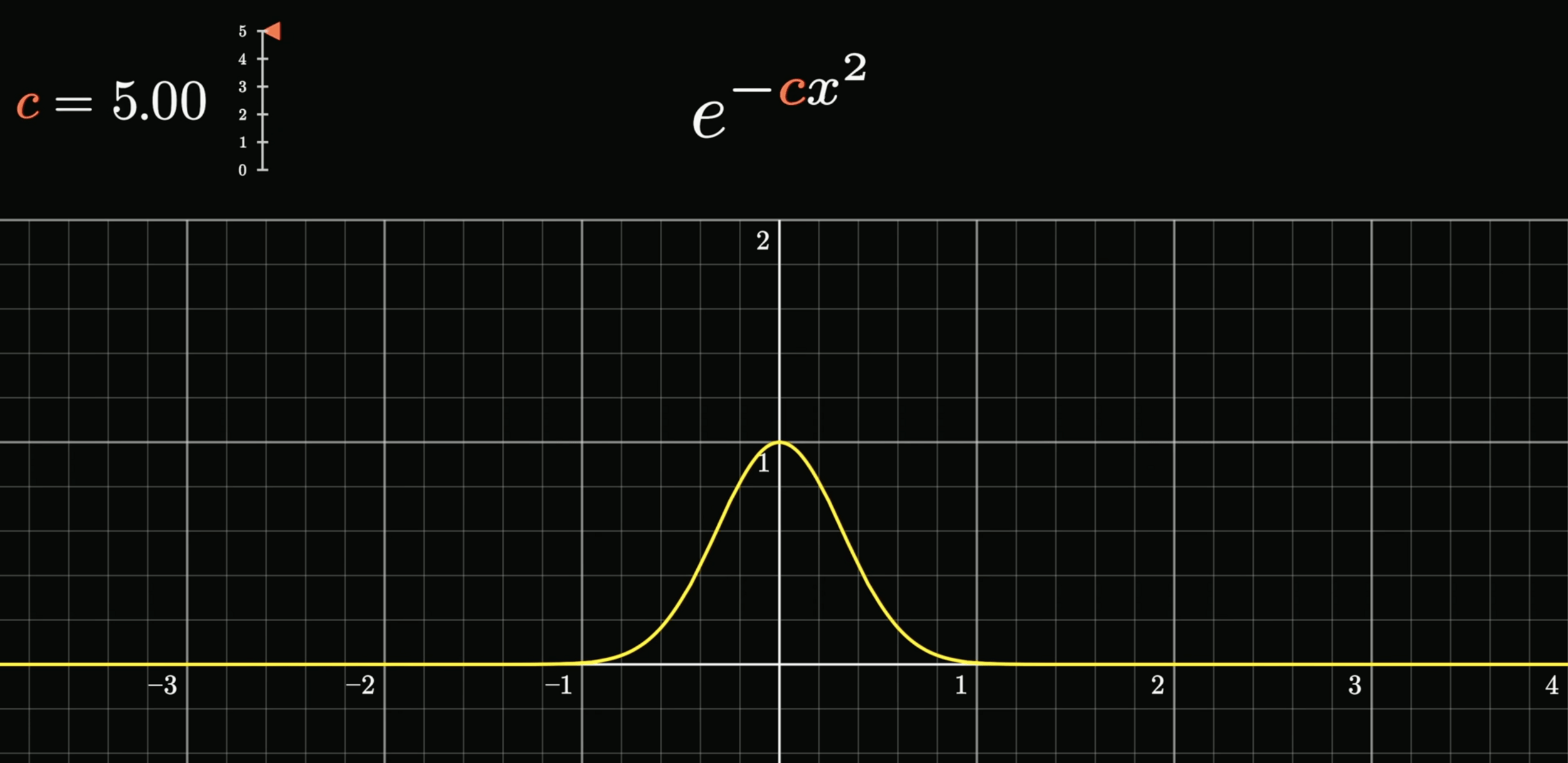
不展開講數學,但我們可以看圖說個故事,想了解的推薦自己去查
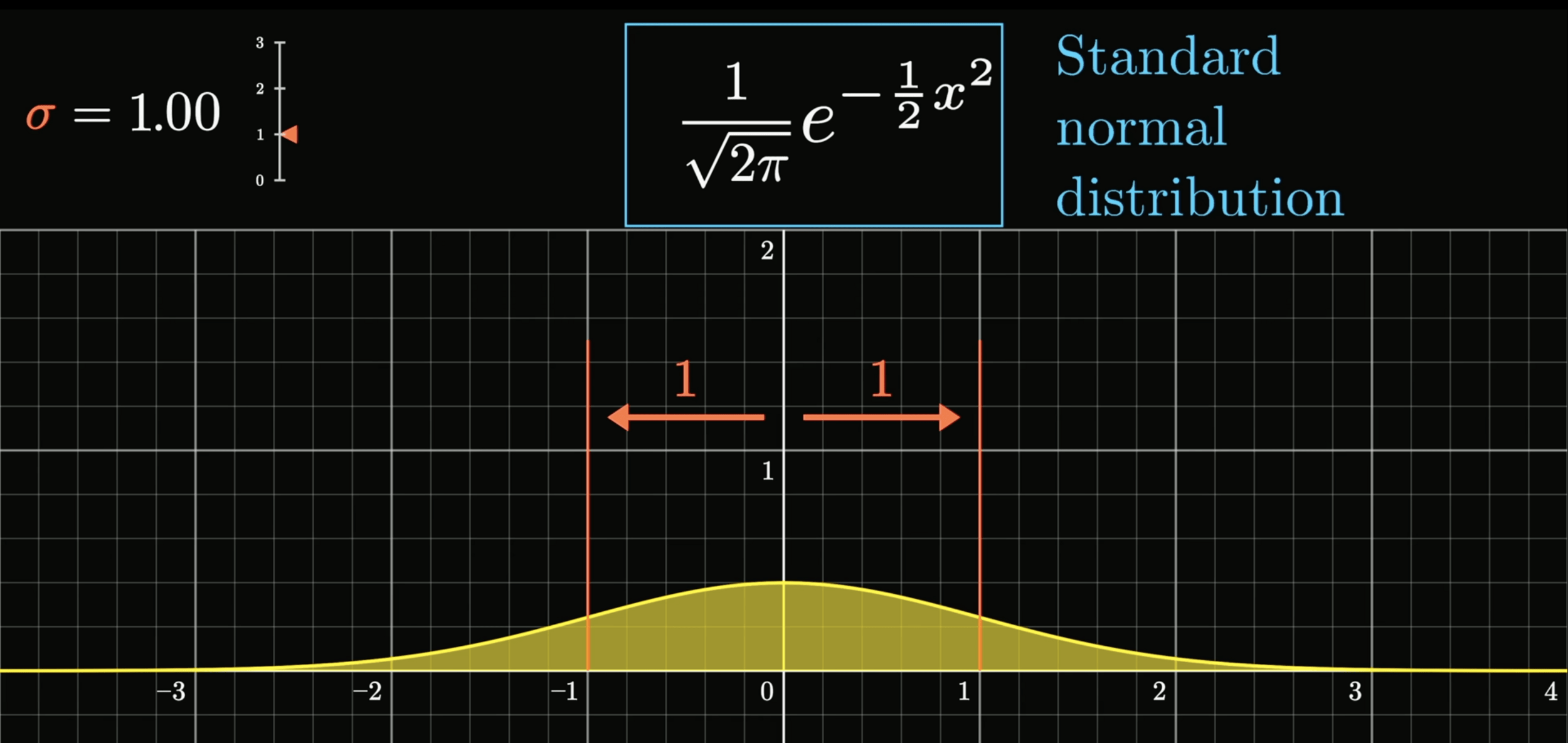
p(\epsilon^{(i)}) = \frac{1}{\sqrt{2\pi}\sigma} \exp\left( -\frac{(\epsilon^{(i)})^2}{2\sigma^2} \right)
Likelihood 似然/似真度
Probability 機率
事件可能發生的程度
某個解釋的合理程度
P(y|x; w) = \frac{1}{\sqrt{2\pi}\sigma} \exp\left( -\frac{(y - wx)^2}{2\sigma^2} \right)
L(w) = \frac{1}{\sqrt{2\pi}\sigma} \exp\left( -\frac{(y - wx)^2}{2\sigma^2} \right)
已知參數
數據
出現的可能性
已知數據
一體兩面
參數 \:w
w
y
y
作為真實解釋
的合理程度
Likelihood 似然/似真度
L(w) = P(y_1|x_1; w) \times P(y_2|x_2; w) \times P(y_3|x_3; w)
\begin{aligned}
L(\theta) &= \prod_{i=1}^{n} p(y^{(i)} | x^{(i)}; \theta) \\
&= \prod_{i=1}^{n} \frac{1}{\sqrt{2\pi}\sigma} \exp\left( -\frac{(y^{(i)} - \theta^T x^{(i)})^2}{2\sigma^2} \right)
\end{aligned}
Likelihood 似然/似真度
\begin{aligned}
\ell(\theta) &= \log L(\theta) \\
&= \log \prod_{i=1}^{n} \frac{1}{\sqrt{2\pi}\sigma} \exp\left( -\frac{(y^{(i)} - \theta^T x^{(i)})^2}{2\sigma^2} \right) \\
&= \sum_{i=1}^{n} \log \frac{1}{\sqrt{2\pi}\sigma} \exp\left( -\frac{(y^{(i)} - \theta^T x^{(i)})^2}{2\sigma^2} \right) \\
&= n \log \frac{1}{\sqrt{2\pi}\sigma} - \frac{1}{\sigma^2} \cdot \frac{1}{2} \sum_{i=1}^{n} (y^{(i)} - \theta^T x^{(i)})^2
\end{aligned}
為計算方便,我們取 log
最小化
最大化
Likelihood 似然/似真度
所以這樣知道這是哪來的了!
除此之外,MLE 的技巧在後面還會用到很多次,所以這裡就先介紹給你們
Classification 分類問題
I. Binary 二元分類
II. Multi-class 多類別分類
邏輯斯回歸
Logistic Regression
我們可以用線性回歸做分類問題嗎
我們可以用線性回歸做分類問題嗎
可以但很怪。
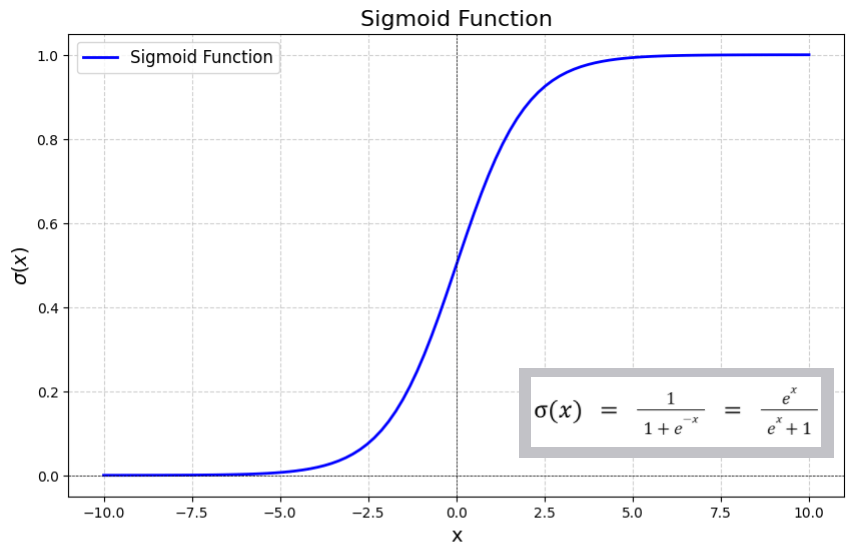
Sigmoid Function / Logistic Function
\begin{cases}
P(y=1 | x; \theta) = h_{\theta}(x) \\
P(y=0 | x; \theta) = 1 - h_{\theta}(x)
\end{cases}
y \in \{0, 1\}
\to P(y | x; \theta) = h(x)^y (1 - h(x))^{1-y}
g(z) = \frac{1}{1 + e^{-z}}
h_\theta(x) = \frac{1}{1 + e^{-\theta^T x}}
Sigmoid Function / Logistic Function
實作
機器學習第 1 堂
By Suzy Huang




