Analyzing bulk OCR Results Among Mixed Typed and Handwritten Documents
Tommy Keswick
Caltech Library
Problems
- Errant HTML in OCR text
HTML in Search Results
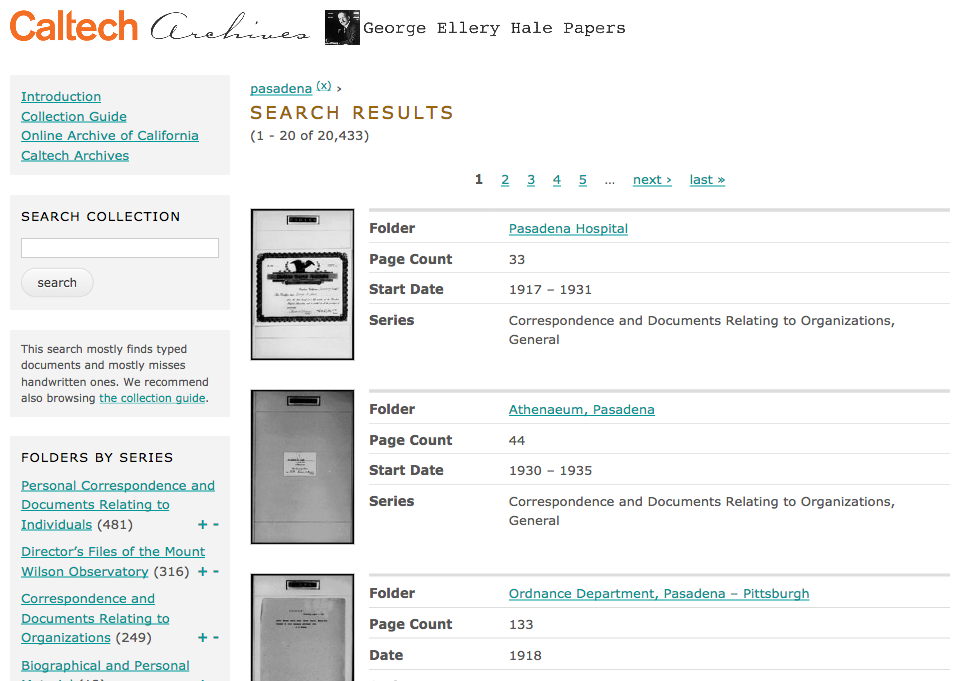
HTML in Search Results
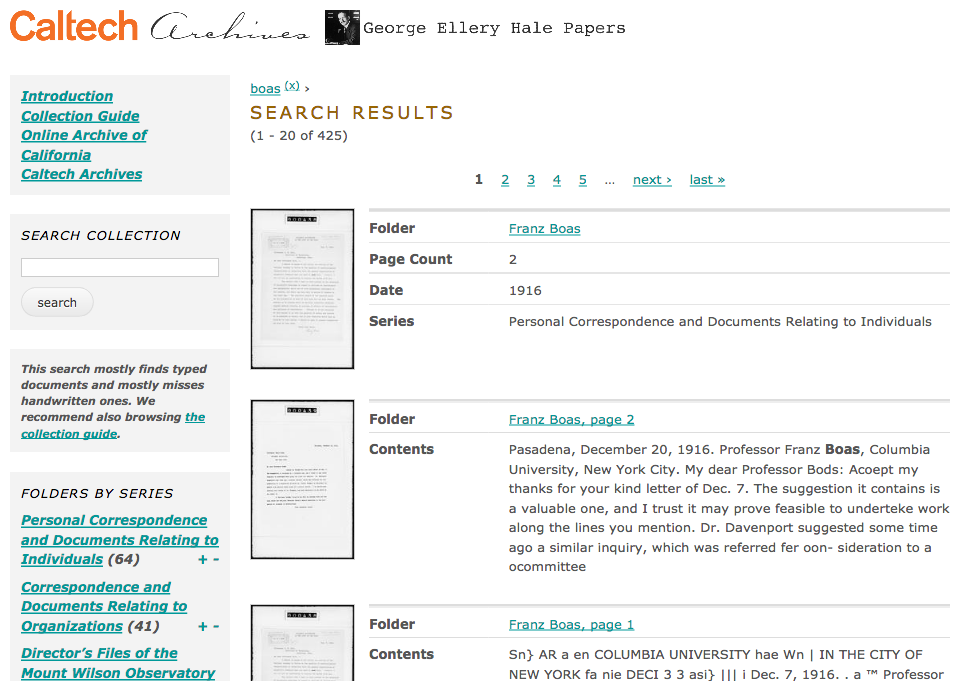
HTML in Search Results

HTML in Search Results

Problems
- Errant HTML in OCR text
- Bias towards typed documents in search results
Approaches
- analyze existing tesseract results
- run statistics with dictionary words
- throw out junk ocr
- generate better ocr/htr with new tools
- google cloud vision
- microsoft azure computer vision
Results
- custom analysis
- plotted dictionary results
- spot-checked graphs
- decided on some thresholds
- online services
- early exploration
- custom software
Script Data
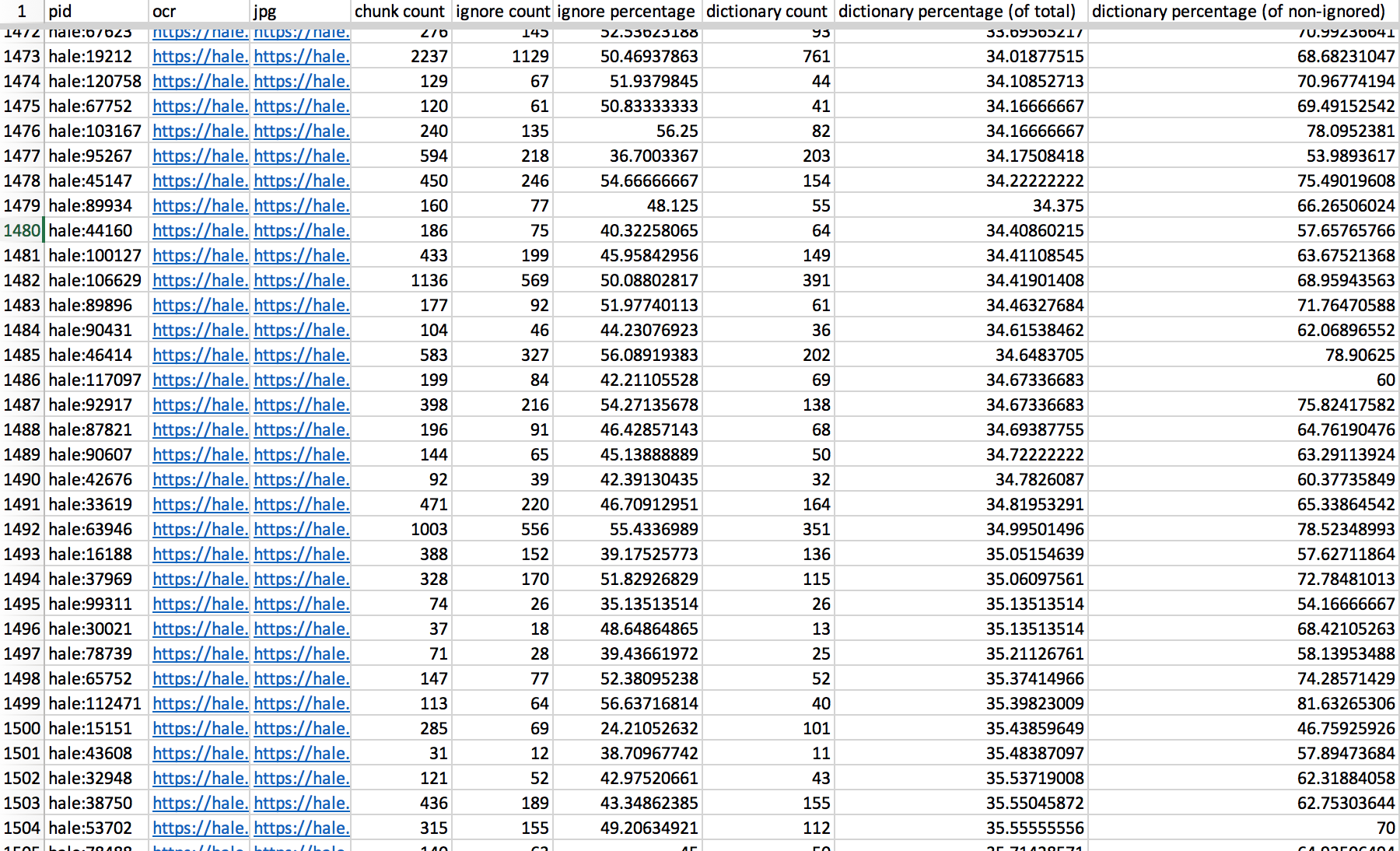
Ignore Percentage
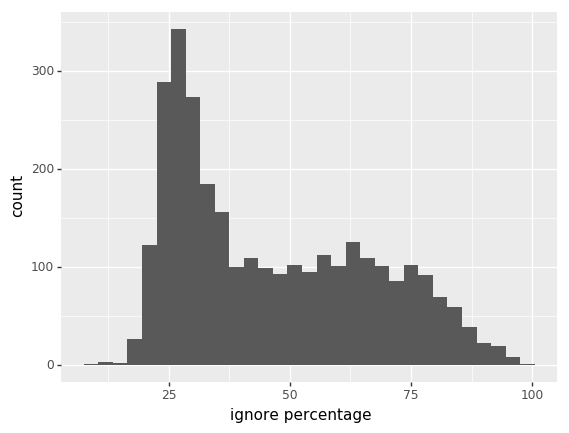
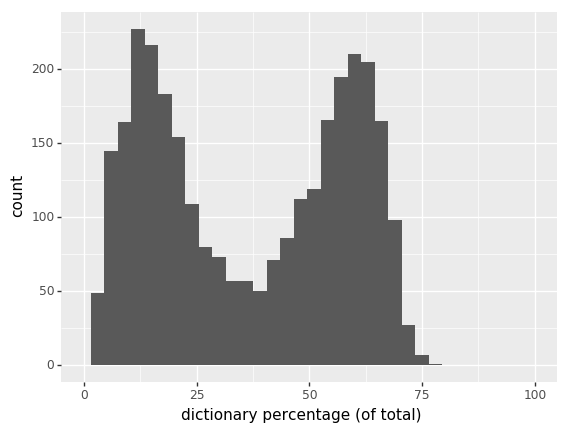
Dictionary Percentage
(of total)
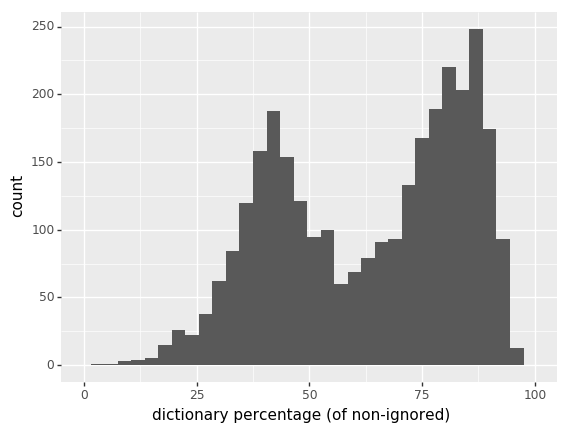
Dictionary Percentage
(of non-ignored)
Thresholds
- dictionary percentage of non-ignored
- >55
- dictionary percentage of total
- >35
Online Services
Next Steps
- better text analysis
- rerun htr
- convert json to hocr
Collaboration
- tkeswick@caltech.edu
- https://github.com/caltechlibrary/ocr-plotting
- https://github.com/caltechlibrary/ocre
- https://github.com/caltechlibrary/handprint
Analyzing bulk OCR Results Among Mixed Typed and Handwritten Documents
By t4k