{MatMul}
simple but can be complicated
Process
Choice of language
C++
1.
2.
Build
Our team makes each part of the build phase seamless with regular check-ins and deliverables.
3.
Launch
It's time to take the product live - the end if the build phase but the beginning of being in market.
# CHAPTER 2
Process
Choice of language
C++
1.
2.
Build
Our team makes each part of the build phase seamless with regular check-ins and deliverables.
3.
Launch
It's time to take the product live - the end if the build phase but the beginning of being in market.
# CHAPTER 2
# CHAPTER 2
Why
After having a brief look at the provided materials, I was left with no other choice but to use C++, if want to the shortest way.


Process
Choice of language
C++
1.
2.
Algorithm
At the start I choose to use Strassen's algorithm
3.
Launch
It's time to take the product live - the end if the build phase but the beginning of being in market.
# CHAPTER 2
Naive matrix multiplication
void multiply(int A[][N], int B[][N], int C[][N])
{
for (int i = 0; i < N; i++)
{
for (int j = 0; j < N; j++)
{
C[i][j] = 0;
for (int k = 0; k < N; k++)
{
C[i][j] += A[i][k]*B[k][j];
}
}
}
}Time Complexity of above method is O(N3).
Strassen’s Method
Time Complexity of above method
T(N) = 7T(N/2) + O(N^2) ~= O(N ^2.8074)
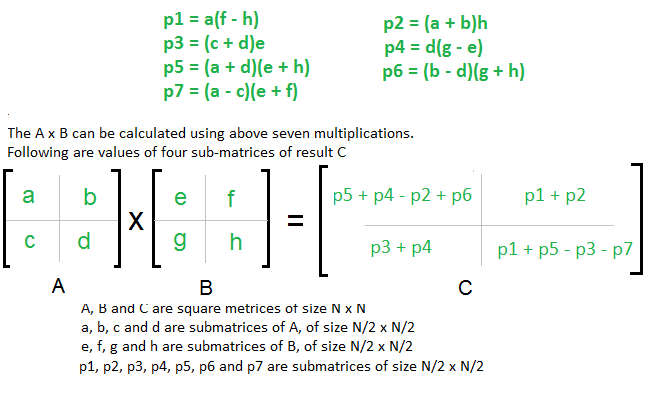
Process
Choice of language
C++
1.
2.
Algorithm
At the start I choose to use Strassen's algorithm
3.
Execution
wrote different implementation for the same
# CHAPTER 2
2
learned about vectorization and it's working
3
Learned about core differences between
CPU and GPU
5
Review and Iterate on the designs with testing of ideas, client feedback and prototypes.
4
Learned about CUDA
Implemented matrix multiplication in it using C++
In this, I learned about the default preferences of a compiler when no flags are provided. Additionally, I gained insight into the various optimization flags that can be utilized to optimize code for different purposes, such as speed, memory efficiency, debugging, and others.
Then I wrote code for the multiplication using both Naive's implementation and Strassen's method. I was confused by the results; the naive implementation was way faster than the Strassen's method.
After looking out I found that Strassen's algorithm is slower as it involves recursive call, which has to be done serially, and also due to extra memory which was temporarily required to store the submatrices, it also involves a greater number of operations.
Vectorisation
For learning vectorisation, I followed the the provided source, first I implemented it the given matrix addition example, but I had encountered an error that both standard loop and vectorised loop was taking same time when I compiled using
By experimenting I got to learn that g++ when used with -O2 was auto vectorising the standard loop, so I had to add an extra flag
-fno-tree-vectorize
g++ -O2 --std=c++14 -fopenmp-simd loop.cpp -Iinclude -o loopWhat is vectorization
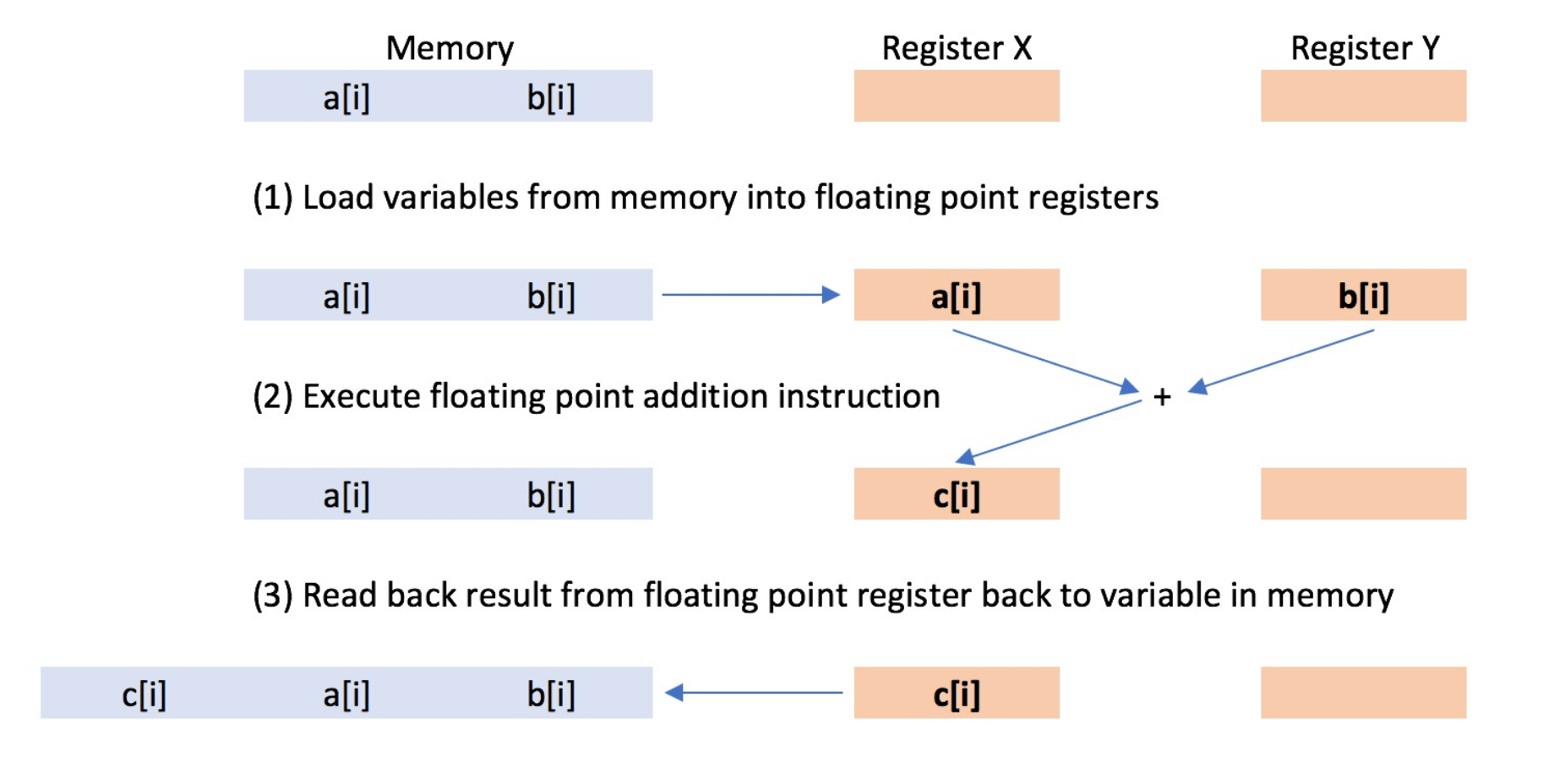
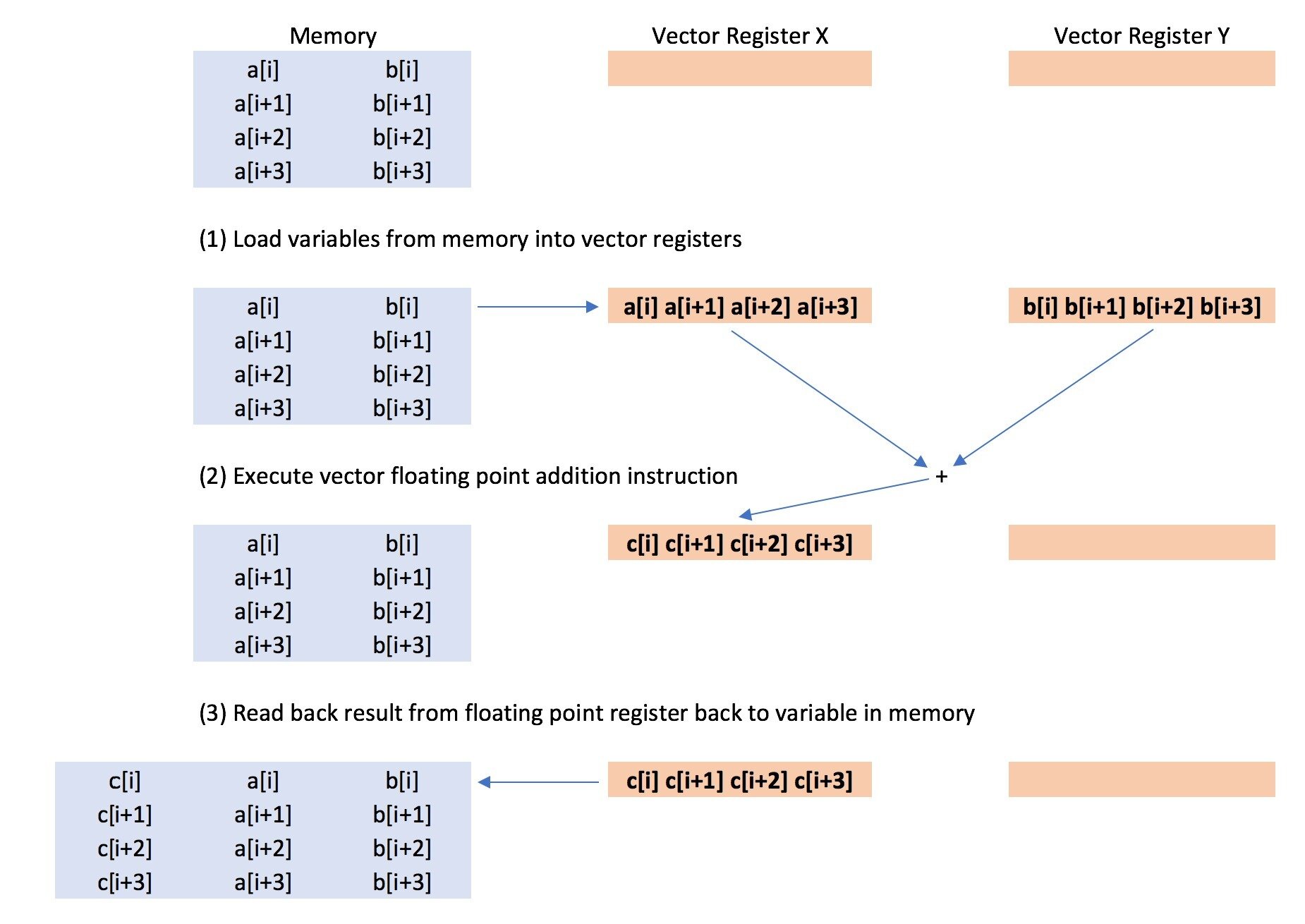
While learning about how vectorization works, I got learn many things like float point processing, registers, about instructions,
vector registers.
Overall I got a basic understanding of how
mathematical operations are performed in processor
After which I planed parallelizing the code, using multithreading, but I then remembered this
so I decided to start learning cuda
CPU vs GPU
here I learned about the major differences between CPU and a GPU, go to know about their basic architecture and caching patterns, I learned that threads in CPU are faster than that in GPU, but very less in number, I learned that CPU is better for running operations sequentially whereas GPU is great for achieving large parallel processing.
CUDA
- I learned how to write a kernel to parallelize a process, I learned about the thread hierarchy ie thread, thread block, grid of thread blocks, and learned relalation between index of thread and thread ID
- I got to know about Memory hierarchy - shared Memory, Global Memory
- I learned about copying memory from host(cpu) to device (gpu), memory allocation with cudaMalloc(), freeing the memory using cudaFree() etc
Code
By Tanush Agarwal
